技术改进的在文本分类中的应用

作者:杨森
01 导读
语音是58同城用户之间的重要沟通媒介,58同城C端用户和B端用户之间可以通过电话(隐私通话)、网络音视频通话(微聊)建立连接,这些场景下产生的语音数据有巨大的挖掘价值。本次议题主要分享语义标签的文本挖掘技术,首先介绍使用主动学习技术解决冷启动时样本少的问题,然后对比了关键词匹配、XGBoost、TextCNN等模型的效果,最后提出了一种改进的Wide&Deep模型,在我们的场景下取得了最优效果。
02 背景
58同城是国内最大的综合信息分类平台,主要涉及房产、招聘、汽车、本地服务四大老牌业务。平台连接着海量的B端的商家和C端用户,B端商家可以在58平台上发布房源、职位、车源、生活黄页等各类信息(帖子),平台将这些帖子分发给C端用户供其浏览,帮助不同业务下的B端商家获取目标用户,同时帮助C端用户获得更好的生活服务。
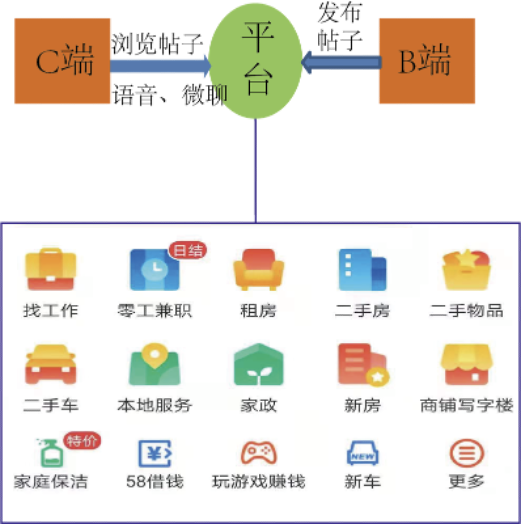
图 1 58同城平台
语音是58同城用户之间的重要沟通媒介,58同城用户之间可以通过电话、网络音视频语音建立连接。在58同城有3大语音场景:呼叫中心平台、电话平台和微聊场景。这些场景下产生大量语音数据,有巨大的挖掘价值。比如,在呼叫中心平台场景下,有许多客户反感销售电话而投诉公司,通过文本挖掘和用户画像可以有效降低客户投诉;在电话平台场景下,有许多B端商家会收到大量的骚扰电话,通过语音分析识别出骚扰电话,从而进行治理,以提升B端商家的体验;在微聊平台,有许多黑产采用技术手段,批量发送吸粉语音,通过语音分析和用户行为分析可以有效识别出黑产用户。
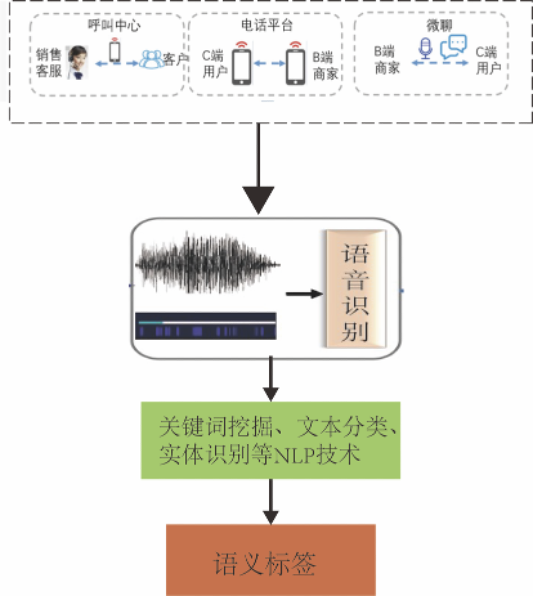
图 2 语音分析应用场景及流程
在语义标签的挖掘工作中,包括两个阶段。第一阶段使用58自研的语音识别引擎,将语音转化成文本;在第二阶段,然后使用关键词挖掘、文本分类、实体识别等自然语言技术,挖掘出语义标签;最后将语义标签应用于上层服务,从而提高业务的效率。
在本文中,主要介绍了的是语音识别后的文本语义标签挖掘工作。首先介绍了如何使用主动学习技术破解冷启动问题;然后详细阐述了不同算法模型的特点与实现过程,并提出了一种改进的Wide&Deep模型,取得了最优的表现效果。
03 主动学习技术
在语义标签的文本分类任务中,通常会遇到两种冷启动问题:一是标注数据量过少,在新的业务场景或新定义的语义标签情况下,往往没有标注数据,导致无法使用机器学习模型,且标注数据的成本比较大,在短时间内无法快速标注大量数据;二是样本不平衡情况下标注问题,比如100个标注数据中,往往只有1个正样本,数据过于稀疏会消耗许多标注资源,且会导致模型过拟合。
而主动学习(Active Learning)被认为是一种非常有效的解决方案:通过使用少量已有标注数据训练机器学习模型,让模型与标注专家进行高效的交互,选择出最优价值和信息量的样本进行标注,能够在预设标准的情况下,有效降低模型学习所需要的标注数据量,进而破解冷启动问题。如图3所示,以下为主动学习迭代模型的流程:
(1) 收集少量已标注数据,训练初始模型;
(2) 使用训练的模型,对未标注的样本进行打分;
(3) 按照查询策略筛选出未标注的数据进行标注,并加入训练数据集;
(4) 使用新的数据集对模型进行调整,得到新的模型;
(5) 重复(2)~(4)步骤,直到未标注样本池数目为0,或者模型达到理想的效果。
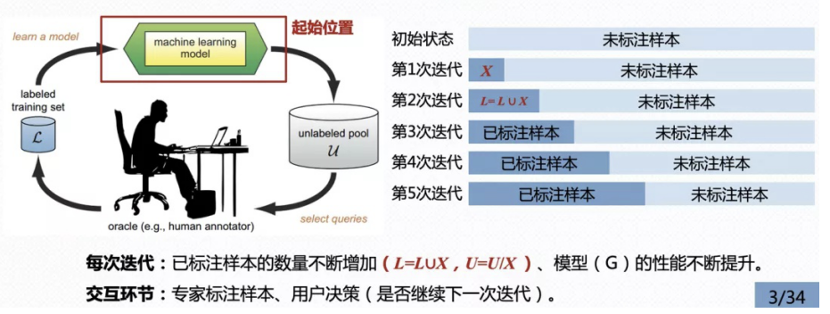
图 3 主动学习的迭代过程
1. 主动学习查询策略
查询策略是主动学习技术的核心之处,通常可以分为基于不确定性的查询策略和基于多样性的查询策略。
不确定性查询方法就是将模型中难以区分的样本数据提取出来,提供给标注专家进行标注,从而达到以较快速度提升算法效果的能力。不确定性的关键就是如何描述数据的不确定性,常见有3种描述不确定性指标:最小置信度、边缘采样、熵方法(图4)。最小置信度方法似乎选择模型预测概率最大,但可信度较低的样本数据。边缘采样指的是选择那些极易被判定成两类的样本数据,即是选择模型预测最大和第二大的概率差值最小的样本。熵是来衡量一个系统的不确定性,熵越大表示不确定性越大,因而选择熵比较大的数据样本数据作为待标注数据。
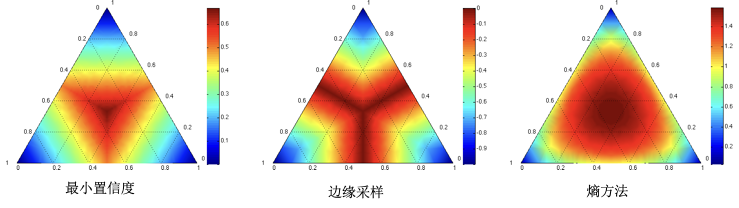
图 4 不确定性查询方法
多样性的查询方法主要考虑样本相关性进行抽样标注,利用一些相似性度量来区分数据之间的差异(图5)。选择差异大的数据集可以丰富训练数据集的特征组合,提升模型的泛化能力,使模型应用的场景也越广。
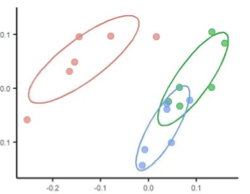
图 5 多样性查询方法
2. 基于不确定性查询策略
在房产语义标签挖掘工作中,尝试进行了不确定性查询策略的实验。在这次实验中,通过初始化模型,对未标注样本的数据进行打分,并选择预测概率在0.3~0.8之间的样本进行标注。之所以选择概率在0.3~0.8之间的样本进行标注,主要考虑原始的样本空间分布是不平衡的,而概率0.3~0.8区间筛选出的样本是平衡的;通过设置概率阈值区间,既可以筛选出不确定的样本进行标注,又可以有效解决样本不平衡性问题。
本文对比了不确定性查询策略和随机标注策略的模型效果(图6)。从图6中可以看出,随着标注数据的增加,两种迭代模型方式的F1 Score均变高,模型效果逐渐变好;然而,主动学习抽样(不确定性抽样)迭代模型的效果优于随机标注方式,且率先达到最优的模型效果。在模型最优的情况下,随机标注方式需要1.7万条标注数据,F1 Score为0.867;而不确定性抽样方式只需要1.2万条标注数据,其F1 Score为0.88。因而,与随机标注相比,不确定性抽样方式节约了近40%的标注数据量。

表格 1 不确定性查询策略最优模型效果及所需标注样本数量
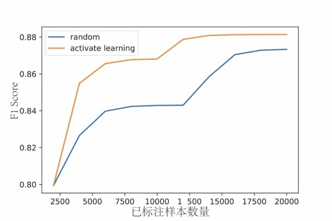
图 6 不确定性查询策略vs随机标注策略
3. 基于多样性的查询策略
多样性查询策略选择文本相似度作为度量,选择与已标注样本池平均相似度最小的样本进行标注。多样性查询策略迭代流程如下(图7):
(1)使用官方发布的预训练Bert将已标注和未标注样本的文本转化成词向量,将所有token的词向量的平均值表征为文本的句向量;
(2)计算未标注样本与与标注样本池的平均相似度;
(3)根据相似度结果进行排序,选择相似度最小的topk样本,交由标注专家进行标注;
(4)将新标注的数据加入已标注样本中,训练模型,并进行下一轮的样本抽样。
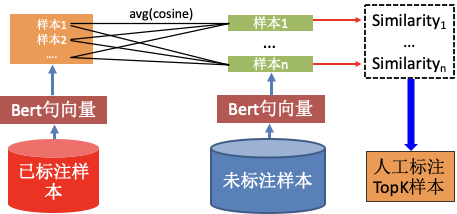
图 7 多样性查询策略
在模型最优的情况下,多样性查询策略仅需要1.3w条标注数据,而随机标注数据则需要2.2万条数据(图8,表2)。与随机标注方式相比,多样性查询策略节约了近60%的标注数据量,且模型效果(F1 Score为0.852)优于随机标注方式(F1 Score为0.849)。

表格 2多样性查询策略最优模型效果及所需标注数量
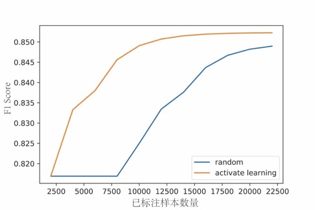
图 8 多样性查询策略 vs 随机标注策略
4. 线上效果
在线上,房产类语义标签进行了两次主动学习迭代(图9):首先进行不确定性查询策略迭代,经过此次迭代,模型的召回率从52%提升到73%;然后进行了多样性查询策略迭代,模型的召回率从73%提升到了80%;与最初的baseline模型相比,经过两次主动学习技术迭代,准确率维持稳定(98%),而召回率绝对提升28%。
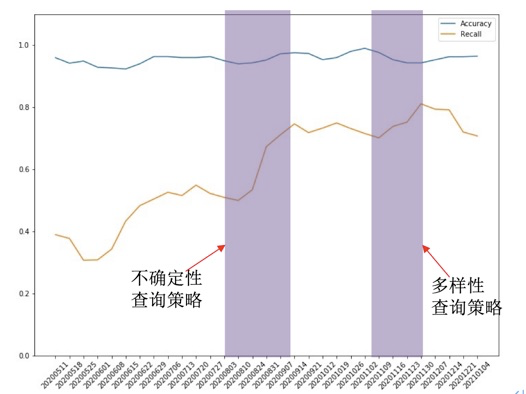
图 9 主动学习在房产类语义标签线上的应用效果
04 模型迭代
语义标签挖掘工作属于文本分类任务,本文依次尝试了关键词匹配、Xgboost、TextCNN、模型融合、CRNN和改进的Wide&Deep模型,其中改进的Wide&Deep模型取得了最优的效果。
1.关键词匹配
在项目早期,由于缺少标注数据,无法训练机器学习模型,而关键词匹配则不需要标注数据,可以快速启动项目。在挖掘关键词过程中,使用了TF-IDF算法和人工挖掘。人工挖掘关键词是指通过人工分析语料数据,总结得到关键词。而TF-IDF算法则是通过计算TF-IDF值,筛选得到关键词。TF-IDF值计算方法如下所示:
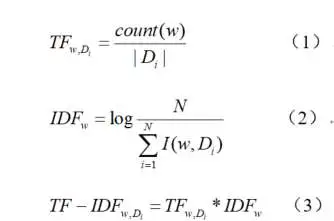
TF表示词频,IDF表示逆文档频率。当一个词的TF-IDF值越高,越有可能是关键词。
关键词匹配模型有许多优点:具有即用性和可解释性等特点。关键词匹配简单、灵活,在很小的数据上进行规则表述与训练,能实现“即插即用”;同时关键词匹配具有良好的解释性,能很好解释匹配到的结果。
关键词匹配可以分为强关键词和弱关键词。强关键词具有较高的准确率,但召回率较低;而弱关键词的准确率较低,但具有较高的召回率。为了提高关键词匹配的准确率和召回率,对关键词匹配进行了策略优化:一是组合关键词;二是设置关键词阈值。
(1)组合关键词。通过将弱关键词进行组合,具有很高的准确率,进而形成强规则。
(2)设置关键词阈值。统计不同关键词命中的次数,对命中次数设置阈值。
关键词匹配取得了较好的效果,本文将关键词匹配作为baseline模型,其准确率为98.75%,召回率为37.44%,F1 Score达到54.3%。
2.Xgboost 模型
在早期的关键词匹配模型中主要存在着两个问题:
(1)关键词数目较少,仅有34个,导致关键词匹配的召回率偏低;
(2)效果不稳定,容易受语音识别(ASR)错误的影响,对方言文本识别错误率高。而Xgboost使用的文本分词特征,其特征数量高达3.2w,远远大于关键词的数量,且能有效的缓解ASR识别错误的影响;此外Xgboost使用有监督的数据,可以更好的挖掘特征。
在Xgboost模型中(图10),首先将对话文本进行分词,然后计算文本的词频特征,将统计的词频特征输入给Xgboost模型进行分类。与关键词匹配相比,Xgboost模型使用了更多维的特征,其F1 Score达到59.21%,优于关键词匹配的效果。
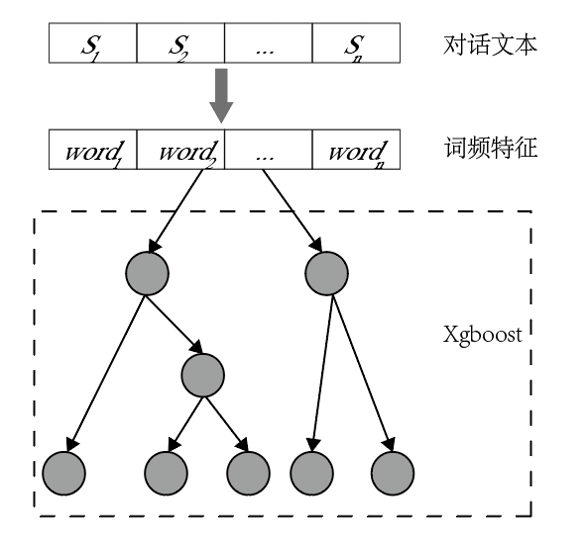
图 10 Xgboost模型
3. TextCNN 模型
Xgboost模型效果虽然优于关键词匹配,但是Xgboost模型本身也存在部分问题。首先Xgboost使用的词频特征依赖于分词的结果,而分词错误将影响模型的效果。比如,“南京市长江大桥”有可能被分成多种结果:“南京、市长、江大桥”和“南京市、长江大桥”。不同的分词结果具有不同词频特征,进而影响Xgboost模型效果。此外,词频特征是一种自编码的特征,无法利用上下文特征,比如“我喜欢你”和“你喜欢我”具有相同的词频特征,但语义完全不同。
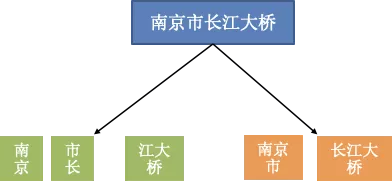
图 11 不同的分词结果
而TextCNN模型可以有效的弥补Xgboost的缺点。TextCNN使用二维卷积核,提取文本局部的上下文语义信息,此外通过控制卷积核的宽度,解析不同N-gram的语义信息。在TextCNN模型中(图12),将文本进行embedding后输入给卷积核,提取得到feature map,最终输出得到语义标签。与Xgboost相比,TextCNN使用的是N-gram特征,模型效果优于Xgboost,F1 Score达到64.97%。

图 12 TextCNN模型
4. 融合模型
关键词匹配、Xgboost和TextCNN模型使用多种类型特征,包括关键词、词频、N-gram特征;3个模型分别具有不同的模型特点:有限状态自动机、树结构和卷积神经网络。将上述3个模型进行融合,可以融合多种特征和多种模型结构,从而提高模型的多样性,进而提高模型的泛化能力。
图13展示了模型融合的原理:首先,将对话文本经过预处理后,分别输入给关键词匹配、Xgboost和TextCNN模型;然后,将Xgboost和TextCNN两个模型的打分取平均值;最后,设置2个阈值条件:
(1)当Xgboost和TextCNN的平均值大于0.75,则认为命中语义标签;
(2)当Xgboost和TextCNN的平均值大于0.6且触发关键词匹配条件,则认为命中语义标签。
在融合模型中,使用多种类型特征和模型有效的提升了模型的效果,其F1 Score达到了70.15%,优于TextCNN模型(F1 Score为64.97%)。
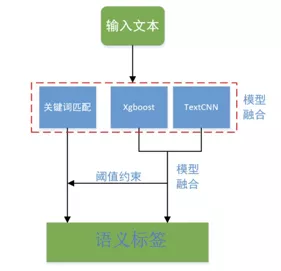
图 13 模型融合原理
5. CRNN模型
尽管融合模型取得了较好效果,但仍旧存在着不足之处。融合模型中3个模型使用的均是局部文本语义特征,而在语音对话场景下是一个多轮对话场景,具有典型的上下文结构。如图14所示,用户在询问商家服务时的话术结构包括:开场白、自我介绍、询问服务、索要电话等环节。关键词匹配、Xgboost和TextCNN模型均无法有效的捕捉这种长距离的话术结构信息。
而CRNN模型是基于上下文模型,可以有效挖掘长距离文本特征信息,其模型主要包括两部分:TextCNN和RNN。如图15所示,CRNN模型使用TextCNN模型对多轮对话中的单句进行局部特征提取,再将TextCNN提取的局部特征输入给RNN,由RNN进行长距离的话术结构特征挖掘。CRNN模型有效的利用了局部特征和长距离话术结构特征,其模型效果优于融合模型,F1 Score达到76.08%。
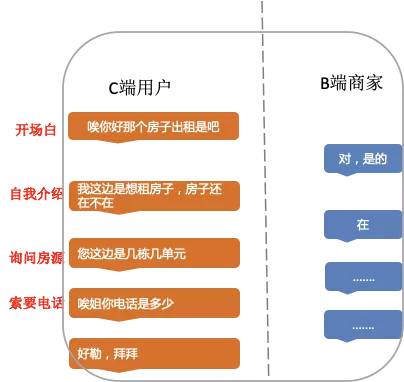
图 14 长距离话术结构示例
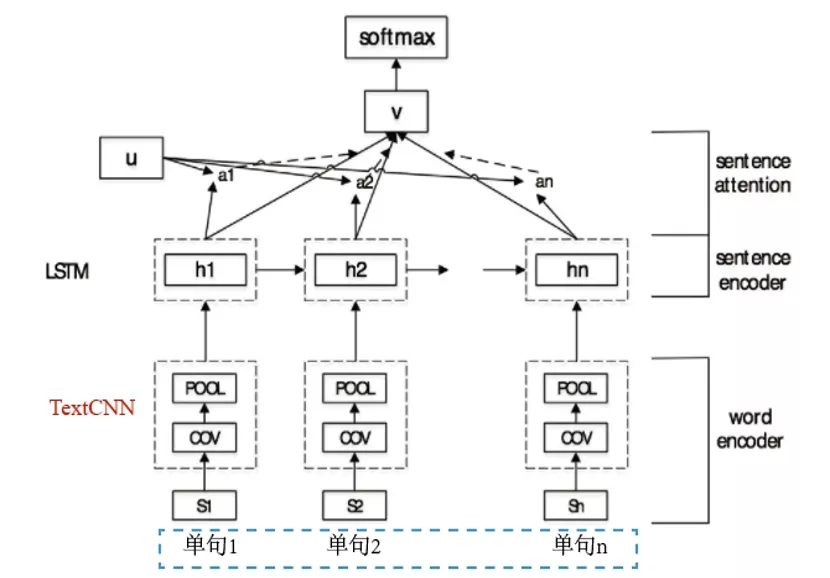
图 15 CRNN模型原理图
6. 改进的Wide&Deep模型
融合模型另外的不足之处是手动的融合多个模型和特征,依靠人工经验设置融合规则,没有办法将多种特征融合在一个模型结构中。为了解决融合模型的不足之处,本文借鉴Google提出的Wide&Deep模型。原生的Wide&Deep模型包括Wide和Deep部分,Wide部分为LR模型,Deep部分为DNN模型。Wide&Deep模型使用的特征包括:词频特征、用户行为特征和对话文本特征(表3)。其中词频特征和用户行为特征输入给LR,将对话文本特征输入给DNN;通过联合训练,可以自动融合使用多种类型的特征。
然而,原生的Wide&Deep模型的Deep部分为DNN,无法有效的挖掘文本语义特征,其F1 Score值仅有63.02%;于是本文提出一种改进的Wide&Deep模型,将Deep部分替换为Te
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8A%80%E6%9C%AF%E6%94%B9%E8%BF%9B%E7%9A%84%E5%9C%A8%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


