年阿里沉淀出怎样的搜索引擎
简介: 阿里妹导读:搜索引擎是阿里的10年+沉淀,具有很高的技术/业务/商业价值。1688很多场景都借助了搜索中台的能力,基于此,以1688主搜为例介绍搜索全链路知识点,希望对你有所借鉴,有所启发。
一、整体架构
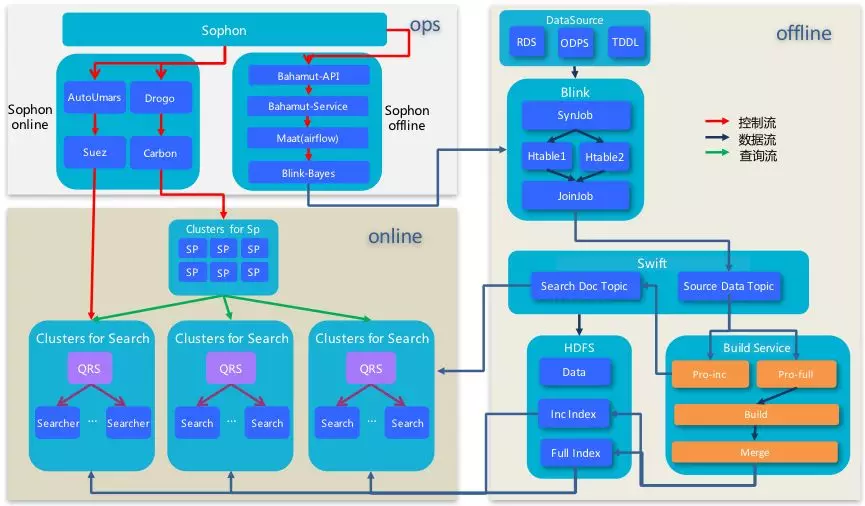
搜索引擎分为数据源聚合(俗称dump)、全量/增量/实时索引构建及在线服务等部分,以Tisplus为入口经由Bahamut(Maat进行工作流调度)->Blink->Hdfs/Swift->BuildService->Ha3->SP->SW等阶段对客户提供高可用/高性能的搜索服务。其中数据源聚合在tisplus平台和Blink平台完成,Build service和Ha3在suez平台完成,SP和SW通过drogo进行部署。具体架构图如下:
二、Tisplus
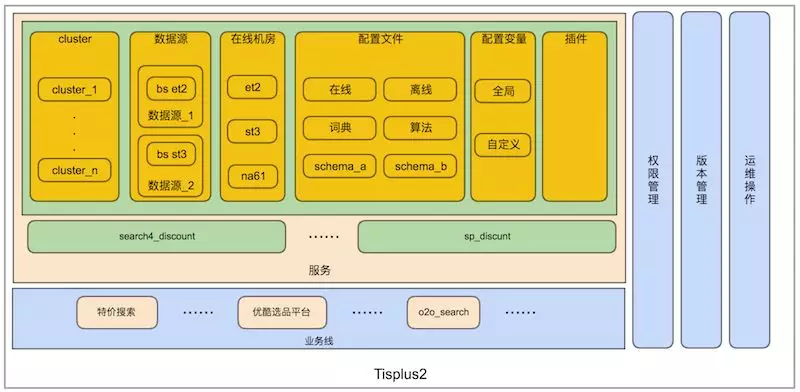
1688目前有spu、cspu,company,buyoffer和feed等引擎及offer离线在tisplus运维,该平台主要ha3和sp的搭建和维护,大体架构如下:
在日常维护中偶尔会遇到数据源产出失败的问题,主要是由于数据源表权限过期及zk抖动等原因。性能方面,在集团内搜索中台团队的引入Blink Batch模型后,dump执行时间被缩短,具体指标如下(以buyoffer引擎为例):

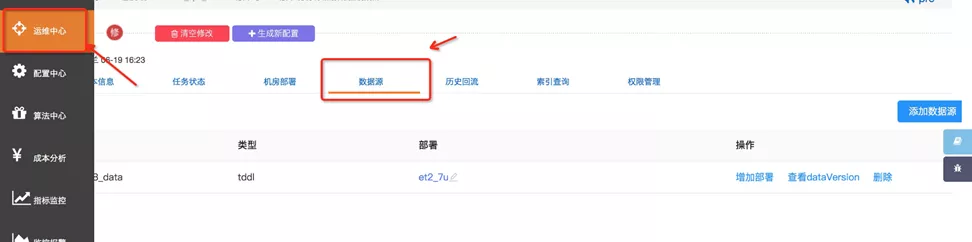
在tisplus平台,离线dump的入口如下:
DAG数据源图示例:
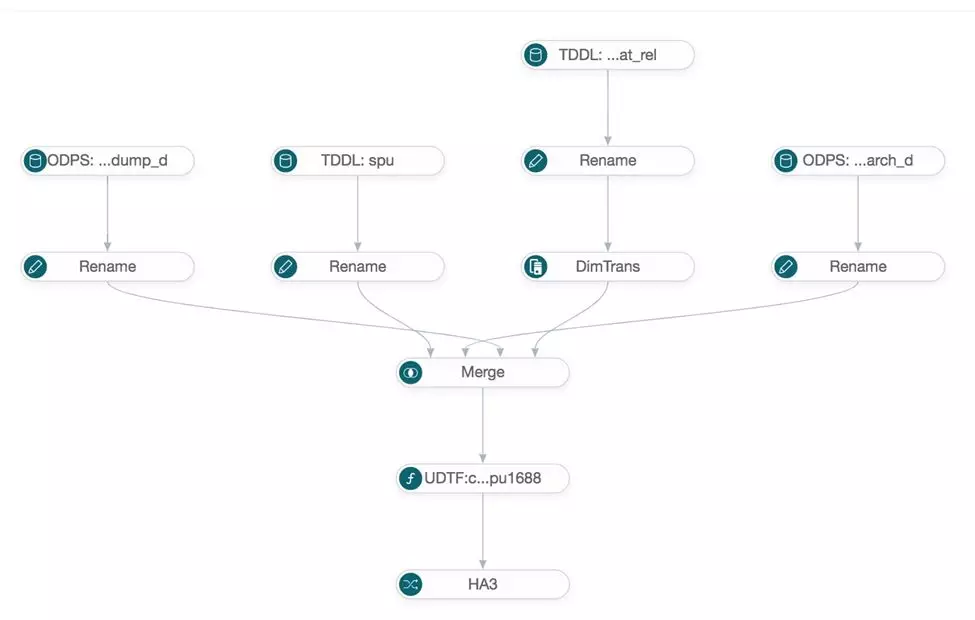
下面主要说下离线dump数据源处理流程,包括Bahamut、Maat和数据输出。
2.1 Bahamut——数据源图处理
Bahamut是离线数据源处理的组件平台,将web端拼接的数据图通过jobManager翻译成可执行的sql语句。目前Bahamut包含的组件有四类,分别是:
-
数据输入:datasource(支持tddl和odps)
-
KV输入:HbaseKV(Hbase数据表)
-
数据处理:Rename(数据字段重命名),DimTrans(使用1对多的数据聚合),Functions(简单字段处理),Selector(字段选择),UDTF(数据逻辑处理),Merge(数据源聚合),Join(left join)
-
数据输出:Ha3(Hdfs/swift)
对数据源的处理过程,描述如下:
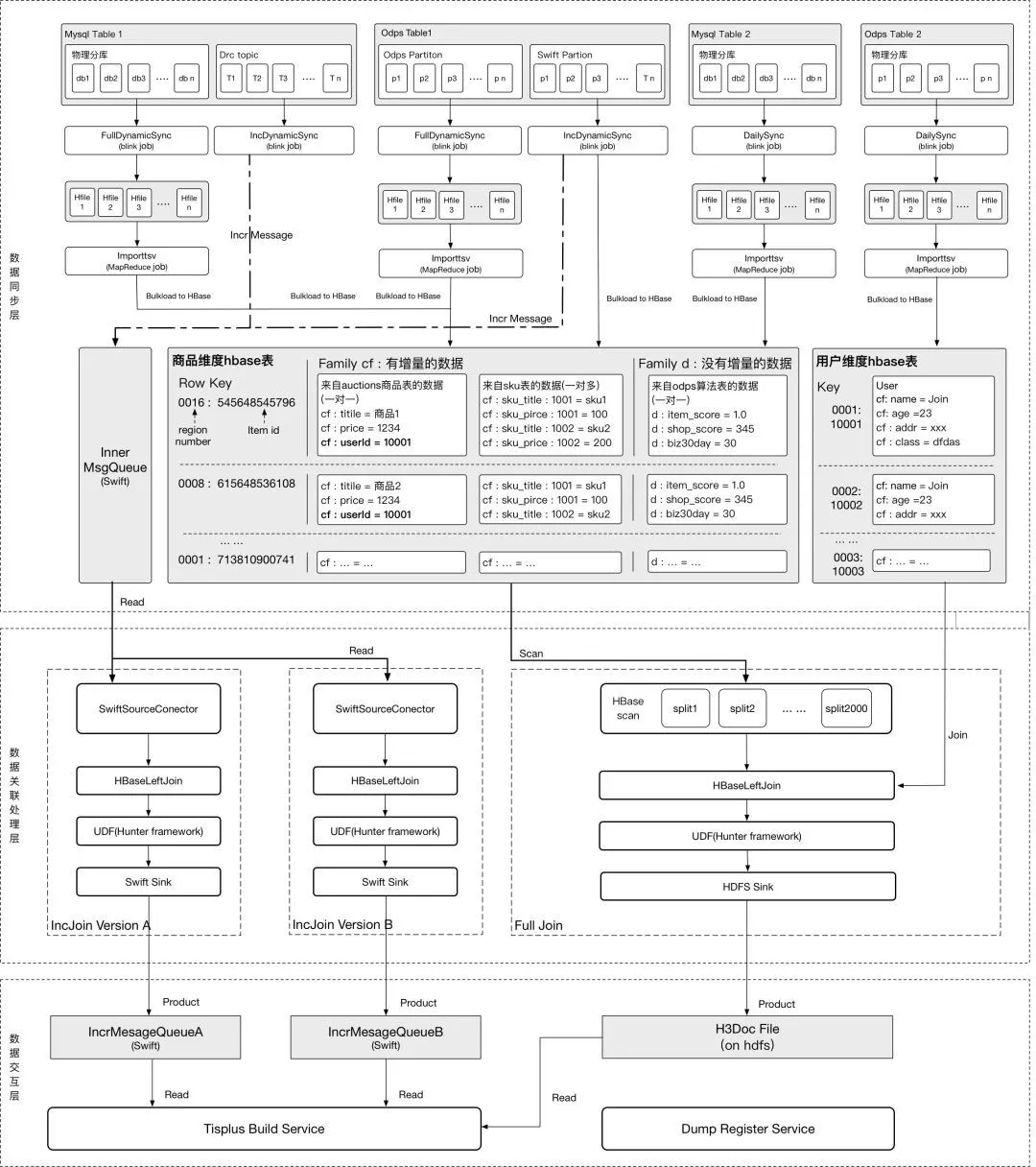
by 敬明
而对于Bahamut->blink过程可以陈述如下:
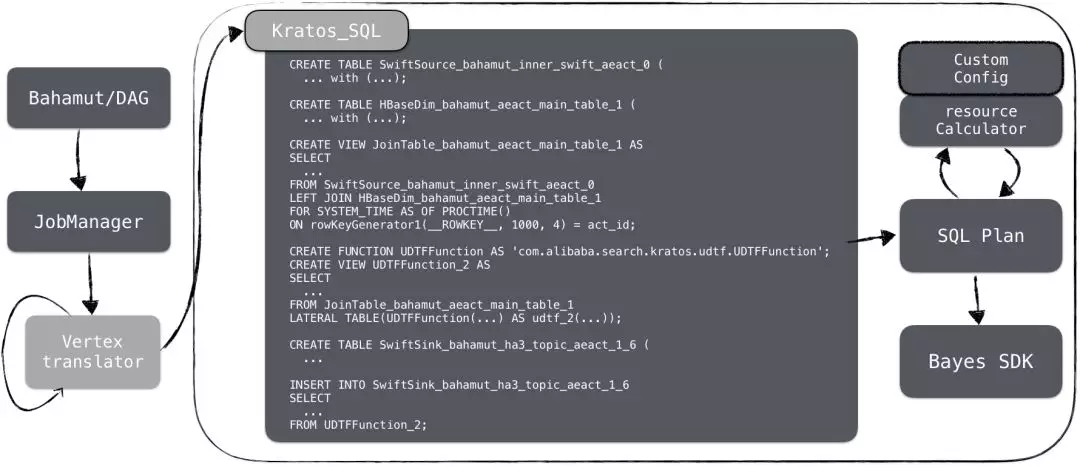
其中,Bahamut将任务拆解后扔给JobManager进行逻辑节点到物理节点的转换,形成若干节点后再归并组合成一个完整的SQL语句,例如上图Kratos_SQL就是一个增量Join的完整SQL,配合资源文件一起通过BayesSDK提交任务。此外,平台增加了一个弱个性化配置的功能,可以通过个性化配置来实现控制某个具体任务的并发度、节点内存、cpu等等参数。
2.2 Maat——分布式流程调度系统
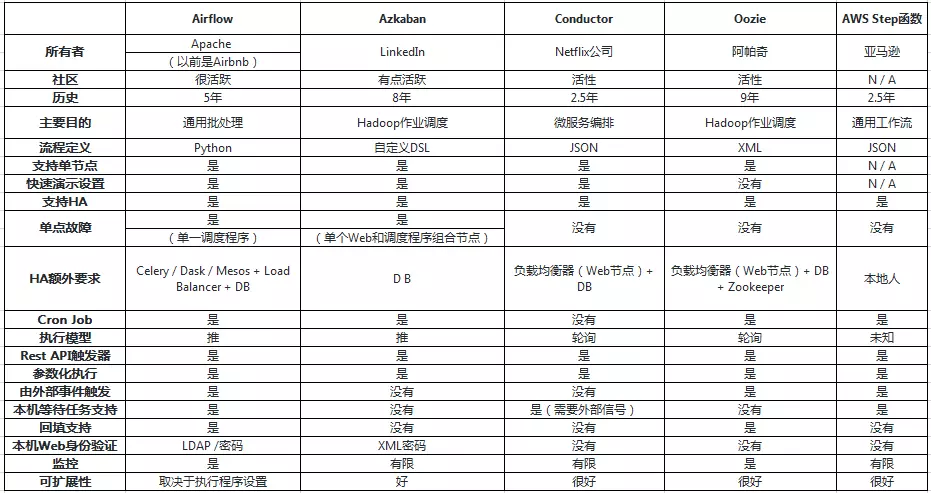
Maat是基于开源项目Airflow再次开发的分布式流程调度系统,具有可视化编辑及通用的节点类型,Drogo化部署,分集群管理及完善的监控&报警机制等优点。
关于Airflow及其他工作流系统,对比陈列如下:
eed引擎为例,maat调度页面如下:
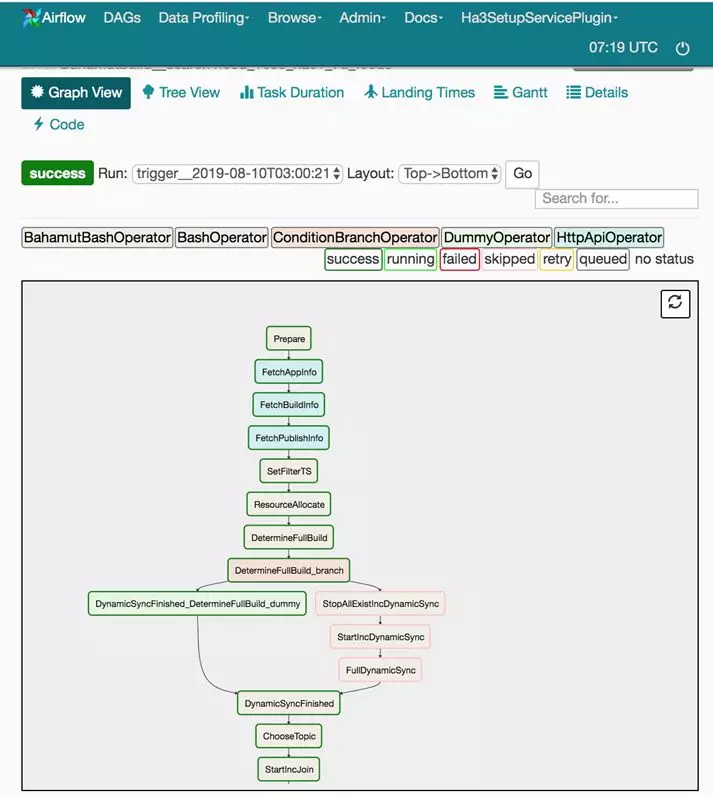
当任务错误时,可以通过该页面进行“将指定步骤置fail”然后重跑全量任务,也可以通过查看某个步骤的log获悉任务失败原因。
2.3 Ha3 doc——数据输出
经过上述步骤后,最后将数据以xml的形式(isearch format)输出到HDFS/Pangu路径(全量)和Swift Topic(增量),引擎全量时通过HDFS路径获取全量doc文件进行build,增量时直接从swift topic中获取增量更新消息更新到引擎中。离线平台通过一个服务为Tisplus引擎模块提供表信息的查询等功能,以下是一个HA3表包含的信息:
{
"1649992010": [
{
"data": "hdfs://xxx/search4test_st3_7u/full", // hdfs路径
"swift_start_timestamp": "1531271322", //描述了今天增量的时间起点
"swift_topic": "bahamut_ha3_topic_search4test_st3_7u_1",
"swift_zk": "zfs://xxx/swift/swift_hippo_et2",
"table_name": "search4test_st3_7u", // HA3 table name,目前与应用名称一样
"version": "20190920090800” // 数据产出的时间
}
]
}
三、Suez
经过上述步骤后,数据以xml(isearchformat)的格式产出到Hdfs和swift,然后通过在suez_ops平台的离线表中选择数据类型为zk并配置相应的zk_server和zk_path即可。
然后由Build service完成全量/增量/实时索引的构建,然后分发到Ha3在线集群提供服务。
suez的离线表构建逻辑如下:
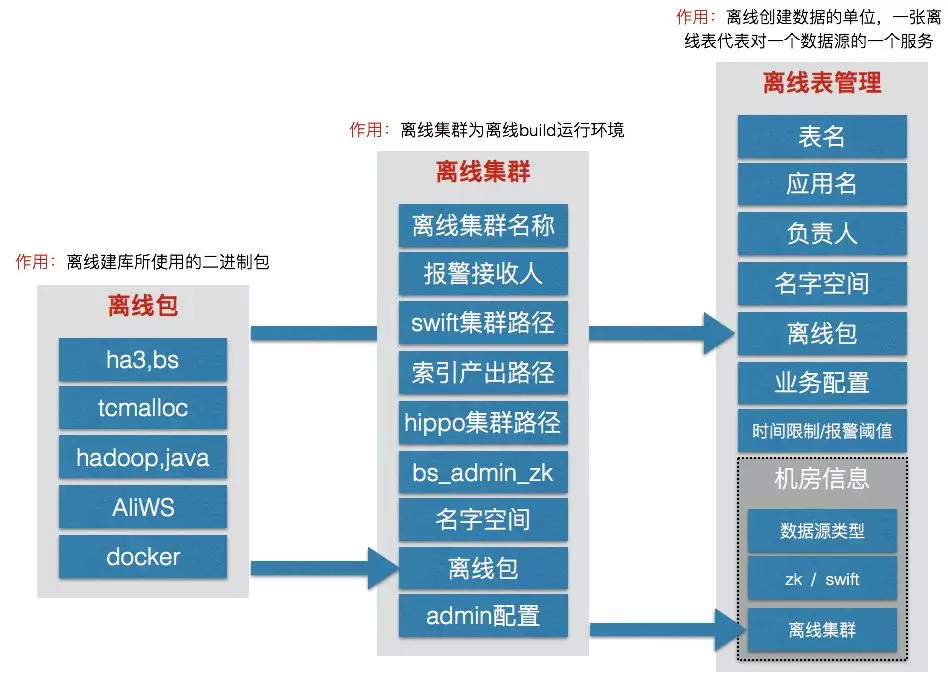
suez在线服务逻辑如下:
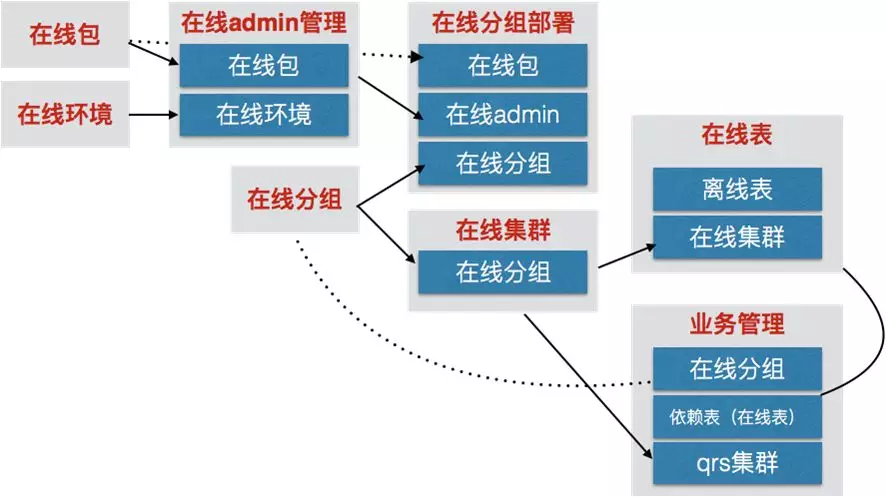
下面针对离线(buildservice)和在线(ha3)进行简述:
3.1 Build Service——索引构建
**
**
Build Service(简称BS)是一套提供全量、增量、实时索引的构建系统
build_service总共有五类角色:
-
admin :负责控制整体build流程,切换全量增量状态,发起定期任务,相应用户的控制请求;
-
processor :负责数据处理,将用户的原始文档转化为轻量级可build的文档形态;
-
builder :负责构建索引;
-
merger :负责索引整理;
-
rtBuilder :负责在线索引的实时构建。
其中admin、processor、builder、merger是以二进制程序的方式运行在hippo上,rtBuilder是以lib的形式提供给在线部分使用。
一个完整的全量+增量过程会产生一个generationid,该generation会经历 process full-> builder full -> merger full ->process inc -> builder inc ->merger inc的过程,其中处于inc过程后,builder inc和merger inc会交替出现。1688在ha3升级之前经常会出现 build tooslow问题就是因为分配到了坏节点或builderinc/merger inc阶段卡住。
3.2 Ha3——在线搜索服务
**
**
Ha3是一套基于suez框架的全文检索引擎,提供丰富的在线查询子句,过滤子句,排序子句,聚合子句且支持用户自定义开发排序插件。服务架构如下:
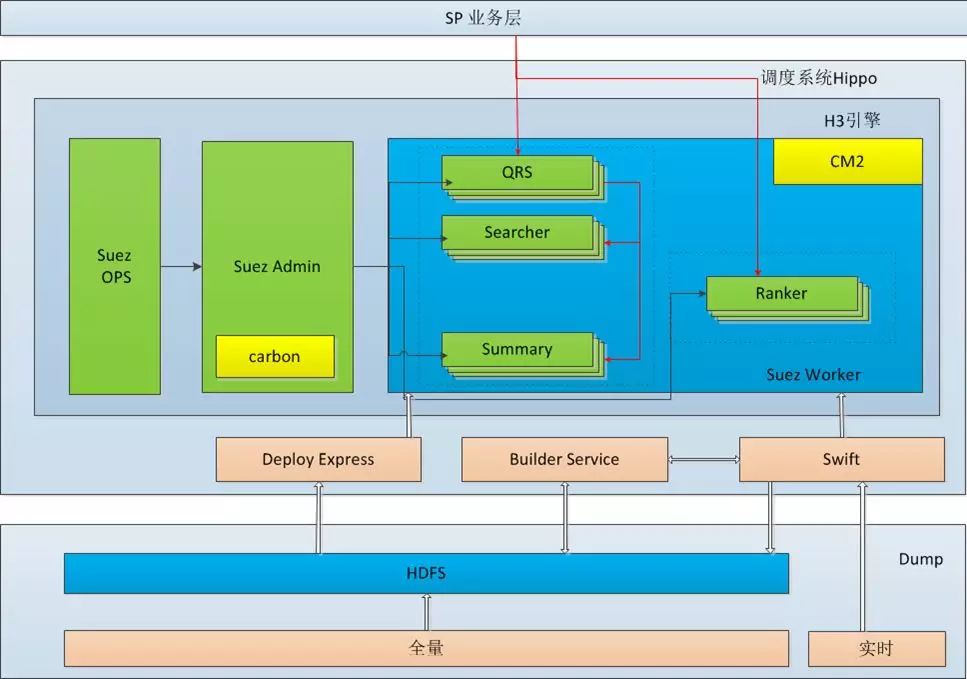
1688主搜引擎由一组Qrs、searcher和summary组成:
-
Qrs的作用是:对输入的查询作解析与校验,通过后把查询转发给相应的;searcher,收集合并searcher返回的结果,最后对结果做一些加工并返回给用户。其中也可以通过写meger插件干预合并规则;
-
searcher:可以是文档的召回服务(searcher),也可以是文档的打分与排序服务(ranker)或者是文档的摘要服务(summary);
-
summary:1688主搜将searcher和summary分离,summary集群只提供取商品详情的服务。
qrs/searcher/summary等机器通过挂载到cm2提供服务,比如qrs有对外cm2,可以对SP等调用方提供服务,searcher和summary有对内cm2,可以接收从qrs来的请求并完成召回排序取详情等服务。
一次调用方的query服务,要经由qrs->query解析->seek->filter->rank(粗排)->agg(聚合)->rerank(精排)->extraRank(最终排)->merger->summary(取详情)的过程,具体描述如下:
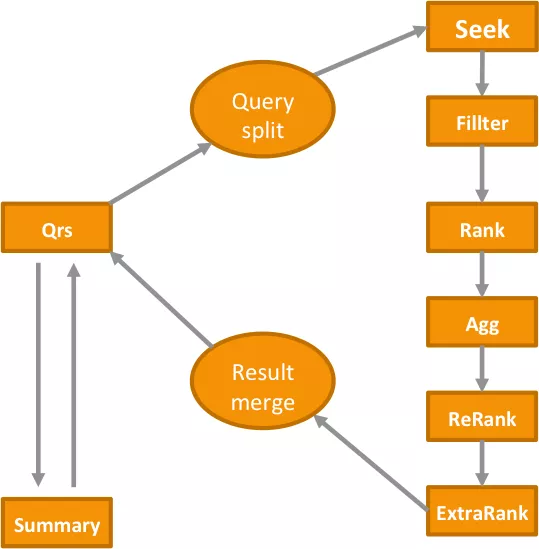
其中,ReRank和ExtraRank由Hobbit插件及基于Hobbit的战马插件完成,业务方可以根据自身需求开发战马特征并指定各特征权重得到商品的最终分。
四、Drogo
**
**
drogo是基于二层调度服务Carbon的无数据服务的管控平台,1688的SP服务及QP代理服务均部署在该平台。
1688搜索链路主要服务平台部署情况简述
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B4%E9%98%BF%E9%87%8C%E6%B2%89%E6%B7%80%E5%87%BA%E6%80%8E%E6%A0%B7%E7%9A%84%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


