应用于实时视频通信的深度学习算法研究
众所周知,深度学习在实时视频通信端到端系统里有很多的应用,比如说我们用它做超分辨率,能取得比较好的效果;我们用它做图像恢复,也能取得比较好的效果。如果说提及挑战的话,在支持移动端的应用里,我们必须考虑复杂性的限制,必须要以一个小的模型,能够在移动平台上实时运行,而且功耗、CPU 占比都得到合适的限制。另外应该在相对合理的数据集上取得比较好的学习效果,让它的泛化能力很强。
简单展示一下结果,我们用传统的算法得到的效果通常比较模糊,基于深度学习的算法我们则能恢复出更多细节、甚至生成出一些细节。
从计算量来看,我们目前能做到把 480x360 放大到 960x720 在 iPhone6 的 GPU 上达到 120fps,使得复杂性得到比较有效的控制。
我们用生成对抗网络的方式来做超分,生成对抗网络最近两三年比较热,在人工智能学习算法的学术会议上,这两年甚至达到了 2/3 以上的论文都是跟生成对抗网络有关。生成对抗网络通常包括一个生成器和一个判别器,生成器尽量模拟真实数据,要像真实数据一样来欺骗判别器,让判别器认为生成的数据是真实的,符合真实数据的分布。判别器的任务正好相反,它要尽量的让生成的数据通不过考验,这个标准越高,通不过的概率就越高。所以生成器和判别器在彼此的矛盾冲突中共同进步,最终达到判别器也判别不出来是真是假这样一个程度。
生成器就是把一个随机的分布,一个噪声 Z,经过生成器之后产生一个图像能跟真的很像。下图形象地表示生成器在逼近真实数据的分布,绿色是这个模型产生的分布,在相互矛盾冲突之中逐渐达到真实数据就是黑色虚线的分布。Z,就是我刚才说的,比如说一个随机变量,它能生成出我们想要的结果,从公式上说实际上生成器在做一件事,它是使判别器犯错的概率最大,就是判别器分不出真假,分不出生成东西是假的,就是要让它犯错。
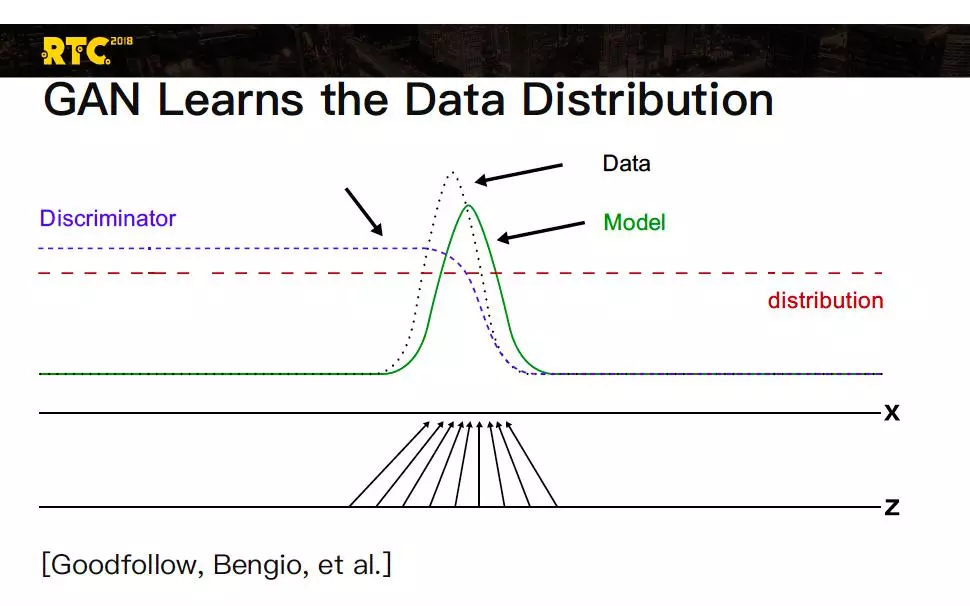
这个判别器,它是要首先最大化一个真实数据为真的这个概率,最小化生成器为真的概率就是我刚才说的矛盾冲突,用公式也是可以表示出来的。这个判别器的最佳解是有数学解的,就是达到纳什均衡。把这两个生成器和判别器综合到一起就是一个价值函数的最大最小优化。
这个有什么问题?这个生成器为了通过判别器的检验,就找了一些它比较好生成的模式来生成,所以训练完之后比如就大概率生成 1,因为 1 很好通过,就是一竖,所以生成器的学习某种意义上会耍点小聪明,它会试图学习那些最容易学的样本,多产生一些容易判对的样本,这就是生成器在做的情形,但这是不理想的情形。
换一个图来看,比如分布是一个均匀的圆,生成器可能最后收敛到某一个地方,总收敛到某一个地方也总通过。判别器因为总通过,网络状态最后就收敛这么一个状况。生成器比较难于生成这种多模态、有多个聚类的分布,我们把这个现象叫模式坍塌。
具体的挑战涉及什么,我简单说一下,我们怎么样缓解这个模式坍塌,就是使得生成器别陷入耍小聪明骗过了判别器的状态。第二是我们给定一个卷积神经网络,它表现有多好、学习能力有多强。换句话问,我们给定一个深度学习的任务,深度卷积神经网络能做到多小,还能达到比较好的效果。

为了降低模式坍塌出现的概率,首先通常会要求加一个局域的限制,要求生成器不仅要骗过判别器,而且要让它带有噪声的输入要像真实的样本,这样的话生成出来跟真实样本不会差太多。就相当于在损失函数上,加了一项,生成的东西要跟目标像,即监督学习。
再换一个角度看,实际上深度学习的神经网络,它是一个流形,这个流形是一个拓扑空间,能把流形同胚映射到 N 维的实数空间,同胚映射的意思就是正映射和逆映射都是连续的。我简单说一下这个概念,比如一个三维空间中的曲面,是一个二维的流形,从编码的角度来说,它可以对应一个隐空间,隐空间是二维的,正映射是降维,是个编码的过程,或者在分类的问题里我们会试图在隐空间里分的更好。反过来讲从隐空间到流形就是变成一个生成器,就是解码的过程,从精简的数据恢复到它看起来的外观是我们希望的样子。
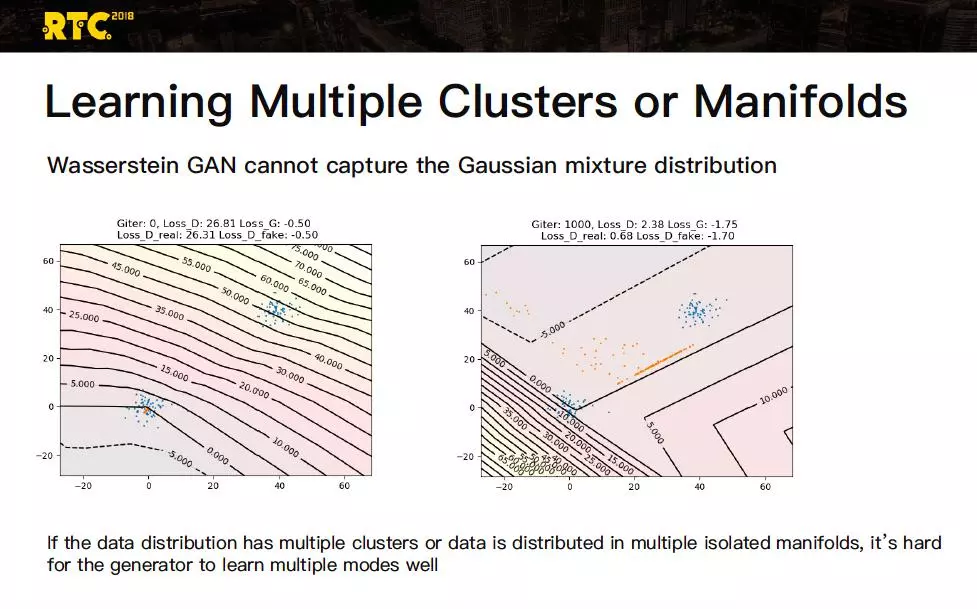
这个曲面在三维空间,我们叫环境空间。Wasserstein 设计了一个生成对抗网络其实也有很多层,到达十层的网络。他要做的事情就是把两个高斯分布:一个在零点,一个在 40×40 的地方,把分布学会。结果发现这个多达十层的一个深度学习网络居然学不会,当收敛之后表现为橘色这些点,就是最后收敛的状态。当数据分布有多个聚类或者多个峰值混合分布的时候,这样的流形对生成对抗网络是有挑战的。
卷积神经网络是什么?我们来看基于矫正的线性单元(ReLU)的卷积神经网络, 它可以看成是一个分段线性的映射,我们看这几个常用的激活函数其实都是分段线性,不管有参数还是随机的,都是分段线性的一个映射。
所以这个流形就被这些分段线性的映射分成了很多子空间,分成很多小的立方体,所以这个流形经过编码器之后就变成很多小空间,都是分段线性的,是多个小的多面体。
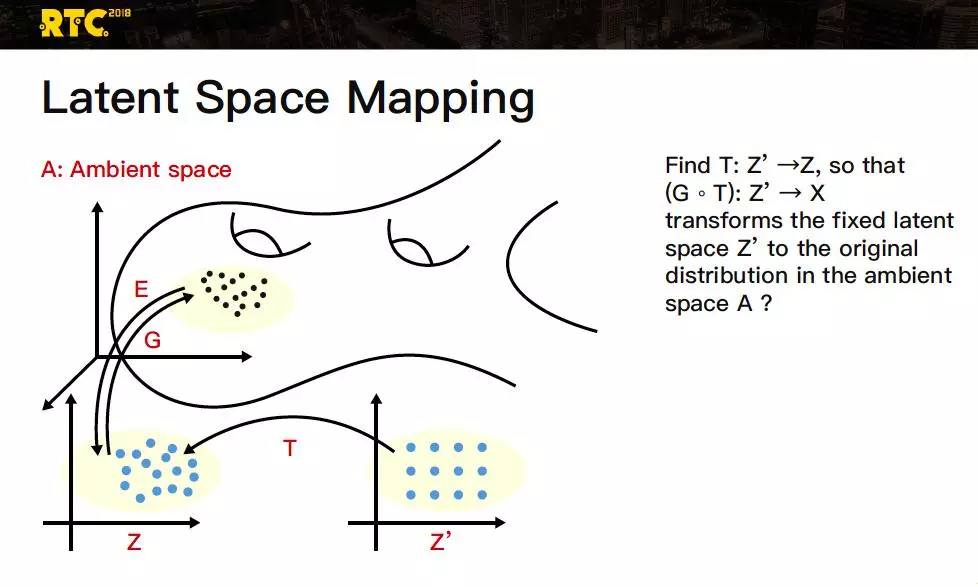
怎么理解这个模式坍塌是怎么来的?当编码器 E,把流形 M 映射到隐空间 E(M)之后,它的分布往往是极其不均匀的,在这个不均匀的奇异分布里要进行分类或者控制都是很难的。提一个问题,我们是否能引入另外一个隐空间,它能映射到 Z,与生成器 G 复合起来 G*T,能把这个 Z’分布比较好比较均匀的分布映射回流形,这样不管做分类,还是做采样点的控制,都应该是比较容易的。丘成桐教授等做了一些分析工作,用最佳质量映射,能把我刚才说的立方体又较好地重新映射回去。
如果不做最佳质量映射,直接应用解码器,会有问题。在编码域上进行均匀的采样(通常有规律的、比如均匀是我们最能掌握的,非均匀的东西我们很难控制得好),那么我把它重叠在编码域的图上,对这些采样出来的点,如果直接用生成器(也是解码器)重构,恢复出来这些点,放到原来的图上,可以看到头部非常稀疏,这个稀疏可以理解成在编码以后的隐空间用这些均匀采样点来解码,很难解出在头部也能均匀恢复的效果,这也是模式坍塌的一种。

如果加上这个最佳质量传输映射,在这个 Z’隐空间做均匀采样,再恢复。就是刚才说的把最佳质量映射和生成器在一块,恢复出来的效果就是比较均匀的。可以看到这个质量是会更好,所以这个最佳质量映射,能在均匀分布的隐空间上使得控制变得非常容易。
丘成桐教授等发现解码器和编码器在数学上有闭式公式可以关联起来,简单说只要有其中一个就可以推导出另外一个,这个在数学上是保证了的。有了这个结论,用到深度学习,就是只要训练好其中一个,就通过几何计算的方法来恢复出另外一个,不需要训练另外一个,免除了数据的担忧。但实际上高维空间中去推导最佳质量映射,是比较困难的,基本上在有限的计算资源下不太容易做到的。所以并没有完全颠覆我们对深度神经网络的认识。
这里有一个问题,这个最佳质量映射也可以通过深度神经网络的方式来学习。第二个自然产生的问题,我们是不是要学两次?我们能不能一次把这个复合映射学会?显然这是很有实际意义的问题:有两个模型把它合成一个模型。
再换一个视角来看模式坍塌,这个视角可能更好理解一点。举例子来说,三维空间中有一个二维曲面,每一个点上有一个切面,对较为规范的流形来说这个切面应该是一个二维的平面,当这个二维的平面退化成一条线甚至是零维的一个点,这时候模式坍塌一定发生。因为退化成一条线的时候,在其法向量方向上,另外一个坐标轴再怎么变都不影响结果,这是模式坍塌。退化成零维的时候更是如此了。
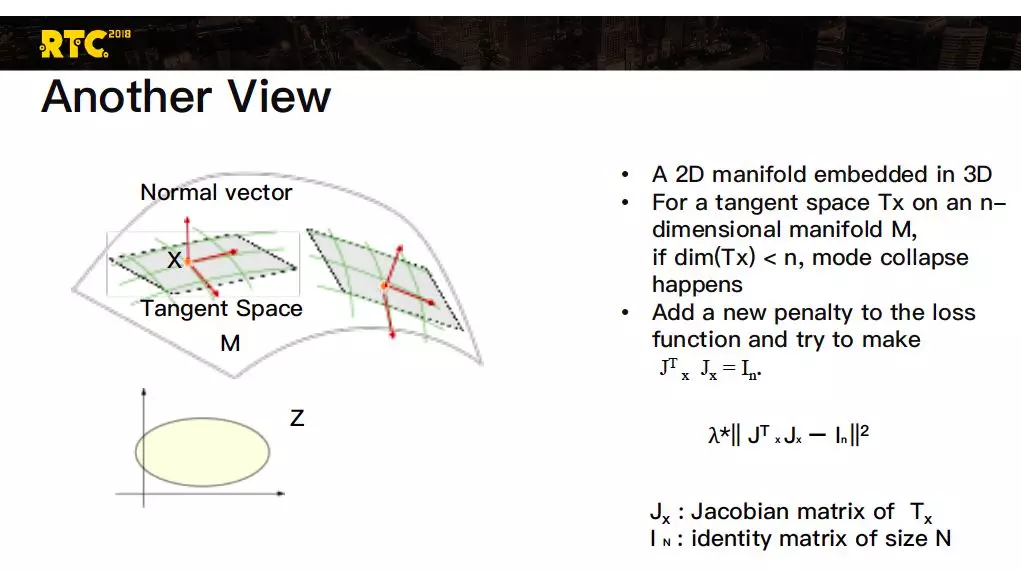
我们可以在损失函数中加上另外一项惩罚项,这个惩罚项表示跟一个恒等矩阵的差,这一项加到损失函数里。它试图使得切空间是满秩的,不会退化到一维或者零维,这样也能有效的减低模式坍塌的出现,这是从另外一个视角看这个问题。
下一个问题,如果给了一个基于矫正分段线性激活函数(ReLU)的卷积神经网络的学习能力究竟能有多强?换句话说给定一个任务,我们能设计多小的一个神经网络来完成任务?我们希望还是能限定它的复杂性,而不是完全开放式的摸索。这样的话多少能给我们探索在移动设备上的深度学习算法,提供一些指导原则。
刚才我提到了编码器和解码器都是分段线性函数,解码器把立方体分的更小,立方体越多越能把缝隙填满,这个逼近的质量决定了编码器和解码器最终的效果。这个很容易理解,一条曲线如果用一段线逼近它和用四条线逼近它,四段肯定逼近的更好,甚至用更多线段来无穷逼近,这个当然对原来的曲线是有一定限定的,比如是凸曲面等等。
这个矫正的复杂度,一个分段映射的复杂性是表征逼近能力的一个度量。它定义成,在 N 维的时空间上,最大的连通子集数,在每一个连通子集上编码器都是线性的,说穿了是分段线性。这是表征了这个解码器的能力。一个 K+2 层的深度卷积神经网络,由它所能表征的最复杂的分段线性映射来表征。
每一组不同的参数就定义了一组分段线性函数,当然参数不同的时候,它的能力不同。那么就有这么一个结论,深度神经网络的复杂性是有上界的,这是一个很好的结论。如果我们知道我们要学习的任务,它的复杂性是高于这个上限的时候,我们这个深度神经网络就设计得太小,肯定学不好。学不好有很多表现,比如泛化能力会比较差。不管你训练多少样本,你可能学到的分布跟实际数据的分布都是不一致的,都是有偏差的。我们可以想像在实际应用中,肯定有些数据的实际效果不是那么好。
同时,它也有一个下界,下界的理解比较简单,某个权重,使得网络复杂度最小的权重。
这样深度卷积神经网络的表征能力有上界也有下界,基本回答我刚才说的那个问题。我有几点体会。一个是因为要求拓扑空间上来做同胚映射,这个限制其实是较强的制约,其实只能学比较简单的几个拓扑结构,不能学太复杂的东西,或者只能学一个局部,一个局部学的很好,全局学起来有困难。最佳质量映射,能够有帮助,但在高维空间中计算出这个最佳质量映射,也算是一
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BA%94%E7%94%A8%E4%BA%8E%E5%AE%9E%E6%97%B6%E8%A7%86%E9%A2%91%E9%80%9A%E4%BF%A1%E7%9A%84%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E7%AE%97%E6%B3%95%E7%A0%94%E7%A9%B6/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


