年七月中旬虾皮北京提前批算法工程师道面试题
福利 | 文末免费送电子书:七月在线干货组最新 升级的《2021最新大厂AI面试题》免费送!
问题1:删除链表倒数第K个节点
该题为leetcode第19题。
在对链表进行操作时,一个常用的技巧就是添加一个哑结点(dummy node),它的next忠贞纸箱链表的头结点,这样就不需要对头结点进行特殊判断了。
- 思路一:计算链表长度
先对链表进行一次遍历,得到链表的长度L,随后再从头节点开始对链表进行一次遍历,当遍历到第L-n+1个节点时,就是需要删除的节点。当我们在头结点前面加上dummy节点后,删除的节点就变为了L-n+1的下一个节点,通过修改指针来完成删除操作。
代码如下:

时间复杂度:O(L),其中 L 是链表的长度。
空间复杂度:O(1)。
- 方法二:栈
在对链表进行遍历时将所有的节点依次放入栈,根据栈先进后出的原则,我们弹出的第n个节点就是需要删除的节点,且此时栈顶的节点就是待删除节点的前驱节点。
代码如下:

时间复杂度:O(L),其中 L 是链表的长度。
空间复杂度:O(L),其中 L 是链表的长度。主要为栈的开销。
- 方法三:双指针
该方法的优点在于不需要预处理链表的长度
使用两个指针 first 和 second 同时对链表进行遍历,并且 first 比 second 超前 n 个节点。当 first 遍历到链表的末尾时second 就恰好处于倒数第 n 个节点。
代码如下:

时间复杂度:O(L),其中 LL 是链表的长度。
空间复杂度:O(1)。
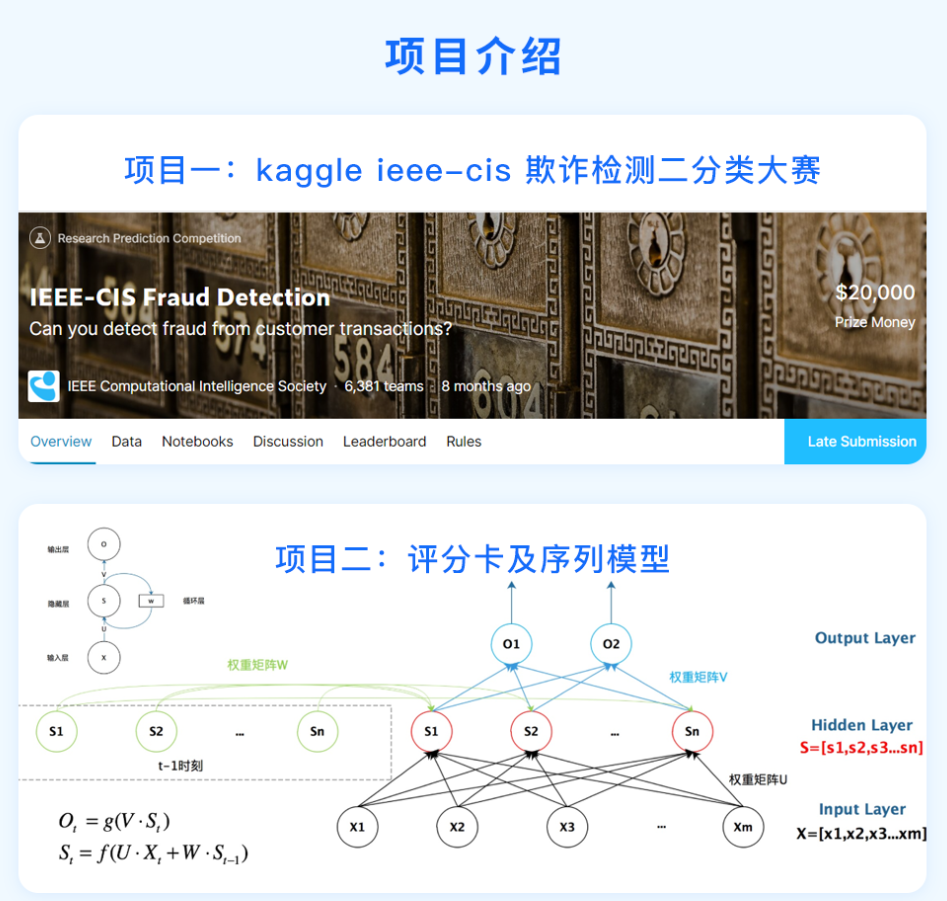
今天给大家一个超棒的课程福利——【 金融欺诈比赛与序列模型】特训课程!限时1分秒杀!

本课从kaggle欺诈比赛和序列模型两个角度带你深入了解金融风控领域知识!
kaggle欺诈比赛中:会从比赛背景知识介绍、效率优化,到数据分析、特征工程,再到模型分析、超参数调优,给你一个参赛必备整体思路;
序列模型中:会从RNN、LSTM、GRU,到Seq2seq、Attention,再到Transformer及案例,带你充分了解金融风控领域中需要掌握的序列模型。
课程配备优秀讲师和助教团队跟踪辅导、答疑,班主任督促学习,群内学员一起学习,对抗惰性。同时课程还配备专业职业规划老师,为你的求职规划,涨薪跳槽保驾护航。
课程链接: https://www.julyedu.com/course/getDetail/303
问题2:将数组划分为给定和为k的2部分。
该题为leetcode416题,结题思路如下:
背包问题——能不能装满容量为target的背包
本题要求把数组分成两个等和的子集,相当于找到一个子集,其和为sum/2,这个sum/2就是target
具体步骤如下:
- 特例:如果sum为奇数,那一定找不到符合要求的子集,返回False。
- dp[j]含义:有没有和为j的子集,有为True,没有为False。
- 初始化dp数组:长度为target + 1,用于存储子集的和从0到target是否可能取到的情况。
比如和为0一定可以取到(也就是子集为空),那么dp[0] = True。
- 接下来开始遍历nums数组,对遍历到的数nums[i]有两种操作,一个是选择这个数,一个是不选择这个数。
-不选择这个数:dp不变
-选择这个数:dp中已为True的情况再加上nums[i]也为True。比如dp[0]已经为True,那么dp[0 + nums[i]]也是True
- 在做出选择之前,我们先逆序遍历子集的和从nums[i]到target的所有情况,判断当前数加入后,dp数组中哪些和的情况可以从False变成True。
(为什么要逆序,是因为dp后面的和的情况是从前面的情况转移过来的,如果前面的情况因为当前nums[i]的加入变为了True,比如dp[0 + nums[i]]变成了True,那么因为一个数只能用一次,dp[0 + nums[i] + nums[i]]不可以从dp[0 + nums[i]]转移过来。如果非要正序遍历,必须要多一个数组用于存储之前的情况。而逆序遍历可以省掉这个数组)
dp[j] = dp[j] or dp[j - nums[i]]
这行代码的意思是说,如果不选择当前数,那么和为j的情况保持不变,dp[j]仍然是dp[j],原来是True就还是True,原来是False也还是False;
如果选择当前数,那么如果j - nums[i]这种情况是True的话和为j的情况也会是True。比如和为0一定为True,只要 j - nums[i] == 0,那么dp[j]就变成了True。
dp[j]和dp[j-nums[i]]只要有一个为True,dp[j]就变成True,因此用or连接两者。
最后就看dp[-1]是不是True,也就是dp[target]是不是True
代码如下:

时间复杂度:O(n * target)
空间复杂度:O(target)
参考:
问题三:二叉树的后序遍历(非递归)
- 方法一:递归
树本身就有递归的特性,因此递归方法最简单。
代码如下:

时间复杂度:O(n),n 为树的节点个数
空间复杂度:O(h),h 为树的高度
- 方法二:迭代
注意:该代码是基于前序遍历改来的,由于前序遍历是中左右,后序遍历是左右中,所以只需要写出中右左,再进行反转即可得到左右中。
代码如下:

时间复杂度:O(n),n 为树的节点个数
空间复杂度:O(h),h 为树的高度
问题4:怎么求特征重要性(GBDT RF等)
RF有两种方法:
- 通过计算Gini系数的减少量 VIm=GI−(GIL+GIR) 判断特征重要性,越大越重要。
- 对于一颗树,先使用OOB样本计算测试误差a,再随机打乱OOB样本中第i个特征(上下打乱特征矩阵第i列的顺序)后计算测试误差b,a与b差距越大特征i越重要。
GBDT计算方法:所有回归树中通过特征i分裂后平方损失的减少值的和/回归树数量 得到特征重要性。
在sklearn中,GBDT和RF的特征重要性计算方法是相同的,都是基于单棵树计算每个特征的重要性,探究每个特征在每棵树上做了多少的贡献,再取个平均值。
Xgb主要有三种计算方法:
- importance_type=weight(默认值),特征重要性使用特征在所有树中作为划分属性的次数。
- importance_type=gain,特征重要性使用特征在作为划分属性时loss平均的降低量。
- importance_type=cover,特征重要性使用特征在作为划分属性时对样本的覆盖度。
评论区回复 “2021”,七月在线干货组最新升级的《2021大厂最新AI面试题 [含答案和解析, 更新到前121题]》,免费送!
持续无限期更新大厂最新面试题,AI干货资料,目前干货组汇总了今年3月-6月份,各大厂面试题。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B4%E4%B8%83%E6%9C%88%E4%B8%AD%E6%97%AC%E8%99%BE%E7%9A%AE%E5%8C%97%E4%BA%AC%E6%8F%90%E5%89%8D%E6%89%B9%E7%AE%97%E6%B3%95%E5%B7%A5%E7%A8%8B%E5%B8%88%E9%81%93%E9%9D%A2%E8%AF%95%E9%A2%98/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


