推荐系统系列详解曝光去重设计与实践
原文: https://zhuanlan.zhihu.com/p/438660053
本文经作者授权转载
1. 什么是曝光去重|曝光过滤?
为什么需要曝光去重?
在推荐这个场景,特别是信息流&短视频领域,视频和图文都属于快消品,用户会频繁的刷新,挑选符合他们口味的内容,尤其像抖音 & bilibi这种短内容平台,一刷就是一个下午。
在上文讲过,推荐的逻辑是从整个大的内容池过滤出最符合当下用户的内容,那么 如何标识哪些内容已经被用户消费过 这个问题,至关重要。
最典型的场景莫过于, 重复推荐 。我甚至能够想象用户多次刷到重复内容的绝望场景:“不会吧不会吧,这个视频我刚已经点过赞了,又来,up这波要赞简直丧心病狂啊”

同理在电商推荐场景也类似,用户已经点击过没有明显消费兴趣的,假如还重复推荐的话,本质上是对流量和广告的一种浪费(都是白花花的钱)
1.1 如何定义内容重复
用户刷到重复内容,可以从以下几个角度考量
1.相同的内容,在内容池里 属于两个不同的itemid 。2.极度相似的内容,在内容池里 属于两个不同的itemid 3.同一篇内容, 同一个itemid ,给同一个用户曝光了多次
其中 1. 2 点都可以通过内容平台入库审核内容时卡掉。相同或者相似的内容不入库。
在检测内容相同或者相似上,有不同的算法。
比如图文内容重复,常见的是 simhash算法。simhash算法是一种局部敏感hash算法。可以将原始的文本映射为 hash数字,且相近的文本得到的hash签名也比较相似。比如 “推荐系统实战” 和 “推荐系统实践” 在文本上只相差1 个字。算出来的 hash 签名可能是 00010 1 和 00010 0 。通过对比两个hash签名的 0 1 区别,即可大致判断文本是否相同或者相似(也叫Hamming distance,海明距离)
视频的相似检测也可以基于类似的方法,首先将视频抽成帧,再基于帧提取图像特征,进行模型训练,每个视频得到对应一个 embedding向量。通过计算向量的相似度来判断视频是否相似。
本文主要讨论第3点,在相同itemid 上的曝光去重工程实践。
2 曝光去重的选型考量
在上一小节介绍内容相似的时候,我们引入simhash等相似算法。那么在去重服务上能否也使用simhash?
理论上是可以的。
但是曝光去重作为一个在线服务,在日活千万的产品下,服务QPS甚至可能达到10w/qps, 因此除了达到判重这个功能性需求外,还需要具备有很高的性能( 时间复杂度,空间复杂度 )
simhash是通过计算内容的签名之间的 01差异数量(海明距离)来判断是否相似的。虽然可以通过离线计算好item之间的相似度,存储起来,但性能和实效性依旧很差,因此曝光去重在线场景不太适合。
2.1 redis hash方案
判断是否存在这个场景。最容易想到的是 hashmap这个数据结构。
以 用户id + item_id 为 key, map里查找下是否存在即可。时间复杂度 O(1)。单机内存存不下,也可以存储在redis 上。方便快捷,批量item_id也只要mget一下即可。
当然,每次用户曝光记录都以user_id + item_id的方式作为key,挺浪费存储的,可以直接使用 redis 的hash结果。每个userid作为key,value 是 用户曝光过的item_id 为key的 hashmap。大概结构如下
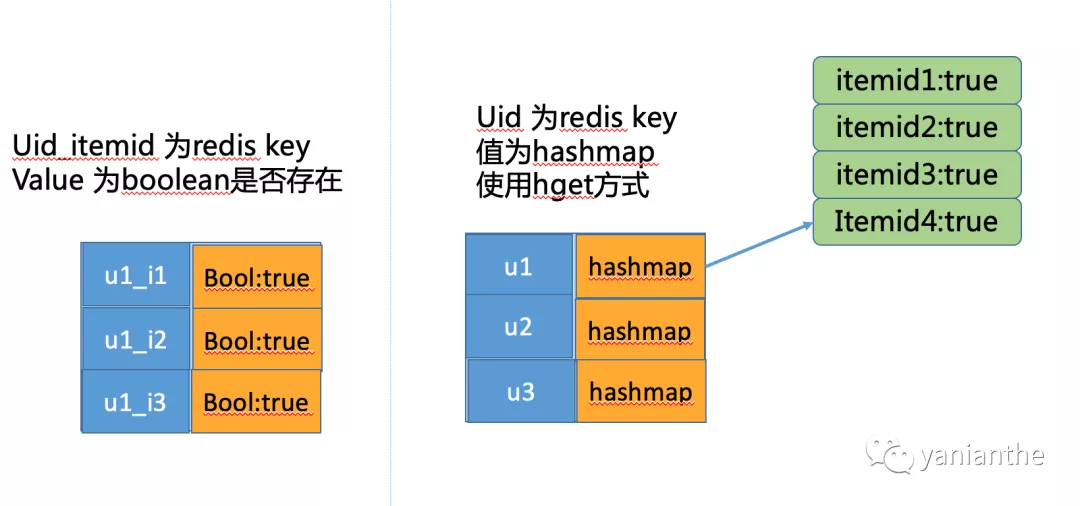
看着没啥毛病,但是我们深究一下。假设 用户id 和 item_id 都是长度为10的字符串,平均每个用户曝光过200个item(很多用户闲着无聊,一个下午都能刷几百条小视频)。整个平台算5000万用户好了。
redis 存储空间大小(key +value大小): 忽略hashmap负载因子等其他因素
5千万(用户量级) * (10(userid) + 10(itemid) * 200(平均200条)) = 1000G (1T左右)
随着业务发展,redis 中曝光列表会越来越长(如何淘汰掉key?每个用户直接设置过期删除整个列表?),成本压力和性能以及稳定性都会面临挑战。
2.2 bitmap & 布隆过滤器方案
在 2.1 方案中,大部分的空间都花在存储曝光的item_id 文本上。为了进一步优化性能和存储,在曝光去重业务中,我们更加关心的是存在与否,具体存在哪些值其实并不重要(想要排查用户的曝光item也可以通过session服务获取,session服务后续也会介绍到)。
联想到海量数据处理中,常用的手法是使用bitmap 位技术。

给定1个byte(有8个bit),一共可以存储8个数字。若第5个bit 为1 。则数字4存在。
使用bitmap的好处,是可以将itemid的长度,从10byte 降低为 1个 bit,存储空间可以极大降低。
假设我们使用 hash32 等算法将 itemid 转化为 int。那么 bitmap 的长度应该是
2^32 (bit) = 512M
5千万的用户,redis 存储占用空间约为:
5000万 * 512M = 2500P 。。。
疯了吧,怎么反而比之前存储的1T方案还多。。。
事实上我们我们的bitmap根本不需要存 2^32这么大。假如我的 内容池子是 1千万,那我bit大小也就,1千万bit = 1.2M 左右。比512M 省多了。
为了节约更多存储,我们还可以进一步压缩bitmap的大小。使用的时候 算一下 hash(itemid) % size(bitmap) 即可。在存储上当然是越小越好的。但是这玩意小了会冲突严重,大了会浪费存储。
所以,应该如何综合考量 冲突率与存储长度之间的权衡 呢?
布隆过滤器应运而生。
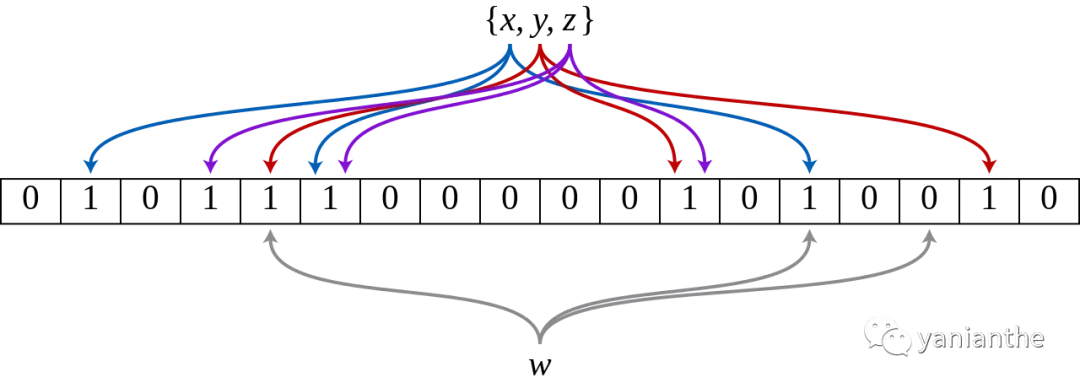
布隆过滤为了降低hash碰撞,引入了多个hash函数。插入元素时,字符串经过k次hash函数计算(可以是不同hash函数),将映射到bitmap相应位置的bit位置为1。查询时同样需要k个位置的bit 为1,元素才算存在。
但由于hash函数有碰撞,因此有一定概率,多个元素,算出来的k个bit位完全相同,这也就是布隆过滤器的 误判率
误判率直白讲,就是本来不在集合里的,你错误判断存在集合,这个在推荐去重服务并不会本质影响业务(试想,即时误判了,也只是当条内容不会推荐给用户,并不会导致重复推荐)
针对布隆过滤器的几个参数,直观理解上:
- 哈希函数越多,误判率会越低,bitmap 上位置会消耗得更快(存储元素就会少一些)。查询开销也会线性增大(需要计算多次hash函数)2.bitmap 存储空间越大,冲突&误判率就会降低。
自变量因素/影响变量误判率存储元素/itemid个数查询开销哈希函数k越多变低变少变大bitmap空间增大变低变多不变
回到上面冲突率和存储空间占用的综合考量问题上,其实就是bitmap大小与 hash函数个数,与误判率之间的选择。
好在布隆过滤器针对误判率与参数判断之间,有成熟的推论(具体的推论有兴趣可以直接看原论文)。
从应用角度上,我们可以通过设置其中某几个固定参数,来相互推导,决定大小。
布隆过滤器参数推导工具:在线推导工具^[1]^
可以设定 在 5个 哈希函数,误判率为0.1%,存储itemid 1万个 的情况下,bitmap的空间是多少
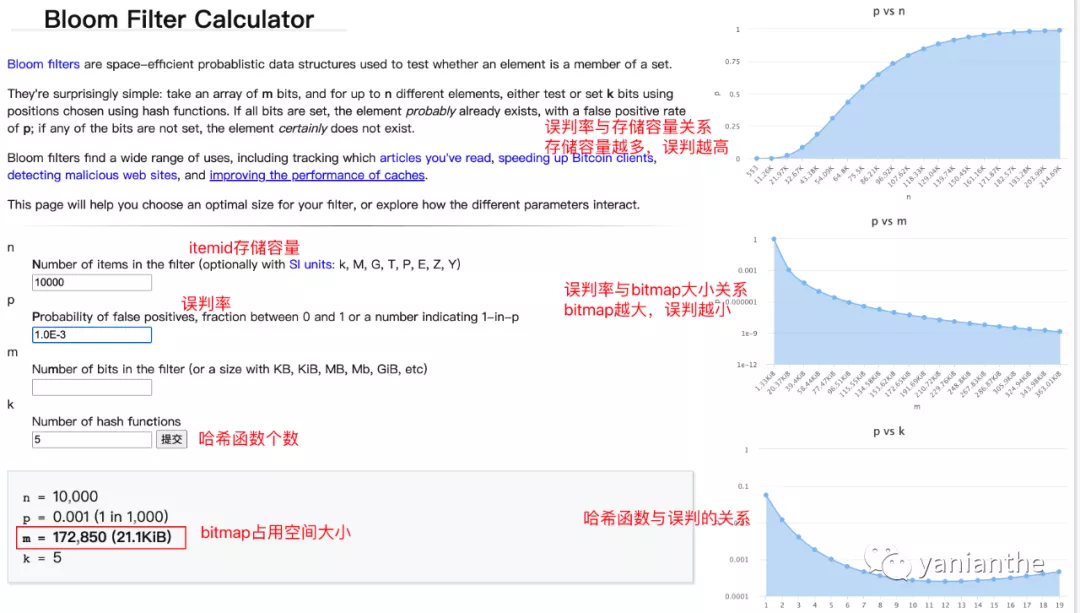
单个参数也不是越大越好,也可以辅助右边曲线图进行判断,某个参数达到一定阈值,增益就会变小。
使用bloomfilter 后,存储1万条的itemid去重,相比redis存储key的方式,存储占用大小前后对比(假设都存1万条itemid情况下)
98kb(1000 * 10byte) —> 21.kb。成本存储可以节约 3/4 +
3 灵魂诘问1-写满了怎么办?
在[2.2小节](#bitmap & 布隆过滤器方案)中我们讨论了使用bloomfilter作为去重利器。在接受一定误判率的前提下,能够极大节约存储成本。
但是随着产品发展,用户体验内容越来越多,bloomfilter 中存储itemid个数也会越来越多(bit位设置为1)。
而bitmap的大小是初始化时就固定的,一旦写入个数越来越多,超过我们的初始容量值时,误判率就会越来越高,在这种情况下,可以认为布隆过滤器“写满了”,不再适用了。
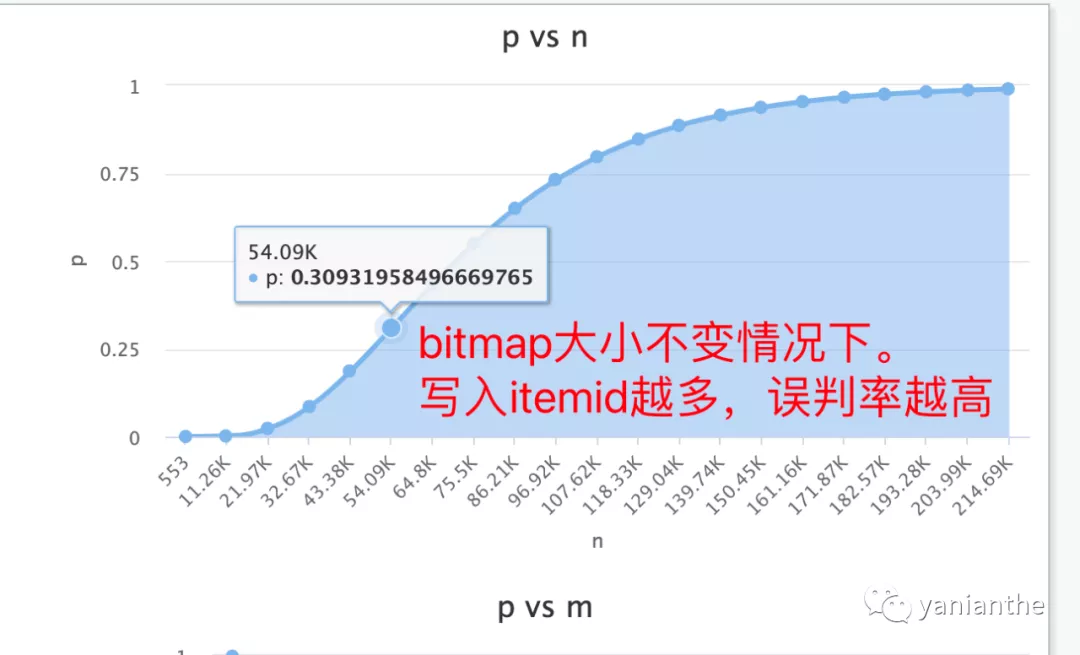
针对bloomfilter 写满的情况,一般情况下是使用多个分片进行切换。
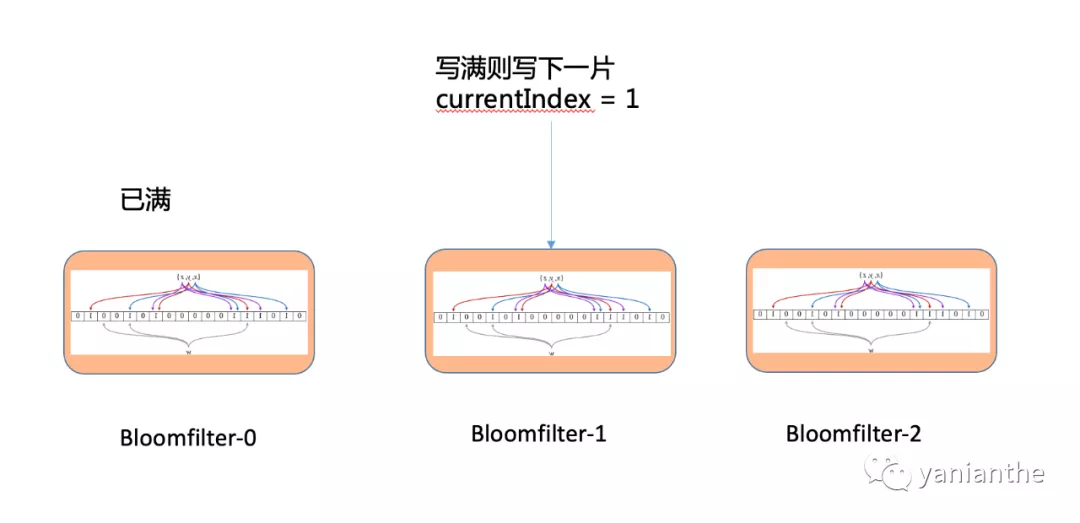
比如每个用户可以保存3片布隆过滤器。使用 currentIndex 记录当前写入哪个分片,比如 0 分片写满,则currentIndex改为1,新增写入1分片。存在与否需要判断 0~currentIndex 之间的所有分片。
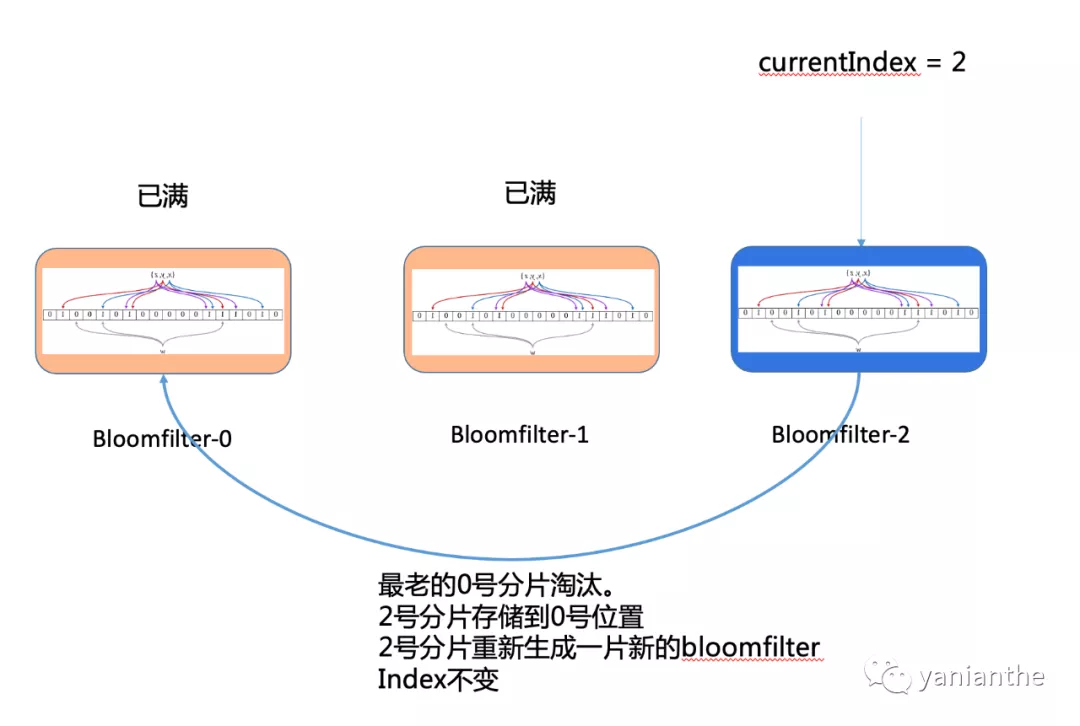
假如所有分片都写满呢? 总不能无限增加分片的吧?
这里具体业务可以斟酌,比如3个分片,总的itemid大小是3万条。都写满了说明用户至少看了3万+,超级重度用户了。这个时候把当前已满的分片,替换到最老的0号分片,2号分片重新初始化即可。这里有2个考量点.
- 重度用户占比低 : 刷满存储的超重度用户在整个系统占比非常小。2. 记忆曲线 : 记忆都看了这么多了,即使把0分片淘汰掉,用户哪里还会记得之前3万个内容推得是啥?
整体流程如下:
4. 灵魂诘问2-还能进一步节约存储吗?
接上小节[3.2bloom写满淘汰](#3.1 写满了怎么办?),我们为了不降低误判率,使用多片bloomfilter进行切换和淘汰。
这无形中,相比单片,又增加了很多存储呀,有没有一些额外的性能优化手段呢?
这里抛砖引玉,介绍下两种工程上常见的优化思路。
4.1 压缩
大部分系统,都遵循二八定律,从轻度和重度用户的活跃度角度上,也是如此。(我瞎拍的,但实际上新浅度用户占比非常高)
这种新重度用户大多也就是体验1-2次产品。bloomfilter 中也就 若干bit 位为1.其余都是0。这种超高的重复率,基本上使用压缩算法,一压一个准。(高压缩比的算法,在这种场景,压缩常常可以节约90%以上)
粗暴简单一些,可以直接使用 常见 的snappy gzip,(考量下压缩比和压缩性能).
大部分系统,做到这个地步也就可以停止了。基本上能够满足功能,性能,存储上的需求了。
但是折腾永无止境。
4.2 自适应-分步法
上面说了,大部分用户的轨迹都是 新用户->浅度用户->中度用户->重度用户->忠实狂热粉。
那么我的去重系统能不能也按照用户的使用习惯,自己慢慢进化,而不是一上来就用最高最强的配置。

4.2.1 “同构自适应法”
同样的,按照新用户的使用深度,我们的布隆过滤器也从小布隆增长到大布隆。针对这种结构相同,布隆过滤器的大小不同,我取了个蹩脚的名字: 同构自适应法。
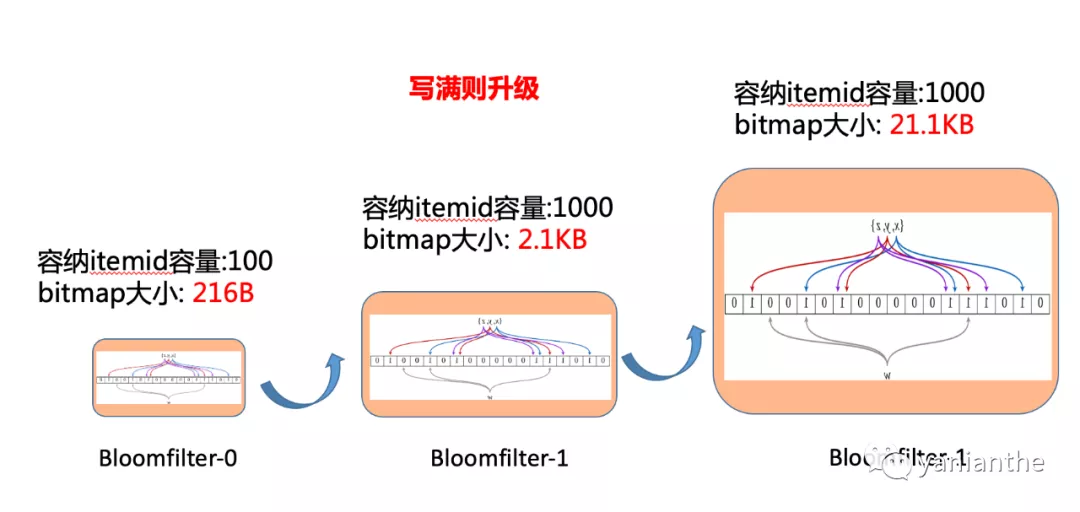
同样的可以设置每个用户有3个分片。用户刚来的时候,初始化1个100容量的bloomfilter(bitmap占约216B)。第一片写满后可以升级为 1000容量的(bitmap占约2.1KB),第二片写满后可以升级为 10000容量的(bitmap占比为21.1KB)。三片都写满后,以后每次初始化就是1万的容量。依次淘汰最老的分片。使用这种做法,能够节约多少存储呢?
假设我�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E7%B3%BB%E5%88%97%E8%AF%A6%E8%A7%A3%E6%9B%9D%E5%85%89%E5%8E%BB%E9%87%8D%E8%AE%BE%E8%AE%A1%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


