年月中旬腾讯算法面试题道
文末免费送电子书:七月在线干货组最新 升级的《名企AI面试100题》免费送!
问题1:SVM 的 优化函数公式怎么写,代价函数是什么?
线性可分支持向量机的最优化问题函数公式:
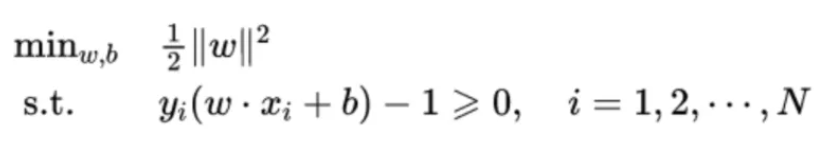
引入拉格朗日乘子,由拉格朗日对偶性可得代价函数如下:
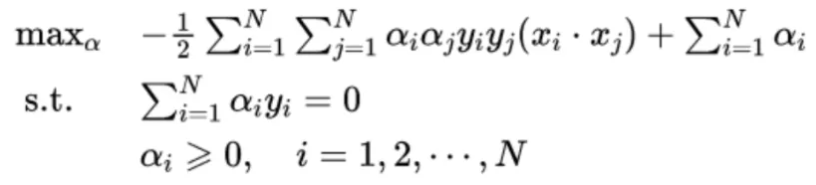
问题2:随机森林是怎么回事,为什么树模型好用,为什么要发明随机森林?
随机森林是一种重要的基于Bagging,进一步在决策树的训练过程中引入随机属性选择的集成学习方法,可以用来做分类、回归等问题。
随机森林的构建过程大致如下:
- 从原始训练集中使用Bootstraping方法随机有放回采样选出m个样本,共进行n_tree次采样,生成n_tree个训练集;
- 对于n_tree个训练集,我们分别训练n_tree个决策树模型;
- 对于单个决策树模型,假设训练样本特征的个数为n,那么每次分裂时根据信息增益/信息增益比/基尼指数选择最好的特征进行分裂;
- 每棵树都一直这样分裂下去,直到该节点的所有训练样例都属于同一类。在决策树的分裂过程中不需要剪枝;
- 将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果。
随机森林的优点:
- 具有极高的准确率;
- 随机性的引入,使得随机森林不容易过拟合;
- 随机性的引入,使得随机森林有很好的抗噪声能力;
- 能处理很高维度的数据,并且不用做特征选择;
- 既能处理离散型数据,也能处理连续型数据,数据集无需规范化;
- 训练速度快,可以得到变量重要性排序;
- 容易实现并行化。
随机森林的缺点:
- 当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大;
- 随机森林模型还有许多不好解释的地方,有点算个黑盒模型。
问题3:XGBOOST相对于GDBT最大的优势是什么,XGBOOST求二阶导数的好处都有什么?
优势:加入了正则化和二阶导数。
XGBOOST求二阶导数的好处:
- xgboost是在MSE基础上推导出来的,在MSE的情况下,xgboost的目标函数展开就是一阶项+二阶项的形式,而其他类似logloss这样的目标函数不能表示成这种形式。为了后续推导的统一,所以将目标函数进行二阶泰勒展开,就可以直接自定义损失函数了,只要损失函数是二阶可导的即可,增强了模型的扩展性。
- 二阶信息能够让梯度收敛的更快。一阶信息描述梯度变化方向,二阶信息可以描述梯度变化方向是如何变化的。
问题4:BERT是怎么分词的?
BERT主要是基于 Wordpiece 进行分词的,其思想是选择能够提升语言模型概率最大的相邻子词加入词表。
BERT 源码中 tokenization.py 就是预处理进行分词的程序,主要有两个分词器: BasicTokenizer 和 WordpieceTokenizer,另外一个 FullTokenizer 是这两个的结合:先进行 BasicTokenizer 得到一个分得比较粗的 token 列表,然后再对每个 token 进行一次 WordpieceTokenizer,得到最终的分词结果。
其中BasicTokenizer完成: 转unicode )-> 去除空字符、替换字符、控制字符和空白字符等奇怪字符 -> 中文分词 -> 空格分词 -> 小写、去掉变音符号、标点分词;
WordpieceTokenizer 大致分词思路是按照从左到右的顺序,将一个词拆分成多个子词,每个子词尽可能长。按照源码中的说法,该方法称
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B4%E6%9C%88%E4%B8%AD%E6%97%AC%E8%85%BE%E8%AE%AF%E7%AE%97%E6%B3%95%E9%9D%A2%E8%AF%95%E9%A2%98%E9%81%93/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


