技术文本表征模型在风控场景下的应用实践
周思丞 58技术

01 导语
本文介绍了文本表征算法在58信安场景下的探索和实践。信息安全场景下业务种类繁多,在对用户发帖内容进行审核时,通过对文本建模得到其表征,既可以用于对文本的直接分类算法,也可以通过聚类算法快速得将文本信息归类。
02 背景
58集团业务线广泛,平台每日会产生千万量级以上的非结构化文本数据,如租房、买房的发帖数据,找工作的招聘数据,58同镇的社交类数据。高效的利用这些数据可以更好多对各个业务场景进行赋能。通过文本的语义表征能力可以将文本数据向量化,在下游的业务中可以直接采用本文表征进行更加细粒度的操作,例如直接对文本的语义表征进行分类,或者通过相似度计算的方式对帖子进行召回,再或通过文本相似度构建用户关系图谱。目前信息安全部在多个安全治理工作中应用了文本表征能力,根据业务场景的需要实践了多种类型表征算法,并根据痛点问题进行了探索优化。
03 基于词向量的文本语义表征模型
利用词向量加权得到文本表征的方法是一种非常简单但是有效的句子向量表示算法。基于词向量的方法的主要计算流程如图所示:

图1 基于词向量的文本表征计算流程
首先,通过分词算法将文本预料切分成词的集合,去除掉句子中存在的停用词,并计算每个词算的bm25权重分值。

拿到bm25分值后,选择分值topn的token,然后利用word2vec[1]、GloVe[2]和fastText[3]等词向量对单词进行表征训练,但考虑到词向量的表征能力与训练语料的丰富程度有关,因此采用了腾讯开源的词向量表征数据,该词向包括了800w条200维的中文词条,涵盖了绝大部分业务中出现的单词。最终文本表征的计算方式下:
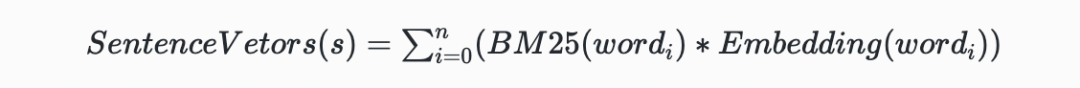

表1 招聘业务场景下文本表征示例
表1为基于词向量的文本表征的示例。在获取句子表征之后,我们在文本涉黄招聘数据集上进行分类实验评测,结果如下:

表2 基于词向量文本表征在分类场景下的效果
采用词向量表征的方式相较于训练的TextCNN[4]模型效果有略微的下降,由于算法的结构简单,在其他的业务场景下直接修改训练目标即可完成分类模型构建。但在风控场景下,除了对发帖数据直接进行判别之外,另一个重要的场景是对用户发帖内容进行聚类。考虑到基于词向量的建模比较粗糙,文本表征可能会受到部分非关键信息的词语影响,例如:

表3 基于词向量文本表征的badcase分析
这类的badcase由于个别词发生变化,导致原本语义比较相似的query计算得到的相似度并不高,因此在我们用户发帖内容聚类的业务场景下,当前的表征能力十分有限。如果想要能够得到包含语义信息更丰富的文本表征,我们需要考虑通过采用更加细粒度的模型进行建模。
04 基于预训练的文本语义表征模型
近些年来,各种bert系的预训练模型层出不穷,其采用海量文本数据预训练的方式,能够使得模型学习到更多语言知识。其中,roberta[5]模型通过采用的动态mask language model训练任务,更大的batch_size,同时去除了效果不明显的nsp任务。相比于bert,在下游的任务中能取得更好的效果。
bert系模型学习mlm任务是比较充分的,能够学习token之间的相关性信息。但在做句子级文本表征时,由于存在高频词和低频次的差异,经过mean-pooling后的句子表征在空间中是非平滑的[6],从而并不能通过直接的相似度计算来衡量文本间的相似度。因此我们需要基于业务类型的需求,针对句子级别的表征设置更合理的finetune任务,来使得句子表征更合理。
1. 基于SimBert的文本语义表征模型
根据通常的预训练模型的使用流程,我们第一时间会想到的采用有监督数据来微调模型,但在处理文本表征任务时,如何设计合理的下游任务则成为了关键。simbert[7]是目前通过有监督方式获取语义相似度的一种有效的解决方案,同时我们将bert模型换成了效果更好的roberta模型。训练语料是基于业务标注的相似句对,通过一句来预测另一句的相似句生成任务来构建Seq2Seq部分,然后[CLS]的向量事实上就代表着输入的句向量,所以可以同时用它来训练一个检索任务,如下图:
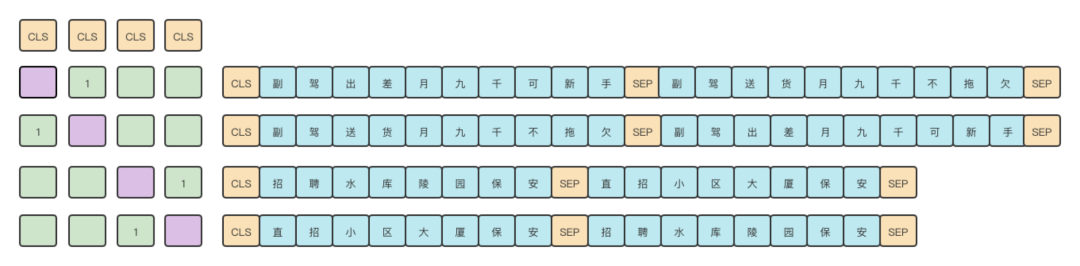
图2 SimBert模型输入示例
为了能够训练出更加精准的文本语义表征模型,需要审核人员根据业务治理需求标注100k的相似发帖数据。首先,在同一个batch中,将相似句“副驾出差月九千可新手” 和 “副驾送货月九千不拖欠”按照[CLS]SENT_a[SEP]SENT_b[SEP]和[CLS]SENT_b[SEP]SENT_a[SEP]分别加入进去。设计两个训练任务,相似句生成任务和相似句分类任务。
相似句生成任务是通过Seq2Seq模型,从SENT_a生成SENT_a。SENT_a内部做self-attention学习到句子本身的表征,SENT_a和SENT_b之间做attention,学习额外的句子信息。句子分类任务则是把batch中[CLS]向量拿出来得到一个句子向量的矩阵,然后对d维度做归一化,然后和转置后的矩阵做内积得到的相似矩阵,并mask对角线上的位置,作为一个分类任务训练,每个样本的目标标签是它的相似句。本质上是将batch内所有的非相似样本都当作负样本,借助softmax来增加相似样本的相似度,降低其余样本的相似度。
最终我们采用招聘发帖相似内容召回作为验证方案,同时对roberta最后一层(last-avg)和最后一层加第一层(last-first-avg)得到的mean-pooling句向量进行了对比实验,得到结果如下:

表4 招聘发帖内容召回准确率在SimBert的模型效果
相对于加权词向量的方式,有监督的simbert明显能够学习到一些相似文本间的特征,效果更好。但我们也发现了问题,simbert的开源的训练预料明显内容更为相似,可以进行Seq2Seq的文本生成任务。而在我们业务上难以标注这样相似的数据,例如图2中的相似句子,让模型去做生成任务确实存在着极高的难度,很可能只有检索任务对模型的效果。因此,我们把生成任务去掉后进行试验:
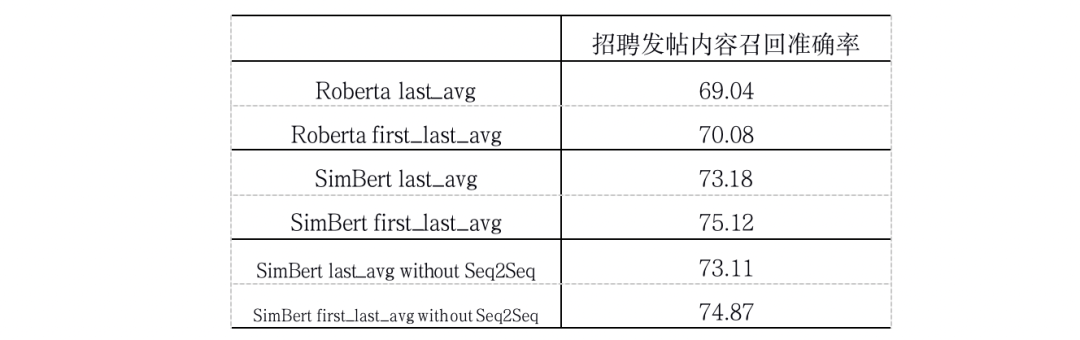
表5 招聘发帖内容召回准确率在SimBert-without-Seq2Seq的模型效果
实验证明去掉Seq2Seq任务后,文本召回准确率仅有小幅下降,这就说明的确生成任务并不适合我们的业务,simbert模型中只有检索式任务发挥了功效。那么如何才能进一步提升呢?
2.基于对比学习的文本语义表征模型
利用有监督数据来微调参数虽然能够取得比较优异的效果,但是获取大量的标注语料是十分困难的。对于信息安全场景下,刷单、刷钻等黑产相似内容的判定需要专业的人员来进行判断,因此标注的人工成本也是十分高昂的。对比学习是近些年来十分火热的研究�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8A%80%E6%9C%AF%E6%96%87%E6%9C%AC%E8%A1%A8%E5%BE%81%E6%A8%A1%E5%9E%8B%E5%9C%A8%E9%A3%8E%E6%8E%A7%E5%9C%BA%E6%99%AF%E4%B8%8B%E7%9A%84%E5%BA%94%E7%94%A8%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


