干货篇观远数据可解释机器学习原理及应用
分享嘉宾: 周远,观远数据联合创始人,首席科学家
整理出品: 张劲,AICUG人工智能社区
PPT下载: http://www.aicug.cn/#/docs
浏览器不支持该媒体的播放 :(
导读: 在商业领域的机器学习应用中,让业务方理解模型逻辑,提升对预测结果的信心,对于算法项目的推进与落地起着关键的推动K作用。因此模型与预测输出的可解释性也日渐成为一个重要议题。在本次分享中,我们将介绍可解释机器学习的技术原理,以及在模型开发,项目落地中的一些应用案例介绍。
为何需要可解释机器学习?
首先介绍下为什么需要可解释机器学习。平时在做机器学习的项目中,会碰到不同的场景,比如淘宝推荐系统,推荐了一些你可能感兴趣的商品,如果推荐的不准确,其实不会造成什么大的损失,或不好的影响。那这种场景下,只需要关注下模型的准确率,尽可能做的越高越好。
另外一种场景,像OCR光学字符识别,它是一个比较成熟的场景,基本上可以达到100%的准确率。而像其他一些需求预测产品,比如金融信用评级系统,医学诊断系统,它给出的是预测,比如需求预测接下来可能要买10箱可口可乐,假如预测多了,可能会造成货物囤积,直接造成经济损失。在这种情况下,我们对机器学习的输出是需要有要求的。还有信用评级,如果我申请了一个信用卡被拒绝了,我就会比较想知道为什么被拒绝,是不是对我的年龄或者性别有歧视等。还比如对Responsible AI这个话题,也会有涉及到这方面的需求,所以我们需要可解释机器学习,让模型输出预测的同时,也要输出预测变化的原因。
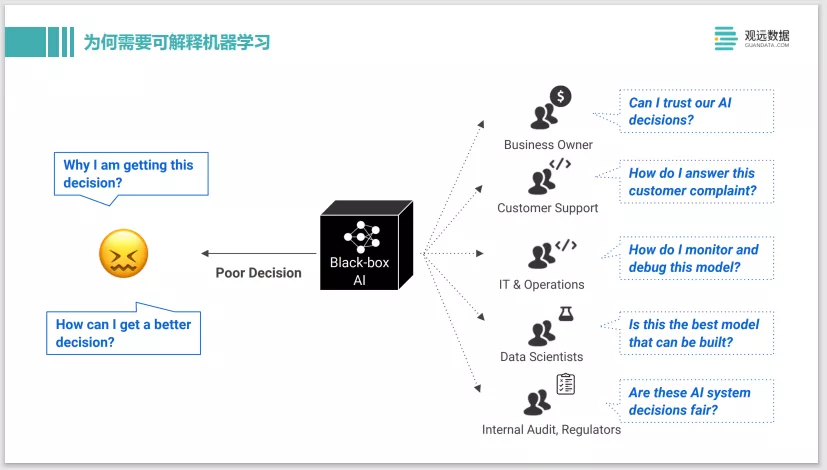
上图介绍了在面对一个黑盒的 AI模型时,其不同职能的人,比如企业管理者、客服、IT或是模型开发工程师,他们对于机器学习的输出是有不同诉求的。比如作为一个算法工程师,如果从黑盒的机器学习模型中得到的预测不好,和真实值偏差得非常远,那他可能会想为什么这个模型给了这样的预测,以及如何做能让模型更好。
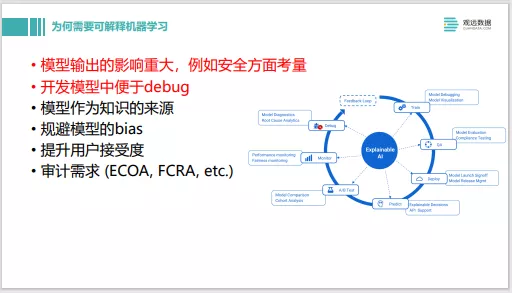
总结下,第一,模型输出的影响重大,如果给出一个错误预测,代价会比较大,就需要可解释机器学习。第二,特别是对算法工程师来说,在开发模型中便于Debug。当然也有一些其他的应用场景,比如规避模型的Bias。现在社区上也有很多这方面的讨论,如果模型是有一些性别歧视,或者种族歧视的话,这个模型是不能上线的。还有在模型交互时,如果碰到业务方的挑战,能给出一些解释,也能提升业务用户的接受度。还有各种各样的审计需求、法规需求,像信用评级系统,如果在线上部署系统,就必须要符合透明性,或者可解释性的需求。
可解释机器学习的各种方法
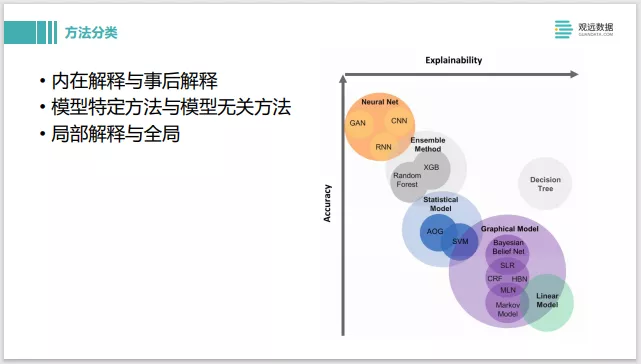
下面我们切入正题,可解释机器学习的各种各样的方法。右边这张图,分为两个维度,一个是模型预测的准确率,另一个是可解释性。
当用一些简单的模型,如右下角的线性模型,Decision Tree决策树,或者一些概率图模型,他们的准确率可能会差一些,因为模型本身结构比较简单,但它们的可解释性会非常好。左上角,像神经网络或者一些集成学习方法,模型复杂度会非常高,准确率也会相应提高,但它的解释性就会差一点。
方法分类上,线性模型这种属于内在可解释模型。神经网络这种属于事后解释的方法,去打开黑盒看一下它里面到底是怎样来做预测的。还有些是模型特定的方法,像神经网络可以通过后续模型的梯度来做些解释。还有一些是黑盒的模型解释方法,像SHAP这些技术,它对模型没有任何要求,都可以做一些解释。
局部解释和全局解释,全局解释类似于线性模型,它的权重就是这个模型全局上的表现是怎样来做决策的。局部性的解释,相当于对某一条单独的样本给出些特定的解释。
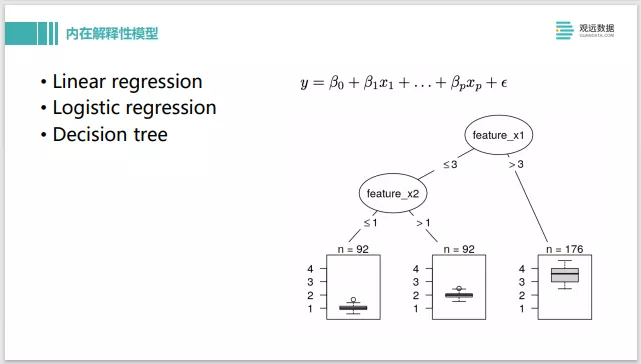
接下来介绍一些内在解释性的模型,像线性回归、线性逻辑回归、决策树等。训练完这些模型后,通过系数和模型的结构就能得到一个解释。系数比较大,说明这个特征对整个输出是有比较大的影响的。系数小,影响就较小。这是自带的一个解释性质。

还有一些类似思路,比如RuleFit或者 Skope-rules这些软件包,可以从数据中提取一些规则,自动构建如右图中显示的这种规则。在预测的同时它的可解释性是非常强的。像朴素贝叶斯,kNN,可以通过其他的样本来进行解释。

还有一些其他的内在解释模型,大体方法也都是在一些简单模型上附加一些方法。像EBM或者 GAMxNN,它们属于广义加性模型,相当于在线行模型的基础上,多构建几个线性模型,每一个线性模型描述系统的一部分,然后把它们加起来。像 Facebook的 Prophet也是一个典型的加性模型,它会分别给出seasonality或trend这方面的一些解释。最近谷歌开源的 TFT,是一个时间序列的模型,它对于 attention机制做了特殊的处理,可以训练完之后,同时让注意力机制也可以作为一个对模型解释的输出。

还有像神经网络,大多是在训练模型完成之后事后解释。我们利用神经网络,去计算它的梯度然后做一些反向传播,去做一些解释。上图是早年研究中我们怎么来理解 CNN模型它学到些什么,可以通过改变它的输入,去让它的每个CNN filter的 activation最大化。这样就可以看到,前面几层 CNN的层能学到边缘,中间的能学到一些形状,再高些能学到一些概念。这个其实就是利用了神经网络的求梯度,然后做反向传播的原理,来做一些解释。

这个例子也类似,是来自于 《Deep Learning with Python》那本书,里面介绍实现了 Grad-CAM的方法。像这个图片,为什么预测这个图片是大象呢?我们就去找大象 class的 activation,然后把它的梯度反向传回去,再看整个 CNN的 layer上面各个像素对它的激活度影响最大的那些像素点是什么,然后用heat-map的形式画出来。就可以看出是因为两个象的头部,这张图片被分类为大象是最有贡献度的,就形成了一个解释。

除了神经网络模型之外,还有一大部分像树模型、 Gradient Boosting这些,其实都可以用一些 Post-hoc模型无关的方法来做一些解释。大致流程是,当有了一个 Black Box Model之后,可以用一些解释的方法,去最终给用户输出一些说明。我们重点讲一下 PDP、LIME和Shapley。
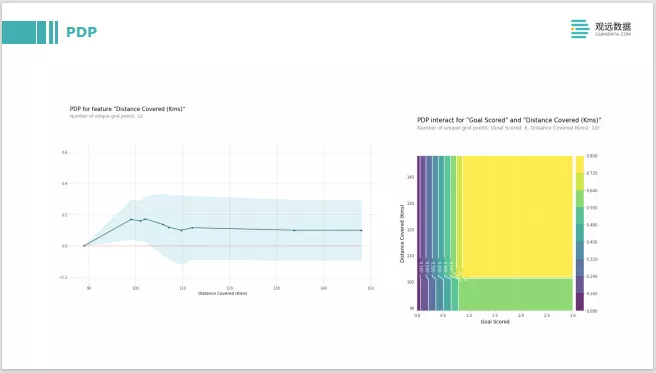
PDP的思想就是去修改特征值。把一个特征值在模型训练完后,有了黑色模型,再输入的时候,把它的特征值做一些修改,比如从0改到100,去看下模型的输出是什么样子。跟what-if的分析非常类似,去看它的输出跟随特征变化会有什么样的变化。右边这张图,是两个特征的交互,两个特征分别做修改,去看它整体对模型输出的影响。
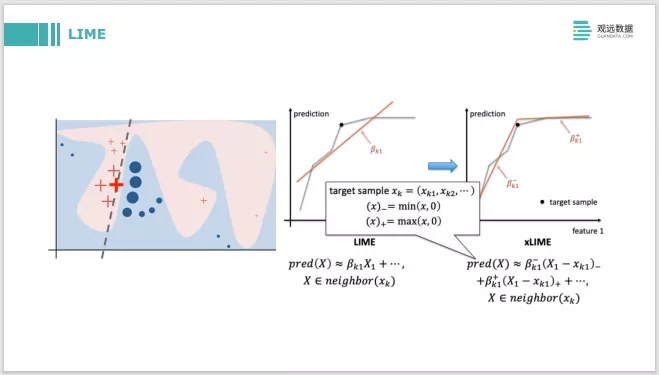
LIME是一个局部解释的方法。对每一个 instance都做出单独的解释,它的做法是在instance附近做些采样。左边这张图,是要解释红色加粗的加号,首先在它周围采了很多样本,在局部样本周围采样之后构建一个线性模型。线性模型对各个特征的系数本身就是可解释的。包括旁边在LIME基础上还有xLIME,它是对这个特征从小变到大,从当前这个点到更大的方向,构造两个线性模型来做解释。

LIME也可以应用于文本。文本图片的挑战是,如果是表格类数据它是比较好采样的。在采样点附近加一点或者减一点,就很容易采到一个新的样本,文本和图片就会稍微难一点。比如图片,它可能要用Super-pixel的方法去做一些像素块的一些采样。作者也在这篇文章里面提了他的一些具体做法效果还是不错的。
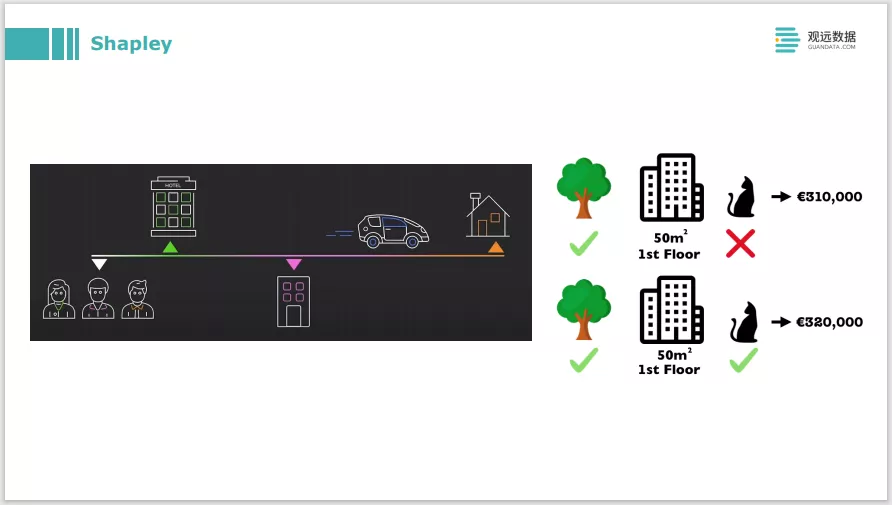
Shapley背后的原理是博弈论的一个理论。比如上面这张图,要解决的问题是,三个人去拼车,三个人在不同的地点下车,那么最后车费应该怎么均摊?迁移到机器学习解释的问题就是,最后总的车费是模型的预测输出,每个人要付多少车费就是三个特征的贡献度。这背后有一套很复杂的运作逻辑,去把各个特征的 attribution算出来,也就是一个 local的解释,对每一条预测样本都做出一些解释。
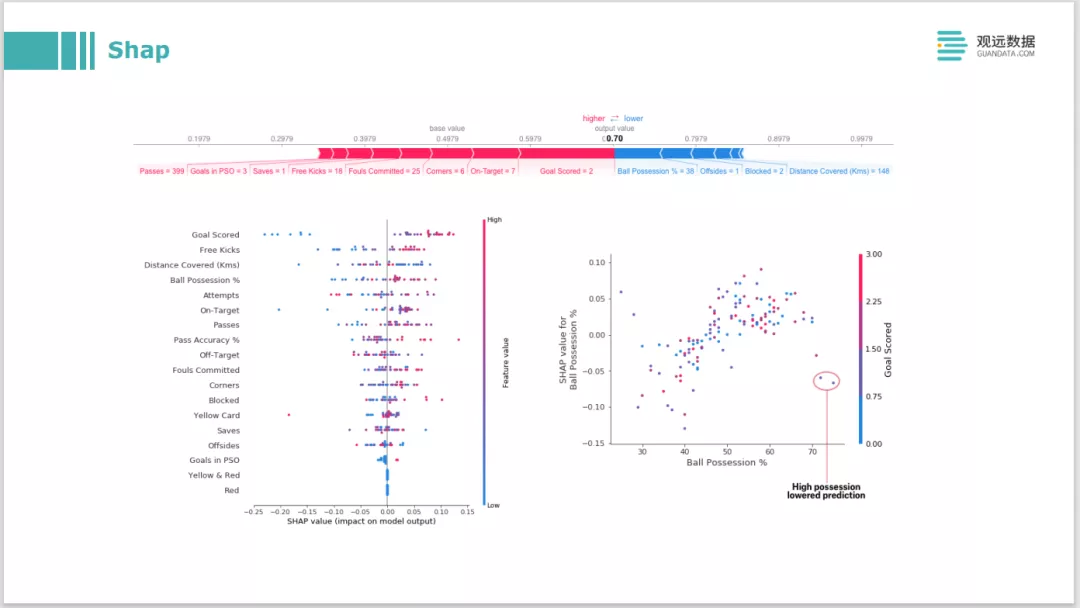
在Shapley理论的基础上开源出一个Shap库。也是目前模型解释领域应用最广泛的一个库。它有很多内置的可视化,在原版Shapley的运行基础上做了很多运算的优化。因为原版的计算开销非常大,Shap在树模型和深度学习模型中分别做了一些优化,可以让运行时间在一个可接受范围内。

接下来讲下基于样本的一些方法。基于这个样本得出的这个预测,那么怎么来解释它呢?就是去找一条跟它类似的样本,或是找一条具有代表性的样本,然后去解释这个模型的行为,或是解释训练数据它其实就是这么分布的。这个方法要有反事实的方法,或prototypes原型方法,还有像 adversarial对神经网络的攻击方法。
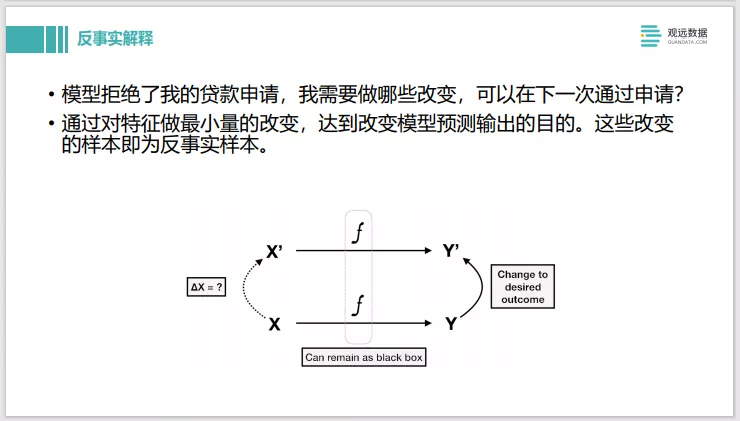
下面讲下反事实解释。比如模型对贷款申请的模型进行判断,输入数据后它拒绝了贷款申请。Shapley的反事实解释就是,需要在特征值上做哪些改变,可以在下一次就通过申请,预测的 label会从0变成1,这就是一个反事实解释。

接下来是原型样本解释。Prototype是数据中具有代表性的样本,反之,如果不太具有代表性,就称为Criticism,类似于outlier,这种方法它能够帮我们发现数据和模型的缺点。举个例子,我们训练的一个CNN模型做物体分类识别,prototype是一些正常的照片,Criticism里面发现了一些晚上光照不好拍的照片,如果这些照片分类为Criticism,就说明我们的数据集中可能对于夜间拍摄的照片的数量不够。这个模型在这部分的数据准确率比较差需要加以改进。
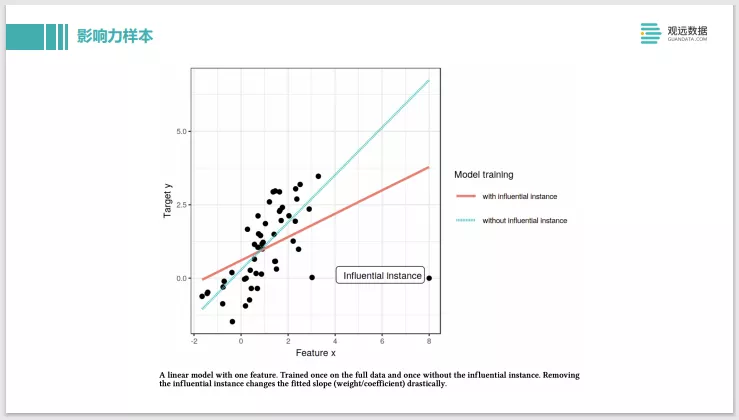
最后这个是影响力样本。相当于原先有全量数据去训练,它会拟合出这条红色线的信息模型。当把右下角这个离其他的点非常远的 influential instance去掉之后,它就拟合出来新的蓝色这条线了,可以看到斜率改变非常大,所以就可以叫右下角这个点是一个influential instance ,就是很有影响力的样本。但这个方法也有些效率上的问题,是和Shapley的原理差不多,要考虑每一个样本的影响力,要把每一个样本去掉,重新训练一个模型来看,开销很大。也有些其他方法,像在神经网络模型上,可以快速在一个构建好的模型上去寻找它影响力样本,还有像集成树模型也有方法是可以快速找到影响力样本。
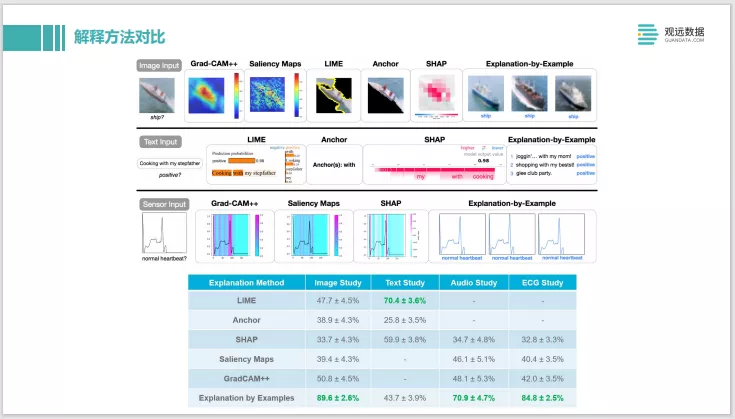
前面讲了很多解释方法,我们再来看一下解释方法的对比。最上面是图像类型的解释。比较了Grad-CAM等类似于显著图的方法,还有像LIME、SHAP,最右边这种通过 example数据的实例来进行解释,中间是text的一些任务,最下面是一个时间序列的input,它分别通过不同的方法来做解释。然后把这些解释的方法放到了亚马逊的 Mechanical Turk众包平台上去,让人工来评判到底哪种解释比较好。可以看到接受度最高的是Explanation by example。
这个也给我们一个启示,如果解释是用于这种业务系统,或者需要像业务方式进行解释的话,使用样本解释的方式更好。但如果作为开发者的话, Shapley可能会更有用些。
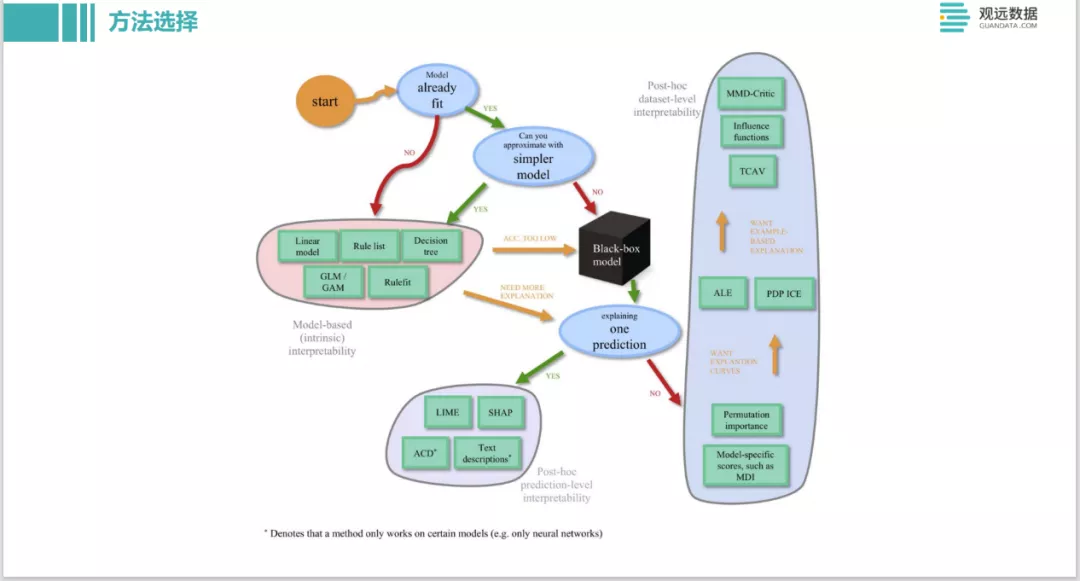
这也是推特上的一个对模型解释的方法选择。包括你能不能接受精度比较差的模型,是不是需要做全局的解释,还是 local的每一条instance的解释,列了一个类似于决策图,也可以根据这个来选择。

那什么是好的解释?也有很多这方面研究。尤其是当解释的对象受众是不一样的群体的时候,要特别去关注一些点,从社会心理学层面,去看人们如何接受什么样是一个好的解释。学术界多这块也有一些研究。
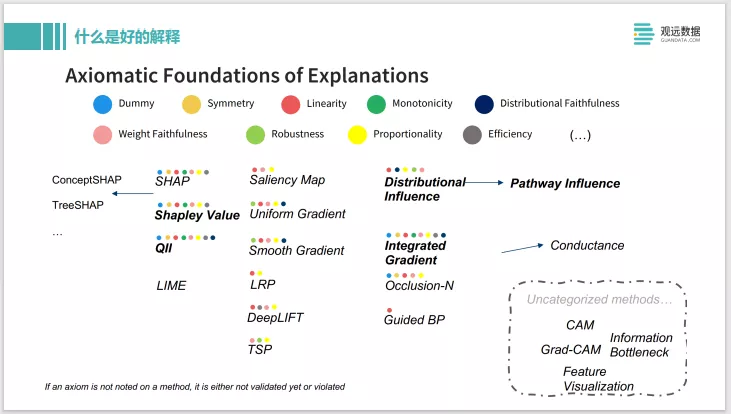
最近 AAAI 2021年的tutorial从数学性质上总结了一系列的好的解释的性质。上面是各个解释的方法它拥有这些性质的多少,数量比较多的两个是 Shapley Value和Integrated Gradient。这两个方法如果用神经网络的话,可以用 IG,如果用一些传统模型,Shapley Value也是一个非常好的选择。
实战环节

前面我们讲了怎么用模型解释的方法来Debug模型。右边这张图是如何构建模型。中间这个人站在一堆矩阵、运算的东西上面,左边这个漏斗是数据进来,右边出口那边结果会出来。当构建起一个很复杂的模型后,数据进来结果出来,你一看这个准确率不太好,那接下来你会怎么做?
这个人把中间这堆很复杂的东西捣鼓下,就是调参数,然后改一改模型结构,换个不同的激活函数或损失函数,然后看看效果是不是变好了,不行的话再继续进行调试。这样的调试可能效率是比较低的,而且也不能准确的知道中间的模型到底做了些什么,所以对于模型的迭代开发来说,并没有什么大的帮助。
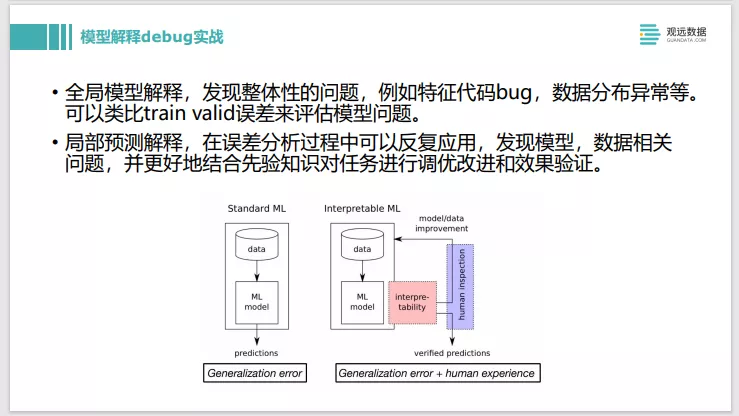
有了模型解释工具之后,可以帮助来改进这个流程。当有了结果之后,可以用模型解释工具,对预测不太好的一些条目进行解释。看一下用的特征是不是符合预期,如果不符合,可以把人工经验植入到模型的构建流程中去。通过模型解释发现问题之后,跑了一轮新的训练,出了一个新的结果,这个时候还可以继续用解释工具去验证改进是不是有效。做实验时,除了过拟合和欠拟合这种很直接从指标上看到的,其他一些更细节的问题,有了模型解释工具之后是很有帮助的,会帮你加快迭代速度,而且很好的把人工业务经验融入进去。
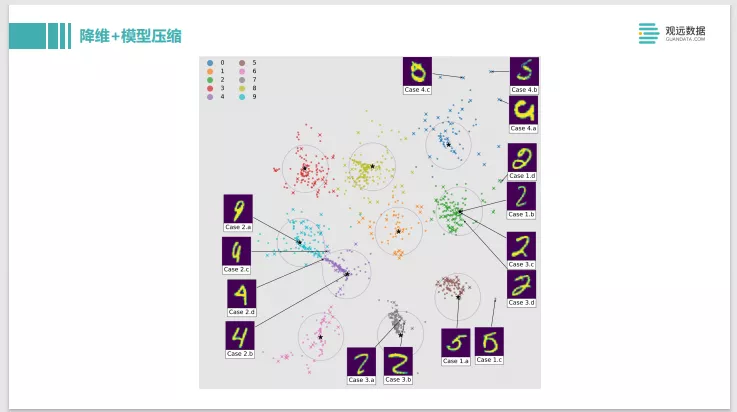
这是一个挺好玩的例子,叫Dark Sight,同时做了一个降维和模型压缩。训练了classifier多分类的模型之后,可以把模型的预测输出结果降维而且可视化在一个二维平面上。这个降维有个很好的特性,可以看到这中间两个,一个是蓝色块,是一系列9的数字,粉色块是4的数字。这两个圈中间有个交界,把交界点数字实例点选出来,会发现这个数字长的既像9又像4。这个特性就能够把模型觉得不好判断的部分很直观的可视化在画布上,而且通过点击交互的去分析,中间那些样本又像9又像4,对模型来说比较困难,那么可以有针对性去做一些处理。这也给我们带来一个启发,其实很多模型的降维和数据的降维,也是对模型的解释有帮助的。
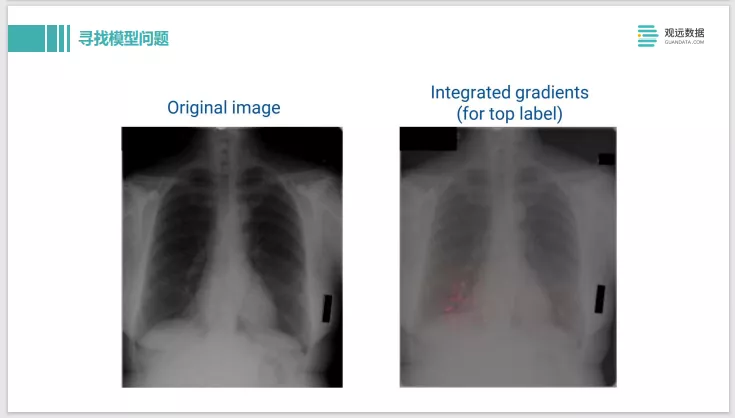
这是利用IG – Integrated Gradients,做 X光片的疾病诊断。可以看到原始输入的图片是左边。输出的 label是这个人有疾病,我们用了 IG去做解释后,可以看到右边这边有一些粉红色的高亮,这表示在这些像素点上的模型认为样本被分类为有问题,是贡献度最大的像素点。
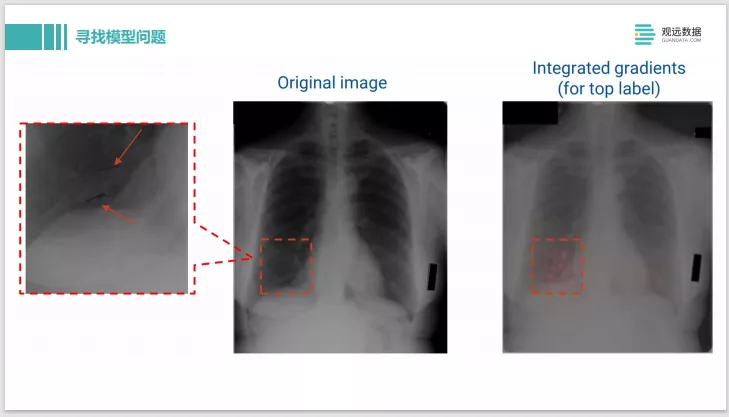
我们可以再把像素点放大,看看模型到底是做了什么样的判断。结果发现这个其实是上面有两条用黑色记号笔画的线,应该是医生在诊断过程中看了X光片,确诊出来有问题,就在这边画了两条马克笔的线,那模型学到的是医生的标记,并不是学到了病理组织的 pattern,所以模型的判断其实是有问题的。这样就可以很方便的通过模型解释的方法去找到模型中的一些弱点。

下面这个例子也是类似的,它也是用了IG的方法。这是一个VQA - Visual Question Answering看图问题的任务。这个问题是在图片中 white bricks有多对称。模型给出的回答是very,它是很对称这个回答是很make sense的正确回答。但是我们用了技术去对它进行了分析之后,发现红色的文字具有很高贡献度,蓝色的是比较有负面贡献度,灰色的几乎是没有什么贡献度的,所以其实模型给出的这个回答预测,其实它是重点关注在这个How上面,所以关注度是有问题的。
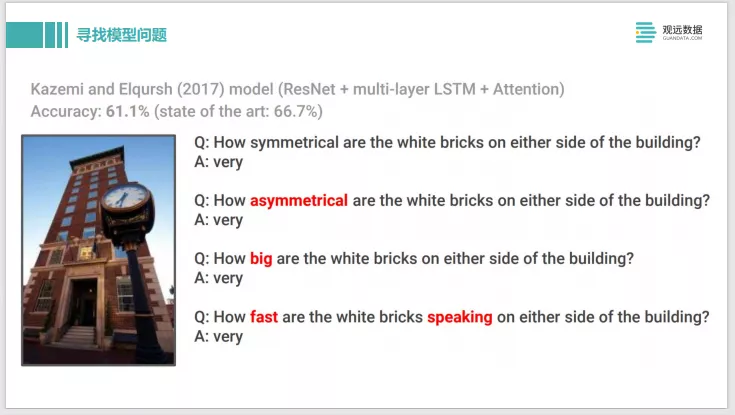
因此如果我们把中间 symmetrical换成别的词,比如asymmetrical,是不是不对称的,或者how big有多大,甚至改成一句完全没有什么含义的话。White bricks speaking, how fast,它回答是very。这样就帮我们发现了这个模型的问题,它其实没有真正的去理解这句话和图片,但是它看似给出了一个很好的预测,这样也是帮我们发现模型的一些问题。
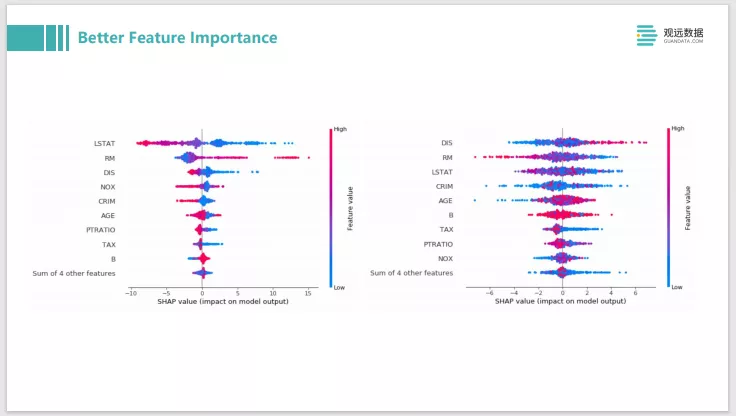
如果是一些传统的表格类的数据,那么我们可以用SHAP来做分析。比如像XGBboost或者LightGBM,大家会经常去分析 feature-importance,给出一个模型的全局解释。其实用shap的话,可以给出一个更好的 feature-importance的解释,它其实不光是特征的贡献度从高到低排序,还可以是这个特征的贡献是正向还是负向,就是坐标轴左边是负向的贡献,右边是正向的贡献。另外还可以把这个特征的值和分布都绘在一张图上展现出来。
比如它的这个线比较粗的话,就是一个圆锥形的分布,数据量比较多;比如蓝色的是一个特征值是比较低的情况,红色的是特征值比较高的情况。左图是一个训练的比较好的模型,你大致看到大多数的特征,它在 Feature value高和低的时候,它可以把红色是负面影响,蓝色是正面影响明显的区分,它基本上可能都可以分开来。
右图我们把 label做了随机的打散。可以看到它的蓝色点和红色点基本就混在一起了,区分度明显不高了,所以可以通过这种图形上的pattern展现,帮助你去发现问题。如果你做了一个特征,它像右图这样,特征高和特征低都会混在一起,不知道是正面的影响还是负面影响,没有什么区分度的话,就需要去看下你的特征是不是做的有问题。
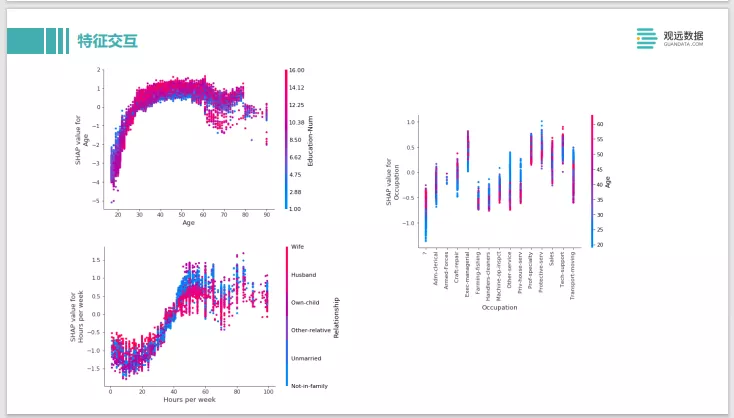
SHAP还可以做一些很复杂的特征交互的分析。这个是一个关于成人收入的例子,左上角两条轴分为两个特征。一个是他受教育的年份,下面是年龄。正向影响的是他的收入比较高,负向影响是他的收入比较低。可以看到年龄在2030岁的时候,当受教育年龄比较低的时候,它反而是一个正向的影响。这个也比较好理解因为在2030之间,如果受了10多年教育那他可能当时刚毕业,大多数情况下收入肯定是低的。这个可以印证,一些业务的知识能不能体现在你数据中,体现在你的模型中。还有比如右边这个可以去看他的职业跟他的年龄和收入的影响。我们可以从中去分析,是不是有一些年龄,他是年纪越大,收入会越高。有些年龄是年纪越轻他的收入会越高,是一个吃年轻饭的职业的。这些都可以通过SHAP value的这种特定交互的分析来做一些判断。如果它不符合你的业务常识,你可以针对性的去做一些数据上的诊断和修改。
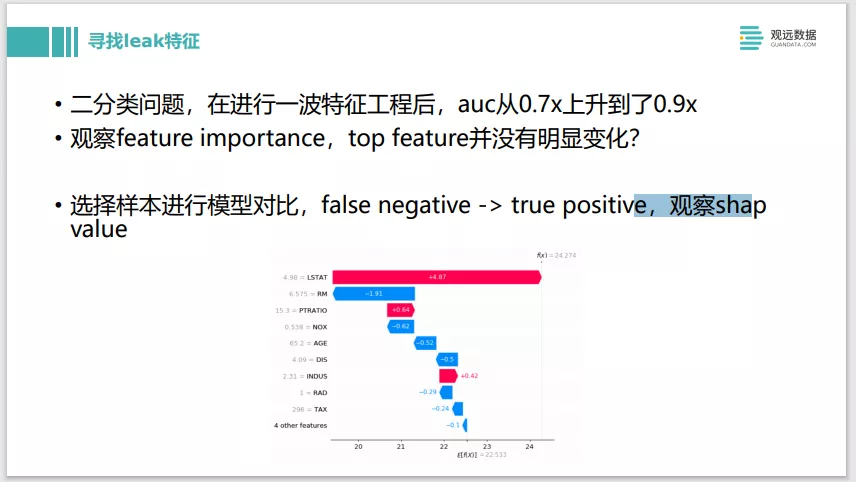
这个例子是我们做了一个二分类的问题,做了一波特征工程,突然发现 AUC从原来的0.7级上升到了0.9,明显是不太合理的,应该是发生了一些问题。我们观察了下前后的Feature importance,发现好像 Top feature它并没有一个很明显的变化,没有一个特征突然importance从下面窜上来,没有找到这样的一个明显的leak特征。其实这样的情况我们也可以用SHAP value来做。可以选择新旧两个模型,然后找一条预测样本。比如它原先是一个false negative预测错了的,后面被预测成true positives预测对的。我们分别去看前后的SHAP value的对比,再去看SHAP value正向贡献差别最大的一个特征到底是哪个。我们可以挑个10条20条样本分别去验证一下,发现他们都是落在了同一的特征上面的话,那么就很容易就可以找到leak的特征到底是哪个。这个也是一个直接用模型检测技术去找leak特征的实例。

那么如果是回归问题的话也是类似的。比如可以找Top高估的那些预测样本和Top低估的预测样本,然后分别去在组内做一些SHAP value相关的一些分析,去看下TOP高估的那些,它的正向影响的最大的特点到底是哪些。如果是有问题的特征,我们可以做一些针对性的分析,如果是特征区分度不够高的话,可能要增加一些新的特征进去。Top低估点,也是类似的做法。

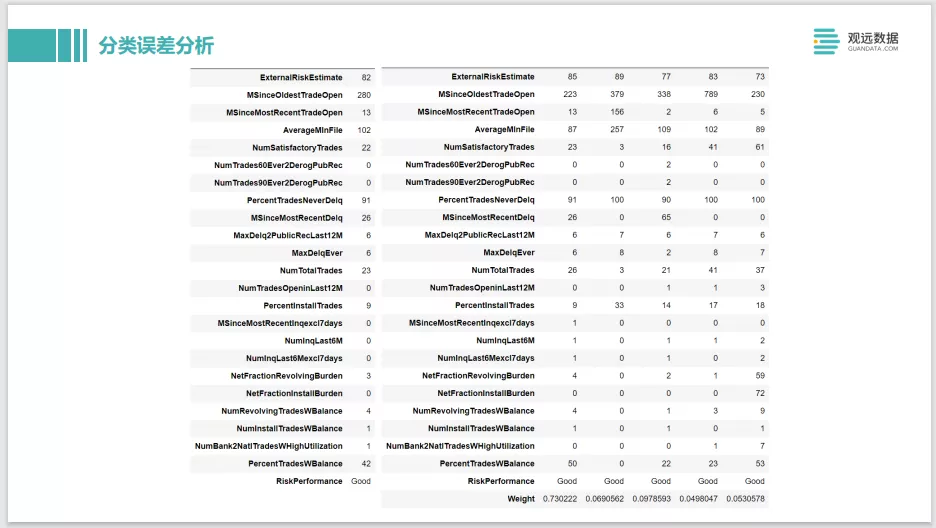
如果是分类问题其实也是一样。比如说你关注得分最高和得分最低的这些错误的样本,就是你最有信心的,但是它预测错了。另外决策边界附近预测是个50%可能性附近的一个样本,你也可以用SHAP去分析它的特征,看看是不是有些冲突的特征。就是a特征跟b特征其实是有一些冲突,导致他们的效果抵消了,最后模型就不太确定到底是一个正样本还是负样本。
除了SHAP之外,分类问题它可以用的一些技术还更多一点。包括使用example来做一些解释,比如ProtoDash来找一些Prototype的样本。还有用反事实样本来诊断这些样本的数据问题。
这个 ProtoDash的大致的含义,它是一个信用卡的信用分析,左边这条样本特征的值,输出预测的结果是好的,就是认为这个人是一个有信用的人。那为什么模型给了他这个预测,我们就可以在训练集中去找跟他类似的样本。所以ProtoDash就是在找出了一条目标样本之后,我们在训练集中去找跟他类似的一些原型样本。找到之后,可以看到右边的第一条weight很高,表示跟它的相似度是非常高的。那就可以给业务方很好地解释,当你的训练样本中有一条跟他特征非常接近的一条样本,因为当时他是一个守信用的人,那新进来的一条样本我们就认为他也是一个守信用的人。但如果这两条发现了冲突,比如我们发现这个人模型预测是好的,左边测试样本最后label显示这个人是信用不好的。那这个时候我们就需要去看,为什么跟他相似的人信用是好的,是不是在这两个人之间有些什么差异我们没有抓到。那我们就需要增加一些特征去强化这两条特征的区分度,否则这个模型在相近的时候就很难区分出来。或者对于特征要有些分层处理,都可以去帮助模型改进提升,可以融入你的一些业务知识改进模型。
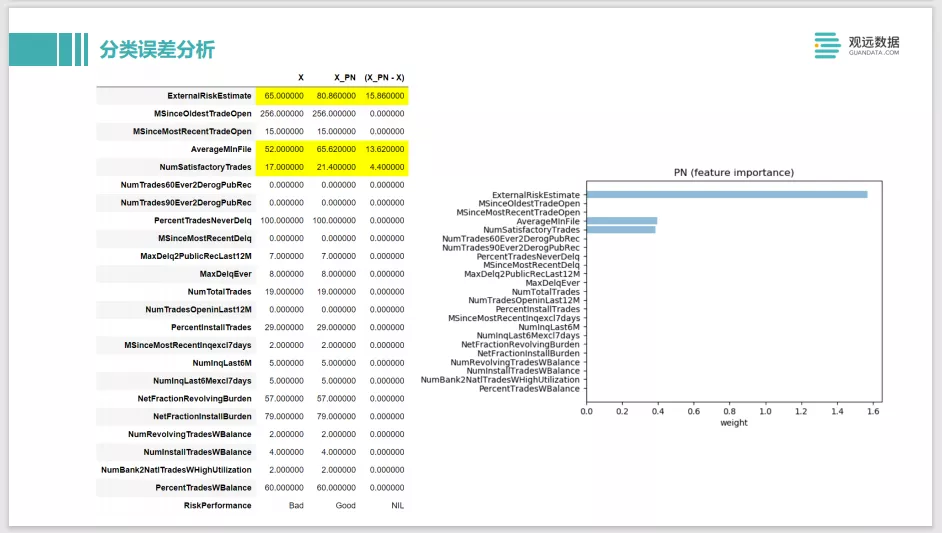
最后这个是一个counterfactual的案例,还是刚才那个例子。比如原先这个人最左边的 X,他被预测出来是不守信用的,那他需要做哪些事情,能够让他通过验证,认为他是一个守信用的人。模型给他的建议是有三个值要提升。第一个是 ExternalRiskEstimate,这个值是越大越好的值,类似于芝麻信用分,是外部的平均积分,芝麻信用越高,说明这个人更守信。下面的 AverageMinFile和 NumSatisfactoryTrades,一个是履约的次数,他履约的次数越多,理论上来说应该是更守信用的,还有他的记录的月数,就是他整个的历史的信用周期有多长,比如信用卡已经用了10年了,那我们会认为他更可能是一个守信用的人。如果counterfactual的样本是比较符合你的业务判断的话,那说明这个模型总体上训练是准确的。
但如果最后出现了一些比如他希望性别换一换或者种族换一换,模型学到的东西可能是有些问题的。我们可能会发现这个模型在对他的公平性上是有问题的,所以需要做一些改进。这个是用这种实例样本的例子,来解释方法,让它帮我们改进模型。

关于模型开发,还有一个大的应用,就是怎么用这个模型解析技术去给业务方做解释。这边举了个例子,我们需要用不同的需求来构建模型。比如我们要构建一个用户的复购模型。我们这边有三种选择,第一种就是能够准确的预测出哪些用户会复购。你的业务的目标是accuracy,就是可以不管别的,只管提升准确率就行了。
模型二是能够告知哪些特性的组合与复购行为是高度相关的,这是一个全局性的解释的例子。就是把insights提供给业务方,业务就知道需要去做哪些事情,可以让用户的复购率提升。对他们来说是一个业务上的指导。我们可以选择一些相对简单的,比如决策树、线性回归就可以了。
模型三是能够告知为什么这个模型认为某一个用户会进行复购。它是一个更细粒度的local的解释。它的使用场景比如是我们在做客户营销时候,某个客户购物后,模型预测他可能后面不回再复购,我们可以解释一下为什么预测他不
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B2%E8%B4%A7%E7%AF%87%E8%A7%82%E8%BF%9C%E6%95%B0%E6%8D%AE%E5%8F%AF%E8%A7%A3%E9%87%8A%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%8E%9F%E7%90%86%E5%8F%8A%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


