快手在千亿级用户特征数据分析中的应用与实践

分享嘉宾:陈杨 快手
编辑整理:Hoh Xil
内容来源:BigData NoSQL 12th Meetup
出品社区:DataFun
快手建设 HBase 差不多有2年时间,在公司里面有比较丰富的应用场景:如短视频的存储、IM、直播里评论 feed 流等场景。本次只分享其中的一个应用场景:快手 HBase 在千亿级用户特征数据分析中的应用与实践。为什么分享这个 Topic?主要原因:对于大部分公司来说,这都是一个普适的场景,因为很普遍,所以可选择的分析引擎也非常多,但是目前直接用 HBase 这种分析用户特征的比较少,希望通过今天的分享,大家在将来遇到这种场景时, 可以给大家提供一个新的解决方案。
本次分享内容包括:
-
业务需求及挑战:BitBase 引擎的初衷是什么;
-
BitBase 解决方案:在 HBase 基础上,BitBase 的架构是什么样;
-
业务效果:在快手的实际应用场景中,效果如何;
-
未来规划:中短期的规划。
▌业务需求及挑战
1. 业务需求
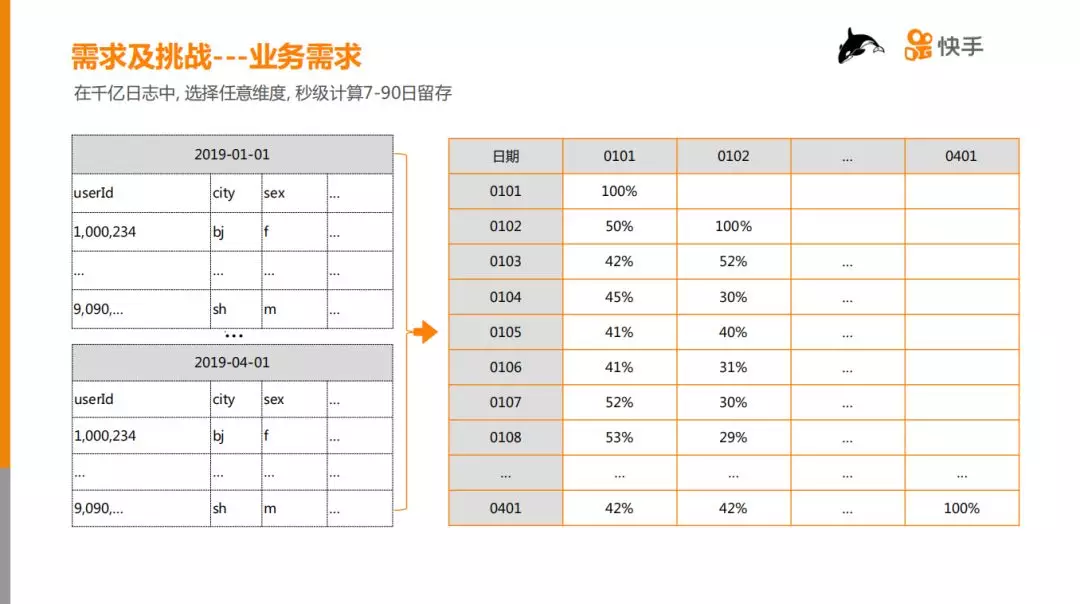
用一句话来概括业务需求:在千亿级日志中,选择任意维度,秒级计算7-90日留存。
如上图所示。左边是原始数据,可能跨90天,每一天的数据可以看作是一张 Hive 宽表,在逻辑上可以认为每行数据的 rowkey 是 userId(这里不严谨,userId 可能是重复的),需要通过90天的原始数据计算得到右边的表,它的横轴和纵轴都是日期,每个格子表示纵轴日期相对于横轴日期的留存率。
该需求的挑战:
-
日志量大,千亿级;
-
任意维度,如 city、sex、喜好等,需要选择任意多个维度,在这些维度下计算留存率;
-
秒级计算,产品面向分析师,等待时间不能过长,最好在1-2秒。
2. 技术选型
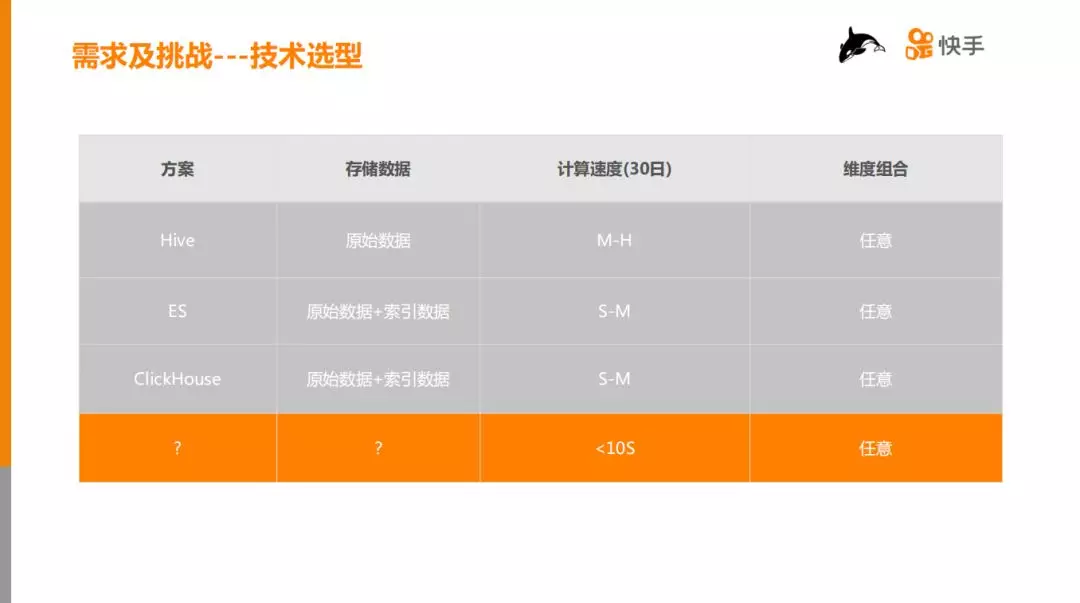
面对这些问题,我们当时的技术选型:
① Hive,因为大部分数据可能是存在 Hive 里,可以直接写 SQL 计算,该方案不用做数据迁移和转换,但是时延可能是分钟到小时级别,因此否定了这个方案。
② ES,通过原始数据做倒排索引,然后做一个类似计算 UV 的方式求解,但是在数据需要做精确去重的场景下,它的耗时比较大,需要秒到分钟级。
③ ClickHouse,ClickHouse 是一个比较合适的引擎,也是一个非常优秀的引擎,在业界被广泛应用于 APP 分析,比如漏斗,留存。但是在我们的测试的中,当机器数量比较少时 ( <10台 ),耗时依然在10秒以上。
立足于这种场景,是否存在其它解决方案,延迟可以做到2-3秒(复杂的场景10秒以下),同时支持任意维度组合?基于 HBase,结合业界简单/通用的技术, 我们设计并实现了 BitBase 解决方案,用很少的资源满足业务需求。
▌BitBase 解决方案
1. 数据模型
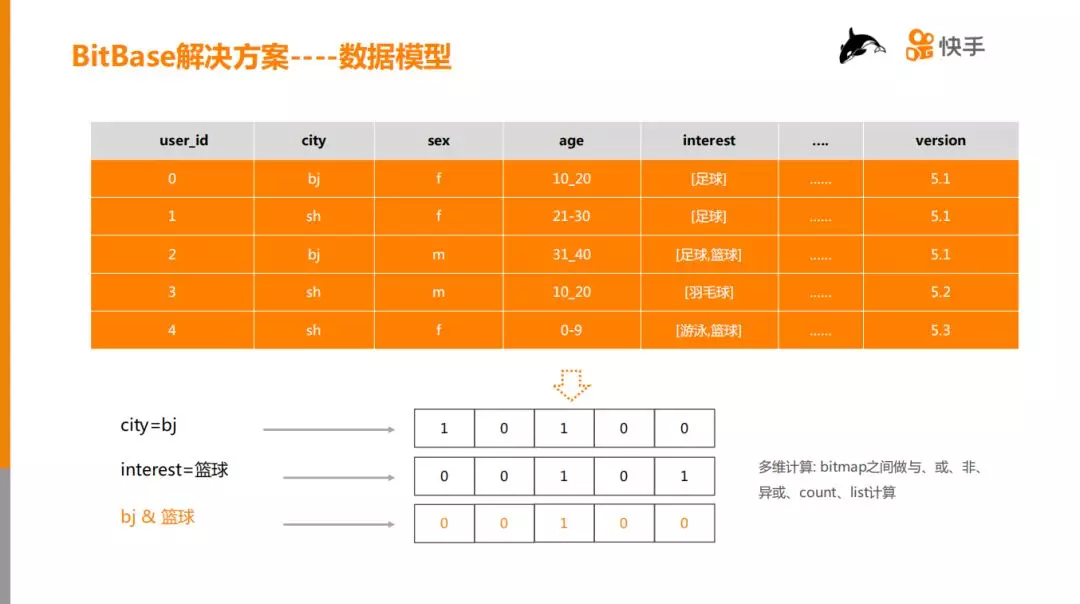
如上图所示,首先将原始数据的一列的某个值抽象成 bitmap(比特数组),举例:city=bj,city 是维度,bj (北京) 是维度值,抽象成 bitmap 值就是10100,表示第0个用户在 bj,第1个用户不在北京,依次类推。然后将多维度之间的组合转换为 bitmap 计算:bitmap 之间做与、或、非、异或,举例:比如在北京的用户,且兴趣是篮球,这样的用户有多少个,就转换为图中所示的两个 bitmap 做与运算,得到橙色的 bitmap,最后,再对 bitmap 做 count 运算。count 表示统计“1”的个数,list 是列举“1”所在的数组 index,业务上表示 userId。
2. BitBase 架构
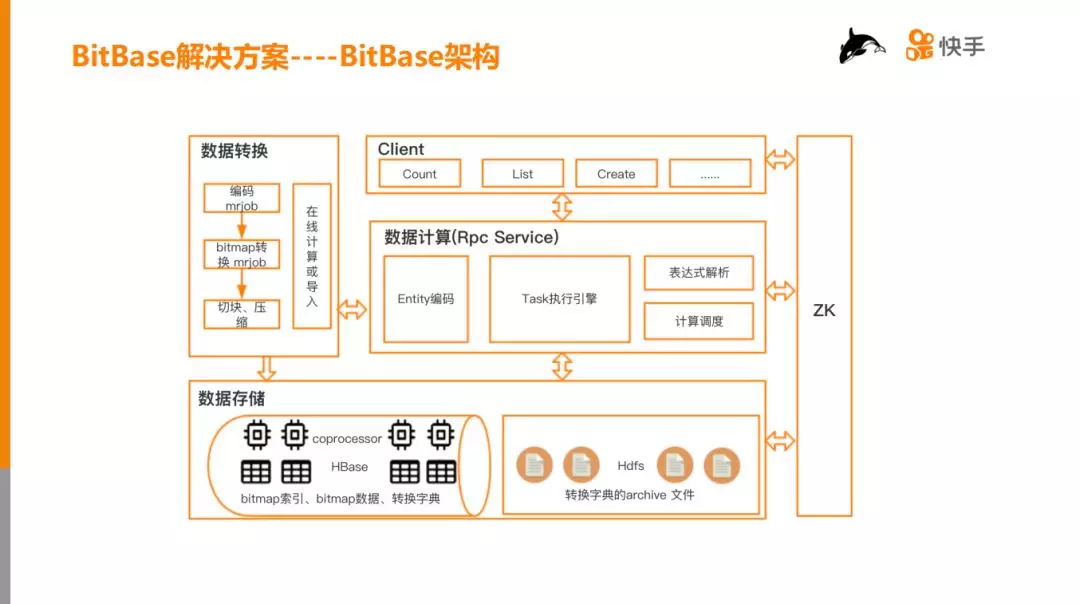
整个 BitBase 架构包括五部分:
-
数据存储:主要存储两类数据,一类数据是 bitmap 索引和数据,另一类是转换字典的归档文件(见后面描述)。
-
数据转换:有两种方式,第一种是通过 mrjob 转换,第二种是在线计算或导入;
-
数据计算:负责计算和调度,并把 IO 数据计算结果返回给 Client;
-
Client:站在业务的角度,把它们的业务逻辑分装成一个个业务的接口;
-
ZK:整个系统是一个分布式的服务,用 ZK 做管理。
3. 存储模块
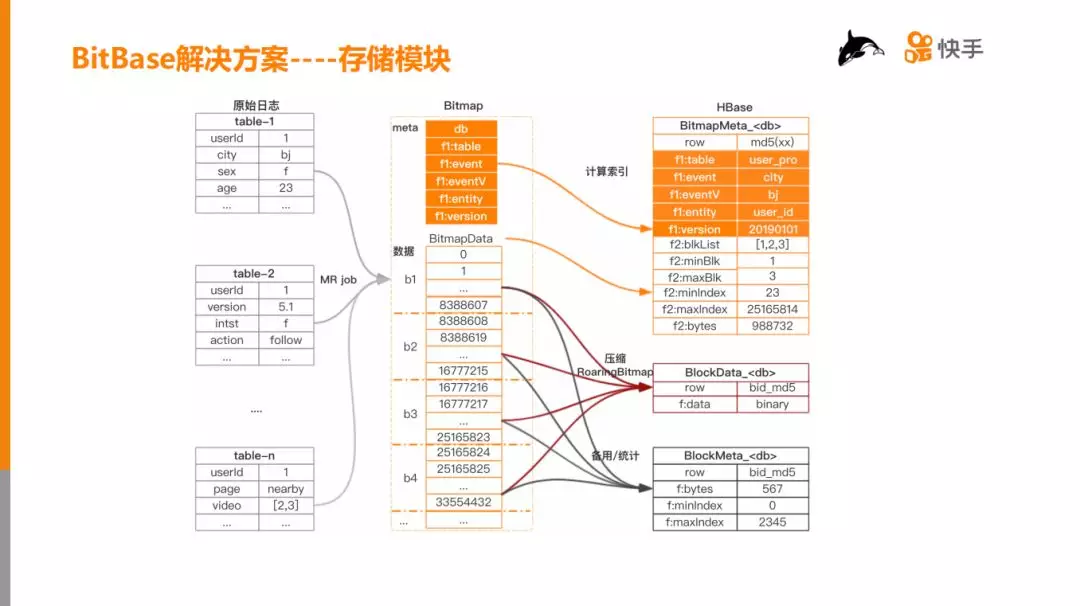
用数据存储设计的核心目的是让计算更快。
如上图,左边为一天的原始数据,包括多个 table,通过 mrjob 或者 rpc 的方式转换成中间的 bitmap。
bitmap 分为两部分,第一部分为 meta 信息(橙色部分),第二部分是 data 信息:
-
Meta 信息唯一定位一个 bitmap,db 可以认为是 hive 中的 db,table 也可以认为是 hive 中的 table,event 表示维度 (如:城市),eventv 表示维度值 (如:bj),entity 表示 userId(也可能是 photoId),version 表示版本。
-
BitmapData 从物理上讲是一个比特数组,把比特数组按照一定的大小进行切块:b1,b2,b3,…,bn,从而实现分块存储,分块计算。
最后把 bitmap 存在 HBase 的3张表中: 两张核心表和一张辅助表。
-
BitmapMeta, 保存 bitmap 的 meta 信息和一些 block 索引信息。
-
BlockData, 直接保存 bitmap block 数据。
-
BlockMeta,保存 block 的 meta 信息,起辅助作用。
4. 计算模块
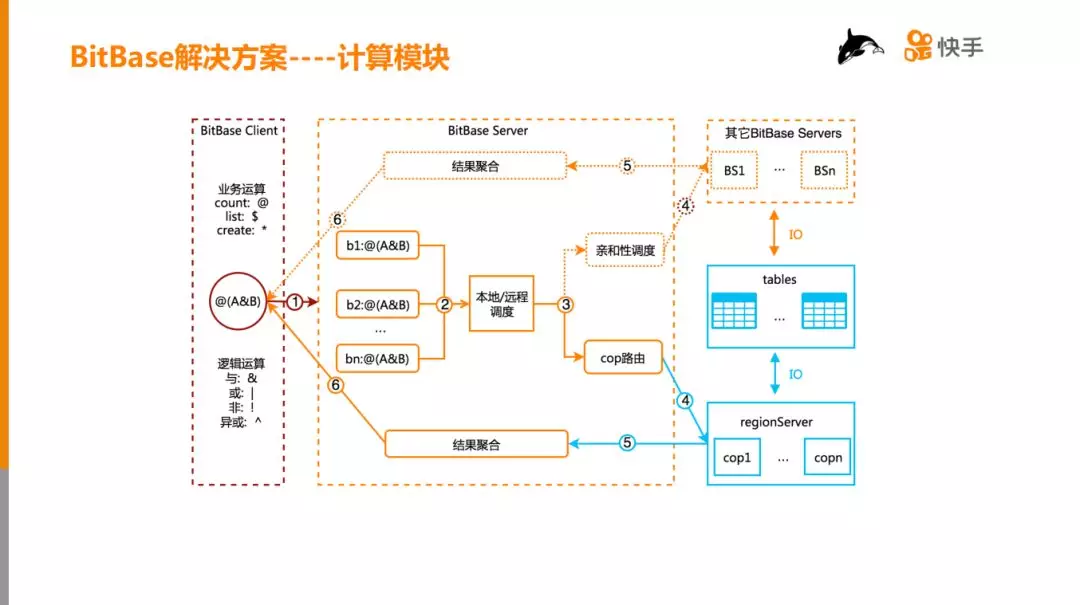
一个完整的计算流程涉及到三个组件:BitBase Client、BitBase Server 和 HBase regionServer。
① BitBase Client 首先把业务的需求封装成计算表达式,然后把计算表达式发给 BitBase Server;
② BitBaseServe 接收到请求后,从 BitmapMeta 表中查询 Block 索引,然后根据索引将表达式切分为 n 个子表达式;
③ 如果所有 bitmap 的 db 相同,则走 coprocessor 路由,否则按照数据亲和性,将 block 计算分发到其它 bitbaseServer 中。
④ 根据第3步的调度策略,分两条不同的路径计算 block 表达式
⑤ BitBase Server 聚合 block 计算表达式的结果,然后返回给 BitBase Client。
两种计算方式的对比:
-
非本地计算,解决跨 db 计算的需求,它主要的瓶颈在于网卡和 GC。
-
本地计算,解决同 db 计算的需求,它主要的瓶颈在 CPU 和 GC 上。整体上看本地计算的性能比非本地计算的性能提高3-5倍,所以要尽量采用本地计算方式。
5. DeviceId 问题
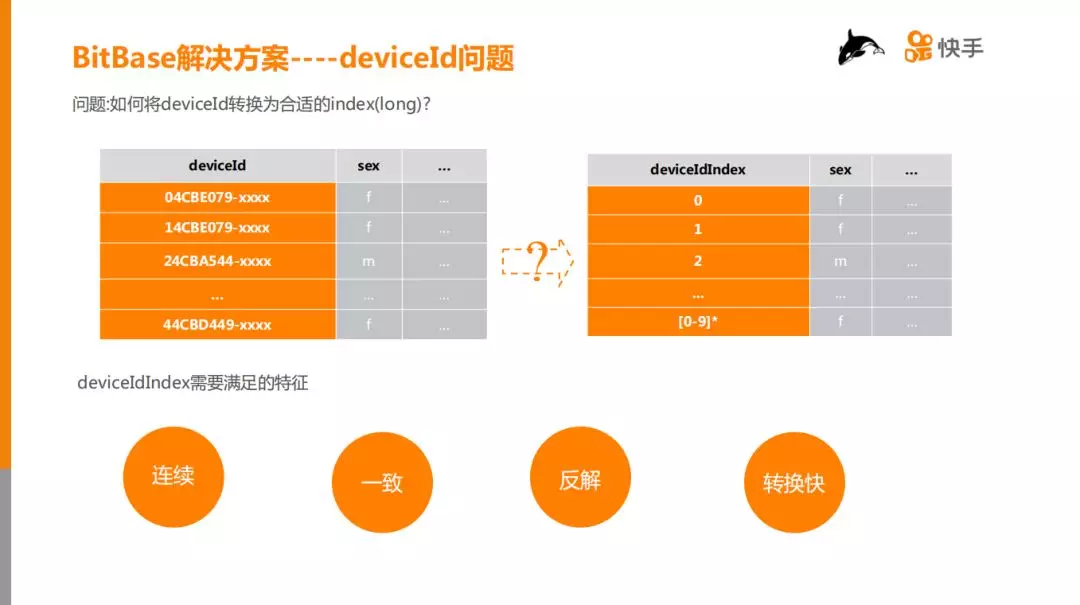
在引入 Bitmap 数据模型之后,我们隐含的也引入了一个非常大的问题:无法支持 deviceId。要支持 deviceId,首先需要将 deviceId 转化为数字类型,并且转换之后的 DeviceIdIndex 必须要满足四个条件:
① 连续:deviceIdIndex 如果存在空洞,会降低压缩效率,同时 Block 数量会增加,计算复杂度相应增加,最终计算变慢;
② 一致:deviceId 和 deviceIdIndex 必须是一一对应的,否则计算结果不准确;
③ 反解:根据 deviceIdIndex 能够准确、快速地反解成原始的 deviceId;
④ 转换快:在亿级数据规模下,deviceId 转化为 deviceIdIndex 的过程不能太长。
6. DeviceId 方案
连续、一致、支持反解:
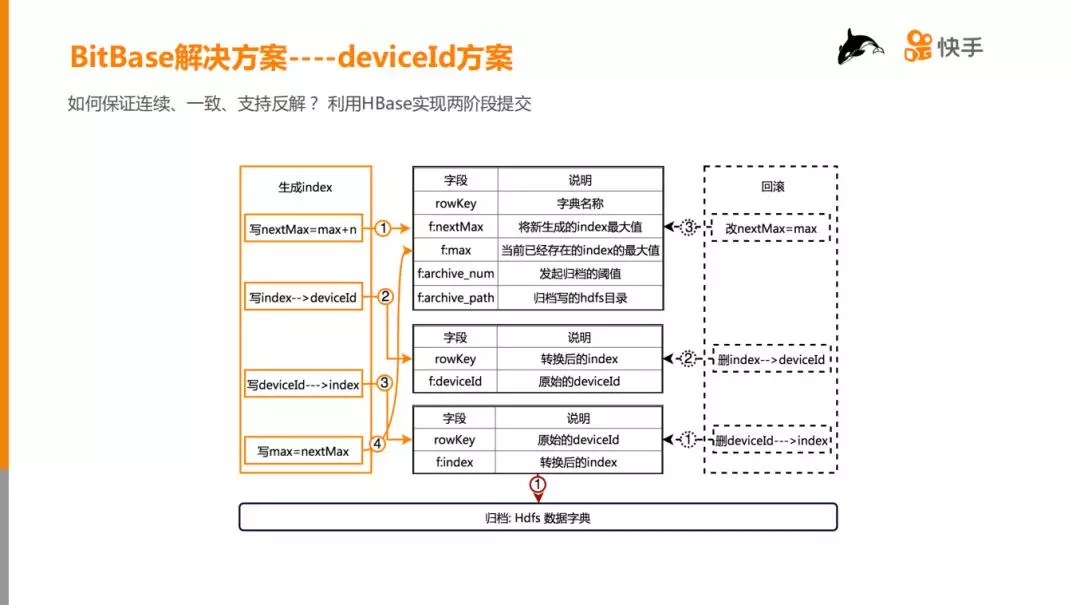
如何保证连续、一致、支持反解?解决方案非常简单,利用 HBase 实现两阶段提交协议。如上图中间实线部分所示,定义 deviceId 到 deviceIdIndex 的映射为字典。第一张表存储字典的 meta 信息;第二张表存储 index 到 de
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BF%AB%E6%89%8B%E5%9C%A8%E5%8D%83%E4%BA%BF%E7%BA%A7%E7%94%A8%E6%88%B7%E7%89%B9%E5%BE%81%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


