推荐系统中的长尾物品推荐问题方案
炼丹笔记干货 作者:九羽
长尾物品(Tail Items)在推荐系统中是非常常见的,长尾的存在导致了样本的不均衡,对于热门头部物品(Head Items)的样本量多,模型学习这部分的效果越好,而长尾物品的样本量少,导致模型对该部分Item的理解不够充分,效果自然也就较差。
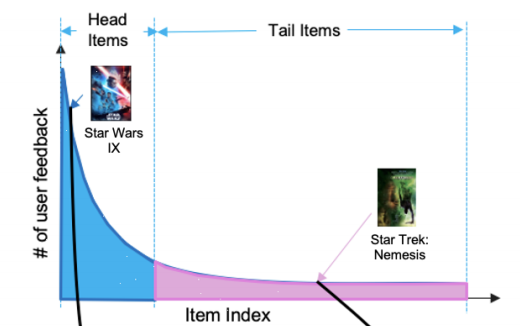
那么,针对长尾物品的推荐,有哪些较好的解决方法呢?本文从几个角度来聊一下这个问题。长尾问题,可以看成是推荐系统倾向于推荐热门商品,而忽略了非热门物品,即推荐系统如何解决纠偏问题?
Bias/Debias思路

在实践中,做推荐系统的很多朋友思考的问题是如何对数据进行挖掘?大多数论文致力于开发机器学习模型来更好地拟合用户行为数据。然而, 用户行为数据是观察性的,而不是实验性的。这里面带来了非常多的偏差,典型的有: 选择偏差、 位置偏差、 曝光偏差 和 流行度偏差 等。如果不考虑固有的偏差,盲目地对数据进行拟合,会导致很多严重的问题,如线下评价与在线指标的不一致,损害用户对推荐服务的满意度和信任度等。下面我们聊一下与长尾问题相关的两个偏差。
01 曝光偏差
曝光偏差的发生是因为 用户只接触到特定项目的一部分,因此未观察到的交互并不总是代表消极偏好。特殊地,用户和商品之间未被观察到的交互可以归因于两大原因:
1)商品与用户兴趣不匹配;
2)用户不知道该商品。
因此,在解释未观察到的相互作用时会产生歧义。无法区分真正的消极互动(如暴露但不感兴趣)和潜在的积极互动(如未暴露)将导致严重的Bias。
解决方法:
目前处理该问题的策略主要还是使用inverse propersity score。为了解决这个问题,类似于外显反馈数据中的选择偏差处理,Yang等人建议用隐式反馈数据倾向的倒数来加权每个观测值。intuition是把经常观察到的交互降权,而对少的样本进行升权。
为了解决曝光偏差的问题,传统的策略就是将所有被观测的交互作为负例并且明确它们的交互。confidence weight可以被分为三类:
1.Heuristic:典型的例子是加权的矩阵分解以及动态MF,未观测到的交互被赋予较低的权重。还有很多工作则基于用户的活跃度指定置信度等,但是赋予准确的置信权重是非常有挑战的,所以这块依然处理的不是非常好。
2.Sampling:另一种解决曝光bias的方式就是采样,经常采用的采样策略有均匀的负采样,对于流行的负样本过采样,但是这些策略却较难捕捉到真实的负样本。
3.Exposure-based model:另外一个策略是开发基于曝光的模型,这样可以知道一个商品被曝光到某个用户的可能性等。
02 流行度偏差
热门商品的 推荐频率甚至超过了它们的受欢迎程度。长尾现象在推荐数据中很常见:在大多数情况下,一小部分受欢迎的商品占了大多数用户交互的比例。当对这些长尾数据进行训练时,该 模型通常会给热门项目的评分高于其理想值,而只是简单地将不受欢迎的商品预测为负值。因此,推荐热门商品的频率甚至比数据集中显示的原始受欢迎程度还要高。
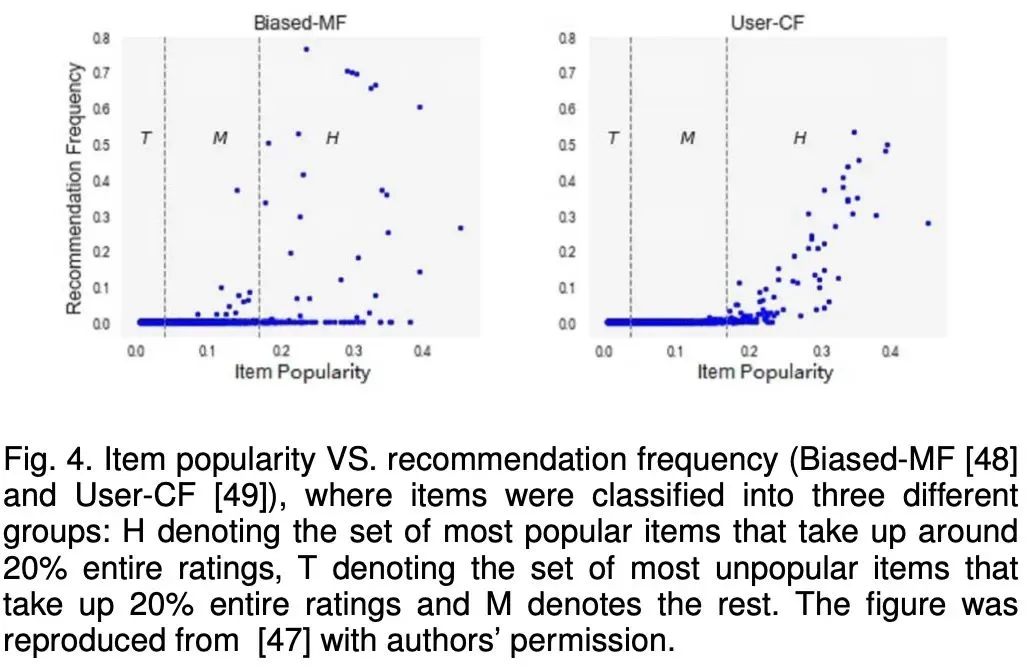
忽略流行度经常会带来非常多的问题:
(1) 降低个性化 的程度影响,影响用户的体验;
(2) 降低了推荐系统的 公平性, 流行的商品却不一定是高质量的, 对流行商品的推荐会降低其它商品的曝光,这是不公平的;
(3) Popular Bias会增加流行商品的曝光率, 使得流行的商品越加流行,使模型训练更加不平衡;
另外一个不平衡的问题的原因是由于推荐结果的不公平带来的。基于诸如种族、性别、年龄、教育程度或财富等属性,不同的用户群体通常在数据中不平等地表示。在对这些不平衡数据进行训练时,模型很可能学习这些表示性过高的群体,在排名结果中对其进行强化,并可能导致系统性歧视,降低弱势群体的可见度(例如,代表少数群体不足、种族或性别陈规定型观念)。
解决方法:
解决流行度偏差的方案有四类:
1.正则
合适的正则可以将模型推向平衡的推荐列表。
CTR预估场景下,构造的模型越复杂参数越多,越容易过拟合。实际场景中,存在着大量的长尾数据,这些数据的存在一方面在训练过程中增加了复杂度,另一方面在结果上产生了过拟合。直接去掉这些长尾数据是一种简单的处理方式,但也丢掉了很多信息。因此,DIN文章中给出了自适应正则化调整的方式( Adaptive正则化方法),对高频减小正则,对低频增大正则。
2. 对抗训练
基本思路在推荐G以及引入的adversary D进行min-max博弈,这样D可以给出提升推荐锡惠的信号。通过G和D之间的对抗学习,D学习流行项和利基项之间的隐式关联,G学习捕捉更多与用户历史相关的niche商品,从而为用户推荐更多长尾商品。
3. Causal graph
因果图是反事实推理的有力工具。Zheng等人利用因果推理解决流行偏差。他们假设用户对商品的点击行为取决于兴趣和流行程度,并构建了一个特定的因果图。为了解决用户兴趣和流行偏差的问题,作者考虑了两种嵌入方法:兴趣嵌入以捕获用户对商品的真实兴趣,以及流行度嵌入来捕获由流行度引起的伪兴趣。在多任务学习的框架下,可以利用特定原因的数据对这些嵌入进行训练。最后,兴趣嵌入将被用于最终推荐,在这里,受欢迎度偏差已经被消除。
4. 其它方法
通过引入其它side information来降低流行度的偏差, propensity score也可以被用来做popularity的bias。通过降低流行项对模型训练的影响,可以减轻流行偏差。
迁移学习思路

由于大多数现有推荐系统中的的长尾模型只关注尾部,而没有考虑与头部们的联系—头部包含丰富的用户反馈信息和与尾部相关的可转移上下文信息。为了改进长尾问题,谷歌进行了 将知识从头部转移到尾部 的研究,提出了一个新的对偶迁移学习框架,它可以从模型层和物品层协同学习知识迁移,利用了头部中丰富的用户反馈以及头尾部之间的语义联系。
01 对偶迁移学习方法
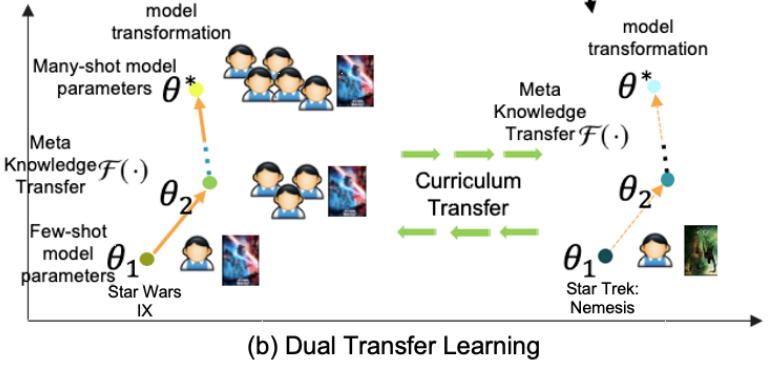
(1)橙色部分学习通用的元迁移器;
(2)绿色部分学习Item之间的语义关系;
02 模型结构
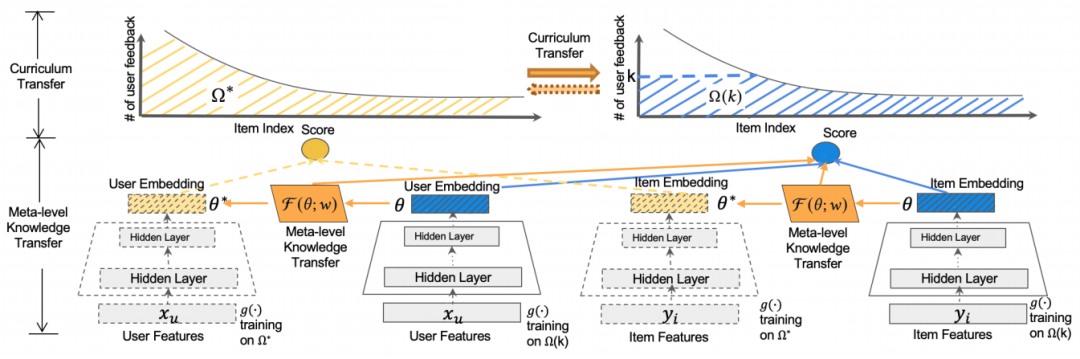
模型探究 使用少量训练样本学习的模型 与相同物品 使用足够训练样本学习的模型 之间的联系。
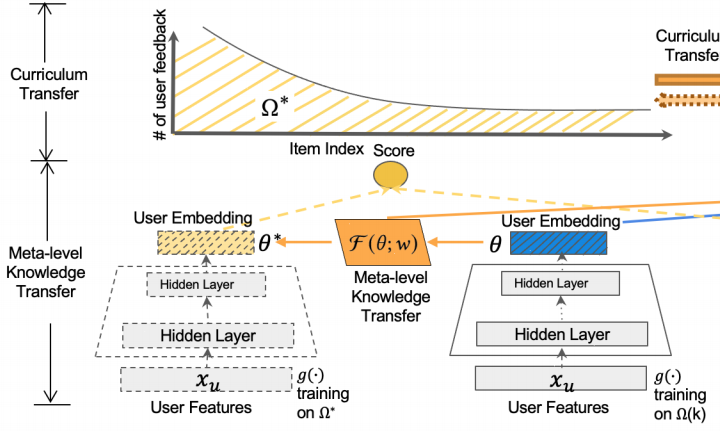
Base-Learner: 通过双塔模型得到的user embedding和item embedding,然后使用内积的方式得出预测的Score。
Meta-Learner:通过基学习器得到few-shot模型和many-shot模型之后,利用元学习器映射两个模型的参数,从而捕捉元级知识。
KDD Cup 冠军思路

在KDD Cup2020中,美团技术团队给出了基于时间加权和图的解决方案,大概思路如下:
针对选择性偏差和�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E4%B8%AD%E7%9A%84%E9%95%BF%E5%B0%BE%E7%89%A9%E5%93%81%E6%8E%A8%E8%8D%90%E9%97%AE%E9%A2%98%E6%96%B9%E6%A1%88/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


