推荐系统遇上深度学习二十三大一统信息检索模型在推荐领域的应用
原文发布于微信公众号 - 小小挖掘机(wAIsjwj)
原文发表时间:2018-09-25
1、引言
信息检索领域的一个重要任务就是针对用户的一个请求query,返回一组排好序的召回列表。
经典的IR流派认为query和document之间存在着一种生成过程,即q -> d 。举一个例子,搜索“哈登”,我们可以联想到“保罗”,“火箭”,“MVP”等等,每一个联想出来的document有一个生成概率p(d|q),然后根据这个生成概率进行排序,这种模型被称作生成模型。人们在研究生成模型的时候,设计了一系列基于query和document的特征,比方说TF-IDF,BM25。这些特征能非常客观的描述query和document的相关性,但没有考虑document的质量,用户的反馈,pagerank等信息。
现代的IR流派则利用了机器学习,将query和document的特征放在一起,通过机器学习方法来计算query和document之间的匹配相关性: r=f(q,d)。举个现实的例子,我们知道“小白”更喜欢“吃鸡”而不是“王者荣耀”,pointwise会优化f(小白,吃鸡)=1,f(小白,王者荣耀)=0;pairwise会优化f(小白,吃鸡)>f(小白,王者荣耀);listwise会考虑很多其他游戏,一起进行优化。机器学习的判别模型能够很好地利用文本统计信息,用户点击信息等特征,但模型本身局限于标注数据的质量和大小,模型常常会在训练数据上过拟合,或陷入某一个局部最优解。
受到GAN的启发,将生成模型和判别模型结合在一起,学者们便提出了IRGAN模型。
2、IRGAN介绍
定义问题
假定我们又一些列的query{q1,…qN}并且有一系列的文档document结合{d1,…dM},对于一个特定的query,我们有一系列标记的真实相关的文档,但是这个数量是远远小于文档总数量M的。query和document之间潜在的概率分布可以表示为条件概率分布ptrue(d|q,r)。给定一堆从真实条件分布ptrue(d|q,r)观察到的样本, 我们可以定义两种类型的IR model。
生成式检索模型:该模型的目标是学习pθ(d|q,r),使其更接近于ptrue(d|q,r)。
判别式检索模型:该模型的目标是学习fΦ(q,d),即尽量能够准确的判别q和d的相关程度
因此,受到GAN的启发,我们将上述的两种IR模型结合起来做一个最大最小化的博弈:生成式模型的任务是尽可能的产生和query相关的document,以此来混淆判别式模型;判别式模型的任务是尽可能准确区分真正相关的document和生成模型生成的document,因此,我们总体的目标就是:
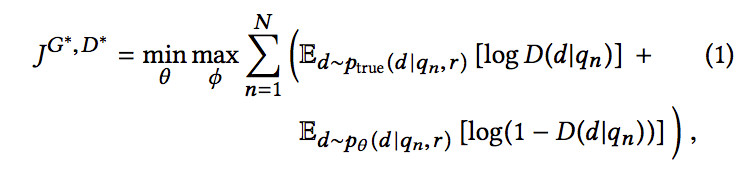
在上式中,生成式模型G为pθ(d|qn,r),生成式模型D对d是否与q相关进行判定,通过下面的式子给出相关性得分:
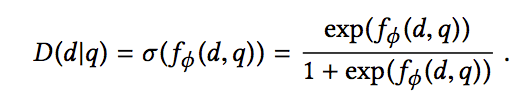
优化判别模型D
判别器的主要目标是最大化我们的对数似然,即正确的区分真正相关的文档和生成器生成的文档。最优的参数通过下面的式子得到:
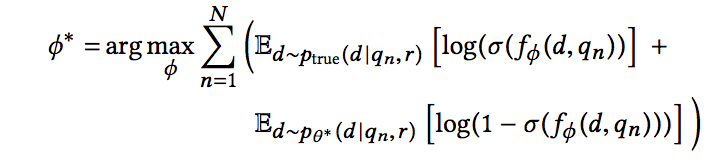
优化生成模型G
生成器的主要目标是产生能够混淆判别器的document,判别器直接从给定的document池中选择document。在固定判别器参数fΦ(q,d)的情况下,生成器的学习目标是(第一项不包含θ,因此可以省略):
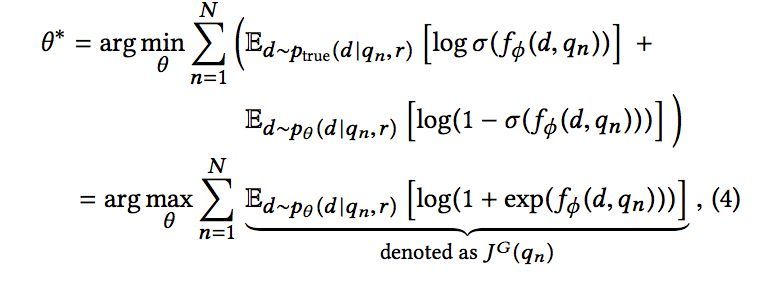
我们把生成器的优化目标写作JG(qn)。
由于生成的document是离散的,无法直接通过梯度下降法进行优化,一种通常的做法是使用强化学习中的策略梯度方法,我们将qn作为state,pθ(d|qn,r)作为对应的策略,而log(1+exp(fΦ(d,qn))作为对应的reward:
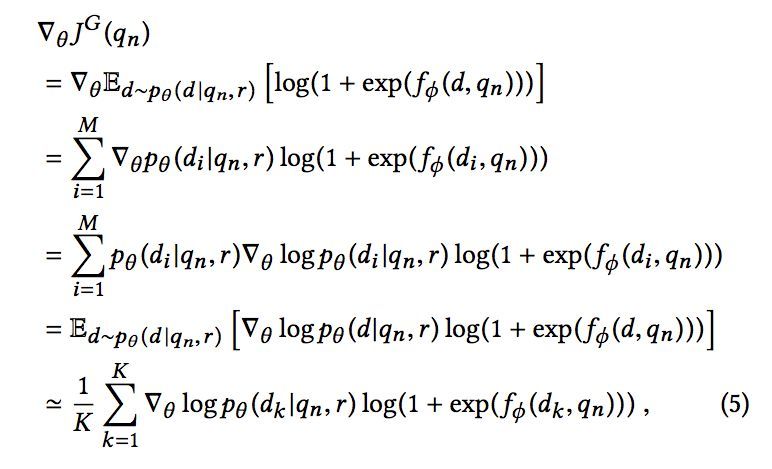
其中,第二步到第三步的变换利用了log函数求导的性质,而在最后一步则基于采样的document做了一个近似。
总体流程
IRGAN的整体训练流程如下:

Pair-wise的情况
在很多IR问题中,我们的数据是对一个query的一系列排序文档对,因为相比判断一个文档的相关性,更容易判断用户对一对文档的相对偏好(比如说通过点击数据,如果两篇document同时展示给用户,用户点击了a而没有点击b,则可以说明用户对a的偏好大于对b的偏好),此外,如果我们使用相关性进行分级(用来表明不同文档对同一个query的匹配程度)而不是使用是否相关,训练数据也可以自然的表示成有序的文档对。
IRGAN在pairwise情况下是同样适用的,假设我有一堆带标记的document组合Rn = {|di > dj}。生成器G的任务是尽量生成正确的排序组合来混淆判别器D,判别器D的任务是尽可能区分真正的排序组合和生成器生成的排序组合。基于下面的式子来进行最大最小化博弈:
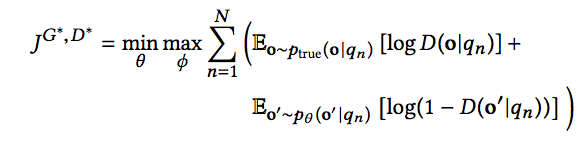
其中,o=,o’=分别代表正确的组合和生成器生成的组合。而D(du,dv|q)计算公式如下:
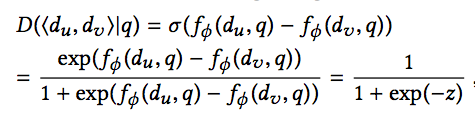
接下来我们就来讲一下生成器的生成策略。首先我们选择一个正确的组合 ,我们首先选取dj,然后根据当前的生成器G的策略pθ(d|q,r),选择比dj生成概率大的dk,组成一组。
有关更多的IRGAN的细节,大家可以阅读原论文,接下来,我们来看一个简单的Demo吧。
3、IRGAN的TF实现
本文的github代码参考:
https://github.com/geek-ai/irgan/tree/master/item_recommendation
源代码是python2.7版本的,修改为python3版本的代码之后存放地址为:
https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-IRGAN-Demo
数据
先来说说数据吧,数据用的是ml-100k的数据,每一行的格式为“uid iid score",我们把评分大于等于4分的电影作为用户真正感兴趣的电影。
Generator
对于训练Generator,我们需要输入的有三部分:uid,iid以及reward,我们首先定义user和item的embedding,然后获取uid和iid的item。同时,我们这里还给每个item定义了一个特征值:
self.user_embeddings = tf.Variable(tf.random_uniform([self.userNum,self.emb_dim],
minval=-initdelta,maxval=self.initdelta,
dtype =tf.float32))
self.item_embeddings = tf.Variable(tf.random_uniform([self.itemNum,self.emb_dim],
minval=-initdelta,maxval=self.initdelta,
dtype=tf.float32))
self.item_bias = tf.Variable(tf.zeros([self.itemNum]))
self.u = tf.placeholder(tf.int32)
self.i = tf.placeholder(tf.int32)
self.reward = tf.placeholder(tf.float32)
self.u_embedding = tf.nn.embedding_lookup(self.user_embeddings,self.u)
self.i_embedding = tf.nn.embedding_lookup(self.item_embeddings,self.i)
self.i_bias = tf.gather(self.item_bias,self.i)
接下来,我们需要计算传入的user和item之间的相关性,并通过传入的reward来更新我们的策略:
self.all_logits = tf.reduce_sum(tf.multiply(self.u_embedding,self.item_embeddings),1) + self.item_bias
self.i_prob = tf.gather(
tf.reshape(tf.nn.softmax(tf.reshape(self.all_logits, [1, -1])), [-1]),
self.i)
self.gan_loss = -tf.reduce_mean(tf.log(self.i_prob) * self.reward) + self.lamda * (
tf.nn.l2_loss(self.u_embedding) + tf.nn.l2_loss(self.i_embedding) + tf.nn.l2_loss(self.i_bias)
)
g_opt = tf.train.GradientDescentOptimizer(self.learning_rate)
self.gan_updates = g_opt.minimize(self.gan_loss,var_list=self.g_params)
Discriminator
传入D的同样有三部分,分别是uid,iid以及label值,与G一样,我们也首先得到embedding值:
self.user_embeddings = tf.Variable(tf.random_uniform([self.userNum,self.emb_dim],
minval=-self.initdelta,maxval=self.initdelta,
dtype=tf.float32))
self.item_embeddings = tf.Variable(tf.random_uniform([self.itemNum,self.emb_dim],
minval=-self.initdelta,maxval=self.initdelta,
dtype=tf.float32))
self.item_bias = tf.Variable(tf.zeros(self.itemNum))
self.u = tf.placeholder(tf.int32)
self.i = tf.placeholder(tf.int32)
self.label = tf.placeholder(tf.float32)
self.u_embedding = tf.nn.embedding_lookup(self.user_embeddings,self.u)
self.i_embedding = tf.nn.embedding_lookup(self.item_embeddings,self.i)
self.i_bias = tf.gather(self.item_bias,self.i)
随后,我们通过对数损失函数来更新D:
self.pre_logits = tf.reduce_sum(tf.multiply(self.u_embedding, self.i_embedding), 1) + self.i_bias
self.pre_loss = tf.nn.sigmoid_cross_entropy_with_logits(labels = self.label,
logits = self.pre_logits) + self.lamda * (
tf.nn.l2_loss(self.u_embedding) + tf.nn.l2_loss(self.i_embedding) + tf.nn.l2_loss(self.i_bias)
)
d_opt = tf.train.GradientDescentOptimizer(self.learning_rate)
self.d_updates = d_opt.minimize(self.pre_loss,var_list=self.d_params)
D中还有很重要的一步就是,计算reward:
self.reward_logits = tf.reduce_sum(tf.multiply(self.u_embedding,self.i_embedding),1) + self.i_bias
self.reward = 2 * (tf.sigmoid(self.reward_logits) - 0.5)
模型训练
我们的G和D是交叉训练的,D的训练过程如下,每隔5轮,我们就要调用generate_for_d函数产生一批新的训练样本。
for d_epoch in range(100):
if d_epoch % 5 == 0:
generate_for_d(sess,generator,DIS_TRAIN_FILE)
train_size = ut.file_len(DIS_TRAIN_FILE)
index = 1
while True:
if index > train_size:
break
if index + BATCH_SIZE <= train_size + 1:
input_user,input_item,input_label = ut.get_batch_data(DIS_TRAIN_FILE,index,BATCH_SIZE)
else:
input_user,input_item,input_label = ut.get_batch_data(DIS_TRAIN_FILE,index,train_size-index+1)
index += BATCH_SIZE
_ = sess.run(discriminator.d_updates,feed_dict={
discriminator.u:input_user,discriminator.i:input_item,discriminator.label:input_label
})
generate_for_d函数形式如下,其根据G的策略,生成一批样本。
def generate_for_d(sess,model,filename):
data = []
for u in user_pos_train:
pos = user_pos_train[u]
rating = sess.run(model.all_rating,{model.u:[u]})
rating = np.array(rating[0]) / 0.2
exp_rating = np.exp(rating)
prob = exp_rating / np.sum(exp_rating)
neg = np.random.choice(np.arange(ITEM_NUM),size=len(pos),p=prob)
# 1:1 的正负样本
for i in range(len(pos)):
data.append(str(u) + '\t' + str(pos[i]) + '\t' + str(neg[i]))
with open(filename,'w') as fout:
fout.write('\n'.join(data))
G的训练过程首先要通过D得到对应的reward,随后更新自己的策略:
for g_epoch in range(50):
for u in user_pos_train:
sample_lambda = 0.2
pos = user_pos_train[u]
rating = sess.run(generator.all_logits,{generator.u:u})
exp_rating = np.exp(rating)
prob = exp_rating / np.sum(exp_rat
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E9%81%87%E4%B8%8A%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%BA%8C%E5%8D%81%E4%B8%89%E5%A4%A7%E4%B8%80%E7%BB%9F%E4%BF%A1%E6%81%AF%E6%A3%80%E7%B4%A2%E6%A8%A1%E5%9E%8B%E5%9C%A8%E6%8E%A8%E8%8D%90%E9%A2%86%E5%9F%9F%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


