技术分析七的性能优化
硬件选择
Elasticsearch(后文简称 ES)的基础是 Lucene,所有的索引和文档数据是存储在本地的磁盘中,具体的路径可在 ES 的配置文件 ../config/elasticsearch.yml 中配置,如下:
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /path/to/data
#
# Path to log files:
#
path.logs: /path/to/logs
磁盘在现代服务器上通常都是瓶颈。Elasticsearch 重度使用磁盘,你的磁盘能处理的吞吐量越大,你的节点就越稳定。这里有一些优化磁盘 I/O 的技巧:
- 使用 SSD。就像其他地方提过的, 他们比机械磁盘优秀多了。
- 使用 RAID 0。条带化 RAID 会提高磁盘 I/O,代价显然就是当一块硬盘故障时整个就故障了。不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能。
- 另外,使用多块硬盘,并允许 Elasticsearch 通过多个 path.data 目录配置把数据条带化分配到它们上面。
- 不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的。
- 如果你用的是 EC2,当心 EBS。即便是基于 SSD 的 EBS,通常也比本地实例的存储要慢。
内部压缩
硬件资源比较昂贵,一般不会花大成本去购置这些,可控的解决方案还是需要从软件方面来实现性能优化提升。
其实,对于一个分布式、可扩展、支持PB级别数据、实时的搜索与数据分析引擎,ES 本身对于索引数据和文档数据的存储方面内部做了很多优化,具体体现在对数据的压缩,那么是如何压缩的呢?介绍前先要说明下 Postings lists 的概念。
倒排列表 - postings list
搜索引擎一项很重要的工作就是高效的压缩和快速的解压缩一系列有序的整数列表。我们都知道,Elasticsearch 基于 Lucene,一个 Lucene 索引 我们在 Elasticsearch 称作 分片 , 并且引入了 按段搜索 的概念。
新的文档首先被添加到内存索引缓存中,然后写入到一个基于磁盘的段。在每个 segment 内文档都会有一个 0 到文档个数之间的标识符(最高值 2^31 -1),称之为 doc ID。这在概念上类似于数组中的索引:它本身不做存储,但足以识别每个item 数据。
Segments 按顺序存储有关文档的数据,在一个Segments 中 doc ID 是 文档的索引。因此,segment 中的第一个文档的 doc ID 为0,第二个为1,等等。直到最后一个文档,其 doc ID 等于 segment 中文档的总数减1。
那么这些 doc ID 有什么用呢?倒排索引需要将 terms 映射到包含该单词 (term) 的文档列表,这样的映射列表我们称之为: 倒排列表(postings list)。具体某一条映射数据称之为: 倒排索引项(Posting)。
举个例子,文档和词条之间的关系如下图所示,右边的关系表即为倒排列表:
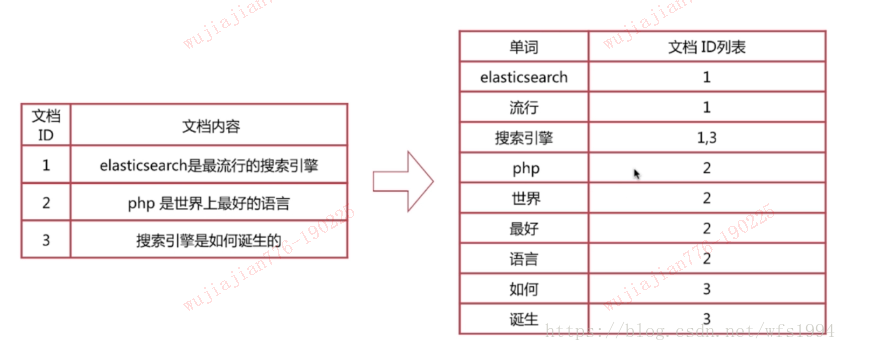
倒排列表 用来记录有哪些文档包含了某个单词(Term)。一般在文档集合里会有很多文档包含某个单词,每个文档会记录文档编号(doc ID),单词在这个文档中出现的次数(TF)及单词在文档中哪些位置出现过等信息,这样与一个文档相关的信息被称做 倒排索引项(Posting),包含这个单词的一系列倒排索引项形成了列表结构,这就是某个单词对应的 倒排列表 。
Frame Of Reference
了解了分词(Term)和文档(Document)之间的映射关系后,为了高效的计算交集和并集,我们需要倒排列表(postings lists)是有序的,这样方便我们压缩和解压缩。
针对倒排列表,Lucene 采用一种增量编码的方式将一系列 ID 进行压缩存储,即称为 Frame Of Reference的压缩方式(FOR),自Lucene 4.1以来一直在使用。
在实际的搜索引擎系统中,并不存储倒排索引项中的实际文档编号(Doc ID),而是代之以文档编号差值(D-Gap)。文档编号差值是倒排列表中相邻的两个倒排索引项文档编号的差值,一般在索引构建过程中,可以保证倒排列表中后面出现的文档编号大于之前出现的文档编号,所以文档编号差值总是大于0的整数。
如下图所示的例子中,原始的 3个文档编号分别是187、196和199,通过编号差值计算,在实际存储的时候就转化成了:187、9、3。
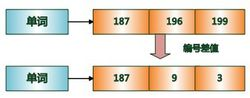
之所以要对文档编号进行差值计算,主要原因是为了更好地对数据进行压缩,原始文档编号一般都是大数值,通过差值计算,就有效地将大数值转换为了小数值,而这有助于增加数据的压缩率。
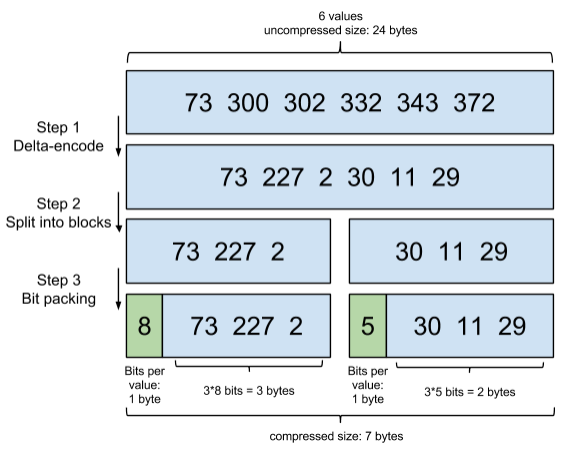
比如一个词对应的文档ID 列表 [73, 300, 302, 332,343, 372] ,ID列表首先要从小到大排好序;
- 第一步: 增量编码就是从第二个数开始每个数存储与前一个id的差值,即
300-73=227,302-300=2,…,一直到最后一个数。 - 第二步: 就是将这些差值放到不同的区块,Lucene使用256个区块,下面示例为了方便展示使用了3个区块,即每3个数一组。
- 第三步: 位压缩,计算每组3个数中最大的那个数需要占用bit位数,比如30、11、29中最大数30最小需要5个bit位存储,这样11、29也用5个bit位存储,这样才占用15个bit,不到2个字节,压缩效果很好。
如下面原理图所示,这是一个区块大小为3的示例(实际上是256):
考虑到频繁出现的term(所谓low cardinality的值),比如gender里的男或者女。如果有1百万个文档,那么性别为男的 posting list 里就会有50万个int值。用 Frame of Reference 编码进行压缩可以极大减少磁盘占用。这个优化对于减少索引尺寸有非常重要的意义。
因为这个 FOR 的编码是有解压缩成本的。利用skip list(跳表),除了跳过了遍历的成本,也跳过了解压缩这些压缩过的block的过程,从而节省了cpu。
Roaring bitmaps (RBM)
在 elasticsearch 中使用filters 优化查询,filter查询只处理文档是否匹配与否,不涉及文档评分操作,查询的结果可以被缓存。具体的 Filter 和Query 的异同读者可以自行网上查阅资料。
对于filter 查询,elasticsearch 提供了Filter cache 这种特殊的缓存,filter cache 用来存储 filters 得到的结果集。缓存 filters 不需要太多的内存,它只保留一种信息,即哪些文档与filter相匹配。同时它可以由其它的查询复用,极大地提升了查询的性能。
Frame Of Reference 压缩算法对于倒排表来说效果很好,但对于需要存储在内存中的 Filter cache 等不太合适。
倒排表和Filter cache两者之间有很多不同之处:
- 倒排表存储在磁盘,针对每个词都需要进行编码,而Filter等内存缓存只会存储那些经常使用的数据。
- 针对Filter数据的缓存就是为了加速处理效率,对压缩算法要求更高。
这就产生了下面针对内存缓存数据可以进行高效压缩解压和逻辑运算的roaring bitmaps算法。
说到Roaring bitmaps,就必须先从bitmap说起。Bitmap是一种数据结构,假设有某个posting list:
[3,1,4,7,8]
对应的Bitmap就是:
[0,1,0,1,1,0,0,1,1]
非常直观,用0/1表示某个值是否存在,比如8这个值就对应第8位,对应的bit值是1,这样用一个字节就可以代表8个文档id(1B = 8bit),旧版本(5.0之前)的Lucene就是用这样的方式来压缩的。但这样的压缩方式仍然不够高效,Bitmap自身就有压缩的特点,其用一个byte就可以代表8个文档,所以100万个文档只需要12.5万个byte。但是考虑到文档可能有数十亿之多,在内存里保存Bitmap仍然是很奢侈的事情。而且对于个每一个filter都要消耗一个Bitmap,比如age=18缓存起来的话是一个Bitmap,18<=age<25是另外一个filter缓存起来也要一个Bitmap。
Bitmap的缺点是存储空间随着文档个数线性增长,所以秘诀就在于需要有一个数据结构打破这个魔咒,那么就一定要用到某些指数特性:
- 可以很压缩地保存上亿个bit代表对应的文档是否匹配filter;
- 这个压缩的Bitmap仍然可以很快地进行AND和 OR的逻辑操作。
Lucene使用的这个数据结构叫做 Roaring Bitmap,即位图压缩算法,简称 BMP。
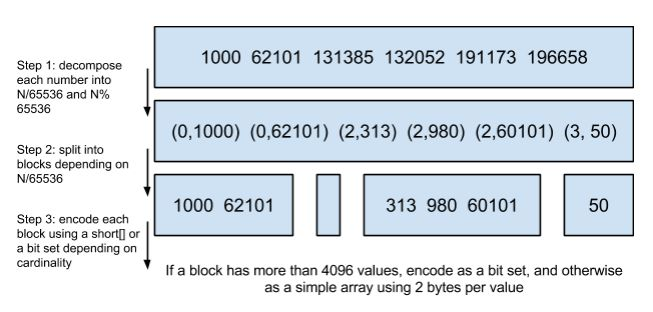
其压缩的思路其实很简单。与其保存100个0,占用100个bit。还不如保存0一次,然后声明这个0重复了100遍。
这两种合并使用索引的方式都有其用途。Elasticsearch 对其性能有详细的对比,可阅读 Frame of Reference and Roaring Bitmaps。
分片策略
合理设置分片数
创建索引的时候,我们需要预分配 ES 集群的分片数和副本数,即使是单机情况下。如果没有在 mapping 文件中指定,那么索引在默认情况下会被分配5个主分片和每个主分片的1个副本。
分片和副本的设计为 ES 提供了支持分布式和故障转移的特性,但并不意味着分片和副本是可以无限分配的。而且索引的分片完成分配后由于索引的路由机制,我们是不能重新修改分片数的。
例如某个创业公司初始用户的索引 t_user 分片数为2,但是随着业务的发展用户的数据量迅速增长,这时我们是不能重新将索引 t_user 的分片数增加为3或者更大的数。
可能有人会说,我不知道这个索引将来会变得多大,并且过后我也不能更改索引的大小,所以为了保险起见,还是给它设为 1000 个分片吧…
一个分片并不是没有代价的。需要了解:
- 一个分片的底层即为一个 Lucene 索引,会消耗一定文件句柄、内存、以及 CPU 运转。
- 每一个搜索请求都需要命中索引中的每一个分片,如果每一个分片都处于不同的节点还好, 但如果多个分片都需要在同一个节点上竞争使用相同的资源就有些糟糕了。
- 用于计算相关度的词项统计信息是基于分片的。如果有许多分片,每一个都只有很少的数据会导致很低的相关度。
适当的预分配是好的。但上千个分片就有些糟糕。我们很难去定义分片是否过多了,这取决于它们的大小以及如何去使用它们。 一百个分片但很少使用还好,两个分片但非常频繁地使用有可能就有点多了。 监控你的节点保证它们留有足够的空闲资源来处理一些特殊情况。
一个业务索引具体需要分配多少分片可能需要架构师和技术人员对业务的增长有个预先的判断,横向扩展应当分阶段进行。为下一阶段准备好足够的资源。 只有当你进入到下一个阶段,你才有时间思考需要作出哪些改变来达到这个阶段。
一般来说,我们遵循一些原则:
-
控制每个分片占用的硬盘容量不超过ES的最大JVM的堆空间设置(一般设置不超过32G,参考下文的JVM设置原则),因此,如果索引的总容量在500G左右,那分片大小在16个左右即可;当然,最好同时考虑原则2。
-
考虑一下node数量,一般一个节点有时候就是一台物理机,如果分片数过多,大大超过了节点数,很可能会导致一个节点上存在多个分片,一旦该节点故障,即使保持了1个以上的副本,同样有可能会导致数据丢失,集群无法恢复。所以, 一般都设置分片数不超过节点数的3倍。
-
主分片,副本和节点最大数之间数量,我们分配的时候可以参考以下关系:
节点数<=主分片数*(副本数+1)
创建索引的时候需要控制分片分配行为,合理分配分片,如果后期索引所对应的数据越来越多,我们还可以通过_索引别名_等其他方式解决。
调整分片分配器的类型
以上是在创建每个索引的时候需要考虑的优化方法,然而在索引已创建好的前提下,是否就是没有办法从分片的角度提高了性能了呢?当然不是,首先能做的是调整分片分配器的类型,具体是在 elasticsearch.yml 中设置 cluster.routing.allocation.type 属性,共有两种分片器 even_shard, balanced(默认)。
even_shard 是尽量保证每个节点都具有相同数量的分片, balanced 是基于可控制的权重进行分配,相对于前一个分配器,它更暴漏了一些参数而引入调整分配过程的能力。
每次ES的分片调整都是在ES上的数据分布发生了变化的时候进行的,最有代表性的就是有新的数据节点加入了集群的时候。当然调整分片的时机并不是由某个阈值触发的,ES内置十一个裁决者来决定是否触发分片调整,这里暂不赘述。另外,这些分配部署策略都是可以在运行时更新的,更多配置分片的属性也请大家自行查阅网上资料。
推迟分片分配
对于节点瞬时中断的问题,默认情况,集群会等待一分钟来查看节点是否会重新加入,如果这个节点在此期间重新加入,重新加入的节点会保持其现有的分片数据,不会触发新的分片分配。这样就可以减少 ES 在自动再平衡可用分片时所带来的极大开销。
通过修改参数 delayed_timeout ,可以延长再均衡的时间,可以全局设置也可以在索引级别进行修改:
PUT /_all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
通过使用 _all 索引名,我们可以为集群里面的所有的索引使用这个参数,默认时间被延长成了 5 分钟。
这个配置是动态的,可以在运行时进行修改。如果你希望分片立即分配而不想等待,你可以设置参数: delayed_timeout: 0。
延迟分配不会阻止副本被提拔为主分片。集群还是会进行必要的提拔来让集群回到 yellow 状态。缺失副本的重建是唯一被延迟的过程。
索引优化
Mapping建模
-
尽量避免使用nested或 parent/child,能不用就不用;
nested query慢, parent/child query 更慢,比nested query慢上百倍;因此能在mapping设计阶段搞定的(大宽表设计或采用比较smart的数据结构),就不要用父子关系的mapping。
-
如果一定要使用nested fields,保证nested fields字段不能过多,目前ES默认限制是50。参考:
index.mapping.nested_fields.limit :50因为针对1个document, 每一个nested field, 都会生成一个独立的document, 这将使Doc数量剧增,影响查询效率,尤其是Join的效率。
-
避免使用动态值作字段(key),动态递增的mapping,会导致集群崩溃;同样,也需要控制字段的数量,业务中不使用的字段,就不要索引。
控制索引的字段数量、mapping深度、索引字段的类型,对于ES的性能优化是重中之重。以下是ES关于字段数、mapping深度的一些默认设置:
index.mapping.nested_objects.limit :10000 index.mapping.total_fields.limit:1000 index.mapping.depth.limit: 20 -
不需要做模糊检索的字段使用
keyword类型代替text类型,这样可以避免在建立索引前对这些文本进行分词。 -
对于那些不需要聚合和排序的索引字段禁用Doc values。
Doc Values 默认对所有字段启用,除了
analyzed strings。也就是说所有的数字、地理坐标、日期、IP 和不分析(not_analyzed)字符类型都会默认开启。因为 Doc Values 默认启用,也就是说ES对你数据集里面的大多数字段都可以进行聚合和排序操作。但是如果你知道你永远也不会对某些字段进行聚合、排序或是使用脚本操作, 尽管这并不常见,这时你可以通过禁用特定字段的 Doc Values 。这样不仅节省磁盘空间,也会提升索引的速度。
要禁用 Doc Values ,在字段的映射(mapping)设置
doc_values: false即可。
索引设置
-
如果你的搜索结果不需要近实时的准确度,考虑把每个索引的
index.refresh_interval改到 30s或者更大。 如果你是在做大批量导入,设置refresh_interval为-1,同时设置number_of_replicas为0,通过关闭 refresh 间隔周期,同时不设置副本来提高写性能。文档在复制的时候,整个文档内容都被发往副本节点,然后逐字的把索引过程重复一遍。这意味着每个副本也会执行分析、索引以及可能的合并过程。
相反,如果你的索引是零副本,然后在写入完成后再开启副本,恢复过程本质上只是一个字节到字节的网络传输。相比重复索引过程,这个算是相当高效的了。
-
修改
index_buffer_size的设置,可以设置成百分数,也可设置成具体的大小,最多给512M,大于这个值会触发refresh。默认值是JVM的内存10%,但是是所有切片共享大小。可根据集群的规模做不同的设置测试。indices.memory.index_buffer_size:10%(默认) indices.memory.min_index_buffer_size: 48mb(默认) indices.memory.max_index_buffer_size -
修改 translog 相关的设置:
-
a. 控制数据从内存到硬盘的操作频率,以减少硬盘IO。可将
sync_interval的时间设置大一些。index.translog.sync_interval:5s(默认)。 -
b. 控制 tranlog 数据块的大小,达到 threshold 大小时,才会 flush 到 lucene 索引文件。
index.translog.flush_threshold_size:512mb(默认)
-
_id字段的使用,应尽可能避免自定义_id, 以避免针对ID的版本管理;建议使用ES的默认ID生成策略或使用数字类型ID做为主键,包括零填充序列 ID、UUID-1 和纳秒;这些 ID 都是有一致的,压缩良好的序列模式。相反的,像 UUID-4 这样的 ID,本质上是随机的,压缩比很低,会明显拖慢 Lucene。
-
_all字段及_source字段的使用,应该注意场景和需要,_all字段包含了所有的索引字段,方便做全文检索,如果无此需求,可以禁用;_source存储了原始的document内容,如果没有获取原始文档数据的需求,可通过设置includes、excludes 属性来定义放入_source的字段。 -
合理的配置使用index属性,analyzed 和not_analyzed,根据业务需求来控制字段是否分词或不分词。只有 groupby需求的字段,配置时就设置成not_analyzed, 以提高查询或聚类的效率。
查询效率
-
使用批量请求,批量索引的效率肯定比单条索引的效率要高。
-
query_string或multi_match的查询字段越多, 查询越慢。可以在 mapping 阶段,利用 copy_to 属性将多字段的值索引到一个新字段,multi_match时,用新的字段查询。 -
日期字段的查询, 尤其是用now 的查询实际上是不存在缓存的,因此, 可以从业务的角度来考虑是否一定要用now, 毕竟利用
query cache是能够大大提高查询效率的。 -
查询结果集的大小不能随意设置成大得离谱的值, 如
query.setSize不能设置成Integer.MAX_VALUE, 因为ES内部需要建立一个数据结构来放指定大小的结果集数据。 -
尽量避免使用
script,万不得已需要使用的话,选择painless & experssions引擎。一旦使用 script 查询,一定要注意控制返回,千万不要有死循环(如下错误的例子),因为ES没有脚本运行的超时控制,只要当前的脚本没执行完,该查询会一直阻塞。如:{ “script_fields”:{ “test1”:{ “lang”:“groovy”, “script”:“while(true){print 'don’t use script'}” } } } -
避免层级过深的聚合查询, 层级过深的group by , 会导致内存、CPU消耗,建议在服务层通过程序来组装业务,也可以通过pipeline 的方式来优化。
-
复用预索引数据方式来提高 AGG 性能:
如通过
terms aggregations替代range aggregations, 如要根据年龄来分组,分组目标是: 少年(14岁以下) 青年(14-28) 中年(29-50) 老年(51以上), 可以在索引的时候设置一个age_group字段,预先将数据进行分类。从而不用按age来做range aggregations, 通过age_group字段就可以了。 -
Cache的设置及使用:
**a) QueryCache: **ES查询的时候,使用filter查询会使用query cache, 如果业务场景中的过滤查询比较多,建议将querycache设置大一些,以提高查询速度。
indices.queries.cache.size: 10%(默认),//可设置成百分比,也可设置成具体值,如256mb。当然也可以禁用查询缓存(默认是开启), 通过
index.queries.cache.enabled:false设置。**b) FieldDataCache: **在聚类或排序时,field data cache会使用频繁,因此,设置字段数据缓存的大小,在聚类或排序场景较多的情形下很有必要,可通过indices.fielddata.cache.size:30% 或具体值10GB来设置。但是如果场景或数据变更比较频繁,设置cache并不是好的做法,因为缓存加载的开销也是特别大的。
**c) ShardRequestCache: **查询请求发起后,每个分片会将结果返回给协调节点(Coordinating Node), 由协调节点将结果整合。
如果有需求,可以设置开启; 通过设置
index.requests.cache.enable: true来开启。不过,shard request cache 只缓存 hits.total, aggregations, suggestions 类型的数据,并不会缓存hits的内容。也可以通过设置
indices.requests.cache.size: 1%(默认)来控制缓存空间大小。
ES的内存设置
由于ES构建基于lucene, 而lucene设计强大之处在于lucene能够很好的利用操作系统内存来缓存索引数据,以提供快速的查询性能。lucene的索引文件segements是存储在单文件中的,并且不可变,对于OS来说,能够很友好地将索引文件保持在cache中,以便快速访问;因此,我们很有必要将一半的物理内存留给lucene ; 另一半的物理内存留给ES(JVM heap )。所以, 在ES内存设置方面,可以遵循以下原则:
-
当机器内存小于64G时,遵循通用的原则,50%给ES,50%留给lucene。
-
当机器内存大于64G时,遵循以下原则:
- a. 如果主要的使用场景是全文检索, 那么建议给ES Heap分配 4~32G的内存即可;其它内存留给操作系统, 供lucene使用(segments cache), 以提供更快的查询性能。
- b. 如果主要的使用场景是聚合或排序, 并且大多数是numerics, dates, geo_points 以及not_analyzed的字符类型, 建议分配给ES Heap分配 4~32G的内存即可,其它内存留给操作系统,供lucene使用(doc values cache),提供快速的基于文档的聚类、排序性能。
- c. 如果使用场景是聚合或排序,并且都是基于analyzed 字符数据,这时需要更多的 heap size, 建议机器上运行多ES实例,每个实例保持不超过50%的ES heap设置(但不超过32G,堆内存设置32G以下时,JVM使用对象指标压缩技巧节省空间),50%以上留给lucene。
-
禁止swap,一旦允许内存与磁盘的交换,会引起致命的性能问题。 通过: 在elasticsearch.yml 中 bootstrap.memory_lock: true, 以保持JVM锁定内存
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8A%80%E6%9C%AF%E5%88%86%E6%9E%90%E4%B8%83%E7%9A%84%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


