干货的实现多视图人体数据集等开源项目
— 文末200本AI纸质书、机械键盘、硬盘、VIP会员,来就送~ —
项目一:YOLOv5-PyTorchYOLOv5的PyTorch实现
项目地址:
https://github.com/Okery/YOLOv5-PyTorc
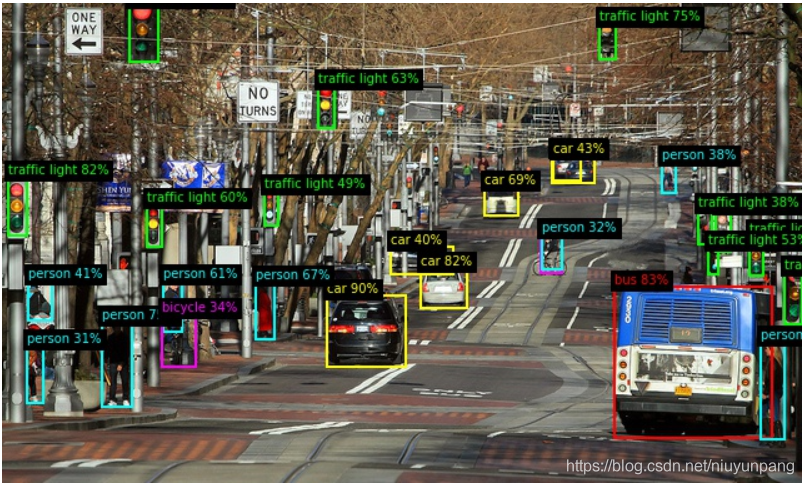
YOLOv5的PyTorch实现。该存储库具有两个功能:
- 纯python代码,无需构建即可立即使用PyTorch 1.4运行
- 简化构造并易于理解模型的工作原理
环境要求:
- Windows或Linux,Python≥3.6
- PyTorch≥1.4.0
- matplotlib-可视化图像和结果
- pycocotools-用于COCO数据集和评估;Windows版本在这里
- nvidia dali(仅Linux)-更快的数据加载器
数据集:
-
该存储库支持VOC和COCO数据集。
-
如果要训练自己的数据集,则可以:
-
编写相应的数据集代码
-
将您的数据集转换为COCO样式
-
PASCAL VOC 2012(下载):http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
MS COCO 2017: http://cocodataset.org/
模型训练:
使用 1 GPU在COCO数据集上训练 (如果你使用2 GPUs, 设置 –nproc_per_node=2)
性能:
在单个RTX 2080Ti GPU上测试COCO 2017

— 今 日 福 利 —
七月在线AI充电季,开宝箱活动倒计时 2 天!!
200本AI纸质书、机械键盘、硬盘、VIP会员,来就送 ~
活动截止时间:7月31日 15:00
**点击立即开宝箱: https://m.julyedu.com/box/landing?treasure_code=3637373037302c37&origin=2**

项目二:weibo-public-opinion-datasets持续维护的微博舆情数据集
项目地址:
https://github.com/nghuyong/weibo-public-opinion-datasets
新浪微博是中国最大的公共社交媒体平台。最新和最受欢迎的社交活动将尽快在微博上公开和讨论。因此,建立一个实时,全面的微博舆情数据集具有重要意义。
目前,在给定指定关键词和指定期限的情况下,微博推文数据集的构建方法有两种:(1)应用微博提供的高级搜索API;(2)遍历所有微博用户,收集指定时间段的所有推文,然后使用指定的关键字过滤推文。
但是,对于第一种方法,由于微博搜索API的限制,一次搜索的结果最多包含1000条推文,这使得构建大型数据集变得困难。至于第二种方法,尽管我们可以构建几乎没有遗漏的大规模数据集,但是遍历数十亿微博用户需要非常长的时间和大量的带宽资源。另外,大量的微博用户是不活跃的,遍历他们的主页是没有意义的,因为他们在指定的时期内可能不会发布任何推文。
为了缓解这些局限性,我们提出了一种新的方法来构建微博推文数据集,该方法可以构建具有高构建效率的大规模数据集。具体来说,我们首先建立并动态维护一个高保密性的微博活跃用户池(仅占所有用户的一小部分),然后我们仅遍历这些用户并在指定时期内使用指定的关键字收集其所有推文。
基于初始种子用户并通过社交关系不断扩展,我们首先建立了一个包括超过2.5亿用户的微博用户池。活跃的微博用户池是基于微博用户池构建的,遵循4条规则:

项目三:occlusion_person具有详细遮挡标签的多视图3D人体姿势估计数据集
项目地址:
https://github.com/zhezh/occlusion_person
该数据集是相关的工作“AdaFuse: Adaptive Multiview Fusion for Accurate Human Pose Estimation in the Wild”,该出版物已发布在IJCV上。该论文位于(arXiv:2010.13302)。

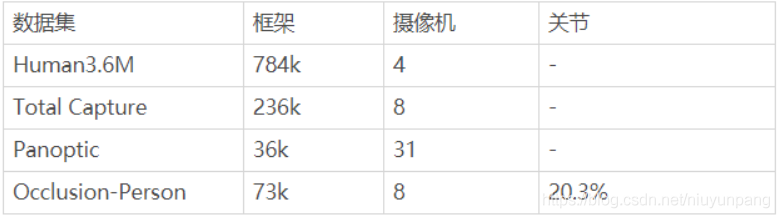
以前的基准测试没有为图像中的关节提供遮挡标签,这阻止了我们对遮挡的关节进行数值评估。另外,基准中的遮挡量是有限的。为了解决这些限制,我们建议构建此综合数据集Occlusion-Person。我们采用UnrealCV来渲染3D模型中的多视图图像和深度图。
特别是,将十三种不同衣服的人体模型放置在九个不同的场景中,例如客厅,卧室和办公室。人体模型由从CMU Motion Capture数据库中选择的姿势驱动。我们故意使用诸如沙发和书桌之类的物体遮挡某些身体关节。每个场景中放置了八台摄像机,以渲染多视图图像和深度图。我们提供15个关节的3D位置作为地面真实情况。
图像中每个关节的遮挡标签是通过将其深度值(可在深度图中获得)与3D关节在相机坐标系中的深度进行比较而获得的。如果两个深度值之间的差小于30cm,则不会遮挡关节。否则,它将被遮挡。下表将此数据集与现有基准进行了比较。特别是在我们的数据集中,约有20%的身体关节被遮挡。

完全下载所有部分后,您应该具有以下文件:
项目四:coco-minitrainminicoco数据集
项目地址:
https://github.com/giddyyupp/coco-minitrain
COCO minitrain是针对COCO的精选小型训练集(25K图像≈train2017的20%)。这对于超参数调整和降低消融实验的成本很有用。minitrain的对象实例统计信息与train2017的那些匹配。在minitrain上训练的模型的val2017性能与在train2017上训练的同一模型的性能强烈正相关。
COCO minitrain是COCO train2017数据集的子集,包含25K图像(约占train2017集的20%)和跨80个对象类别的约184K注释。我们从全套样本中随机采样了这些图像,同时尽可能保留了以下三个数量:
每个类中对象实例的比例,
小型,中型和大型物体的整体比例,
小型,中型和大型物体的每类比率。
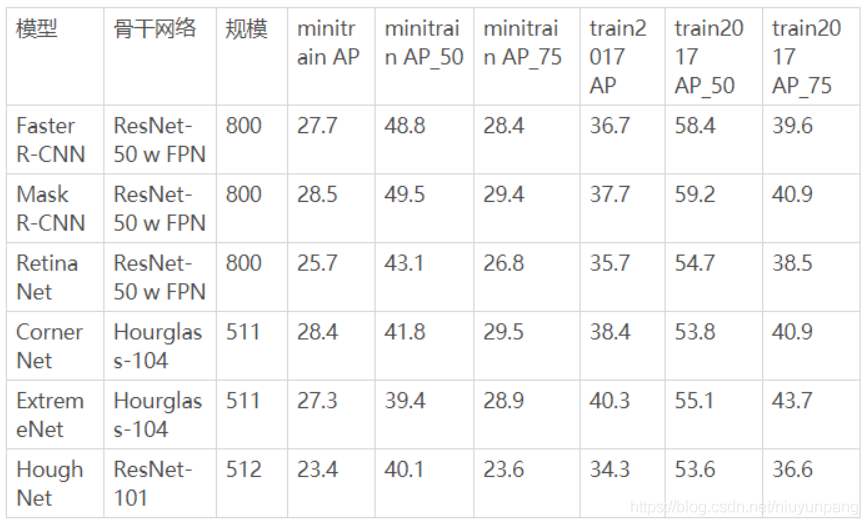
对象检测器性能。在minitrain上训练模型并在val2017上进行评估:
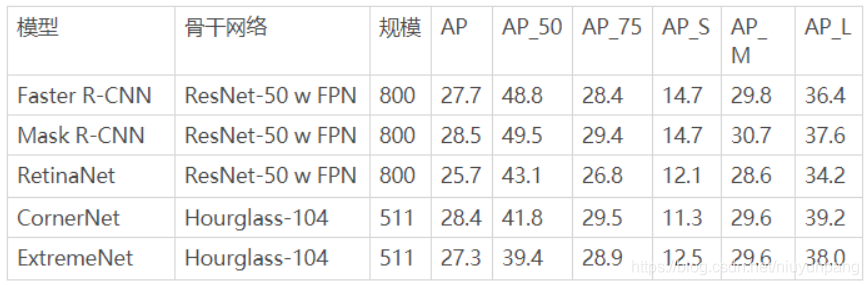
在Minitrain vs Train2017上训练的对象检测器性能。模型在val2017上进行评估:
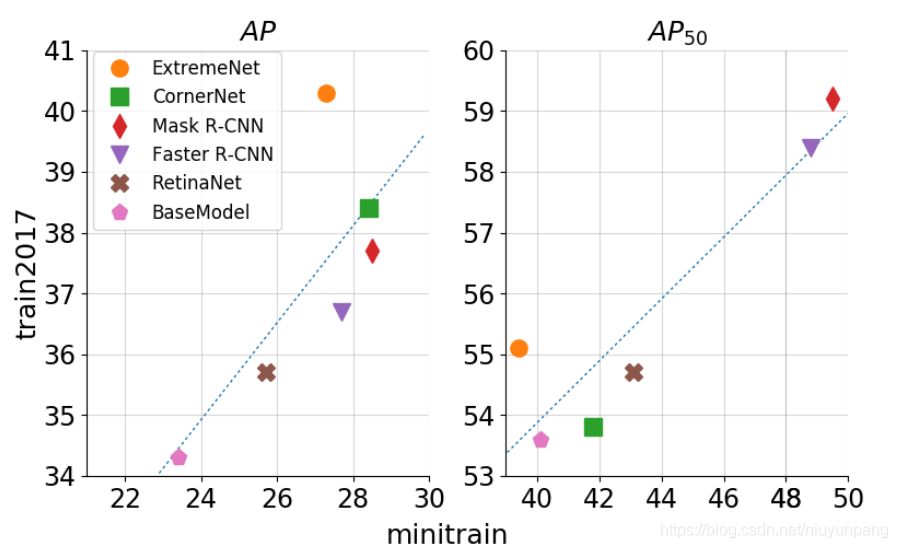
下图比较了train2017和minitrain上的物体检测结果。该图还显示了train2017和minitrain结果之间的正相关。对于COCO评估指标AP和AP50,皮尔逊相关系数分别为0.74和0.92。此图基于上表。 BaseModel与具有ResNet-101主干的HoughNet模型相对应。
项目五:sidechainnet 用于机器学习的全原子蛋白质结构数据集
项目地址:
https://github.com/jonathanking/sidechainne

SidechainNet是一种蛋白质结构预测数据集,它直接扩展了Mohammed AlQuraishi�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B2%E8%B4%A7%E7%9A%84%E5%AE%9E%E7%8E%B0%E5%A4%9A%E8%A7%86%E5%9B%BE%E4%BA%BA%E4%BD%93%E6%95%B0%E6%8D%AE%E9%9B%86%E7%AD%89%E5%BC%80%E6%BA%90%E9%A1%B9%E7%9B%AE/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


