快手端上智能在快手上下滑推荐取得时长的应用实践

1.背景
1.1.端上智能
端上智能是相对于云计算人工智能应用(如推荐、搜索)的概念:如工业界成熟的推荐系统方案,几乎都是通过云计算的算力,在海量候选集中搜索用户感兴趣的 Feed,并通过复杂的精排模型(百亿至千亿级参数规模)将排序 Top 的 Feeds 列表发送给智能手机终端。智能手机终端在这个过程中,只是对云端下发的 Feeds 列表进行渲染,收集用户反馈进行上报,并没有执行推荐算法。所有 AI 算法全都部署在云端,智能手机通过网络请求才能获得云端 AI 计算的结果。
近些年智能手机等终端设备的算力有了显著提升,这些算力足以支持一些中等规模的 DNN 模型进行推理与训练,一些原本只能在云端运行的 AI 模块,可以部署在智能手机终端上,从而使得智能手机终端,在不依赖云端的情况下,也可以进行独立的 AI 计算。
目前业内,手淘猜你喜欢在端上智能落地方面已有实践,并取得较为显著收益(EdgeRec[1, 2], 双十一 ipv+10%, gmv+5%)。
1.2.上下滑推荐
上下滑推荐,相对于传统的 Feeds 流推荐,不再向用户展示 Feeds 封面列表,每一屏直接展示一个 Feeds 详情页内容,用户不能预知接下去展示的 Feeds(见图一)。
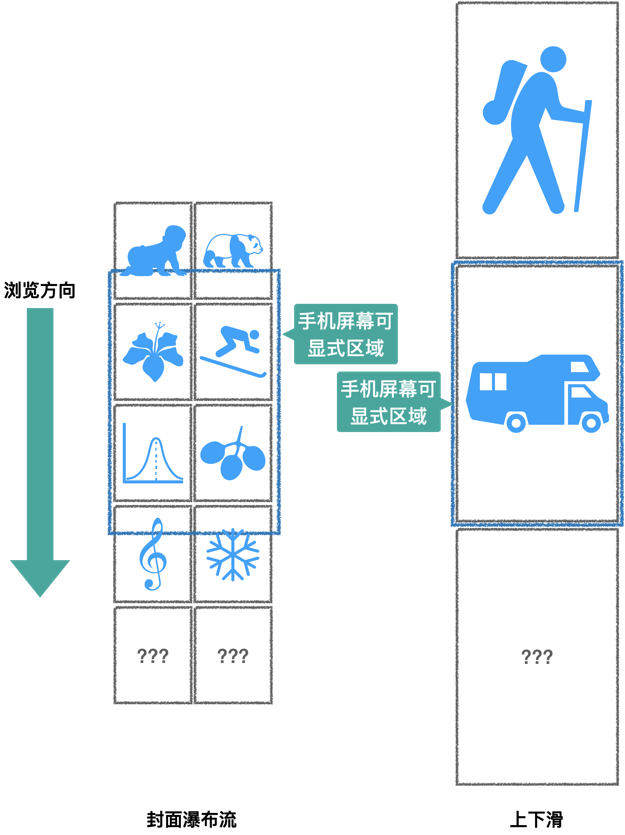
图一: 封面瀑布流与上下滑
对于上下滑这种推荐形式,很自然的想到,每一屏消费一个视频时,用户都会产生显式/隐式的反馈,推荐系统根据这些实时反馈可以及时修正用户偏好,下一屏即向用户推荐更好的作品。
遗憾的是,上下滑的推荐形式并不支持手机终端每屏都请求云端重新生成一个推荐结果。客户端每次请求服务端,实际会下发 PageSize(PageSize » 1)个 Feeds,等用户浏览完下发的 PageSize 个 Feeds 后,才会继续触发服务端推荐系统,重新计算并下发 PageSize 个 Feeds(见图二)。
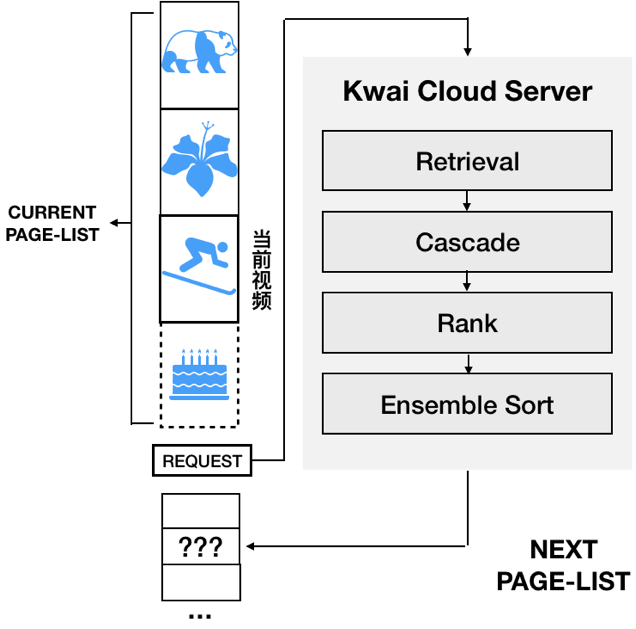
图二: 上下滑分页请求
这是因为:
1.客户端请求服务端天然存在显著的边界耗时成本(网络>100ms),请求服务端频率存在极限,用户快速滑动时极易卡顿。
2.减小 PageSize 会增加客户端对服务端的请求 qps,从而增加服务端的计算压力。
综上所述,目前基于云计算架构的推荐系统,不能实时响应用户的反馈修正推荐结果,已经难以满足上下滑推荐这种高频交互式推荐产品。
1.3. KIR: 上下滑推荐+端上智能
上下滑推荐这种全新的产品形式,使我们面临一个高频交互的推荐场景,暴露了云计算架构推荐系统的缺陷。我们基于端上智能技术设计并实现了 KIR(Kwai Instant Recommend)框架,使得智能手机终端具备 DNN 推理能力,用户每浏览一个 Feed,就能触发终端对未展示的候选 Feeds 集合进行重排序,实时修正用户偏好,向用户推荐更好的 Feed。
相对于 EdgeRec[1, 2]的工作,我们面临一个极高的 Baseline,服务端 PageSize 已在客户端流畅滑动与服务端请求压力允许的情况下,调整至一个极小值,使得端上智能即时推荐的潜在收益空间被压缩,对端上智能推荐系统与模型设计提出了更高的要求。另外,上下滑推荐作为一个高频交互的推荐场景,对即时推荐的需求也超过交互行为较稀疏的封面瀑布流推荐模式,端上智能是更适合上下滑推荐场景的技术。
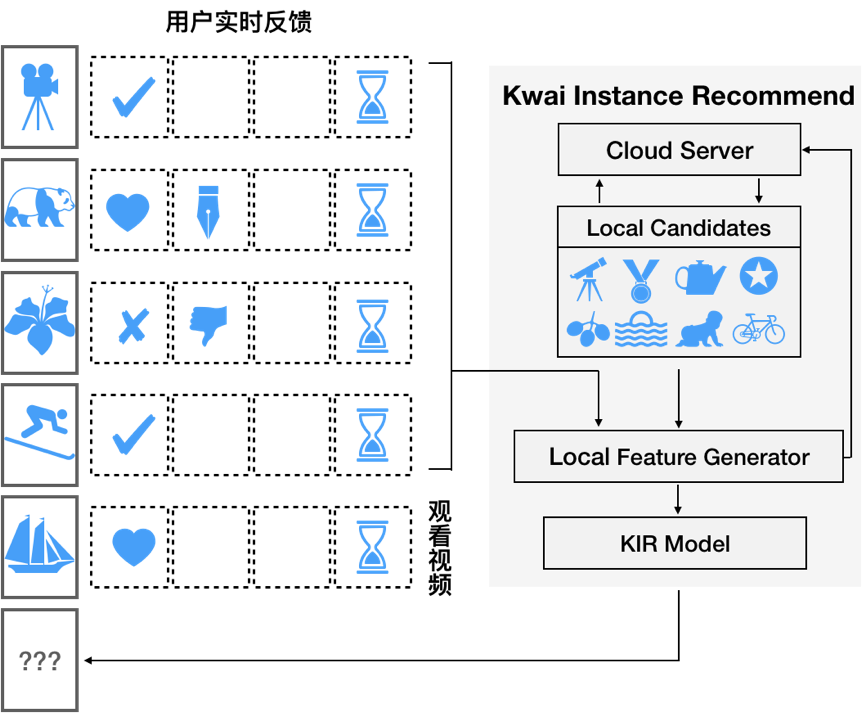
图三: KIR 推荐流程
KIR 上线后,对用户互动指标有非常显著的收益,更是取得了 APP 时长+1%的显著提升。
2.KIR 实时排序
2.1 系统架构
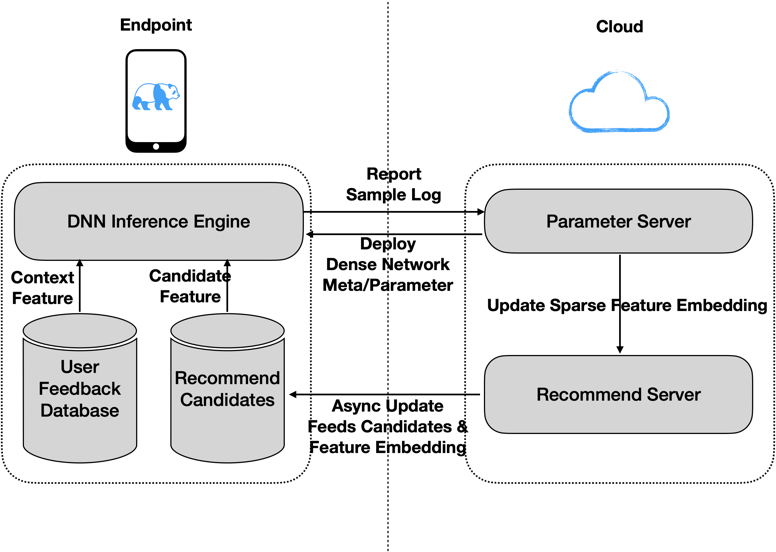
图四: KIR 系统架构
因为端上的计算资源受限,无法存储完整的超大规模参数模型,我们因此将训练的模型参数拆分成了 Dense Network 与 Sparse Feature Embedding 分别部署用于 DNN 计算推理:
1.DenseNetwork 被转化成 tflite 格式,存储在 K-CDN(KUAISHOU Content Delivery Network)上,供客户端启动时一次性拉取,载入 DNN 推理引擎(Tensorflow Lite)。DenseNetwork 参数较少,可持久存储在客户端本地。
2.SparseFeatureEmbedding 存储在服务端 EmbeddingServer 中,在推荐引擎下发 FeedList 时,会从 EmbeddingServer 获取当次下发结果 Rank 推理所需的部分 SparseFeatureEmbedding,与 FeedList 一同下发至客户端,在客户端与 DenseNetwork 合并,进行 Rank 推理。SparseFeatureEmbedding 全量极大(上亿系数参数),并且实时更新,因此需要存储在服务端。
2.2 推荐机制
KIR 仍然兼容云端推荐系统,终端每次获取服务端一个 Batch 的 Feeds,以此作为端上推荐的推荐候选池。KIR 端上推理引擎,实际是一个对推荐候选池进行排序的模块。对于上下滑推荐来说,KIR 不需要进行 list 推荐,无需考虑 list 间多样性,将排序简化为 NextOne 推荐,只需选出候选池中最好的作品,作为用户下一滑推荐,只需保证整体 session 的多样性即可。候选池中的 Feeds 不会全部展示,在触发一定的 TTL(TIME TO LIVE)淘汰机制后,便会全部清除,终端重新请求云端获取新的候选集。
2.3 算法模型
在快手极速版/精选模式等短视频上下滑场景中,因为用户无法预知接下来的 Feed 结果,所以用户对于已展示视频的反馈行为将会帮助我们更好的捕捉用户的实时兴趣变化。因此在 KIR 特征体系中,除了一般意义的用户侧与视频侧的类目特征与统计特征外,用户的实时反馈特征是重要的组成部分;这不仅包括点赞/关注/转发等直接交互行为,对于部分交互较少的用户,KIR 也可以通过完播/短播/长播等特征抽象用户的隐式反馈;此外,由于快手服务端精排模型已经较好的建模用户对于视频的点赞率/关注率/转发率等数十个目标,在终端再次对这些目标建模会带来巨大的计算开销,所以复用这部分服务端预估值作为特征会是一个更好的选择;同时,用户的实时网络环境,视频预加载进度都会直接影响用户浏览体验,因此在 KIR 特征体系中也需要考虑这部分特征;总体而言,KIR 系统的特征体系包括以下几个方面: (1) 用户特征 ,主要包括点赞数等统计特征以及用户侧序列特征等; (2) 视频特征,主要包括类目特征等; (3) 用户实时反馈特征; (4) 视频服务端预估特征; (5) 用户设备特征,主要包括设备网络状况/解码方式等;

表一: KIR 特征体系
受到以 Transformer 结构为代表的用户序列建模在工业届大量落地的启发,KIR 重排序模型在 DeepFM 模型基础上,同样使用 Mult-Head Self-Attention 结构构建高阶特征,探寻最优的下一刷视频;为了显示的引入时序特征,KIR 重排序模型同样加入了时间戳特征以及 Index 特征。基于 KIR 的特征体系,特别是每个视频不仅有 ID 类的类目属性特征,还包括服务端的预估特征,因此用户的实时反馈行为也应该对这两类特征分开建模,对于视频的 ID 类特征,用户的实时反馈体现在用户对于不同 ID 特征的偏好,而对于视频的服务端预估特征而言,用户的实时反馈可以理解为对预估值的一种修正;因此 KIR 模型通过两组独立 Transformer 结构分别抽象用户反馈对于这两部分特征的表征,并
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BF%AB%E6%89%8B%E7%AB%AF%E4%B8%8A%E6%99%BA%E8%83%BD%E5%9C%A8%E5%BF%AB%E6%89%8B%E4%B8%8A%E4%B8%8B%E6%BB%91%E6%8E%A8%E8%8D%90%E5%8F%96%E5%BE%97%E6%97%B6%E9%95%BF%E7%9A%84%E5%BA%94%E7%94%A8%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


