推荐系统模型的快速线上评估方法
今天我们关注模型的评估和线上测试。有经验的算法工程师肯定非常清楚,在一个模型的开发周期中,占工作量大头的其实是特征工程和模型评估及上线的过程。在机器学习平台已经非常成熟的现在,模型结构的实现和调整反而仅仅是几行代码的事情。所以 如果能够将模型评估和线上 AB Test 的效率提高,那一定是大大解放算法工程师效率的事情。
今天这篇文章我们就介绍一下流媒体巨头 Netflix 的“独门线上评估秘笈”——Interleaving。
周所周知,Netflix 是美国的流媒体巨头,其广为人知的原因不仅是因为其多部知名的原创剧,高昂的市值,在推荐技术领域,Netflix 也一直走在业界的最前沿。那么驱动 Netflix 实现推荐系统快速迭代创新的重要技术,就是我们今天要介绍的快速线上评估方法——Interleaving。
Netflix 推荐系统问题背景
Netflix 几乎所有页面都是推荐算法驱动的,每种算法针对不同的推荐场景进行优化。 如图 1 所示,主页上的“Top Picks 行”根据视频的个性化排名提供推荐,而“Trending Now 行”包含了最近的流行趋势。 这些个性化的行共同构成了 Netflix 将近 1 亿会员“千人千面“的个性化主页。
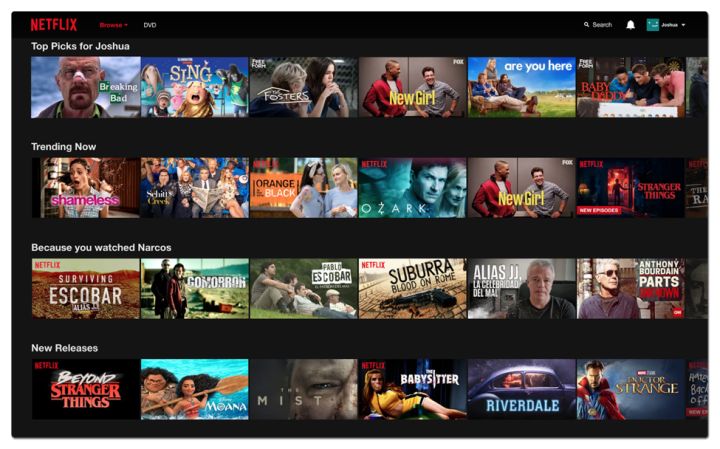
图 1: 个性化 Netflix 主页示例 。 每一行是一个推荐类别,对于给定的行,从左到右的视频排序由特定的排序算法确定。
对于强算法驱动的 Netflix 来说,算法的迭代创新当然是必不可少的。为了通过算法最大化 Netflix 的商业目标(这些商业指标包括每月 用户订阅数、 观看总时长 等等),需要进行大量的 AB Test 来验证新算法能否有效提升这些关键的产品指标。
这就带来一个矛盾,就是 算法工程师们日益增长的 AB Test 需求和线上 AB Test 资源严重不足之间的矛盾。因为线上 AB Test 必然要占用宝贵的线上流量资源,还有可能会对用户体验造成损害,但线上流量资源显然是有限的,而且只有小部分能够用于 AB Test;而算法研发这侧,算法驱动的使用场景不断增加,大量候选算法需要逐一进行 AB Test。这二者之间的矛盾必然愈演愈烈。这就迫切需要设计一个快速的线上评估方法。
为此,Netflix 设计了一个两阶段的线上测试过程(如图 2)。
- 第一阶段利用被称为 Interleaving 的测试方法进行候选算法的快速筛选,从大量初始想法中筛选出少量“优秀的”Ranking 算法。
- 第二阶段是对缩小的算法集合进行传统的 AB Test,以测量它们对用户行为的长期影响。
大家一定已经对传统的 AB Test 方法驾轻就熟,所以这篇文章专注于介绍 Netflix 是怎样通过 Interleaving 方法进行线上快速测试的。
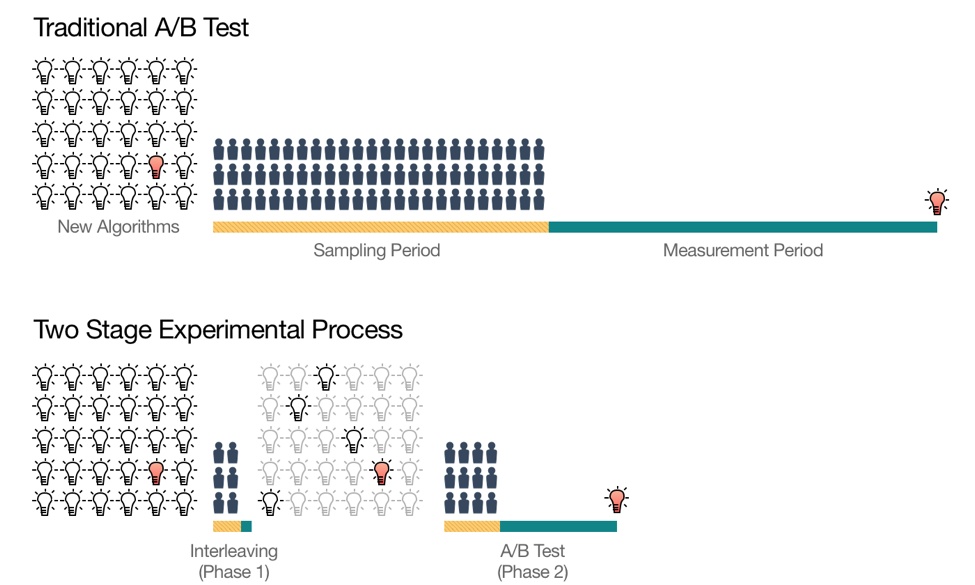
图 2:使用 Inter leaving 进行快速线上测试。 用灯泡代表候选算法。 其中,最优的获胜算法用红色表示。Interleaving 能够快速地将最初的候选算法集合进行缩减,相比传统的 AB Test 更快地确定最优算法。
传统 AB Test 存在的问题
传统的 AB Test 除了存在效率问题,还存在一些统计学上的显著性差异问题。下面用一个很典型的 AB Test 问题来进行说明。
这里设计一个 AB Test 来验证用户群体是否对“可口可乐”和“百事可乐”存在口味倾向。那么按照传统的做法,我们会将测试人群随机分成两组然后进行“盲测”,即在不告知可乐品牌的情况下进行测试。第一组只提供可口可乐,第二组只提供百事可乐,然后根据大家一定时间内的可乐消耗量来观察人们是更喜欢“可口可乐”还是“百事可乐”。
这个实验一般意义上确实是有效的,很多时候我们也是这么做的。但也确实存在一些潜在的问题:
- 总的测试人群中,对于可乐的消费习惯肯定各不相同,从几乎不喝可乐到每天喝大量可乐的人都有。
- 可乐的重消费人群肯定只占总测试人群的一小部分,但他们可能占整体汽水消费的较大比例。
这两个问题导致了,即使 AB 两组之间重度可乐消费者的微小不平衡也可能对结论产生不成比例的影响。
在互联网场景下,这样的问题同样存在。比如 Netflix 场景下,非常活跃用户的数量是少数,但其贡献的观看时长却占较大的比例,因此 Netflix AB Test 中活跃用户被分在 A 组的多还是被分在 B 组的多,将对结果产生较大影响,从而掩盖模型的真实效果。
那么如何解决这个问题呢?一个方法是不对测试人群进行分组,而是让所有测试者都可以自由选择百事可乐和可口可乐(测试过程中仍没有品牌标签,但能区分是两种不同的可乐)。在实验结束时,统计每个人可口可乐和百事可乐的消费比例,然后进行平均后得到整体的消费比例。
这个测试方案的优点在于:
- 消除了 AB 组测试者自身属性分布不均的问题;
- 通过给予每个人相同的权重,降低了重度消费者对结果的过多影响。
这个测试思路应用于 Netflix 的场景,就是 Interleaving。
Netflix 的快速线上评估方法——Interleaving
图 3 描绘了 AB Test 和 Interleaving 之间的差异。
- 在传统的 AB Test 中,Netflix 会选择两组订阅用户:一组接受 Ranking 算法 A 的推荐结果 ,另一组接受 Ranking 算法 B 的推荐结果。
- 在 Interleaving 测试中,只有一组订阅用户,这些订阅用户会接受到通过混合算法 A 和 B 的排名生成的交替排名。
这就使得用户同时可以在一行里同时看到算法 A 和 B 的推荐结果(用户无法区分一个 item 是由算法 A 推荐的还是算法 B 推荐的)。进而可以通过计算观看时长等指标来衡量到底是算法 A 好还是算法 B 好。
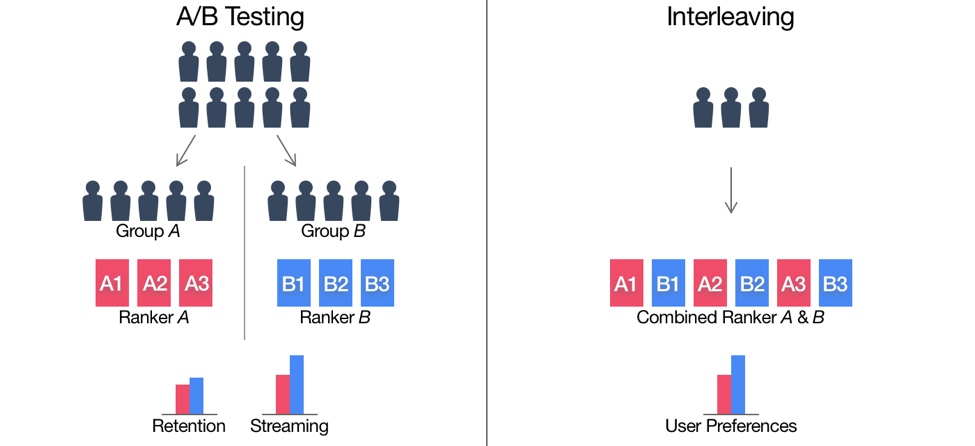
图 3:传统 AB Test 和 Interleaving 在传统 AB Test 中,测试用户分为两组,一组暴露于排名算法 A ,另一组暴露于算法 B,在两组之间进行比较观看时长等核心评估指标。另一方面,Interleaving 将所有测试用户暴露于算法 A 和 B 的混合排名,再比较算法相对应的 item 的指标
当然,在用 Interleaving 方法进行测试的时候,必须要考虑位置偏差的存在,避免来自算法 A 的视频总排在第一位。因此需要以相等的概率让算法 A 和算法 B 交替领先。这类似于在野球场打球时,两个队长先通过扔硬币的方式决定谁先选人,然后在交替选队员的过程。
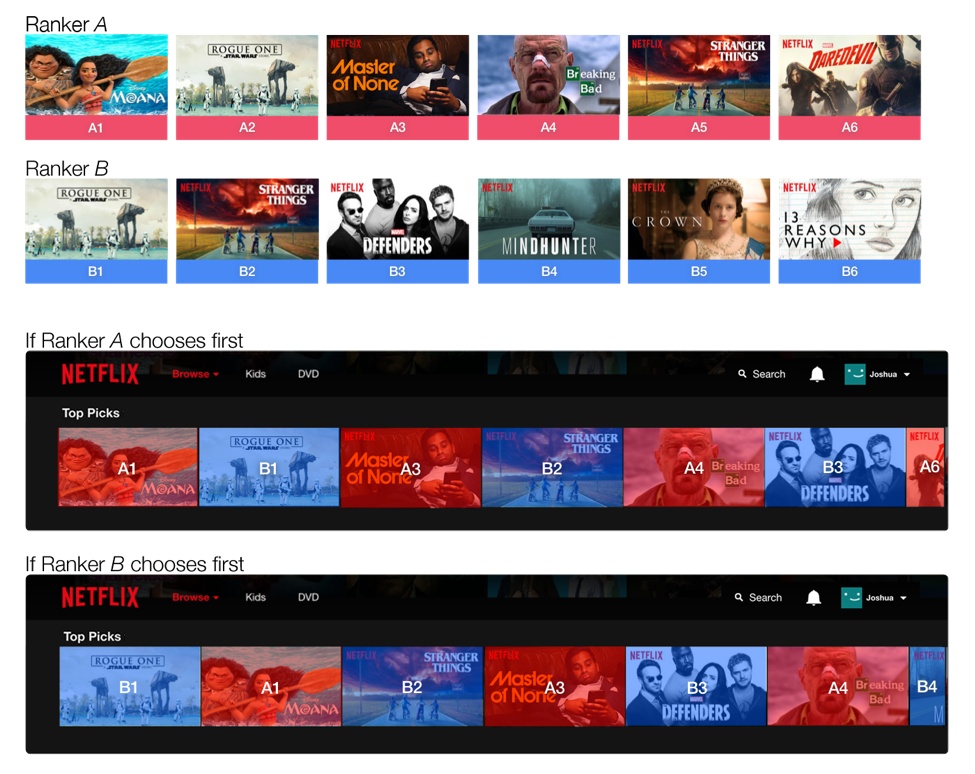
图 4:使用“队长选人”的方式来混合两个排名算法的视频。 ranking 算法 A 和 B 分别产生了推荐视频列表。 通过随机抛硬币确定是 ranking 算法 A 还是 B 贡献第一个视频。然后,轮流从算法 A 和 B 中从高到底选择视频。
在清楚了 Interleaving 方法之后,还需要验证这个评估方法到底能不能替代传统的 AB Test,会不会得出错误的结论。Netflix 从两个方面进行了验证,一是 Interleaving 的“灵敏度”,二是 Interleaving 的“正确性”。
Interleaving 与传统 AB Test 的灵敏度比较
Netflix 的这组实验希望验证的是 Interleaving 方法相比传统 AB Test,需要多少样本就能够验证出算法 A 和算法 B 的优劣。我们之前一再强调线上测试资源的紧张,因此这里自然希望 Interleaving 能够利用较
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E6%A8%A1%E5%9E%8B%E7%9A%84%E5%BF%AB%E9%80%9F%E7%BA%BF%E4%B8%8A%E8%AF%84%E4%BC%B0%E6%96%B9%E6%B3%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


