快手基于的实时计算持续优化与实践
摘要: 本文由快手实时计算负责人董亭亭分享,主要介绍快手基于 Flink 的持续优化与实践的介绍。内容包括:
- Flink 稳定性持续优化
- Flink 任务启动优化
- Flink SQL 实践与优化
- 未来的工作
一、Flink 稳定性持续优化
第一部分是 Flink 稳定性的持续优化。该部分包括两个方面,第一个方面,主要介绍快手在 Flink Kafka Connector 方面做的一些高可用,是基于内部的双机房读或双机房写和一些容错的策略。第二部分关于 Flink 任务的故障恢复。我们在加速故障恢复方面做了一些优化工作。

首先,介绍 Source 方面的高可用。在公司内部比较重要的数据写 Kafka 时,Kafka 层面为保障高可用一般都会创建双集群的 topic。双集群的 topic 共同承担全部流量,如果单集群发生故障,上游自动分流。Kafka 层面通过这种方式做到双集群的高可用。但是 Flink 任务在消费双集群 topic 时,本身是不能做到高可用的。Flink 任务通过两个 Source union 方式消费,Source 分别感知上游 topic 故障,单集群故障需手动将故障 Source 摘除。这种方式的缺点是故障时需要人工的干预,必须手动去修改代码的逻辑,程序内部本身是不能做到高可用的。这是做双机房读的背景。
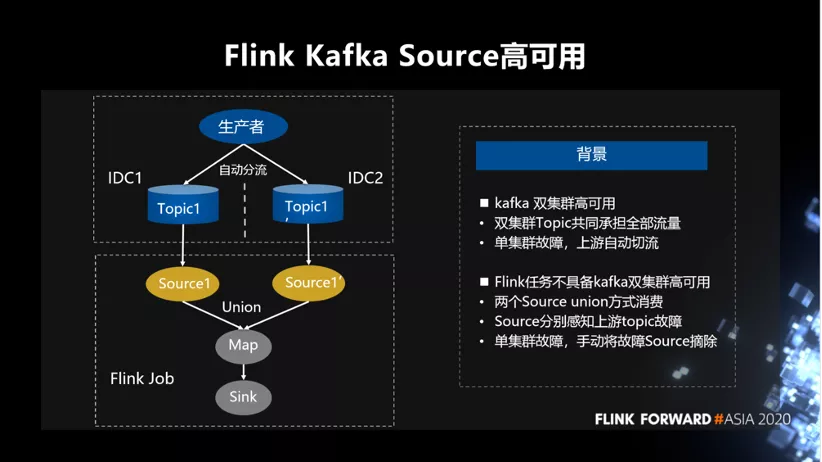
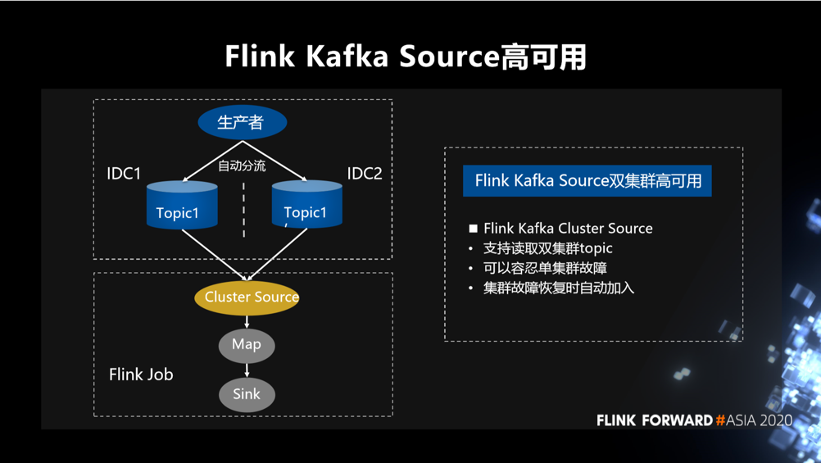
为了解决上述问题,我们封装了一个 Kafka 的 Cluster Source,它在 API 上支持读取双集群的 topic。同时做到,可以容忍单集群故障,集群故障恢复时也可以自动将故障集群重新加入。
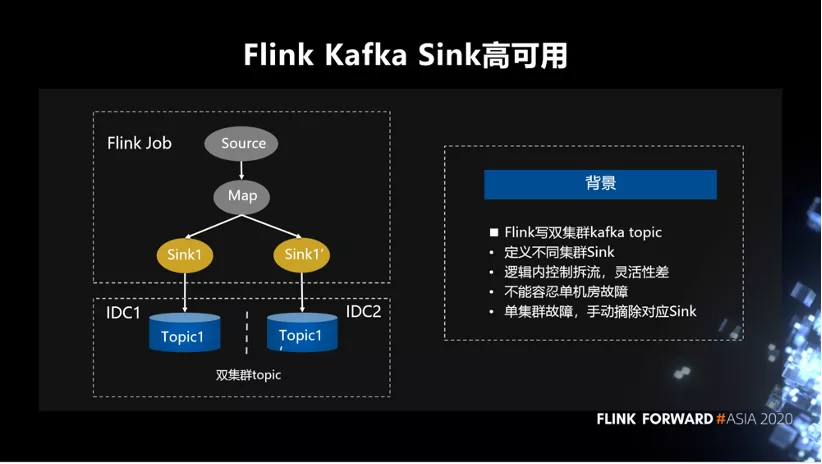
接下来是关于 Sink 方面的高可用。Flink 写双集群 Kafka topic,会定义不同集群 Sink,逻辑内控制拆流。这种方式灵活性差,且不能容忍单机房故障。如果单集群发生故障,仍需要手动摘除对应的 Sink。
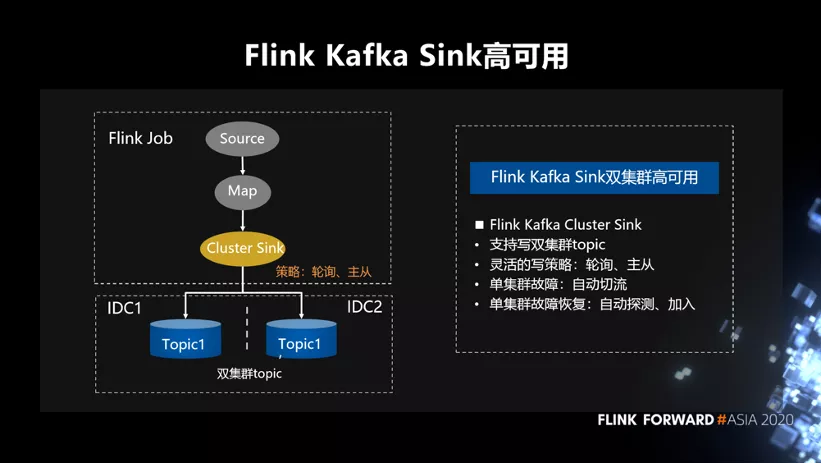
同样,针对 sink 我们也定制了一个 Cluster Sink,它 API 上支持写双集群 topic。具体写的策略,可以支持轮询和主从写的方式。如果单集群发生故障,逻辑内会自动将流量切到正常集群 topic。如果单集群故障恢复之后,也能感知到集群的恢复,可以自动的再把相应集群恢复回来。
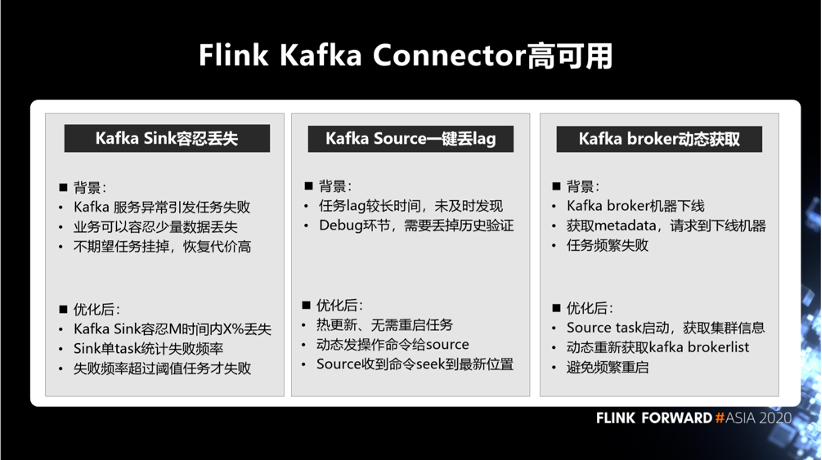
另外,基于 Kafka 的 connector,我们也做了一些容错的策略,这里提到三点。
- 第一点就是 Kafka Sink 容忍丢失。该问题的背景是,如果 Kafka 服务异常引发任务失败,并且业务可以容忍少量数据丢失,但是不期望任务挂掉的情况。针对该问题,我们的优化是,设置 Kafka Sink 容忍 M 时间内 X% 丢失。具体实现上,Sink 单 task 统计失败频率,失败频率超过阈值任务才失败。
- 第二点是 Kafka Source 一键丢 lag。该问题背景是, 一旦任务 lag 较长时间,未及时发现,或者任务 debug 环节,需要丢掉历史验证。之前只能靠重启任务来丢弃 lag,任务重启代码比较好,耗时长。我们优化后,可以热更新、无需重启任务即可以丢弃 lag。实现逻辑是动态发操作命令给 source,source 收到命令后 seek 到最新位置。
- 第三点是 Kafka broker 列表动态获取。该问题背景是, 生产环境中 Kafka broker 机器可能会故障下线,一旦请求到下线机器,会发生获取 metadata 超时,任务频繁失败。我们优化后,Source task 启动,可以获取集群信息,动态重新获取 Kafka brokerlist,避免频繁重启。
第二部分是 Flink 任务的故障恢复优化,分为两个过程。一个是故障发现,另外一个是故障恢复。实际的生产环境中,一些不稳定的因素会导致故障恢复的时间特别的长,用户的感知会比较差。同时,内部也有一些比较高优的任务,它对稳定性的要求比较高。我们希望做一些事情,把整个故障恢复的时间尽可能缩短。我们定了一个优化目标,20 秒内做到一个自动的恢复。
在故障发现阶段的优化包括三点:
- 第一,内部自研 Hawk 系统,5s 发现宕机。
- 第二,Yarn 整合 Hawk,快速感知宕机。
- 第三,Flink 感知宕机 container release。
在故障恢复阶段的优化包括:
- 第一,允许冗余部分 Container。
- 第二,适当调整 cancel task timeout 时间。
- 第三,针对适合任务开启 Region Failover。

二、Flink 任务启动优化
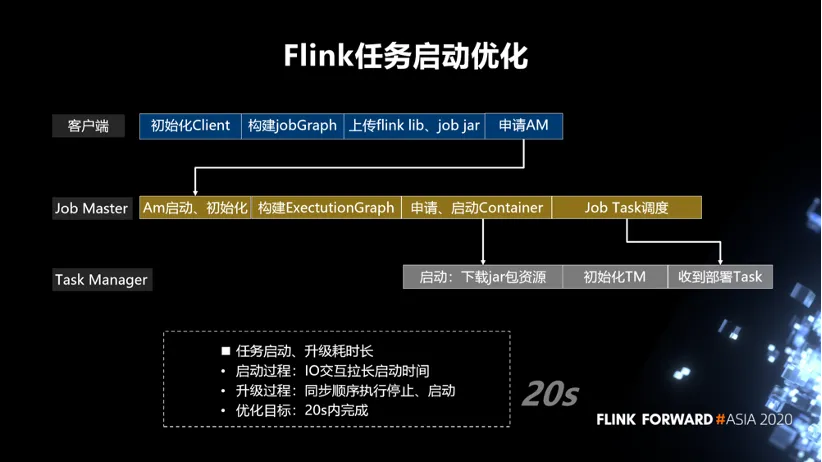
第二部分是任务启动优化,Flink 任务启动的时候,一般会涉及到比较多的角色,还有多个实例。如下图所示,它的启动在客户端包括,初始化 Client,构建 jobGraph,上传 Flink lib、job jar,申请 AM。在 Job Master,AM 启动后、初始化,构建 ExectutionGraph,申请、启动 Container,Job Task 调度。在 Task Manager 端, 容器申请到之后,启动下载 jar 包资源,再去初始化 Task Manager 服务,然后收到 task 后才会去做部署。我们发现,线上启动一个任务的时候,基本上在分钟级别,耗时比较长。如果有一些任务需要升级,比如说,改了一些简单的逻辑,需要将原来的任务停掉,然后再去重新启动一个新的任务,这种场景可能就会更慢。因此,我在任务启动的时候做一些优化,尽可能缩短任务启动的时间,业务的断流时间也进一步缩短。
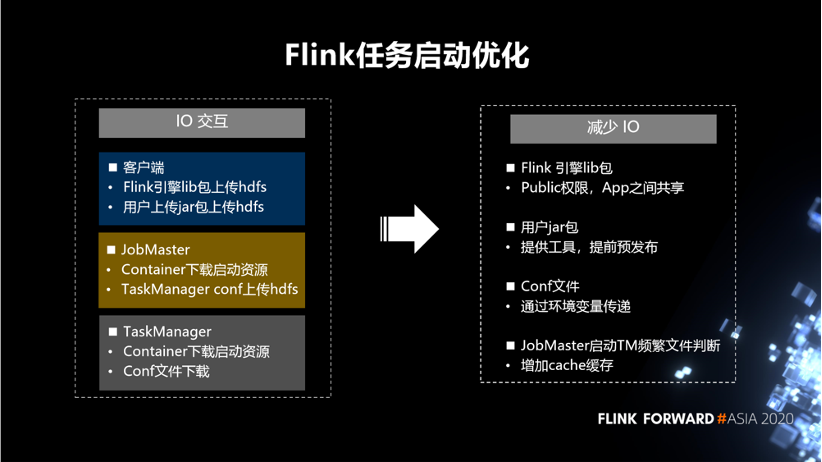
在 Flink 新任务启动优化方面,我们发现 IO 交互会比较耗时。在客户端的 IO 包括,Flink 引擎 lib 包上传 HDFS,用户上传 jar 包上传 HDFS。在 JobMaster 包括, Container 下载启动资源,TaskManager conf 上传 HDFS。在 TaskManager 包括, Container 下载启动资源,Conf 文件下载。
因此,想尽量的减少这样的一些 lO 的操作。针对 Flink 引擎 lib 包,设置 Public 权限,App 之间共享。对于用户 jar 包,提供工具,提前预发布到集群机器。对于 Conf 文件,通过环境变量传递。针对 JobMaster 启动 TM 频繁文件判断,增加 cache 缓存。
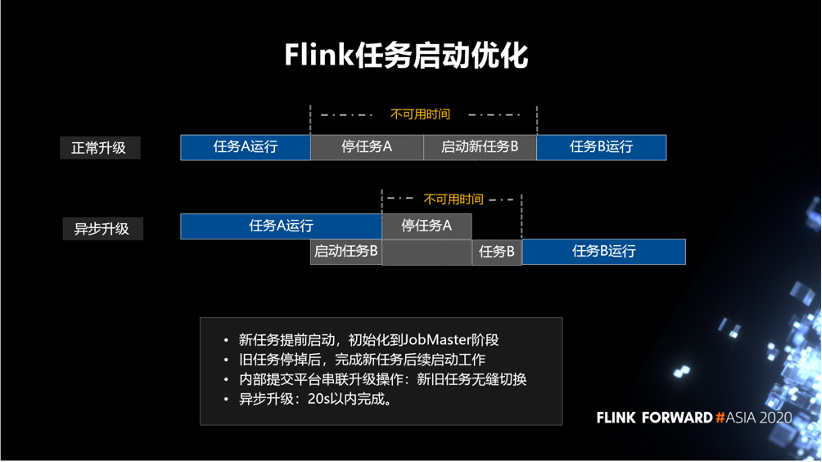
以上是针对一个新任务启动场景,下面介绍任务升级的场景。以前是同步升级,比如说,任务 A 在运行着,然后我要把任务 A 停掉,再去启动新的任务 B。如下图所示,不可用时间包括停任务 A 和启动新任务 B。是否可以不用等任务 A 完全停掉之后,再启动任务 B。针对这个想法我们做了一个异步升级的策略。新任务提前启动,初始化到 JobMaster 阶段。旧任务停掉后,完成新任务后续启动工作,这样新旧任务无缝切换。通过内部提交平台将该步骤串联起来,目标是异步升级在 20s 以内完成。
三、Flink SQL 实践与优化
第三部分会介绍一下我们在使用 Flink SQL 的一些实践和优化。首先介绍一下 Flink SQL 在快手的现状。目前,我们内部 Flink SQL 的任务占比在 30% 左右。Flink SQL 的任务个数是 360 多个。然后它的峰值处理的条目数还是比较高的,大约是 4亿每秒。在我们内部的一些重要活动的实时大屏的场景下,目前 Flink SQL 也作为一条链路,参与了相关指标的计算。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BF%AB%E6%89%8B%E5%9F%BA%E4%BA%8E%E7%9A%84%E5%AE%9E%E6%97%B6%E8%AE%A1%E7%AE%97%E6%8C%81%E7%BB%AD%E4%BC%98%E5%8C%96%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


