推荐系统遇上深度学习二十九协同记忆网络理论及实践
协同过滤(collaborative filtering)是推荐系统中经典的一类方法。协同过滤中比较经典的解法有基于邻域方法、矩阵分解等,这些方法都有各自的优点和缺点,本文介绍的方法-**协同记忆网络(Collaborative Memory Network,简称CMN)**融合了不同协同过滤方法的优点。我们来一探究竟!
协同记忆网络CMN论文: https://arxiv.org/pdf/1804.10862.pdf
代码地址: https://github.com/tebesu/CollaborativeMemoryNetwork
1、协同过滤介绍
在信息过载的时代,推荐系统显得十分重要。而在推荐系统中,协同过滤是一种非常受欢迎且有效的方法。协同过滤基于用户和物品的过去交互行为,同时认为相似的用户会消费相似的物品,从而进行推荐。
协同过滤是一类推荐方法,大体上可以分为三个分支:
-
基于邻域的方法。这也是我们常说的基于物品的协同过滤和基于用户的协同过滤方法。我们首先需要计算用户之间、物品之间的相似度,随后基于计算的相似度进行推荐。这种方法的一个主要缺陷就是只使用了局部的结构,而忽略了很多全局的信息,因为我们只使用K个相似用户或者相似物品进行相关的推荐。
-
基于隐向量的方法。这一分支中最具代表性的是矩阵分解及后面的各种改进方法。通常的做法是将每一个用户和物品表示称一个n维的向量,通过用户矩阵和物品矩阵的相乘,希望能够尽可能还原评分矩阵。这种做法虽然考虑了全局的信息,但是忽略了一些比较强的局部联系。
-
基于混合模型的方法。由于上述两种方法都有各自的缺陷,因此混合方法开始出现。最具代表性的是因子分解机和SVD++方法。
也就是说,在使用协同过滤这些方法时,我们通常需要关注两点:
1、需要考虑全局的信息,充分利用整个评分矩阵。
2、需要考虑局部的信息,考虑用户或者物品之间的相似性。相似性高的用户或者物品给予更高的权重。
本文将要介绍的协同记忆网络,便是充分利用了上述两方面的信息。协同过滤我们已经介绍了,那么什么是记忆网络呢?我们接下来进行介绍。
2、记忆网络Memory Network简介
Memory Network是深度学习的一个小分支,从2014年被提出到现在也逐渐发展出了几个成熟的模型。我们这里只介绍其中两个比较基础的模型。一个是 Basic Memory Network,另一个是End to End Memory Network。
我们首先要搞清楚的是,为什么要有记忆网络?在翻译、问答等领域的任务中,我们通常使用的是Seq2Seq结构,由两个循环神经网络组成。循环神经网络(RNN,LSTM,GRU等)使用hidden states或者Attention机制作为他们的记忆功能,但是这种方法产生的记忆太小了,无法精确记录一段话中所表达的全部内容,也就是在将输入编码成dense vectors的时候丢失了很多信息。因此,在模型中加入一系列的记忆单元,增强模型的记忆能力,便有了Memory Network。
2.1 Basic Memory Network
基本的Memory Network由Facebook在2014年的“Memory Networks”一文中提出。该模型主要由一个记忆数组m和I,G,O,R四个模块。结构图如下所示:
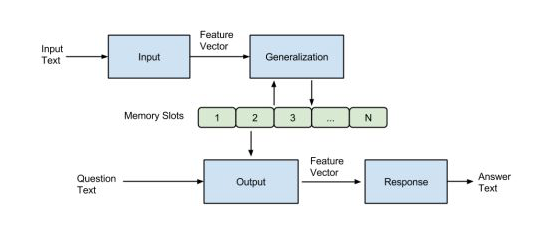
简单来说,就是输入的文本经过Input模块编码成向量,然后将其作为Generalization模块的输入,该模块根据输入的向量对memory进行读写操作,即对记忆进行更新。然后Output模块会根据Question(也会进过Input模块进行编码)对memory的内容进行权重处理,将记忆按照与Question的相关程度进行组合得到输出向量,最终Response模块根据输出向量编码生成一个自然语言的答案出来。各模块作用如下:

有关记忆网络的详细原理,参考文章: https://zhuanlan.zhihu.com/p/29590286 或者原论文: https://arxiv.org/pdf/1410.3916.pdf。
2.2 End to End Memory Network
End to End Memory Network是Memory Network的一个改进版本,可以进行端对端的学习。原文中介绍的网络模型应用于QA任务。单层网络的结构如下图所示:
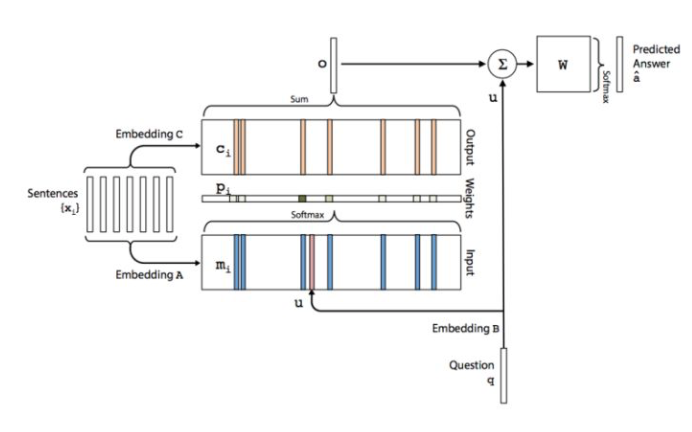
模型主要的参数包括A,B,C,W四个矩阵,其中A,B,C三个矩阵就是embedding矩阵,主要是将输入文本和Question编码成词向量,W是最终的输出矩阵。从上图可以看出,对于输入的句子s分别会使用A和C进行编码得到Input和Output的记忆模块,Input用来跟Question编码得到的向量相乘得到每句话跟q的相关性,Output则与该相关性进行加权求和得到输出向量。然后再加上q并传入最终的输出层。
进一步,我们可以使用多层的结构:
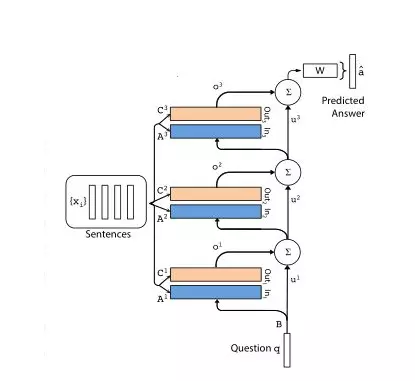
有关End2End Memory Network的详细原理,可以参考文章: https://zhuanlan.zhihu.com/p/29679742 和原论文: http://10.3.200.202/cache/11/03/papers.nips.cc/82b8c2ad3e5cde7cad659be2d37c251e/5846-end-to-end-memory-networks.pdf。
当然,也可以动手实现一个网络结构,参考代码: https://github.com/princewen/tensorflow_practice/tree/master/nlp/Basic-EEMN-Demo
3、协同记忆网络原理
我们的协同记忆网络CMN其实借鉴了End2End Memory Network的思路,我们先来看一下完整的网络结构,随后一步步进行介绍:
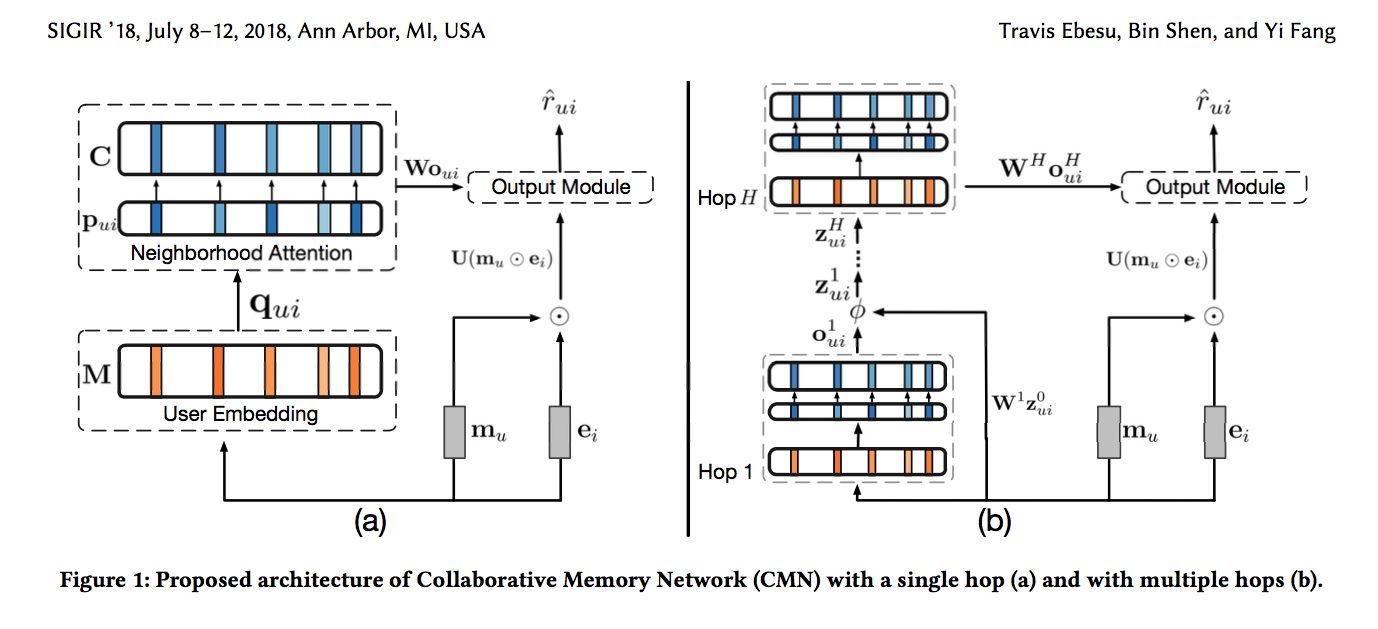
这里明确一点,我们的任务是预测用户u对于物品i的评分。
3.1 User Embedding
首先,我们会有 两组用户的Memory(其实就是Embedding),分别是M和C,M用于计算用户之间关于某件物品i的相关性,C用于最终的输出向量。我们还有一组物品的Memory(其实就是Embedding),我们称作E。
对于预测用户u对于物品i的评分。我们首先会得到历史上所有跟物品i有反馈的用户集合,我们称作N(i)。接下来,我们要计算目标用户u和N(i)中每个用户的相关性,基于下面的公式:
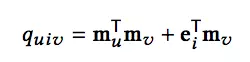
其中,mu,mv分别是用户u和用户v在M中的相关记忆。ei代表物品i在E中的相关记忆。
3.2 Neighborhood Attention
对于上一步计算出的相关性,我们需要通过一个softmax操作转换为和为1的权重向量:
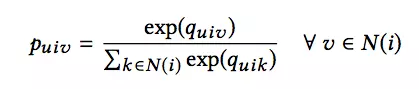
同时,根据得到的权重向量,我们根据下面的式子得到输出向量:
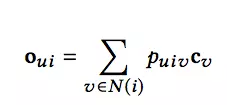
其中,cv代表用户v在C中的相关记忆
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E9%81%87%E4%B8%8A%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%BA%8C%E5%8D%81%E4%B9%9D%E5%8D%8F%E5%90%8C%E8%AE%B0%E5%BF%86%E7%BD%91%E7%BB%9C%E7%90%86%E8%AE%BA%E5%8F%8A%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


