推荐系统系列二算法理论与实践
背景
在 CTR/CVR 预估任务中,除了 FM 模型[2] 之外,后起之秀 FFM(Field-aware Factorization Machine)模型同样表现亮眼。FFM 可以看作是 FM 的升级版,Yuchi Juan 于 2016 年提出该模型,但其诞生是受启于 Rendle 在 2010 年发表的另一个模型 PITF [3](FM 也是 Rendle 在 2010 年发表的),其论文原文 [1] 中写道:
The idea of FFM originates from PITF proposed for recommender systems with personalized tags.
在各种深度推荐模型出来之前,FM/FFM 模型在各大推荐相关的竞赛中大放异彩。今天,我们就来好好梳理一下 FFM 的原理以及如何将理论转化为实践。
分析
1. FFM 公式定义
相较于 FM 模型,FFM 模型引入了域(Field)的概念(该想法来源于 PITF [3]),可看做是对特征进行分组。例如,对于性别特征而言,通常有两种取值
 、
、
 。对值进行 one-hot 编码之后性别特征会拆分为两个独立的特征
。对值进行 one-hot 编码之后性别特征会拆分为两个独立的特征
 和
和
 。显然,这两个特征具有共同的性质:都属于性别。所以可以将这两个特征归在同一个 Field 下,即有相同的 Field 编号。不同域的特征之间,往往具有明显的差异性。对比 FM 中的做法,每个特征有且仅有一个隐向量,在对特征
。显然,这两个特征具有共同的性质:都属于性别。所以可以将这两个特征归在同一个 Field 下,即有相同的 Field 编号。不同域的特征之间,往往具有明显的差异性。对比 FM 中的做法,每个特征有且仅有一个隐向量,在对特征
 与其他特征进行交叉时,始终使用同一个隐向量
与其他特征进行交叉时,始终使用同一个隐向量
 。 这种无差别式交叉方式,并没有考虑到不同特征之间的共性(同域)与差异性(异域)。
。 这种无差别式交叉方式,并没有考虑到不同特征之间的共性(同域)与差异性(异域)。
FFM 公式化定义如下:

其中
 为域(Field)映射函数,
为域(Field)映射函数,
 表示为
表示为
 特征对应的 Field 编号。
特征对应的 Field 编号。
将公式(1)对比 FM 可以发现,二者之间的差异仅在于二阶交叉对应的隐向量。设数据集中 Field 的数目为
 ,那么对于每个特征
,那么对于每个特征
 拥有
拥有
 个对应的隐向量,分别应用于与不同域特征进行交叉时。设隐向量维度为
个对应的隐向量,分别应用于与不同域特征进行交叉时。设隐向量维度为
 ,FFM 二阶交叉项参数为
,FFM 二阶交叉项参数为
 。
。
2. 求解
由于引入了 Field,公式(1)不能像 FM 那样进行改写,所以 FFM 模型进行 推断 时的时间复杂度为
 。
。
为了方便推导各参数的梯度,隐向量表示为
 。公式(1)展开:
。公式(1)展开:

当参数为
 时,
时,
 。
。
当参数为
 时,
时,
 。
。
当参数为
 时,其他参数视为常量,只考虑公式(2)交叉项。由于 Field 数量以及映射关系
时,其他参数视为常量,只考虑公式(2)交叉项。由于 Field 数量以及映射关系
 取决于数据集,这种情况参数梯度的数学统一表达式稍微复杂点(但当确定
取决于数据集,这种情况参数梯度的数学统一表达式稍微复杂点(但当确定
 之后很好计算),所以这里就暂且按下不表。
之后很好计算),所以这里就暂且按下不表。
3. 性能评估
上述小节并未得到统一的参数梯度表达式,但估计模型训练时的时间复杂度,仍需评估更新
 参数的时间复杂度。尽管没有梯度公式,但可以通过夹逼定理来确定该参数的更新时间复杂度。两种极端情况:1)
参数的时间复杂度。尽管没有梯度公式,但可以通过夹逼定理来确定该参数的更新时间复杂度。两种极端情况:1)
 ;2)
;2)
 ;参数更新时间复杂度位于二者之间。
;参数更新时间复杂度位于二者之间。
 时,所有特征均属于同一个 Field,此时 FFM 退化为 FM。可以将
时,所有特征均属于同一个 Field,此时 FFM 退化为 FM。可以将
 暂时省略,公式(2)可以表示为
暂时省略,公式(2)可以表示为

有,

所以,更新参数
 所需时间复杂度为
所需时间复杂度为
 。这只是二阶项中
。这只是二阶项中
 个参数中的其中一个,所以更新二阶项参数总时间复杂度为
个参数中的其中一个,所以更新二阶项参数总时间复杂度为
 。
。
2.
 时,每个特征的 Field 都不相同。不失一般性,可以设
时,每个特征的 Field 都不相同。不失一般性,可以设
 ,此时公式(2)可以表示为
,此时公式(2)可以表示为

有,

所以,更新参数
 所需时间复杂度为
所需时间复杂度为
 。这只是二阶项中
。这只是二阶项中
 个参数中的其中一个,所以更新二阶项参数总时间复杂度为
个参数中的其中一个,所以更新二阶项参数总时间复杂度为
 。
。
综上,更新二阶项参数所需时间复杂度为
 ,因为
,因为
 与
与
 参数更新时间复杂度为
参数更新时间复杂度为
 ,所以 FFM 训练的时间复杂度为
,所以 FFM 训练的时间复杂度为
 。
。
总结:FFM 训练/推断 时间复杂度都为
 。
。
4. 优缺点
优点:
- 在高维稀疏性数据集中表现很好。
- 相对 FM 模型精度更高,特征刻画更精细。
缺点:
- 时间开销大。FFM 时间复杂度为
 ,FM 时间复杂度为
,FM 时间复杂度为
 。
。 - 参数多容易过拟合,必须设置正则化方法,以及早停的训练策略。
5. 注意事项
FFM 对于数据集的要求 [1]:
- FFMs should be effective for data sets that contain categorical features and are transformed to binary features.
- If the transformed set is not sparse enough, FFMs seem to bring less benefit.
- It is more difficult to apply FFMs on numerical data sets.
- 含有类别特征的数据集,且需要对特征进行二值化处理。
- 越是稀疏的数据集表现效果相较于其他模型更优。
- FFM 比较难应用于纯数值类型的数据集。
数据预处理 [4]:
与 FM 一样,最好先进行特征归一化,再进行样本归一化。
超参数对于模型的影响 [1]:
首先需要注意的是,FFM 的隐向量维度远小于 FM 的隐向量维度,即
 。
。
- 隐向量维度
 对于模型的影响不大。
对于模型的影响不大。
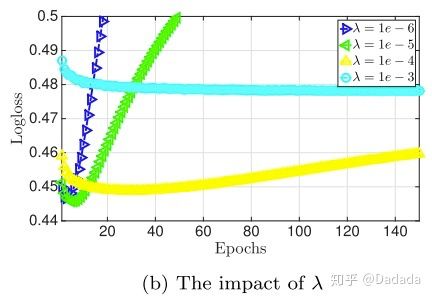
 2)正则化系数
2)正则化系数
 如果太大,容易导致模型欠拟合,反之,容易过拟合。
如果太大,容易导致模型欠拟合,反之,容易过拟合。
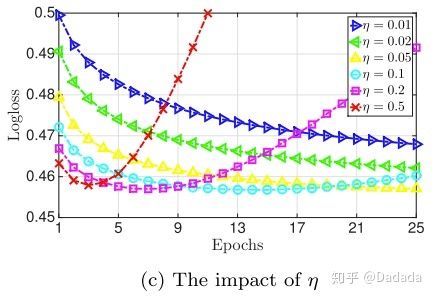
 3)在论文中,使用的是 Adagrad 优化器,全局学习率
3)在论文中,使用的是 Adagrad 优化器,全局学习率
 也是超参数。如果
也是超参数。如果
 在一个较小的水平,则可以表现最佳。过大,容易导致过拟合。过小,容易欠拟合。
在一个较小的水平,则可以表现最佳。过大,容易导致过拟合。过小,容易欠拟合。
 模型训练加速 [1,4]:
模型训练加速 [1,4]:
- 梯度分布计算;2)自适应学习率;3)多核并行计算;4)SSE3 指令并行编程;
实验
与 FM 一致使用
 数据集,将评分大于 3 的样本置为正样本 1,其他置为负样本 0,构造一个二分类任务。使用
数据集,将评分大于 3 的样本置为正样本 1,其他置为负样本 0,构造一个二分类任务。使用
 损失函数,最后使用了
损失函数,最后使用了
 优化算法。
优化算法。
论文中使用的
将样本构造为-1、1 的二分类,同时使用的是
优化算法 [1]
核心代码如下:
|
|
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E7%B3%BB%E5%88%97%E4%BA%8C%E7%AE%97%E6%B3%95%E7%90%86%E8%AE%BA%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


