所有机器学习项目都适用的检查清单
作者:Harshit Tyagi
编译:ronghuaiyang
导读
构建端到端机器学习项目的任务检查清单。
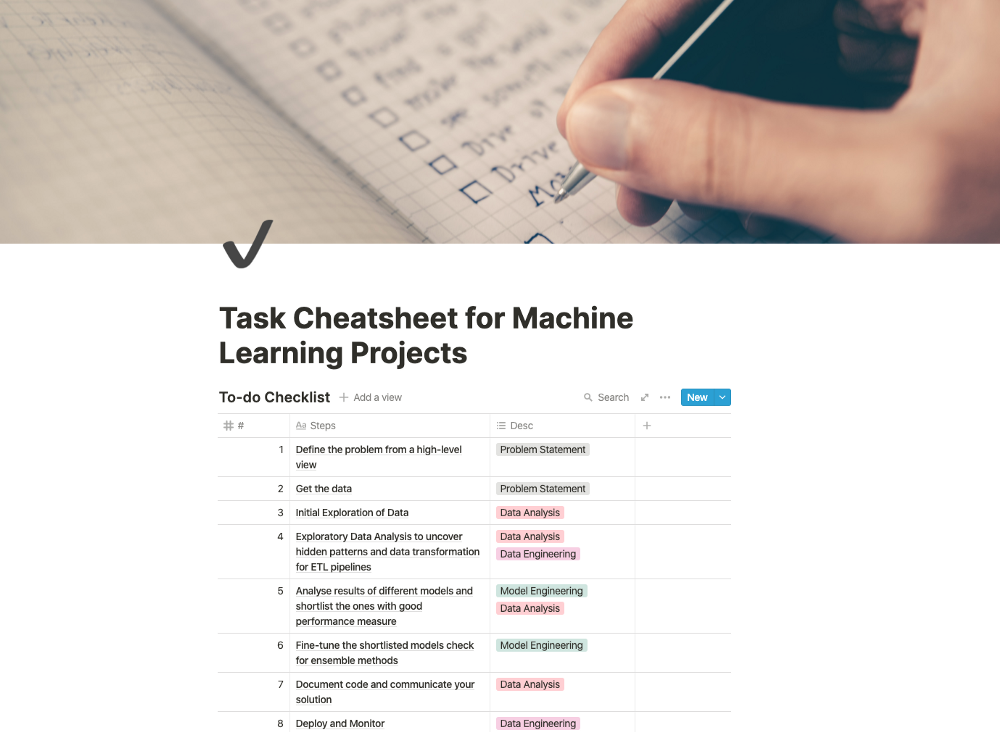
Image for post我正在创建一系列 有价值的项目,我想到了将我从别人那里学到的或在工作中开发的实践记录下来。在本博客中,我整理了在处理端到端ML项目时经常提到的任务清单。
为什么我需要一个清单?
因为在一个项目中,你需要处理许多元素(争吵、准备、问题、模型、调优等等),所以很容易失去对事情的了解。
这个清单可以引导你完成接下来的步骤,并促使你检查每一个任务是否执行成功。
有时,我们很难找到起点,清单可以帮助你从正确的来源引出正确的信息(数据),以便建立关系并揭示相关的见解。
最好的做法是让项目的每个部分都经历检查。
正如 Atul Gawande 在他的书“The Checklist Manifesto”中所说,
我们所知道的东西的数量和复杂性已经超出了我们个人正确、安全或可靠地利用其优点的能力。
所以,让我带你过一遍这个简单的清单,它将减少你的工作量,提高你的产出……
机器学习项目检查清单
在几乎每个ML项目中,你都必须执行8-10个步骤。其中一些步骤可以顺序互换执行。
1. 从高层次上定义问题
这是为了理解和阐明问题的业务逻辑。它会告诉你:
- 问题的性质(监督/非监督,分类/回归),
- 你可以开发的解决方案类型
- 你应该用什么标准来衡量表现?
- 机器学习是解决这个问题的正确方法吗?
- 手动解决问题的方法。
- 问题的固有假设
2. 确认数据来源并获取数据
在大多数情况下,如果你有了数据,并且希望围绕数据定义问题以更好地使用传入的数据,那么可以在第一步之前执行此步骤。
根据问题的定义,需要确定数据源,可以是数据库、数据存储库、传感器等。对于要部署在生产环境中的应用,应该通过开发数据管道来实现这一步的自动化,以保持传入的数据流入系统。
- 列出你需要的数据的来源和数量。
- 检查存储空间是否会成为一个问题。
- 检查你是否被授权为你的目的使用数据。
- 获取数据,并将其转换为可行的格式。
- 检查数据类型(文本、类别、数字、时间序列、图像)
- 取出一份样品作最终测试之用。
3. 初始的数据探索
在这一步中,你需要研究影响你的结果/预测/目标的所有特征。如果你有一个巨大的数据块,在此步骤中对其进行采样,以使分析更易于管理。步骤:
- 使用jupyter notebooks,因为它们提供了一个简单和直观的界面,以研究数据。
- 确定目标变量
- 识别特征的类型(类别、数字、文本等)
- 分析特征之间的相关性。
- 添加一些数据可视化,方便解释每个特征对目标变量的影响。
- 记录你的发现。
4. 进行数据探索分析来准备数据
现在可以通过定义用于数据转换、清洗、特征选择/特征工程和缩放的函数来执行前一步的发现了。
- 编写函数转换数据和自动化处理即将到来的批数据。
- 编写函数来清洗数据(输入缺失值和处理异常值)
- 编写函数来选择特征和特征工程 —— 删除冗余的特征,特征格式转换,以及其他的数学变换。
- 特征缩放 —— 特征标准化。
5. 开发一个基线模型,然后探索其他模型,选出最好的模型
创建一个非常基本的模型,作为所有其他复杂机器学习模型的基线。检查表的步骤:
- 使用默认参数训练一些
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%89%80%E6%9C%89%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E9%A1%B9%E7%9B%AE%E9%83%BD%E9%80%82%E7%94%A8%E7%9A%84%E6%A3%80%E6%9F%A5%E6%B8%85%E5%8D%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


