推荐系统工程难题如何做好深度学习模型线上
这篇文章希望讨论的问题是深度学习 CTR 模型的线上 serving 问题。对于 CTR 模型的离线训练,很多同学已经非常熟悉,无论是 TensorFlow,PyTorch,还是传统一点的 Spark MLlib 都提供了比较成熟的离线并行训练环境。但 CTR 模型终究是要在线上环境使用的,如何将离线训练好的模型部署于线上的生产环境,进行线上实时的 inference,其实一直是业界的一个难点。本篇文章希望跟大家讨论一下几种可行的 CTR 模型线上 serving 方法。
自研平台
无论是在五六年前深度学习刚兴起的时代,还是 TensorFlow,PyTorch 已经大行其道的今天,自研机器学习训练与上线的平台仍然是很多大中型公司的重要选项。为什么放着灵活且成熟的 TensorFlow 不用,而要从头到尾进行模型和平台自研呢?重要的原因是由于 TensorFlow 等通用平台为了灵活性和通用性支持大量冗余的功能,导致平台过重,难以修改和定制。而自研平台的好处是可以根据公司业务和需求进行定制化的实现,并兼顾模型 serving 的效率。笔者在之前的工作中就曾经参与过 FTRL 和 DNN 的实现和线上 serving 平台的开发。由于不依赖于任何第三方工具,线上 serving 过程可以根据生产环境进行实现,比如采用 Java Server 作为线上服务器,那么上线 FTRL 的过程就是从参数服务器或内存数据库中得到模型参数,然后用 Java 实现模型 inference 的逻辑。
但自研平台的弊端也是显而易见的,由于实现模型的时间成本较高,自研一到两种模型是可行的,但往往无法做到数十种模型的实现、比较、和调优。而在模型结构层出不穷的今天,自研模型的迭代周期过长。因此自研平台和模型往往只在大公司采用,或者在已经确定模型结构的前提下,手动实现 inference 过程的时候采用。
预训练 embedding+ 轻量级模型
完全采用自研模型存在工作量大和灵活性差的问题,在各类复杂模型演化迅速的今天,自研模型的弊端更加明显,那么有没有能够结合通用平台的灵活性、功能的多样性,和自研模型线上 inference 高效性的方法呢?答案是肯定的。
现在业界的很多公司其实采用了“复杂网络离线训练,生成 embedding 存入内存数据库,线上实现 LR 或浅层 NN 等轻量级模型拟合优化目标”的上线方式。百度曾经成功应用的“双塔”模型是非常典型的例子(如图 1)。
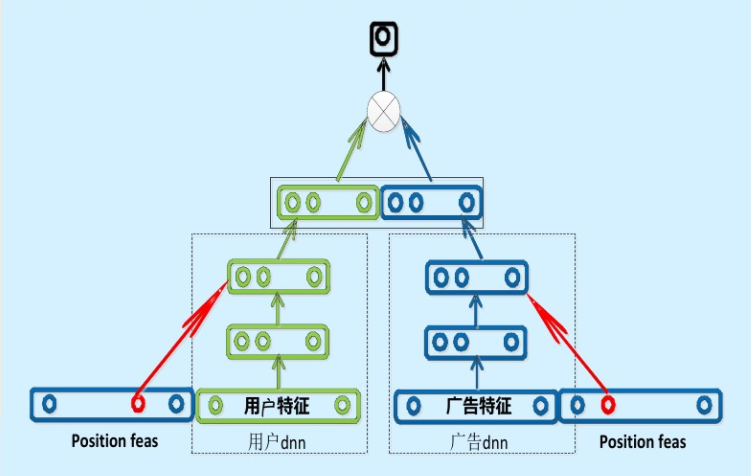
图 1 百度的“双塔”模型
百度的双塔模型分别用复杂网络对“用户特征”和“广告特征”进行了 embedding 化,在最后的交叉层之前,用户特征和广告特征之间没有任何交互,这就形成了两个独立的“塔”,因此称为双塔模型。
在完成双塔模型的训练后,可以把最终的用户 embedding 和广告 embedding 存入内存数据库。而在线上 inference 时,也不用复现复杂网络,只需要实现最后一层的逻辑,在从内存数据库中取出用户 embedding 和广告 embedding 之后,通过简单计算即可得到最终的预估结果。
同样,在 graph embedding 技术已经非常强大的今天,利用 embedding 离线训练的方法已经可以融入大量 user 和 item 信息。那么利用预训练的 embedding 就可以大大降低线上预估模型的复杂度,从而使得手动实现深度学习网络的 inference 逻辑成为可能。
PMML
Embedding+ 线上简单模型的方法是实用却高效的。但无论如何还是把模型进行了割裂。不完全是 End2End 训练 +End2End 部署这种最“完美”的形式。有没有能够在离线训练完模型之后,直接部署模型的方�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E5%B7%A5%E7%A8%8B%E9%9A%BE%E9%A2%98%E5%A6%82%E4%BD%95%E5%81%9A%E5%A5%BD%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%A8%A1%E5%9E%8B%E7%BA%BF%E4%B8%8A/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


