微博基于的机器学习实践
分享嘉宾:于茜 微博 高级算法工程师
编辑整理:王洪达
内容来源:Flink Forward
导读: 微博作为国内比较主流的社交媒体平台,目前拥有2.22亿日活用户和5.16亿月活用户。如何为用户实时推荐优质内容,背后离不开微博的大规模机器学习平台。本文由微博机器学习研发中心高级算法工程师于茜老师分享,主要内容包含以下四部分:
- 关于微博
- 微博机器学习平台 ( WML ) 总览
- Flink在WML中的应用
- 使用Flink的下一步计划
01关于微博

微博2008年上线,是目前国内比较主流的社交媒体平台,拥有2.22亿日活用户和5.16亿月活用户,为用户提供在线创作、分享和发现优质内容的服务;目前微博的大规模机器学习平台可以支持千亿参数和百万QPS。
02微博机器学习平台 ( WML ) 总览
接下来介绍一下微博机器学习平台,即WML的总览;机器学习平台 ( WML ) 为CTR、多媒体等各类机器学习和深度学习算法提供从样本处理、模型训练、服务部署到模型预估的一站式服务。
1. 总览
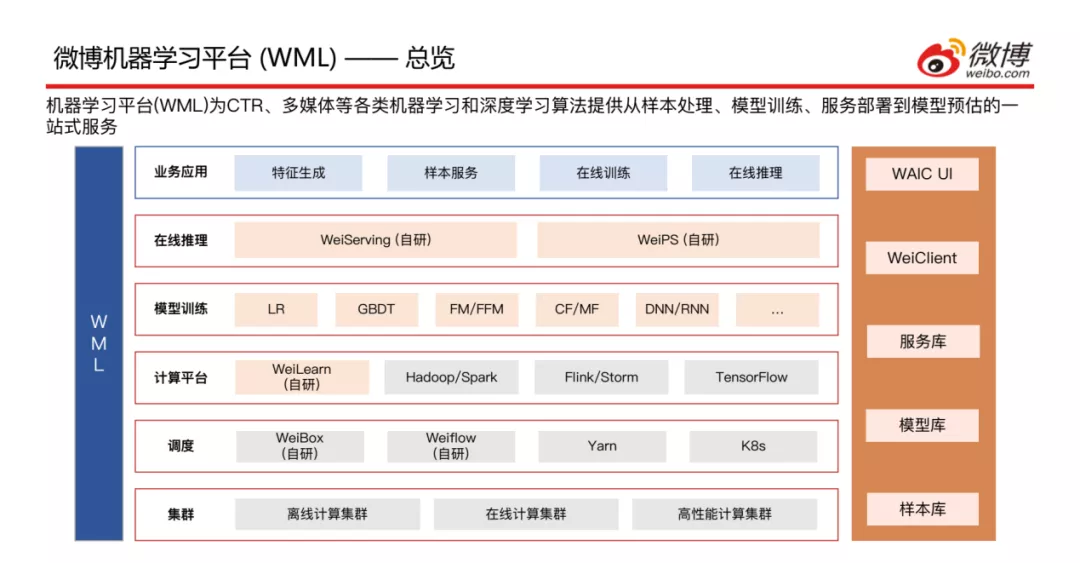
上方是WML的一个整体架构图,共分为六层,从下至上依次介绍:
- 集群层:包含离线计算集群、在线计算集群和高性能计算集群;
- 调度层:包含自研的WeiBox ( 提供使用通用的接口将任务提交到不同集群的能力 )、Weiflow ( 提供将任务间的依赖关系处理好、组成DAG工作流的能力 ),以及常见的调度引擎Yarn和K8s;
- 计算平台层:包含自研的WeiLearn ( 提供给用户在该平台做业务开发的能力 ),以及Hadoop/Spark离线计算平台、Flink/Storm在线计算平台和Tensorflow机器学习平台;
- 模型训练层:目前支持LR、GBDT、FM/FFM、CF/MF、DNN/RNN等主流的算法;
- 在线推理层:包含自研的WeiServing和WeiPS;
- 业务应用层:主要应用场景是特征生成、样本服务、在线训练和在线推理;
- 右边是自定义的一些概念,样本库、模型库、服务库以及两个任务提交方式WeiClient ( CLI方式提交 )、WAIC UI ( 界面操作 )。
2. 开发模式
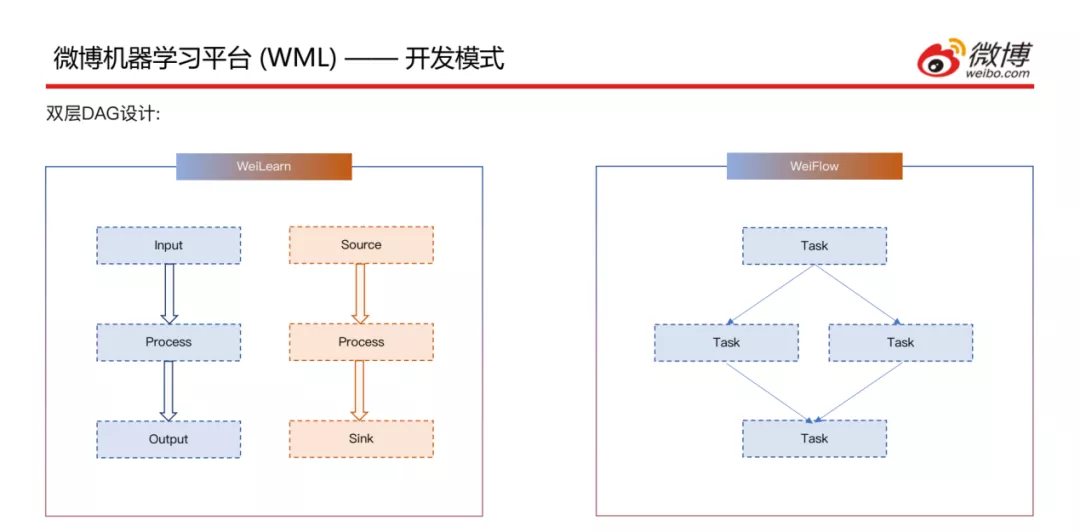
接下来介绍一下开发模式,有两层DAG的设计:
- 内层,WeiLearn层里面可以重写离线的Input、Process和Output方法以及实时的Source、Process和Sink方法,用户自己开发一个UDF来实现自己的业务逻辑;内层的每一个DAG都会组成一个Task。
- 外层,即第二层DAG层,WeiFlow层里面将WeiLearn中产生的Task的依赖关系组成一个集群内或者跨集群的WorkFlow,然后运行计算。
3. CTR模型
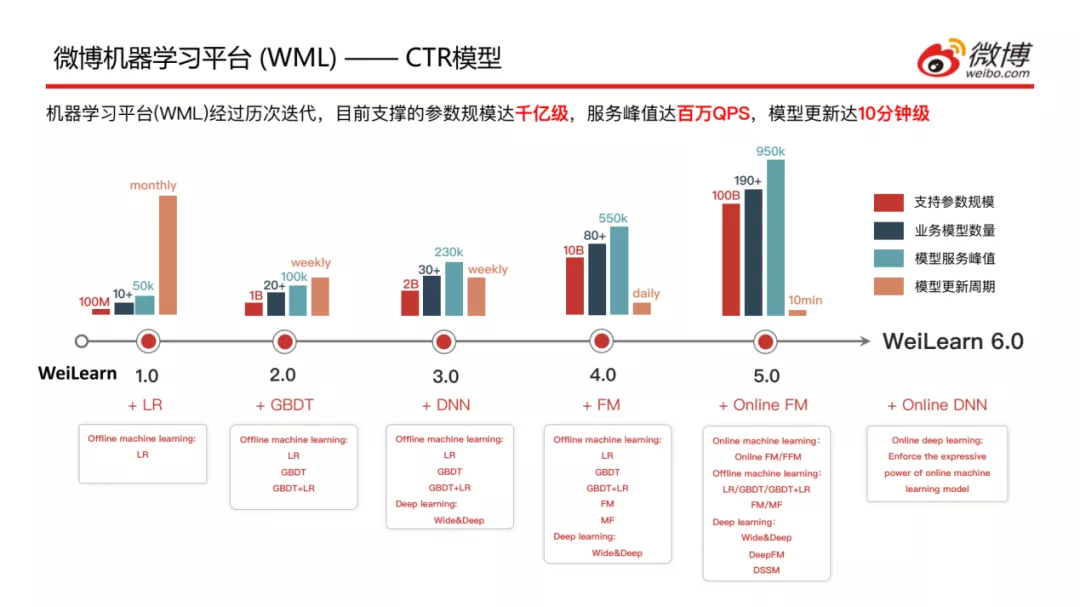
介绍一下CTR模型在微博迭代的情况,经过几年的研究和探索,目前支撑的参数规模达千亿级,服务峰值达百万QPS,模型更新的周期大概在10分钟左右;现在是Weilearn6.0版本,可以看到WeiLearn在不断完善更新自己的算法:
- 1.0版本仅支持LR离线学习
- 2.0版本支持LR/GBDT/LR+GBDT离线学习
- 3.0版本支持LR/GBDT/LR+GBDT离线学习以及Wide&Deep的深度学习
- 4.0版本支持LR/GBDTLR+GBDT/FM/MF离线学习以及Wide&Deep的深度学习
- 5.0版本支持Online FM/FFM在线学习,LR/GBDT/LR+GBDT/FM/MF离线学习以及Wide&Deep/DeepFM/DSSM的深度学习
- 6.0版本更新了Online DNN模型,加强在线机器学习模型的表达能力
03Flink在WML中的应用
下面介绍Flink在微博机器学习平台WML中的架构
1. 概览
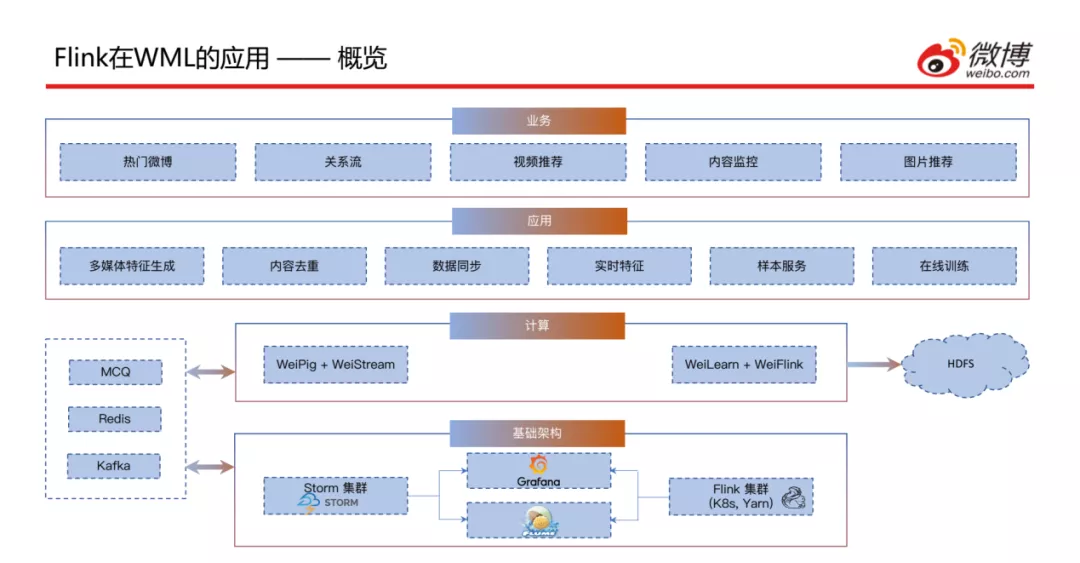
上图为实时计算平台的整体情况,接下来详细介绍一下各模块:
- 基础架构层:包含Storm集群、Flink集群、Flume以及用于监控系统运行的Grafana。
- 计算层:主要是对Pig和Flink的进一步封装,包含WeiPig + WeiStream和WeiLearn + WeiFlink;左侧为实时数据源,包含实时消息队列、Redis、Kafka;一些历史数据会存到右侧的HDFS中。
- 应用层:目前这套平台主要应用于多媒体特征生成、内容去重、数据同步、实时特征生成、样本服务以及在线训练。
- 业务层:支撑了目前微博主要的几个业务,包含热门微博、关系流、视频推荐、内容监控和图片推荐。
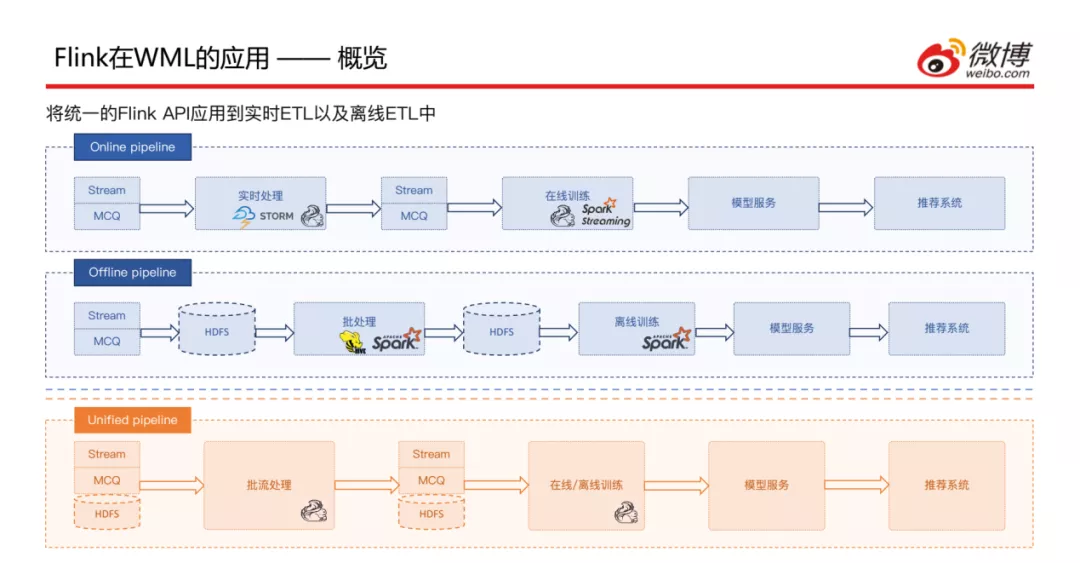
接下来看一下Flink在ETL的Pipeline中的概览:之前是有两个Pipeline,一个为在线的,以前是使用Storm进行的处理,目前正在往Flink迁移,两套现在处于并行状态,处理流程是从消息队列中获取数据进行处理,然后给到在线训练模块 ( Flink和Spark Streaming并行 ),最后提供模型服务给推荐系统调用;一个为离线的,和在线类似,首先写入到HDFS交给Hive或Spark进行处理,再次落到HDFS中交给离线训练使用,最后提供模型服务给推荐系统调用。因为有两类ETL的Pipeline,使用不同的框架,需要维护两套代码,维护成本较高。
目前做的就是将两套融合成一套,进行批流统一的处理,此处可能会用到FlinkSQL,然后将ETL后的数据输出到实时消息队列或者HDFS中,交给在线和离线模型训练,最后提供模型服务给推荐系统调用。
2. 样本服务
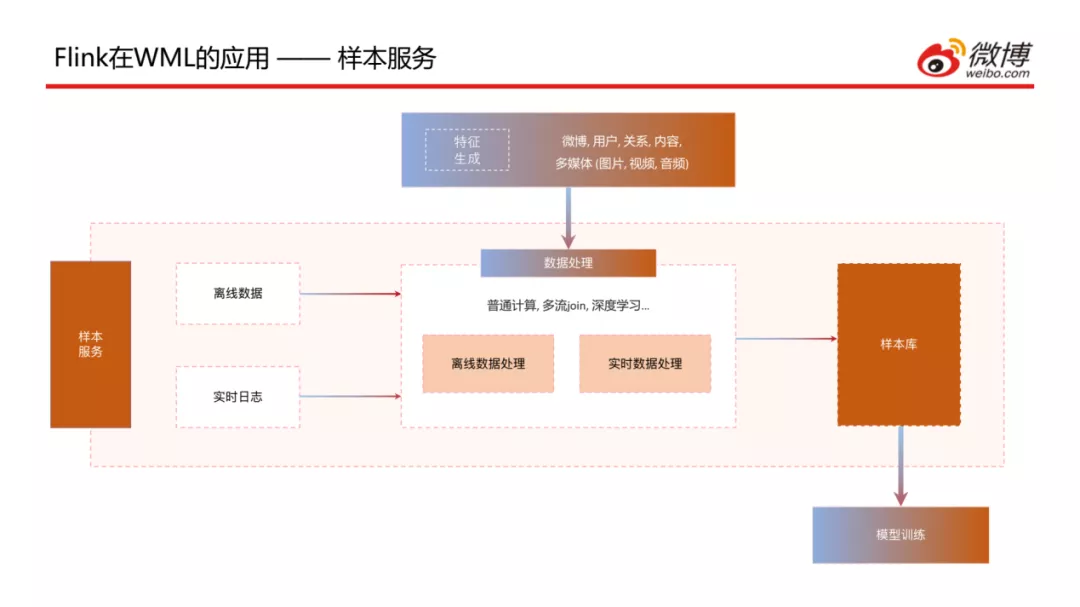
介绍一下样本生成服务,上图为该服务的整体架构图,包含样本数据的处理和计算等,除了一些生成的离线和实时数据外,还需要一些已经生成好的特征的引用,通过普通计算、多流Join、深度学习等处理方式生成样本,最后存储到样本库中供模型训练来调用。
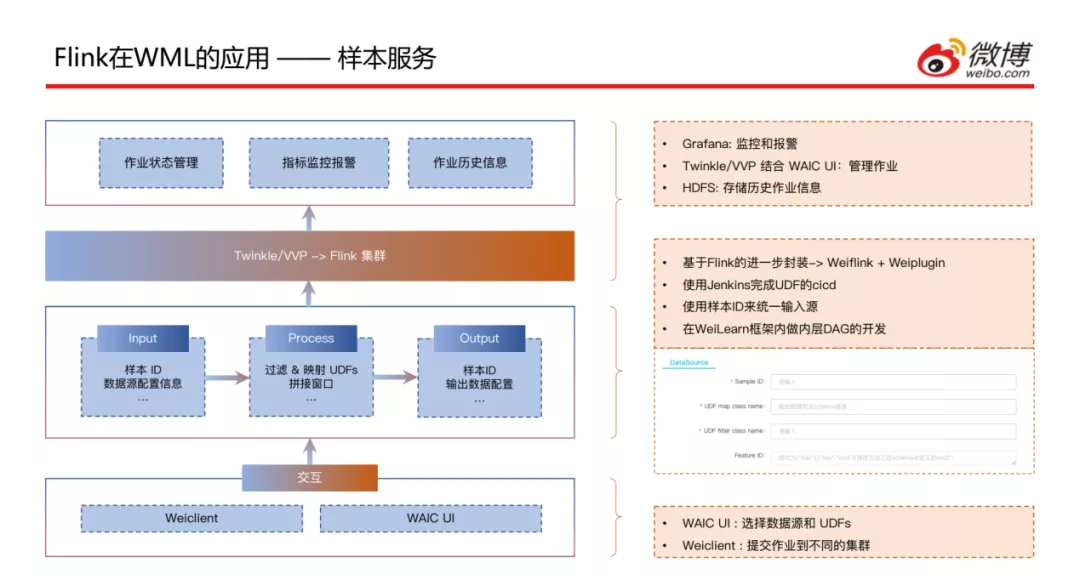
这个是样本服务任务提交的方式,可以通过之前提到的WeiClient命令行方式提交,也可以通过WAIC UI方式指定样本ID以及UDF的class name和要拼接的特征ID,通过一种统一的方式将作业提交到集群上;之后是通过Twinkle或VVP的方式提交到Flink集群,然后会对作业状态进行管理,通过Grafana进行监控和报警,将历史作业信息存储到HDFS中。
3. 多流Join
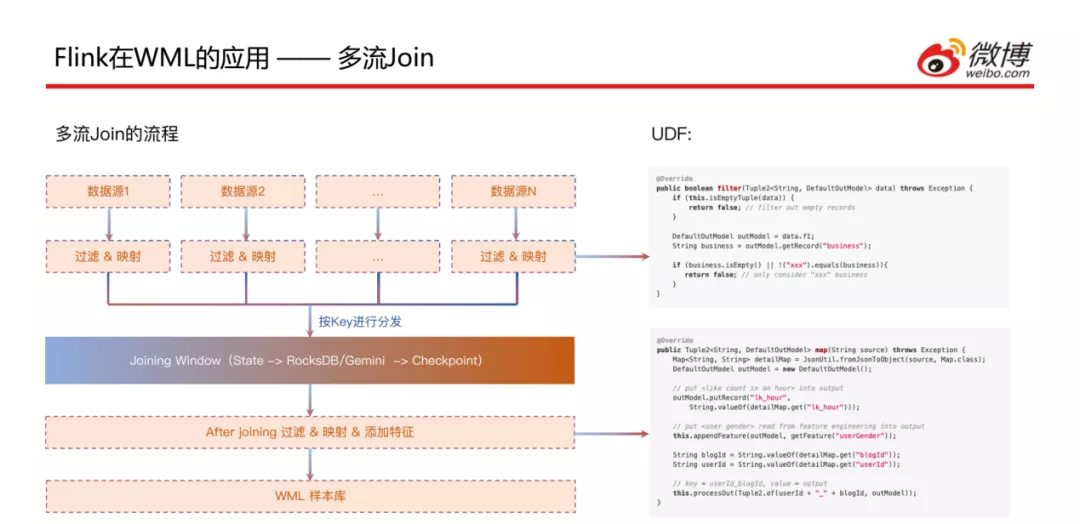
这是微博目前的一个主流场景,多数据流Join场景 ( 大部分是大于等于3 ):有N个数据源,通过过滤和映射的处理后按照Key进行分发,在Joining Window中进行join后 ( 此处后面会详细讲 ),会再进行一次过滤和映射以及添加特征,最后输出到样本库中。
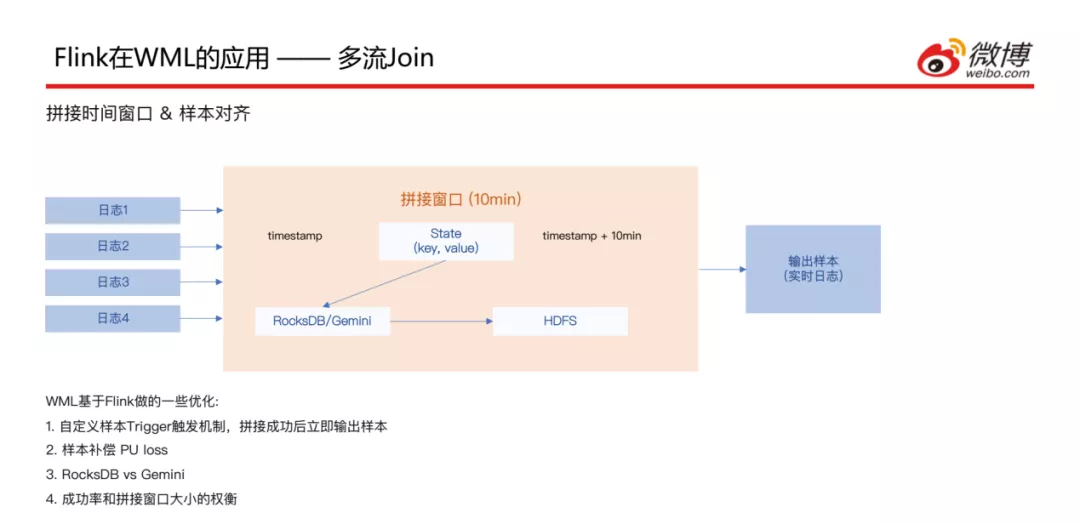
接下来看一下刚刚讲到的拼接窗口的实现方式,这是和业务比较相关的,对于CTR场景来说日志有很多种 ( 多个行为日志 ),但是到达的时间并不完全一致,比如点击这种行为日志可能会比曝光日志到的晚一些;这样就会需要一个时间窗口,以10分钟为例,如果某种日志先到了,就会将对应的key和value存储到State中,状态存储这块是基于RocksDB和HDFS做的;经过这个十分钟窗口之后,拼接好的样本数据会输到实时流中;此处基于Flink做了一些优化:
- 因为窗口是10分钟的,但是如果10分钟内日志数据已经全部到达,就不同等到10分钟窗口结束后再输出去;所以自定义了样本trigger触发机制,样本拼接成功后就可以立即输出,这样可以减少一些时延
- 样本补偿 PU loss;此处是基于Twitter在2019年发的一篇论文的实现方式,就是拿到正样本之后,首先对正样本做一个梯度下降的处理,另外可�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BE%AE%E5%8D%9A%E5%9F%BA%E4%BA%8E%E7%9A%84%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


