推荐系统遇上深度学习二十八知识图谱与推荐系统结合之模型原理及实现
原文发布于微信公众号 - 小小挖掘机(wAIsjwj)
原文发表时间:2018-11-19
知识图谱特征学习在推荐系统中的应用步骤大致有以下三种方式:
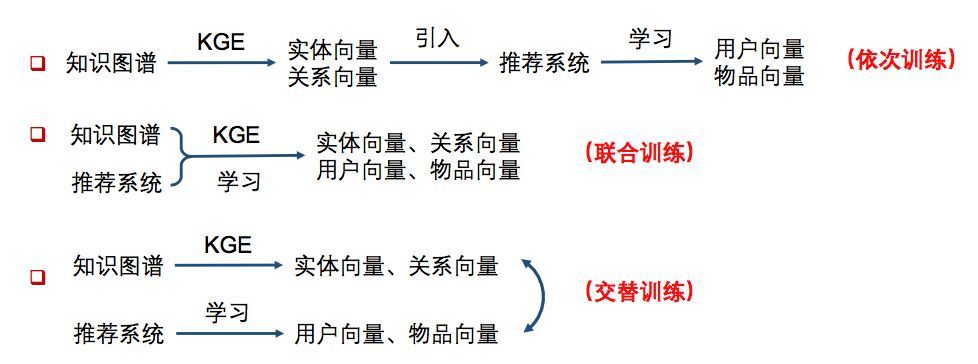
依次训练的方法主要有:Deep Knowledge-aware Network(DKN)
联合训练的方法主要有:Ripple Network
交替训练主要采用multi-task的思路,主要方法有:Multi-task Learning for KG enhanced Recommendation (MKR)
本文先来介绍交替训练的方法MKR。
网上没有找到相关的论文,只有在一篇帖子里有所介绍,github上可以找到源代码进行学习。
1、MKR原理介绍
由于推荐系统中的物品和知识图谱中的实体存在重合,因此可以采用多任务学习的框架,将推荐系统和知识图谱特征学习视为两个分离但是相关的任务,进行交替式的学习。
MKR的模型框架如下图,其中左侧是推荐系统任务,右侧是知识图谱特征学习任务。推荐部分的输入是用户和物品的特征表示,点击率的预估值作为输出。知识图谱特征学习部分使用的是三元组的头节点和关系作为输入,预测的尾节点作为输出:
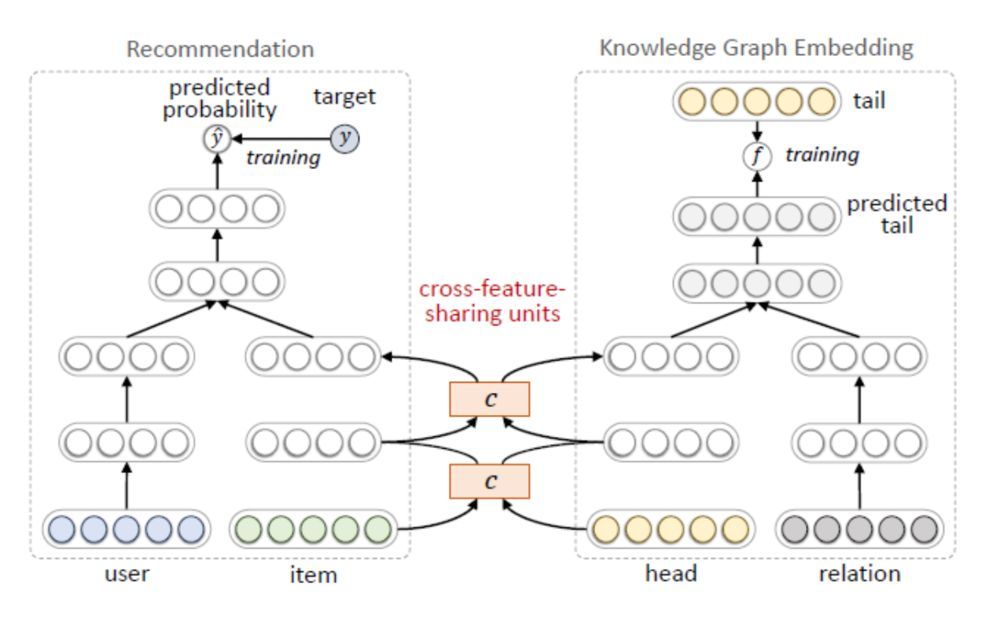
由于推荐系统中的物品和知识图谱中的实体存在重合,所以两个任务并非相互独立。所以作者在两个任务中设计了交叉特征共享单元(cross-feature-sharing units)作为两者的连接纽带。
交叉特征共享单元是一个可以让两个任务交换信息的模块。由于物品向量和实体向量实际上是对同一个对象的两种描述,他们之间的信息交叉共享可以让两者都获得来自对方的额外信息,从而弥补了自身的信息稀疏性的不足,其结构如下:
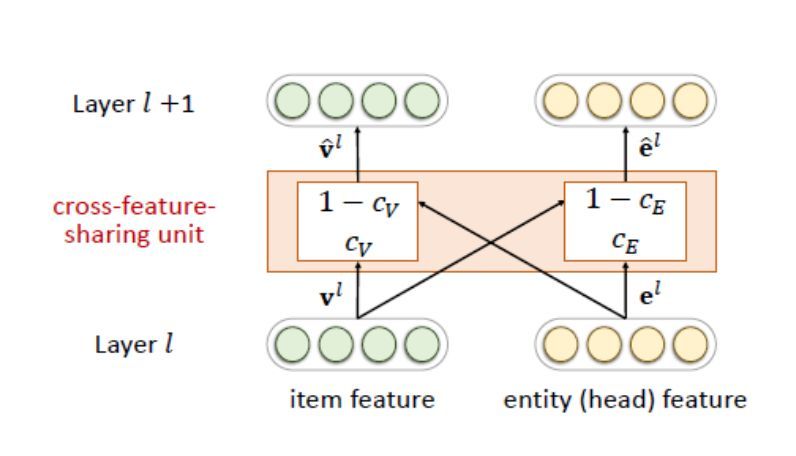
关于这个交叉单元具体实现,大家可以参照代码进行理解。
最后是损失函数部分,由于是交替训练的方式,所以在训练时首先固定推荐系统模块的参数,训练知识图谱特征学习模块的参数;然后固定知识图谱特征学习模块的参数,训练推荐系统模块的参数。
推荐系统模块是点击率预估模型,损失函数是对数损失加l2正则项;知识图谱特征学习模块希望预测得到的tail向量和真实的tail向量相近,因此首先计算二者的内积(内积可近似表示向量之间的余弦相似度),内积经过sigmoid之后取相反数,再加上l2正则项,即得到了知识图谱特征学习模块的损失。关于损失的计算,我们在代码里可以更清楚的看到。
2、MKR模型tensorflow实现
本文的代码地址为: https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-MKR-Demo
参考代码地址为: https://github.com/hwwang55/MKR
数据下载地址为: https://pan.baidu.com/s/1uHkQXK_ozAgBWcMUMzOfZQ 密码:qw30
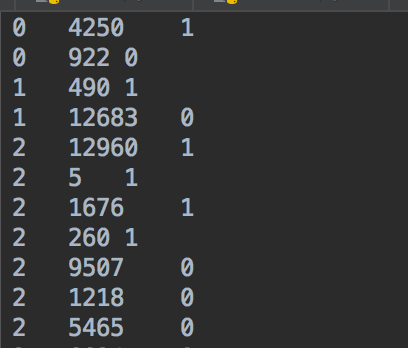
在对数据进行预处理后,我们得到了两个文件:kg_final.txt和rating_final.txt
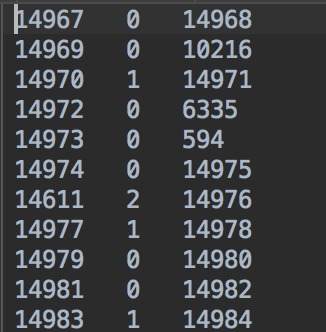
rating_final.txt数据形式如下,三列分别是user-id,item-id以及label(0是通过负采样得到的,正负样本比例为1:1)。
kg_final.txt格式如下,三类分别代表h,r,t(这里entity和item用的是同一套id):
好了,接下来我们重点介绍一下我们的MKR框架的构建。
模型输入
模型输入有以下几部分:用户的id、物品的id、推荐系统部分的label、知识图谱三元组的head、relation、tail的对应id:
def _build_inputs(self):
self.user_indices = tf.placeholder(tf.int32,[None],'user_indices')
self.item_indices = tf.placeholder(tf.int32,[None],'item_indices')
self.labels = tf.placeholder(tf.float32,[None],'labels')
self.head_indices = tf.placeholder(tf.int32,[None],'head_indices')
self.tail_indices = tf.placeholder(tf.int32,[None],'tail_indices')
self.relation_indices = tf.placeholder(tf.int32,[None],'relation_indices')
低层网络构建
低层网络指下面的部分:
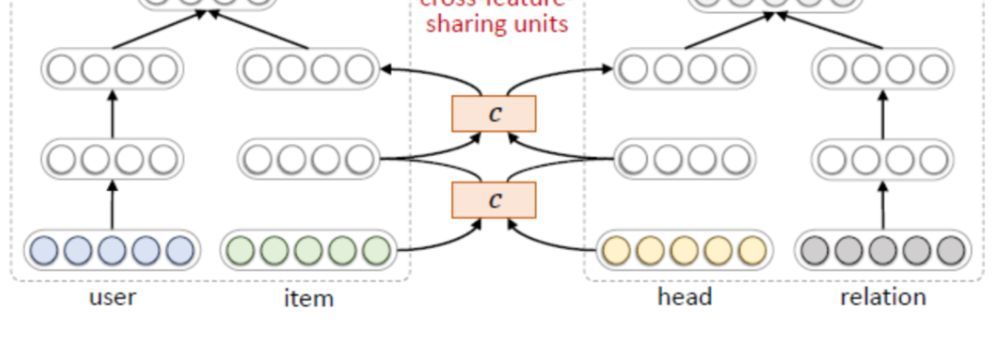
可以看到,user_id、item_id、head_id以及relation_id首先转换为对应的embedding,user_id和relation_id经由多层神经网络向上传播、而head_id和item_id经过交叉单元进行传播。
def _build_low_layers(self,args):
self.user_emb_matrix = tf.get_variable('user_emb_matrix', [self.n_user, args.dim])
self.item_emb_matrix = tf.get_variable('item_emb_matrix', [self.n_item, args.dim])
self.entity_emb_matrix = tf.get_variable('entity_emb_matrix', [self.n_entity, args.dim])
self.relation_emb_matrix = tf.get_variable('relation_emb_matrix', [self.n_relation, args.dim])
# [batch_size, dim]
self.user_embeddings = tf.nn.embedding_lookup(self.user_emb_matrix, self.user_indices)
self.item_embeddings = tf.nn.embedding_lookup(self.item_emb_matrix, self.item_indices)
self.head_embeddings = tf.nn.embedding_lookup(self.entity_emb_matrix, self.head_indices)
self.relation_embeddings = tf.nn.embedding_lookup(self.relation_emb_matrix, self.relation_indices)
self.tail_embeddings = tf.nn.embedding_lookup(self.entity_emb_matrix, self.tail_indices)
for _ in range(args.L):
user_mlp = Dense(input_dim=args.dim,output_dim=args.dim)
tail_mlp = Dense(input_dim=args.dim,output_dim = args.dim)
cc_unit = CrossCompressUnit(args.dim)
self.user_embeddings = user_mlp(self.user_embeddings)
self.item_embeddings,self.head_embeddings = cc_unit([self.item_embeddings,self.head_embeddings])
self.tail_embeddings = tail_mlp(self.tail_embeddings)
self.vars_rs.extend(user_mlp.vars)
self.vars_rs.extend(cc_unit.vars)
self.vars_kge.extend(tail_mlp.vars)
self.vars_kge.extend(cc_unit.vars)
接下来,我们来看一下交叉单元的代码:
v,e = inputs
v = tf.expand_dims(v,dim=2)
e = tf.expand_dims(e,dim=1)
# [batch_size, dim, dim]
c_matrix = tf.matmul(v, e)
c_matrix_transpose = tf.transpose(c_matrix, perm=[0, 2, 1])
# [batch_size * dim, dim]
c_matrix = tf.reshape(c_matrix, [-1, self.dim])
c_matrix_transpose = tf.reshape(c_matrix_transpose, [-1, self.dim])
v_output = tf.reshape(tf.matmul(c_matrix,self.weight_vv) + tf.matmul(c_matrix_transpose,self.weight_ev),[-1,self.dim]) + self.bias_v
e_output = tf.reshape(tf.matmul(c_matrix, self.weight_ve) + tf.matmul(c_matrix_transpose, self.weight_ee),
[-1, self.dim]) + self.bias_e
return v_output,e_output
item对应的embedding用v表示,head对应的embedding用e表示,二者初始情况下都是batch * dim大小的。过程如下:
1、v扩展成三维batch * dim * 1,e扩展成三维batch * 1 * dim,随后二者进行矩阵相乘v * e,我们知道三维矩阵相乘实际上是后两维进行运算,因此得到c_matrix的大小为 batch * dim * dim
2、对得到的c_matrix进行转置,得到c_matrix_transpose,大小为batch * dim * dim。这相当于将e扩展成三维batch * dim * 1,v扩展成三维batch * 1 * dim,随后二者进行矩阵相乘e * v。这是两种不同的特征交叉方式。
3、对c_matrix和c_matrix_transpose 进行reshape操作,变为(batch * dim ) * dim的二维矩阵
4、定义两组不同的参数和偏�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E9%81%87%E4%B8%8A%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%BA%8C%E5%8D%81%E5%85%AB%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E4%B8%8E%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E7%BB%93%E5%90%88%E4%B9%8B%E6%A8%A1%E5%9E%8B%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E7%8E%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


