推荐系统中粗排扮演的角色和算法发展历程
以下文章来源于搜索与推荐Wiki ,作者Thinkgamer
1.推荐系统经典的级联架构
其实这里本来写的是「传统」的级联架构,后来思索万千,觉得不太合适,就改为了「经典」。因为级联架构目前依旧在各大互联网公司被应用,其扮演的角色也很重要。一般情况下我们常见级联架构主要是由四部分组成,但依据具体的业务和数据量适当的选择其中若干部分进行应用。
1.1 四部分及角色
四部分指的是:召回 / recall -> 粗排 / prerank -> 精排 / rank -> 重排 / rerank
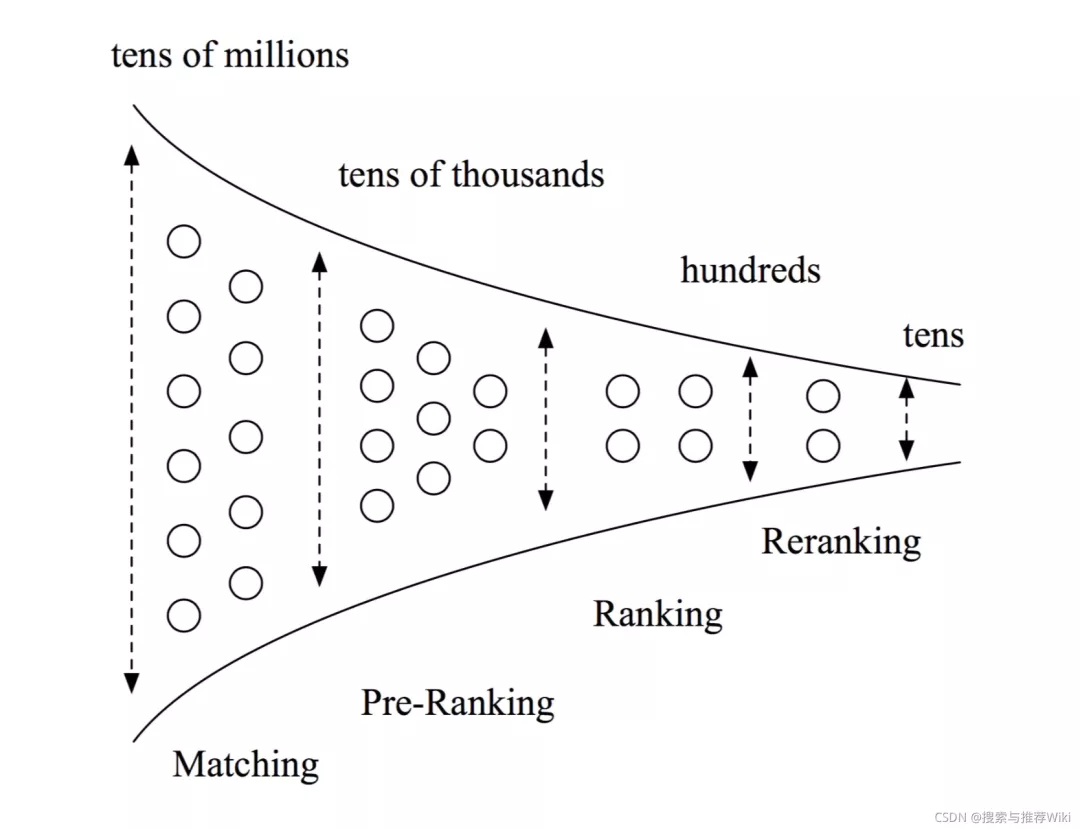 四级级联架构不同的部分所扮演的角色也不相同,每个阶段都在为完成自己的使命而发光发热。
四级级联架构不同的部分所扮演的角色也不相同,每个阶段都在为完成自己的使命而发光发热。
- 召回:负责从最原始的候选集中选出用户感兴趣下一个错别字
- 和可能感兴趣的item,一般集合在几千到1万+,视具体的推荐架构和算力而定
- 粗排:减小精排排序的压力,对召回池中的商品进行排序,选出用户最喜欢的top N个item,N的取值一般是几百
- 精排:从粗排提供的候选池中选出用户最有可能点击的M个item,M的取值一般是几十个
- 重排:从精排返回的结果中进行重新排序,返回给上游接口,继而展示给用户
1.2 结合业务数据选择模块
在前边也提到,这样的四级级联架构并非是所有推荐业务的必须选择,因为业务的特性和item的规模都是不一样的,因此在制定技术方案时不一定要严格遵循召回->粗排->精排->重排的流程,而是结合业务选取若干部分,具体大家可以看下面举的案例。
eg 1:一个精选品电商业务,所有的item只有几千个,这时候可以跳过召回,直接全部item进粗排,然后是精排和重排
eg 2:传统的电商平台,所有的item数以亿计,这时候召回阶段是跳不过的,就需要走召回->粗排->精排->重排的流程(或者是召回 -> 精排 -> 重排,需要严格限制召回的数量)
eg 3:一个新的电商业务初期,数据比较少,能够构造的特征也比较少,这时候就可以抛弃传统的四部分级联架构,直接由cf得到的结果也是可以接受的
所以并非严格遵循流程就是好的,适当的时候也要变通和尝试,结合业务才能做出好的效果。
2.对粗排阶段的思考
粗排在推荐系统中扮演的角色是精排的前置阶段,其目标理论上应该和精排是一致的,这样能保证精排从粗排返回的结果中选出的top M一定是结果最优的。
2.1 粗排是必要的吗?
粗排是不是必要的?伴随这个问题的还有召回是不是必要的?精排是不是必要的?重排是不是必要的?
不同的业务、不同的发展阶段,甚至可以说召回、排序都可能不是必须的。粗排当然也不是在所有业务、所有阶段都是必须的。
分发物料少的业务,可以不用召回,精排模型打分就可以了;推荐架构刚刚搭建,甚至连内容标签都没有的阶段,多维度的特征无法建立的时候,也许只有协同召回的效果也是能接受的。同样,粗排是在发展到一定的阶段之后,有很多路不同维度召回,而且精排模型又已经达到一个很复杂很精细程度的时候,是夹在召回和精排中间的“折中”的产物。重排则是为了更大程度的保证用户体验,从而提高效果的一种手段,当前几个阶段都没有建立完整的链条时,又何必花费大力气去建设精排呢!
2.2 粗排与精排的异与同
粗排和精排在一定程度是相同的,至少目标是一致的,但是也存在一些差异。同:
- 目标一致:选出用户最感兴趣的top M、top N
- 特征一致:使用的特征粗排应该是精排的子集(选取区分度比较高的特征),或者大部分特征是一致的
- 技术栈相同:比如精排是DNN,粗排一般也采样DNN,这样精排上验证有效的策略可以容易的迁移到粗排模型(但并不是一定要相同,主要看个人而定)
异:
- 量级不同:粗排因为是精排的前置阶段,所以粗排一般接受几千或者1万+的item进行排序,而精排则接受几百个商品进行排序
- 延时要求不同:因为粗排和精排打分的item量级不一致,所以精排对延时的要求比粗排更加严格
- 特征不同:精排特征比粗排特征更细,更加丰富
2.3 粗排与召回的差异
比如以DSSM为例,它作为召回和作为粗排模型,做法一样吗?
目的不一样,样本构造不一样。作为召回,它要不遗漏,它可以从全库item中负采样。作为粗排,它要准确,要接近精排,它的可以用线上的曝光的负样本,或者从全体召回候选中负采样。
像一些其他的召回方法是被严格限制在了召回阶段,是没有办法应用于粗排的,比如CF、标签召回等。
另外一个例子,当算力满足粗排可以对全库的item进行打分时,是否需要保留召回模块?答案:是。
因为召回有一个隐藏的任务: 弥补排序的“贪婪”,限制排序模型对眼前的欲望,留点机会后面有潜力的item,不能只给排序模型它喜欢的item,即保证结果的多样性 。否则就会让用户陷入信息茧房,让用户觉得全世界都是我的!
2.4 粗排的优缺点
我们先假定推荐系统的级联架构只有:召回 -> 精排 -> 重排,且精排可以接受的排序量为1000。
那么当构建若干召回通路时,各路召回的quota怎么控制?各路召回孰轻孰重?这时候就需要引入粗排来对各路召回的item进行统一打分和度量了(因为每路召回中的分值是不可比的)。同时因为召回为了保证多样性,召回的item量级是要比精排能够接受排序的量级大一些的,复杂的精排模型增加排序量会使得响应时间线性增大,于是我们需要一个简单有效、性能优良的模型来完成这一工作,这就是粗排模型。
也可以在召回层面控制进入精排的item数量,比如设置一个总的quota和各路召回的权重,然后进行各路quota的动态分配。
但是粗排使用不当也会带来很大的问题:
- 对于新增的召回源,因为模型的选择偏差,对这一路并不友好
- 当粗排和精排一致性差的时候,会拉低线上效果。即精排认为好的,粗排都没有排上来
3.粗排技术的发展
目前粗排模块一般使用的都是精准值预估的方法,即以业务导向为目标,预测出具体的数值,进行排序和截断,选取Top N送往精排。
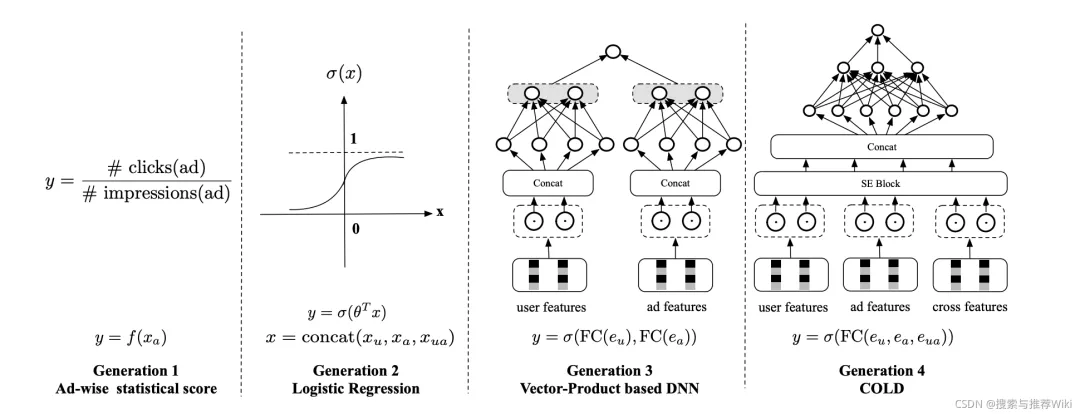 粗排技术发展### 3.1 静态的“质量分”
粗排技术发展### 3.1 静态的“质量分”
一般情况下,算法团队都会为所有的item构建一个综合指标,离线评估这个item的好坏,大家一贯的称呼都是质量分,当然也有别的称呼,不过其表达的含义都是一样的。
需要注意的是这个质量分是静态的,T+1更新的,因此在使用了没有办法去考虑item当天的数据,但是由于其已经是离线计算好的,因此在性能上会很快。
除了离线质量分,也可以使用离线过去制定时间周期内的CTR、CVR、CXR等
3.2 机器学习模型
早期的则是逻辑回归(Logistics Regression,LR),因为其模型简单和有一定的模型表达能力,可以进行在线的更新和模型打分,因此应用十分广泛。
后期则是演变到了以GBDT为代表的树模型,相比LR,其个性化表达能力更加突出,结构简单,成为了各大公司的排序宠儿。
再往后则是GBDT的演进版,XGB、Light GBM、GBDT+LR等技术,但其都是属于机器学习模型时代的优秀产物,其都是先在精排侧取得了不错的效果之后,过渡到粗排模型的。
3.3 基于向量内积的深度模型
基于向量内积的深度模型是目前应用最广泛的粗排模型,一般为双塔结构,两侧分别输入用户特征和item特征,经过深度网络计算后,分别产出用户向量和item向量,再通过内积等运算计算得到排序分数:
score = \sigma (v_u ^T * v_i)
其中典型代表为DSSM,关于DSSM的介绍可以参考: 论文|从DSSM语义匹配到Google的双塔深度模型召回和广告场景中的双塔模型思考。
3.3.1 经典的向量内积模型-以DSSM为例
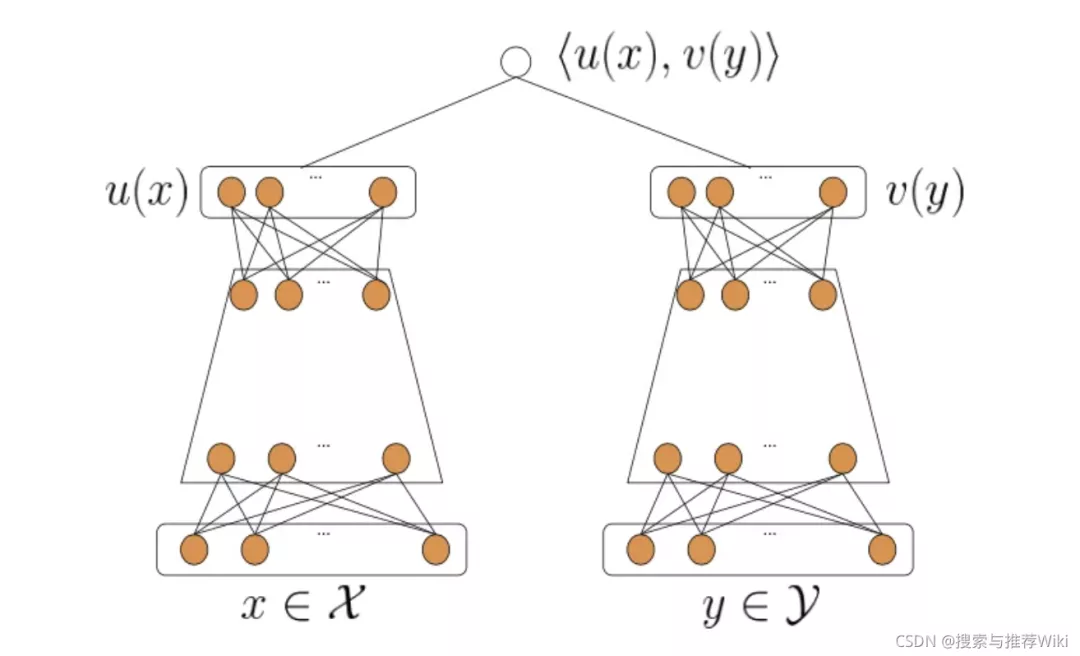 双塔网络双塔模型,两侧输入的分别是user的特征和item的特征,各自经过DNN变化后分别产出user向量和item向量。
双塔网络双塔模型,两侧输入的分别是user的特征和item的特征,各自经过DNN变化后分别产出user向量和item向量。
向量内积模型相比之前的粗排模型,表达能力有了很显著的提升,其优点:
- 内积计算简单,节省线上打分算力
- item向量离线计算产出,user向量实时计算,然后进行实时向量检索
- 双塔结构的user侧网络可以引入transformer等复杂结构对 用户实时行为序列 进行建模
但是也存在一些缺点,比如:
- 模型表达能力仍然受限:向量内积虽然极大的提升了运算速度,节省了算力,但是也导致了模型无法使用交叉特征,能力受到极大限制
- 模型实时性较差:item向量一般需要提前计算好,而这种提前计算的时间会拖慢整个系统的更新速度,导致系统难以对数据分布的快速变化做出及时响应,这个问题在双十一等场景尤为明显
- 存在冷启动问题,对新item、新用户不友好
- 迭代效率:user向量和item向量的版本同步影响迭代效率。因为每次迭代一个新版本的模型,分别要把相应user和item向量产出,其本身迭代流程就非常长,尤其是对于一个比较大型的系统来说,如果把user和item都做到了上亿的这种级别的话,可能需要一天才能把这些产出更新到线上,这种迭代效率很低
因此就基于传统的双塔模型进行很多改进,比如双塔版本的Wide&Deep模型。
3.3.2 双塔版本的Wide&Deep模型
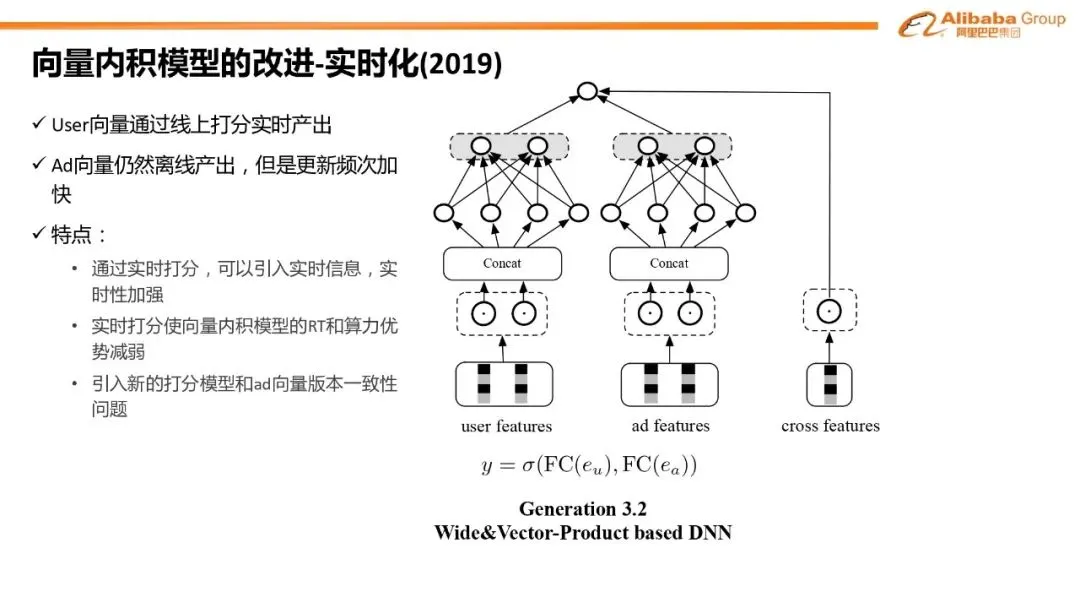 上图来自于王哲老师在DataFun的分享,没在网络上找到对应的论文,应该是其内部的实践。
上图来自于王哲老师在DataFun的分享,没在网络上找到对应的论文,应该是其内部的实践。
向量版Wide&Deep模型,deep部分仍然是向量内积结构,wide部分引入基于人工先验构造的user和item的交叉特征,一定程度上克服了向量内积模型无法使用交叉特征的问题。然而该方法仍然有一些问题,wide部分是线性的,受限于RT的约束,不能做的过于复杂,因此表达能力仍然受限。
3.3.3 双塔模型引入SeNet网络
这个主要采用的还是双塔网络结构, 在user塔和item塔侧各自引入一个SeNet模块,参考: SENet双塔模型在推荐领域召回粗排的应用及其它。
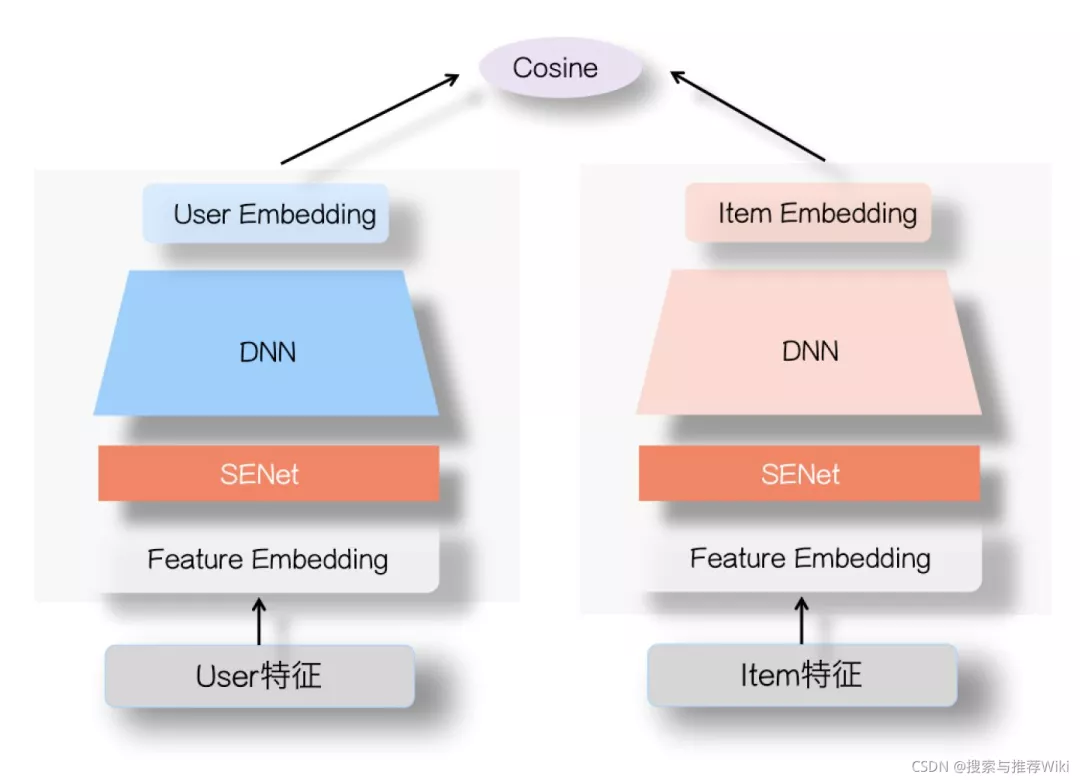 SeNet### 3.4 阿里粗排COLD框架
SeNet### 3.4 阿里粗排COLD框架
COLD框架目前在其他公司应用的比较少,大多数还是基于向量内积的深度模型来计算打分的。COLD模型的结构如下:
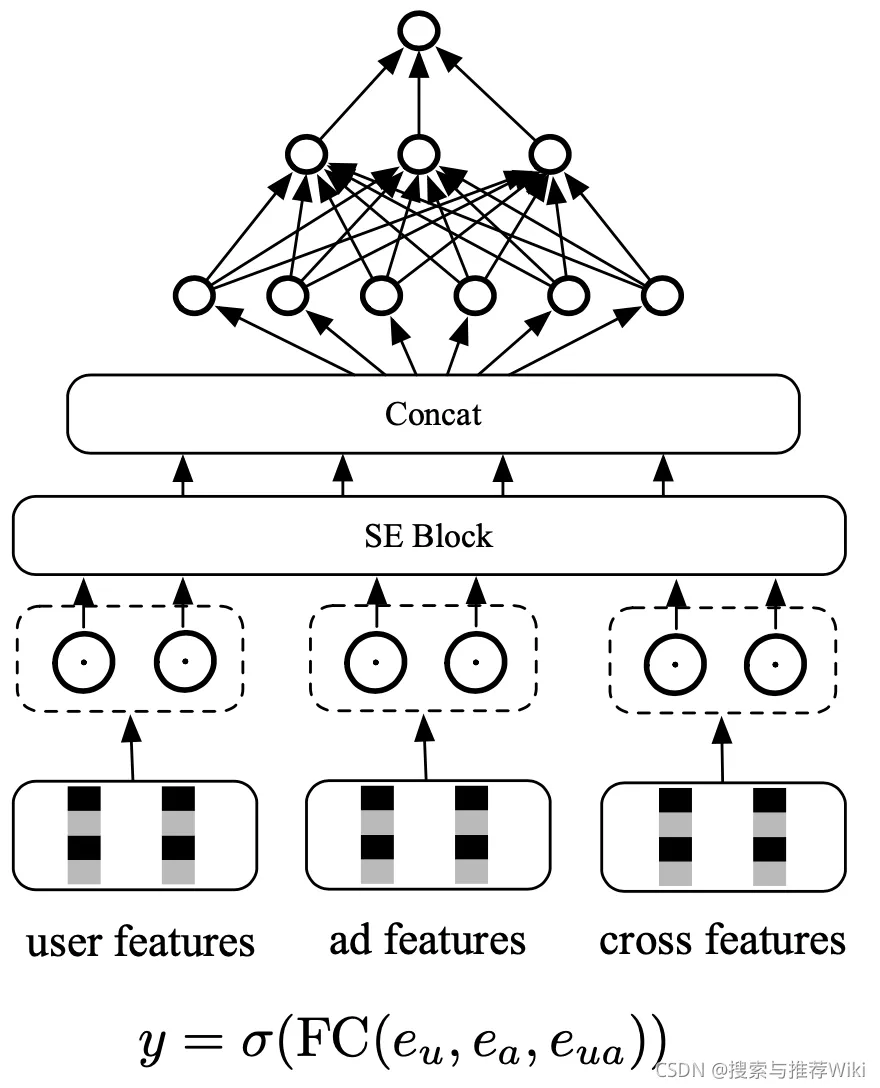 COLD框架因为其在工程架构层面也进行了很多的优化,最终取得了不错的效果,工程的优化主要包括:
COLD框架因为其在工程架构层面也进行了很多的优化,最终取得了不错的效果,工程的优化主要包括:
- 将计算分成并行的多个请求以同时进行计算,并在最后进行结果合并
- 将行计算重构成列计算,对同一列上的稀疏数据进行连续存储,之后利用MKL优化�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E4%B8%AD%E7%B2%97%E6%8E%92%E6%89%AE%E6%BC%94%E7%9A%84%E8%A7%92%E8%89%B2%E5%92%8C%E7%AE%97%E6%B3%95%E5%8F%91%E5%B1%95%E5%8E%86%E7%A8%8B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


