技术招聘商业智能搜索召回体系搭建

作者: 58技术 曹冉冉 稿
01 背 景
58招聘过去的搜索召回逻辑主要基于类目体系,用户在输入关键词后,会跳转关键词对应的二级类,召回该二级类下的帖子。严格的类目限制导致很多符合的信息无法被召回,商业帖子填充率较低。同时,在58招聘蓝领为主的业务特点下,B&C端用户本身均有跨类需求,严格分类体系反而成为阻碍,堵不如疏。
因此,我们重构了搜索场景的检索逻辑,打破类目限制,展示全职招聘一级类下相关的信息。同时,将用户的搜索意图贯穿召回、排序等全检索环节策略,更好的匹配用户需求。
本文主要介绍在58商业招聘搜索打破类目限制的条件下,智能召回策略体系的搭建。58招聘搜索query文本特点比较突出,多为短文本,结构化程度较高,集中在职位词、工作性质词、工作场所等类型上,而在帖子侧,描述中存在大量UGC内容,其多样的文本表述方式对召回产生较大的干扰。在这样的特点下,我们把对C端query的分析和B端帖子doc的理解作为搜索策略优化的切入点,召回更多符合用户意图的帖子,并在此基础上,各个环节能力相互贯通,搭建了覆盖全检索流程的搜索策略体系。
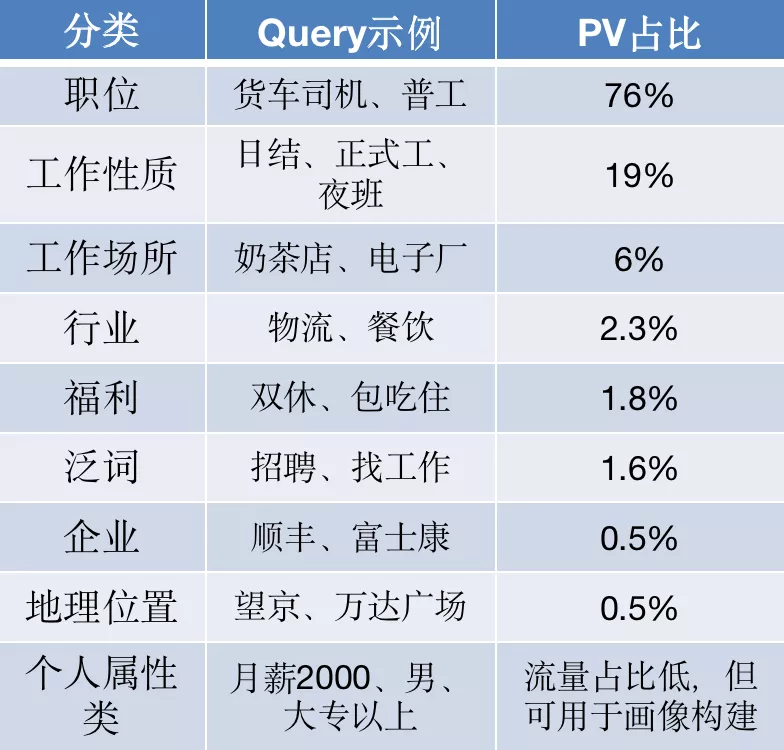
02 智能搜索策略能力体系
招聘商业搜索策略系统整体上包括Query理解、帖子Doc理解、召回、粗排过滤、精排五个模块,我们在各个模块均有不同策略点的落地:
- Query理解环节 ,通过query改写模块对query进行扩展、归一,从而扩大query召回能力,同时通过意图识别能力对query进行结构化分析,将文本映射到职位、工作性质、福利等标签维度,协助整个检索流程的优化。
- Doc理解模块 ,从文本语义角度出发,明确帖子真实在招的职位,同时过滤掉帖子标记不合理的文本,避免召回阶段将文本包含但不相关的帖子被误召回。
- 检索召回阶段 ,在多通道召回的基础上,针对query特点、C端流量特点、B端候选集分布等特征,分别搭建文本召回、标签召回、向量召回等能力。
- 排序模块 ,包含粗排过滤和精排等环节,结合搜索场景的特点,分别考虑文本相关性、ctr、收入等因素,兼顾连接效率及商业变现效率。
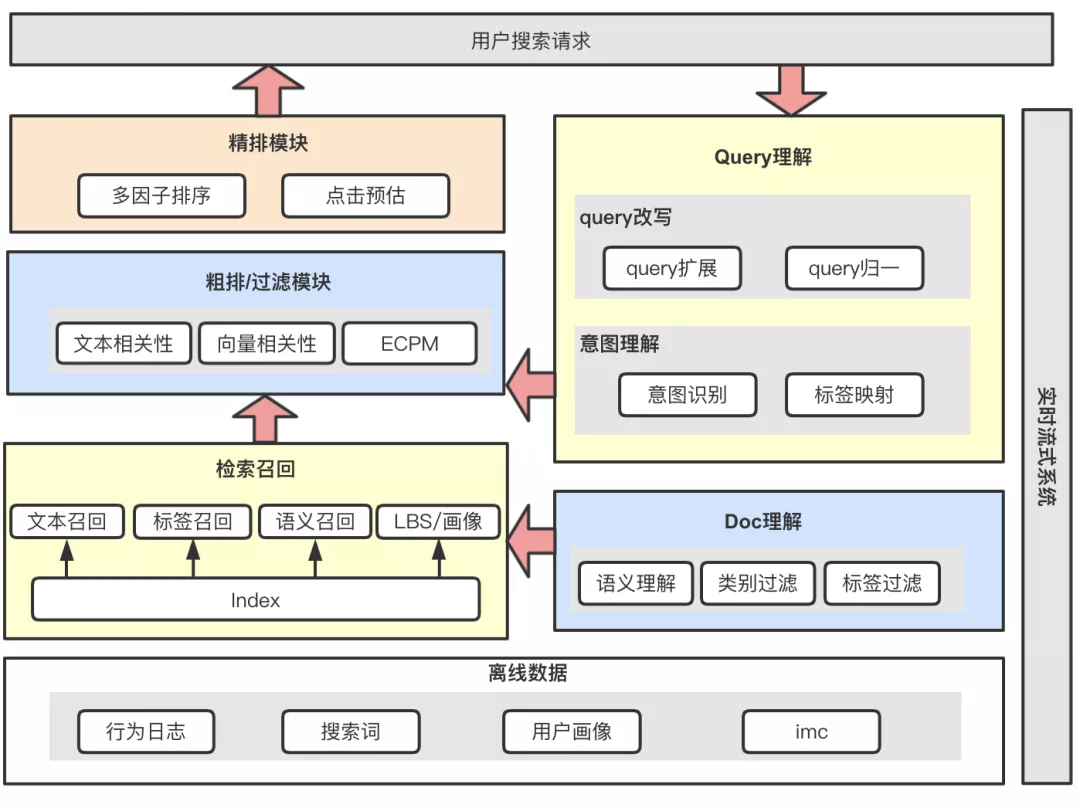
03 搜索召回算法架构
为了在兼顾相关性的基础上最大限度提升搜索系统的召回能力,检索召回环节针对C端query特点和B端帖子特点等建设了多个召回通道,各个通道算法能力具有各自相对的优势,覆盖query分析、doc理解、索引过滤、检索触发等搜索召回阶段所涉及的所有环节:
- 文本通道: 具备query改写和doc理解能力。通过query召回对应帖子中包含query文本的帖子,优势为通过文本直接召回帖子,避免标签环节的影响。query侧通过改写对搜索词进行扩展和归一,在帖子侧doc理解能力对不相关文本进行过滤。
- 意图通道: 具备意图识别和doc理解标签过滤能力。针对query结构化程度较高的特点,意图识别能力将query文本映射到标签体系,召回标签匹配的帖子。
- 向量通道: 具备向量召回能力。将query和帖子表征为向量,通过向量相似度判断帖子是否召回,避免query改写、标签映射、文本切词等多个环节对最终效果的影响,对语义相近但文本不包含类帖子的召回效果较突出。
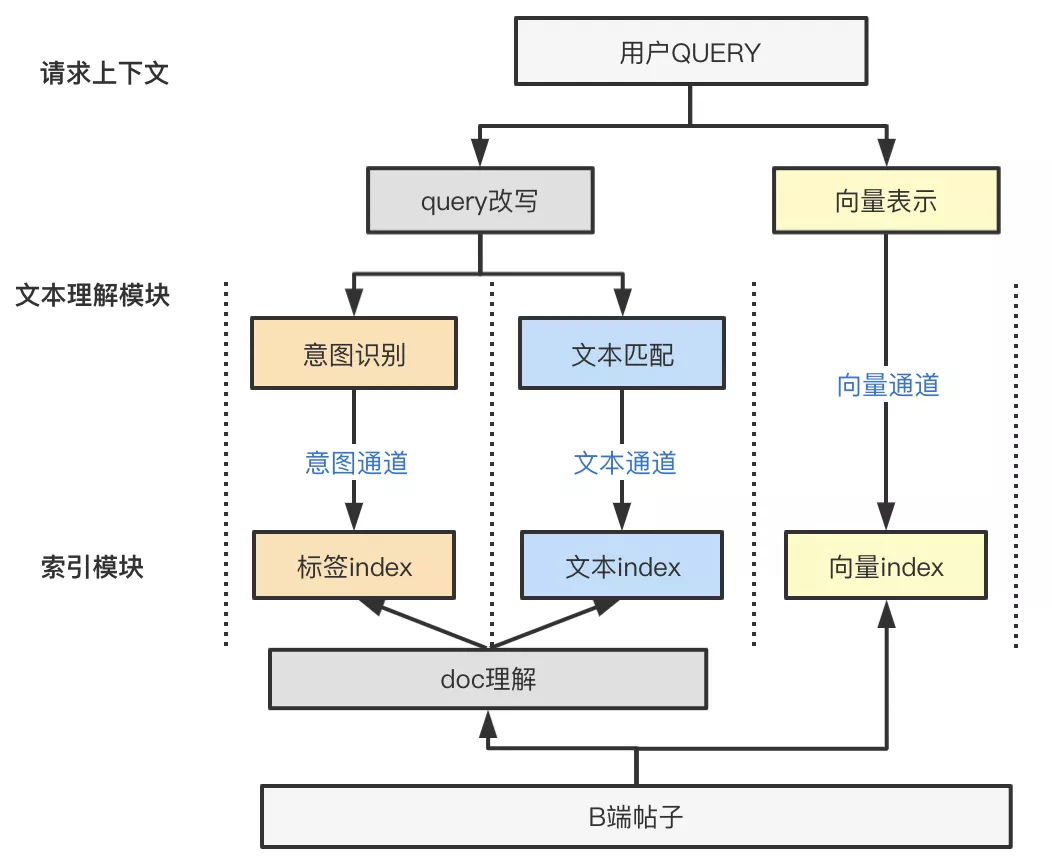
下文围绕在各个通道涉及的query改写、doc理解、意图识别、向量召回等算法能力做详细的介绍。
04 基础能力
4.1 文本&意图通道-query改写
query改写环节通过对query的拓展和归一,达到扩大单一query召回能力的效果,如“理发师”改写成“发型师”、“理发助理”,则包含改写词或标签的帖子均可被召回。
业界常用的建模思路主要有以下两种方式:
1. 基于session序列或点击行为建模
a) 同session或点击下,用户产生的多个query一般存在一定的相关性,可通过统计互信息、关联规则挖掘共现关系;
b) 把同session下的query作为一篇文章,通过query2vec训练得到embedding相似度。
2. 基于业务语料建模
a) 对于语料较丰富的场景,可以考虑采用业务语料训练词向量模型,计算query间相似度。
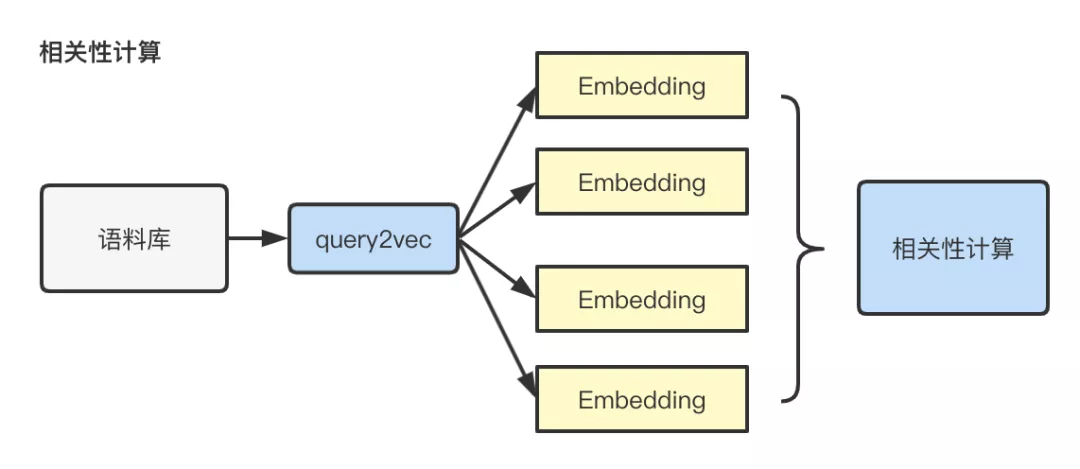
初版我们采用了基于语料的方式,将query输入预训练模型生成其embedding表示,利用不同query embedding的内积表示query的相似度,从而能拓展出相关的query。首先预训练模型帮助我们在语料有限的条件下,学习到更多语义通用知识,同时相比word2vec等其他常用文本embedding表示方式,基于字级别的输入,解决了长尾词oov问题,避免了基于滑动窗口的训练方式对语料质量的强依赖问题。
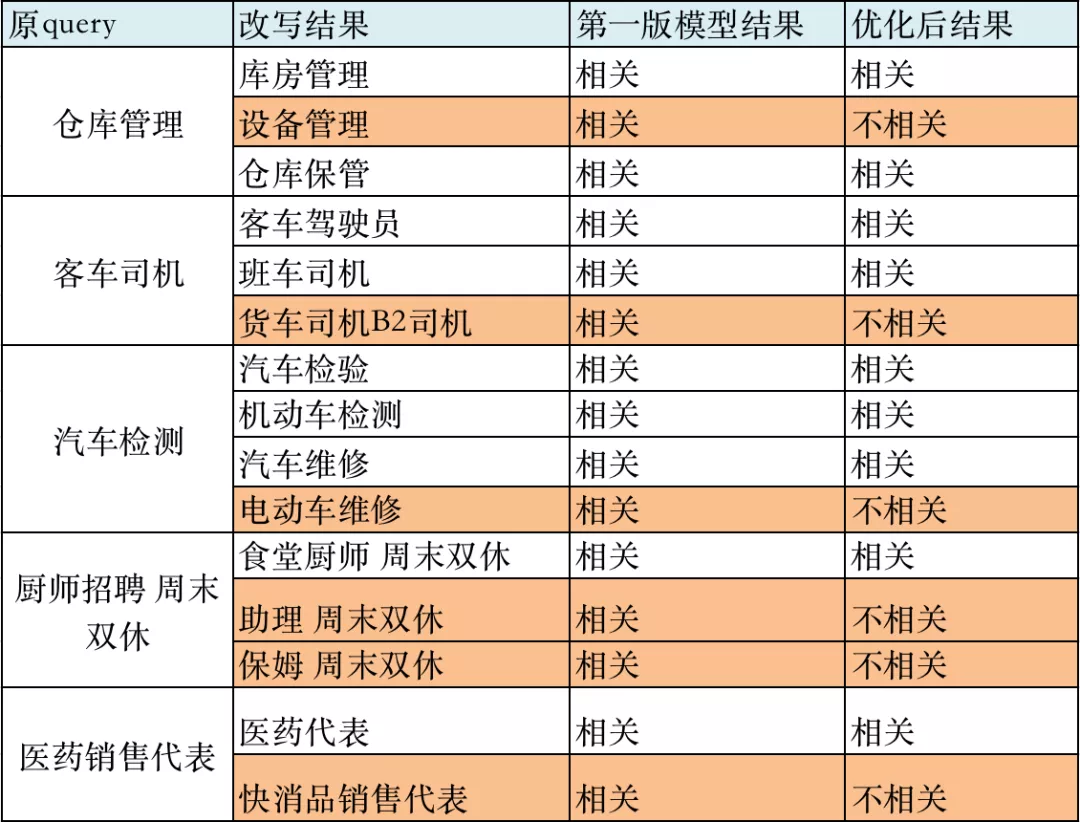
第一版上线后,我们发现存在如“英语老师”被改写成“日语老师”、“法语老师”的case,在58招聘的场景下,该类扩展会导致不相关职位被误召回。其问题原因在于,我们仅仅基于预训练模型进行无监督学习,未学习到58场景下的业务信息,同时,字级别encoding方式,容易对不同义但多字重合的query表示成相近的embedding,如“药店店员”改写成“商店店员”。因此,在第一版模型的基础上,我们采用finetune进一步有监督学习query与query之间的相关性。
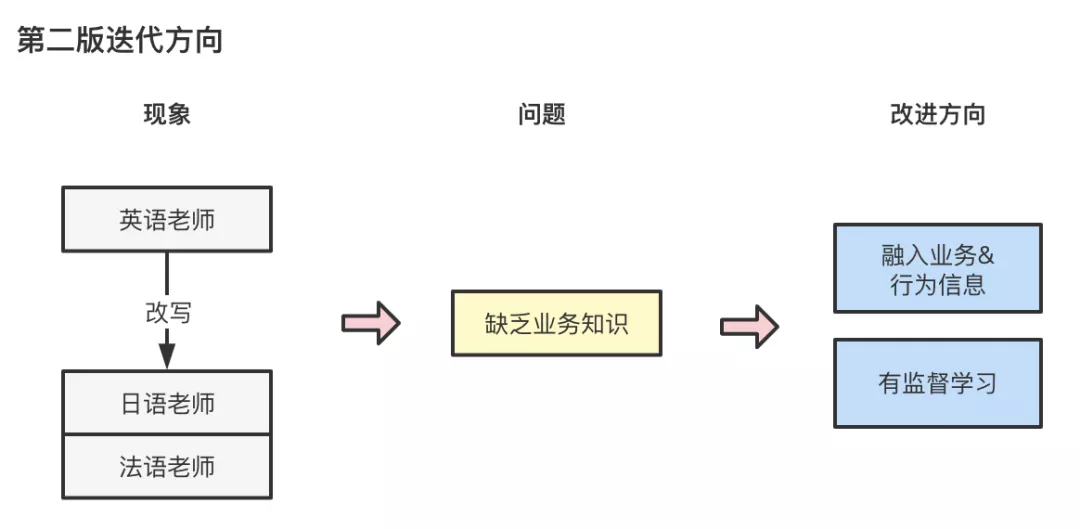
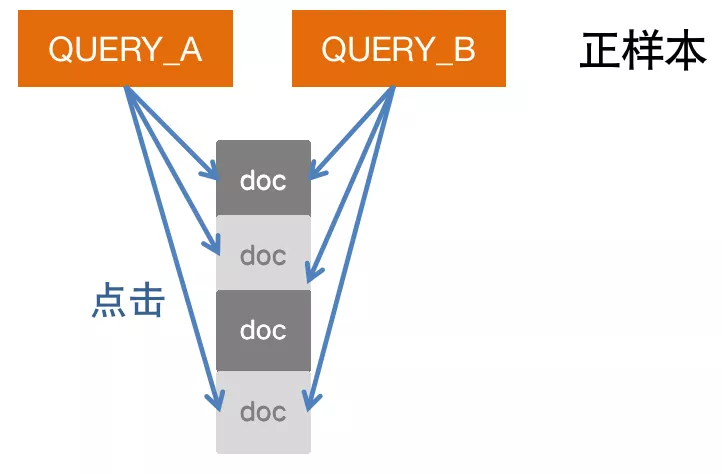
样本方面,大规模的人工样本标注成本过高,正样本的标注我们利用query与query之间点击帖子的共现关系,当两个query下点击的帖子重合程度超过一定阈值后被标记为相似query,从而将业务信息通过用户行为融入样本中。提高了样本的置信度,一定程度上避免随机点击给样本带来噪声。
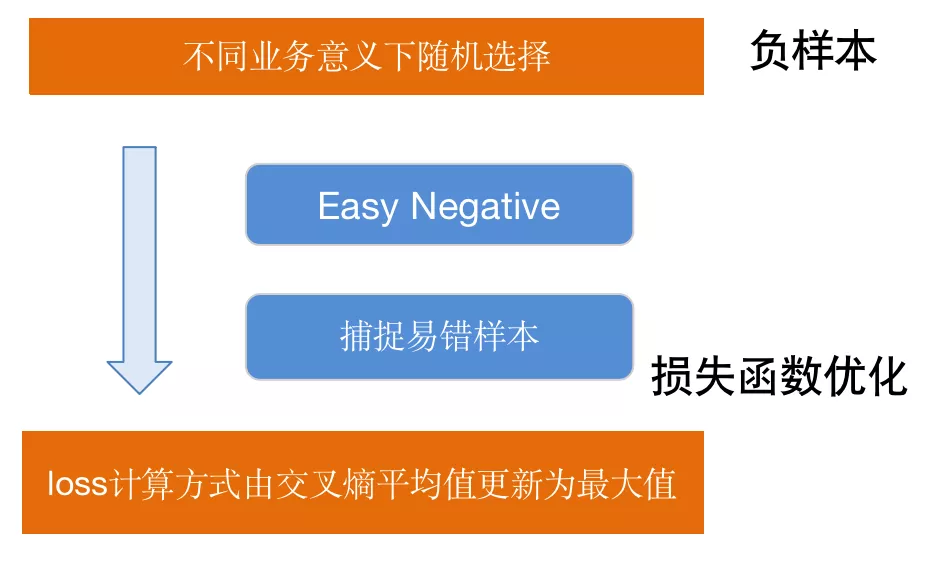
负样本的选择我们采用在不同业务意义下的随机选择方式,避免检索各环节对行为分布的影响,扩大了样本的泛化能力。但同时随机选择也造成样本存在easy learning的问题,为了更好的捕捉易错样本,我们同步对损失函数进行更新,将loss由一个batch下交叉熵的平均值更新为最大值,一定程度可以使每个batch的hard sample影响更大。
通过两版优化,我们query改写离线准确率提升20%,上线后由query改写导致的badcase也降低10%+。
4.2 意图通道 - 意图识别能力
在通过query改写对用户输入搜索词进行拓展的同时,因为query结构化程度高的特点,也启发我们将query文本转化成系统能更好理解的标签体系,从而通过对query的分析捕捉到结构化的用户意图信息,并传递到包括召回、排序、创意展示等全检索环节,针对性地进行更加个性化的适配。
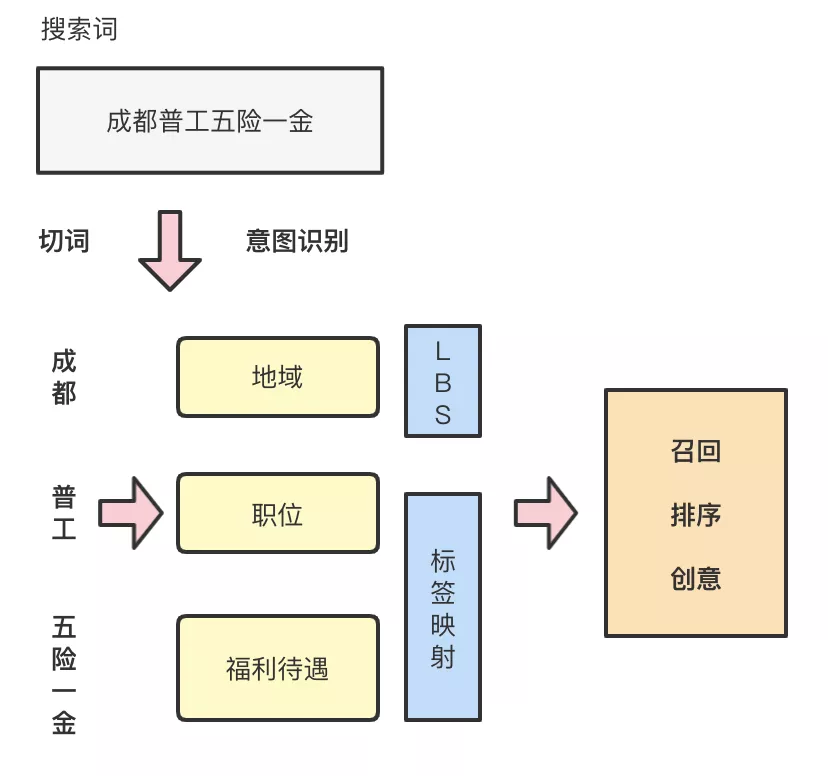
意图识别的基本思路是首先对query进行切词,对切词后的每一部分term进行意图分类。属性类别包括职位、公司名称、工作场所等9类,基本上覆盖线上query描述中招聘业务相关的所有属性。我们前期的策略设计思路主要包含三个步骤:
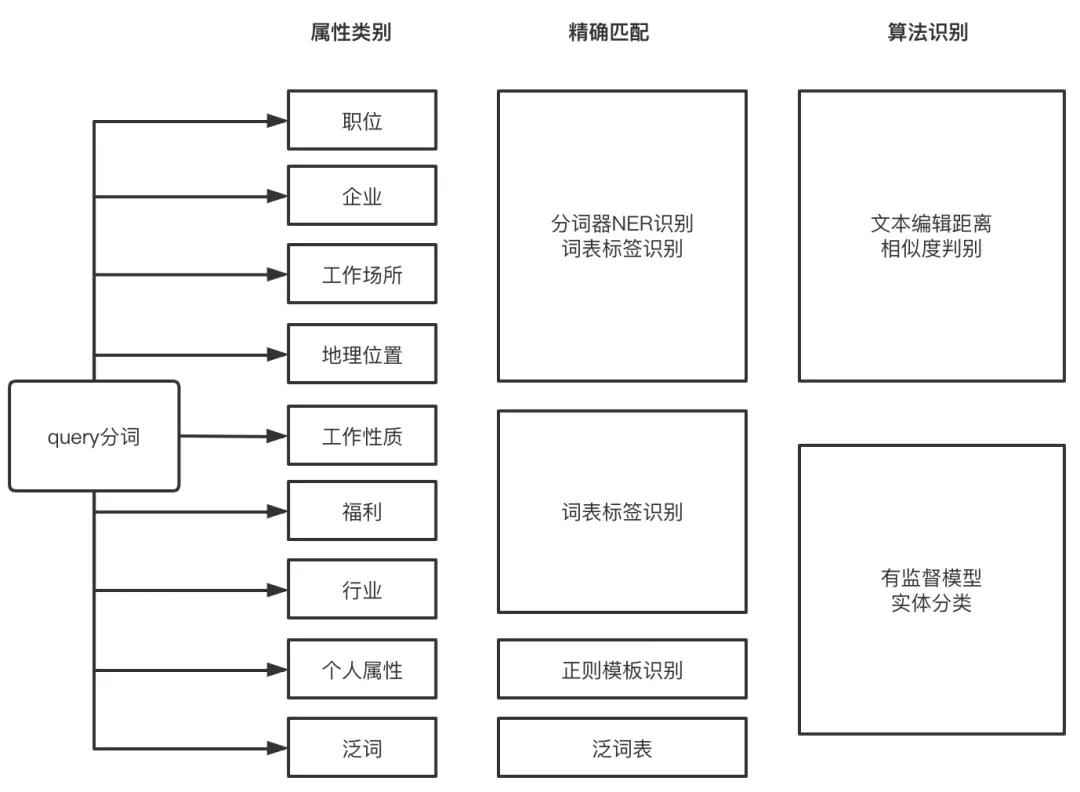
1. 精确规则匹配
a) 利用58自建分词器的命名实体识别能力,对职位、企业、工作场所和地理位置进行初步识别;
b) 对个人属性包括薪资、年龄、性别和学历四个类别,可以根据常用的表述方式,设计每个类别的识别模版,比如薪资,一般描述有:“月薪2000以上”,“月工资5000左右”等,正则模版相应为【^月薪(. ?)以上$】、【^ 月工资(.?)左右$】;
c) 泛词:人工总结泛词词表,如“招聘”、“工作”等词,同时通过分词器过滤停用词。
2. 采用文本编辑距离计算相似度
a) 在此基础上,采用文本的编辑距离来表征文本相似性,计算query分词后的文本和标签文本的编辑距离,直接将文本映射到与其编辑距离较近的标签上。
3. 构建query文本分类模型实现对实体的识别
a) 采用模型有监督分类识别,计划采用预训练-微调的架构,实现对实体的分类功能。
在实际优化过程中,因为query的结构化程度相对较高,且目前招聘业务已有的标签体系对各类属性的覆盖程度较高,我们主要进行了上述精确匹配和文本编辑距离计算两个环节的优化,对于query意图的覆盖率和准确率均达到90%以上,满足线上的使用要求。
4.3 文本 &意图 通道 - doc理解
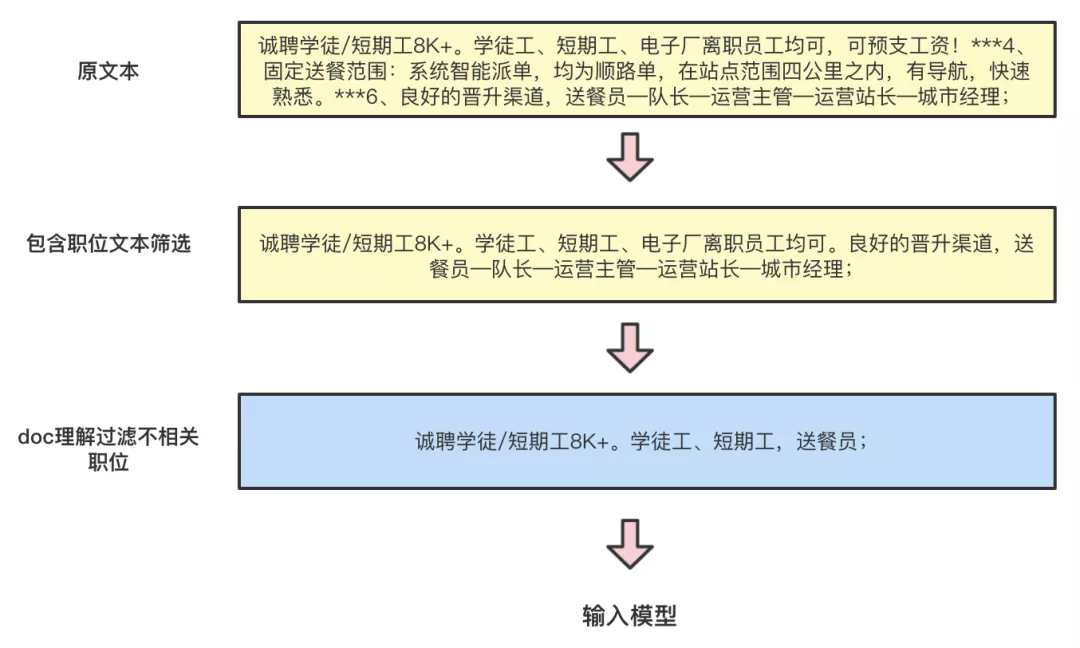
在C端对query进行改写和意图识别后,我们可以确保打破类目的限制后,直接通过文本和标签两个体系召回相关的帖子,但线上仍存在大量与query不相关的帖子被召回的现象,影响了用户的搜索体验,经过对不相关case分析发现,超过一半的误召回原因是“内容包含文本关键字但实际内容不相关”,例如,在实际招聘送餐员的帖子详情描述中包含“服务员不如送餐员”等语句,用户在搜索“服务员”时会命中该类帖子,导致与query不相关的帖子被召回。
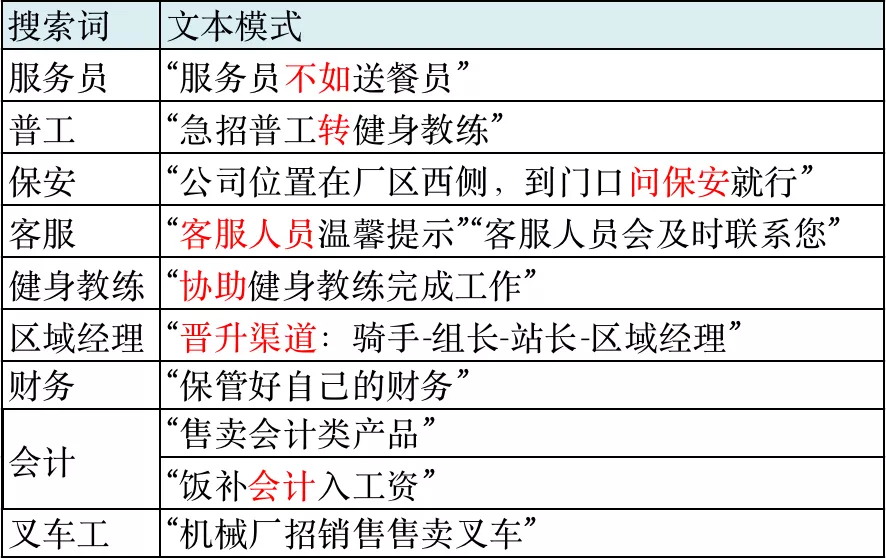
因此,为了解决该类问题,我们构建了doc理解的能力,从文本语义角度出发,明确帖子真实在招的职位,过滤掉帖子标记不合理的文本及职位标签。
在策略方案选择上,因为badcase模式多样且不断更新,无法基于模式匹配或文本统计特征等方式完全识别,经过调研,我们决定构建基于语义理解的深度网络模型,学习帖子描述和职位、类别等之间的关系。
在模型训练阶段,将query和对应的帖子文本作为pair对输入模型,学习query和帖子文本的相关性。考虑到帖子的详情内容多为长文本,且大多数带有干扰项的描述有较突出的文本特点,为了能更好的捕捉长文本的位置关系,我们选用bert作为相关性识别的主要模型,其双向transformer结构能帮助我们识别多种文本模式。
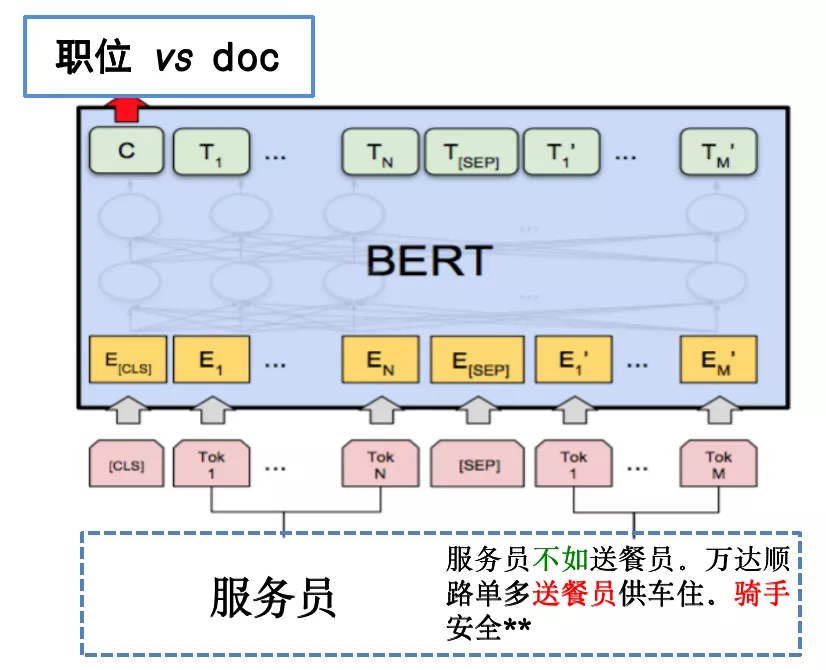
在样本准备阶段,除了利用已知的行为信息标注样本外,我们也人工标注了2w+的样本,覆盖已知主要的badcase文本描述模式,同时,为了增加模型的泛化能力,采用随机职位替换、关键信息调换等数据增强的方式提高模型的鲁棒性。如“服务员不如送餐员”的case,前期会做如下三种样本补充:
- 弱特征样本增强,补充成“服务员不如送餐员不如普工”等形式;
- 随机职位替换,将“送餐员”替换成“服务员不如厨师”;
- 关键信息位置调换,将“服务员不如送餐员”调换前后职位信息为“送餐员不如服务员”。
线上环节,我们对帖子真实在招的职位进行预测,直接在索引建库环节过滤掉不相关的文本及职位标签,避免在检索阶段重复召回造成对资源的浪费。同时,索引写入阶段异步的调用方式对时效性要求相对较低,支持采用bert等参数量级较大的模型进行在线预测。
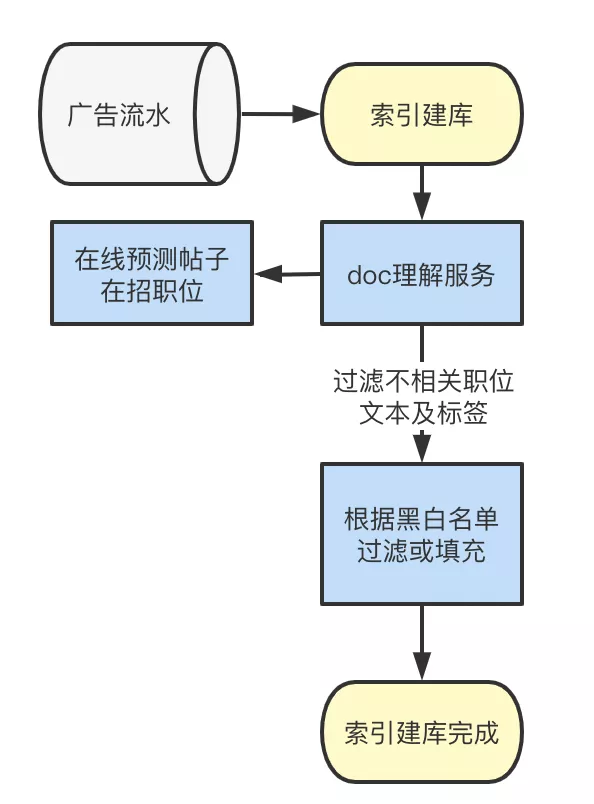
一期模型上线后,线上综合搜流量下,策略影响产品的准确率提升17%,极大提升了搜索体验。二期,我们将识别的范围扩大到对非职位词、类别与帖子文本相关性的识别上,目前相关能力已经在58搜索主要商业产品的全部流量上应用,在通过文本和标签通道召回的帖子中,各产品线上正确率均提升10%-20%。
4.4 向量通道 - 向量召回 能力
通过以上意图及文本等召回策略,已经极大地提高了搜索召回能力,但分析发现,存在大量语义相近但文本不包含的帖子未被召回,如搜索“寒假工”,可以召回在帖子描述中不包含寒假工,但包含“学徒”、“短期工”等的帖子,这部分通过标签及文本匹配等方式难以被召回。另一方面,其他通道存在标签映射、切词、文本匹配等多个环节,每个环节的问题都会对最终召回效果产生影响。为了解决上述问题,需要直接从语义出发,根据query和doc的相关性直接召回帖子。
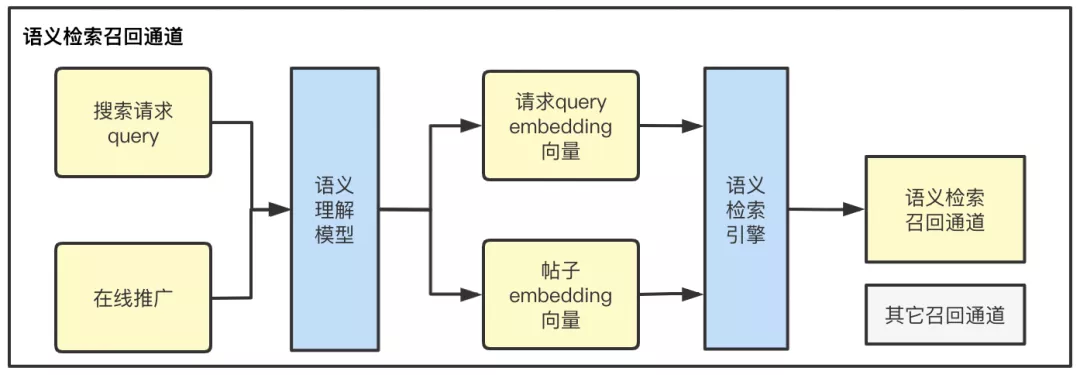
相关性表示在策略层面已经有较成熟的方案,问题的难点主要集中在相关性学习能力和召回阶段检索性能的权衡。为了解决上述问题,策略框架层面,我们采用业界常用的表示型语义匹配方式 - 双塔结构对query和帖子doc进行向量表征,通过向量空间距离去刻画query和doc的相关性。双塔结构既满足了召回阶段对性能的要求,同时也能更好地适配现有的检索架构,从而支持算法快速落地及迭代。从算法角度,双塔结构虽不能最大限度学习到帖子和query特征交叉的信息,但对于在召回阶段更大限度扩充候选集的目的,该结构已基本能满足算法要求。
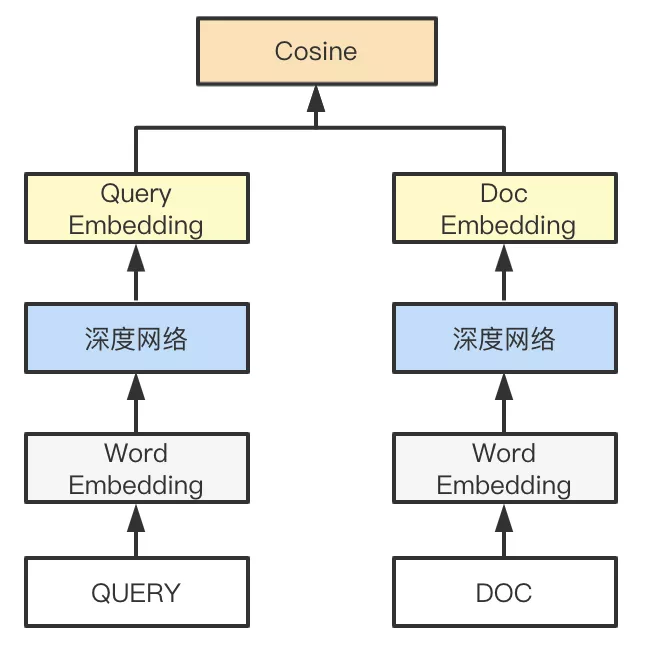
模型部分,在传统DSSM结构下我们加入CNN的网络结构。CNN的学习方式能更好地帮助我们学习到帖子上下文信息。
同时,为了能更好提高短-长文本匹配的效果,我们将注意力放在对帖子doc的长文本处理上,初版模型我们将帖子标题加详情全文作为doc侧的输入,发现效果远不如只将帖子标题或标题加详情首句输入的效果好,说明长篇幅的详情内容加入了过多的冗余信息,反而不利于模型学习到帖子描述的核心内容。同时,因为帖子描述存在误导性信息,我们利用上文已经建设成熟的doc理解能力,对帖子文本内容进行过滤,剔除掉一些不相关的干扰文本。
模型评测方面,除了考虑auc等常规评估方式外,为了能更直观评估召回阶段的效果,我们也抽样评估了单query下,在相似度头部排序区间的正样本数量,如下表所示,在相似度排名前60的样本中,表现较好的query如“淘宝客服”下,正样本多集中在排名靠前区域,说明该query下模型效果较好。
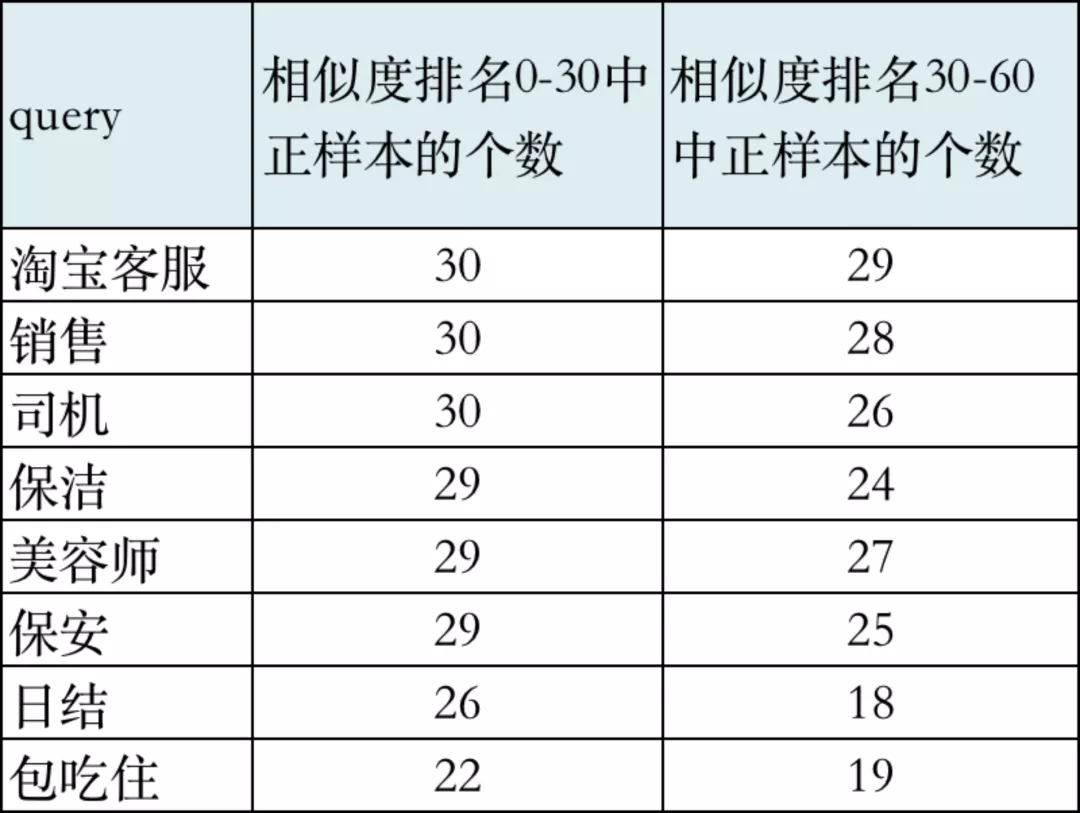
上线后,在向量召回生效的流量下,pvr及asn均取得了15%~20%的增长,带来cash/uv和resume/uv 10%的增长,在扩大召回能力的同时,人工评估线上整体准确率也保持不变,满足对搜索相关性的要求。
对效果进一步分析发现,样本质量很大程度上决定了最终的效果上限。模型在高频词上相关性表现更好,主要因为高频词对应的样本相关性更好,样本量也更丰富,使模型可以充分学习,而目前基于行为的样本标注方式,使低频query下因为行为数据稀疏导致样本不足,或样本噪声过大。针对以上问题,目前我们也在探索通过word2vec、EGES等方式,挖掘帖子与帖子间关系,更好地对低
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8A%80%E6%9C%AF%E6%8B%9B%E8%81%98%E5%95%86%E4%B8%9A%E6%99%BA%E8%83%BD%E6%90%9C%E7%B4%A2%E5%8F%AC%E5%9B%9E%E4%BD%93%E7%B3%BB%E6%90%AD%E5%BB%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


