年月底明略科技算法岗道面试题分享
文末彩蛋:七月在线干货组最新升级的《2021大厂最新AI面试题 [含答案和解析, 更新到前121题]》免费送!
问题1:熵,交叉熵的概念
判断一个数是否是7的倍数可以直接用取余的方法,判断一个数中是否含有数字7,这里提供两种方法:一种是将数字转换成字符串,用 in 进行判断;另一种是将数字转换成字符串,用 find 方法,如果不包含会返回 -1。
在信息论和概率统计中,嫡是表示随机变量不确定的度量,随机边量×的嫡定义如下:
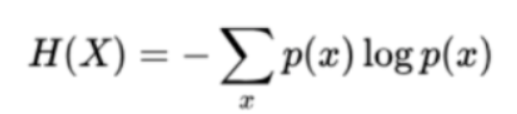
嫡只依赖于X的分布,与X的取值无关。
条件嫡H(YIX)表示在已知随机变量×的条件下随机变量Y的不确定性,H(Y|IX)定义为在给定条件X下,Y的条件概率分布的嫡对X的数学期望:
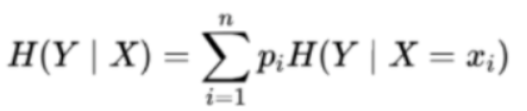
问题2:逻辑回归损失函数,并推导梯度下降公式
逻辑回归损失函数及梯度推导公式如下:
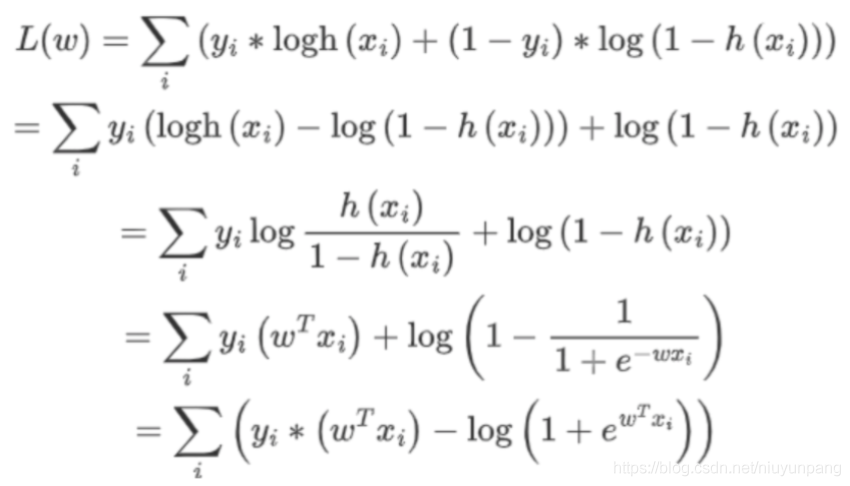
求导:
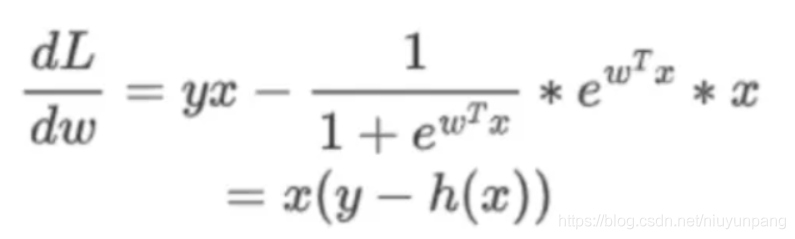
问题3:归一化和标准化区别
归一化公式:
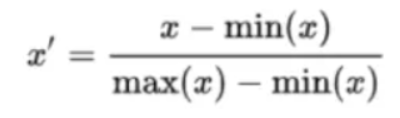
标准化公式:
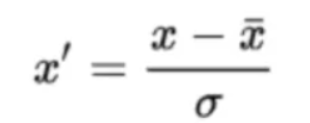
归一化和标准化的区别:归一化是将样本的特征值转换到同一量纲下把数据映射到[0,1]或者[-1,1]区间内,仅由变量的极值决定,因区间放缩法是归一化的一种。标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,转换为标准正态分布,和整体样本分布相关,每个样本点都能对标准化产生影响。它们的相同点在于都能取消由于量纲不同引起的误差﹔都是一种线性变换,都是对向量X按照比例压缩再进行平移。
问题4:knn算法的思想
在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类, 其算法的描述为:
- 计算测试数据与各个训练数据之间的距离;
- 按照距离的递增关系进行排序;
- 选取距离最小的K个点;
- 确定前K个点所在类别的出现频率;
- 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
问题5:knn的k设置的过大会有什么问题
KNN中的K值选取对K近邻算法的结果会产生重大影响。如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差(近似误差:可以理解为对现有训练集的训练误差)会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法来选择最优的K值。经验规则:k一般低于训练样本数的平方根。
问题6:gbdt和bagging的区别,样本权重为什么会改变?
gbdt是�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B4%E6%9C%88%E5%BA%95%E6%98%8E%E7%95%A5%E7%A7%91%E6%8A%80%E7%AE%97%E6%B3%95%E5%B2%97%E9%81%93%E9%9D%A2%E8%AF%95%E9%A2%98%E5%88%86%E4%BA%AB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


