干货模型验证的常用武器和
每次做完二值分类模型(eg: Logistic Regression, Decision Tree, Neural Network etc.),我们经常会面对一连串的模型验证指标,最常用的有ROC&AUC、Gini、PS、K-S等等。那我们不禁会问:
1. 这个指标怎么定义?
2. 怎么实现指标计算?
3. 为什么用这个指标?
4. 怎么用它评价模型?
事实上,如果不明白这些评估指标的背后的直觉,就很可能陷入一种机械的解释中,不敢多说一句,就怕哪里说错。在这里就通过这篇文章,针对上述4个问题,介绍一下ROC&AUC。
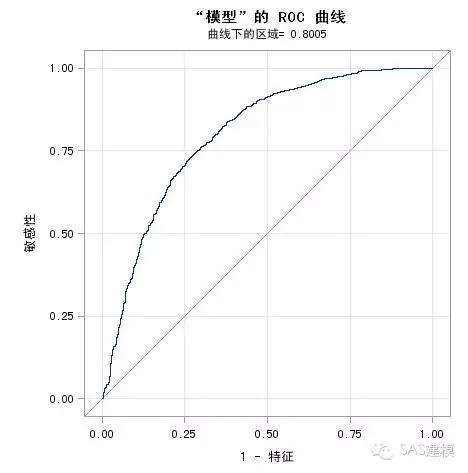
问题1: ROC&AUC的定义分别是什么?
ROC曲线 全称为受试者工作特征曲线 (receiver operating characteristic curve),它是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(敏感性)为纵坐标,假阳性率(1-特异性)为横坐标绘制的 曲线。
AUC (Area Under Curve)被定义为ROC曲线下的 面积。我们往往使用AUC值作为模型的评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
** 注意:ROC是一条曲线是一条曲线啊,并不是一个值啊!真正通过计量手段比较模型功效的是AUC!!**
问题2: AUC是如何计算得到的?
既然我们已经了解到AUC其实就是ROC曲线下的面积,那我们首先要理解ROC曲线从何而来,这其中必定蕴含了ROC&AUC蕴含的价值。
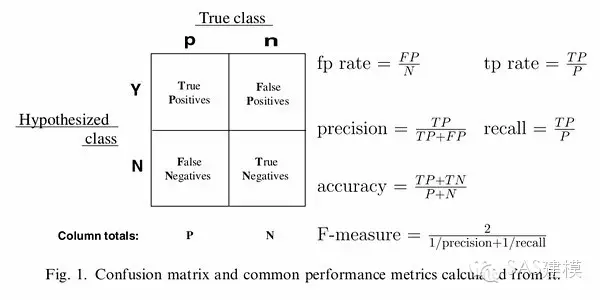
作为理解ROC曲线的铺垫,我们还要先了解一下 混淆矩阵(Confusion Matrix)。显然,一个完美的二分类模型就是,如果一个客户实际上属于类别good,也预测成good(True Positive类),处于类别bad,也就预测成bad(True Negative类),也就是完全预测准确。但从实际模型情况来看,往往会有一些实际上是good的客户,经过我们的模型,被预测为bad(False Negative类),对一些bad的客户,却预测他为good(False Positive类)。事实上,我们需要知道所建的模型到底预测对了多少,预测错了多少,然而混淆矩阵就把所有这些信息,都归到这样一个表里。
**_
 **
**
_
实际数据中,客户只有good/bad两种可能,模型预测结果同样也只有这两种可能,可能匹配可能不匹配。匹配的好说,Negative预测为Negative,或者 Positive预测为Positive,这就是True Negative(其中Negative是指预测成Negative)和True Positive(其中Positive是指预测成Positive)的情况。
同样,犯错也只有两种情况。实际是Positive,预测成Negative ,这就是False Negative;实际是Negative,预测成Positive,这就是False Positive;
明白这些概念后,不难理解以下几组常用的评估指标:
(事实上ROC曲线只用到其中的3和4)
1. 准确率accuracy: 针对整个预测情况。预测正确的/总实例数 = (TP+TN)/(P+N) 2. 误分类率error rate: 针对整个情况。预测错误的/总实例数 = (FP+FN)/(P+N)
3. 召回率recall/敏感性sensitivity: 针对good的正确覆盖了。预测对的good实例/实际good的实例 = TP/P
4. 特异性specificity: 针对bad的预测正确率。预测对的bad实例/实际的bad实例数 = FP/N
5. 命中率precision: 针对good的预测正确率。预测对的good实例/预测的good实例数 = TP/(TP+FP)
6. Type I error: False Discovery Rate(FDR, false alarm) = 1- precision
7. Type II error: miss rate = 1- sensitivity
理解了混淆矩阵后,ROC曲线就不难理解了。事实上,ROC曲线就是不同的阈值下,敏感性(Sensitivity)和1-特异性(Specificity)的关系曲线。其中ROC曲线的横轴为(1-特异性),即1-预测对的bad实例/实际的bad实例数;纵轴为敏感性,即预测对的good实例/实际good的实例,易知ROC曲线的横轴纵轴的值域均为[0,1]。
下面我们从ROC曲线横轴值从0到1取三个点进行展示,以计算对应的纵轴值:
1. 1-特异性=0
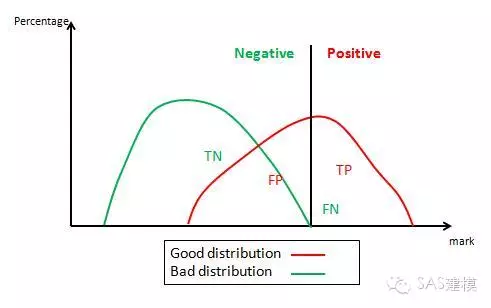
1-特异性=0 意味着 预测对的bad实例/实际的bad实例数=1,也就是说所有bad都被预测为bad,如上图所示。此时,对应的纵轴值敏感性=TP/P=0.45。因此对应ROC曲线上的点(0,0.45)。
2. 0<1-特异性<1
随着横轴值从0到1的增加,通过上图可以表达为分割线的左移,如下图。
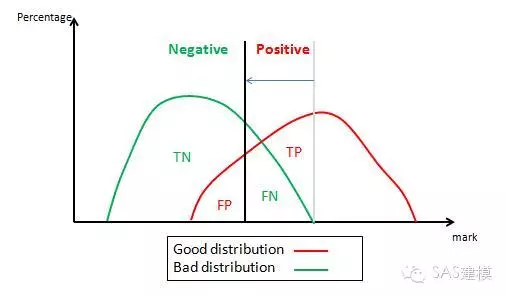
可以看到,随着分割线的左移,也就是特异性逐渐减小,敏感性则逐渐增加。此时1-特异性=0.2,对应的敏感性=0.85。因此对应ROC曲线上的点(0.2,0.85)。
3. 1-特异性—>1
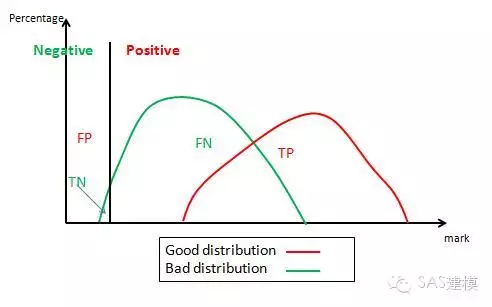
随着分界线的继续左移,达到样本分数最小值时,所有样本都被预测为good,此时1-特异性=0.98,对应的纵轴值敏感性=,1。对应ROC曲线上的点(0.98,1)。
好了,每个点都能画了,那ROC曲线也就不在话下了,AUC的计算也就顺其自然的进行了。
实际应用中,对于最常用的Logistic regression,SAS的PROC LOGISTIC可以轻松解决ROC图像绘制以及AUC计算的问题。
代码如下
proc logistic data=dataname plots(only)=roc;
model y=x1 x2 x3... xn;
run;
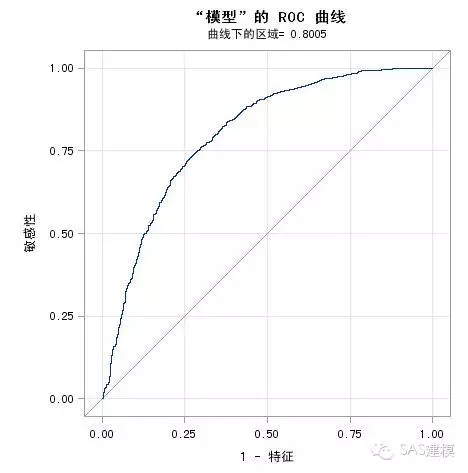
运行程序即可得到ROC曲线以及相应AUC=0.8005。
问题3: AUC值和模型功效有何关系?
我们不妨先固定某一横轴值,也就是说固定了分割线相对bad样本的位置关系,根据敏感性的定义(敏感性=预测对的good实例/实际good的实例 ),不难发现在有相等横轴值的情况下,纵轴值(敏感度)越大,模型功效越好。
下图中,对于相同的横轴值(固定坏样本分布和分割线),若模型的好样本结果的分布情况为Distribution2,其相应的纵轴值显然大于Distribution1的情况,也就是y2>y1。 同样,任意移动分割线(也就是对任意横轴值),都可以得到Distribution2的纵轴值大于等于Distribution1。那也很显然情况2的模型比情况1具备更强的区分能力。这是最简单的比较情况,如果两个模型并不是对于任意横轴值都存在一致的纵轴值大小区分,我们该怎么比较呢?
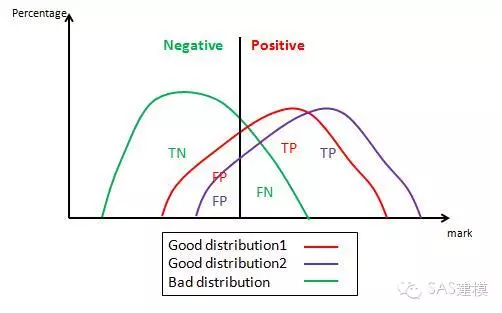
这里我们再来回顾一下AUC是什么。AUC事实上是ROC曲线下的 面积,事实上也是**敏感性在x属于[0,1]区间内的积分!**既然对于每个固定横轴值,都存在纵轴值越大模型功效越好这个说法,那么通过计量面积来比较模型的功效依旧成立,同时AUC还简化了指标的维度,将2维的ROC图转化为1维数值,简化的同时还提供了模型与模型之间比较的契机,这也就很容易理解我们为什么要使用AUC值来展示模型的区分能力了!
问题4: 如何使用AUC值评价模型?
ROC曲线下的面积值(AUC)正常情况下在0.5和1之间。应用中通常使用以下标准评价模型功效。
| AUC | 评价 |
| 0.9-1 | 高准确性 |
| 0.7-0.9 | 有一定准确性 |
| 0.5-0.7 | 有较低准确性 |
| 0-0.5 | 不符合真实情况 |
事实上,当模型的ROC=1时,模型将所有好坏样本完全分离,也就是说低分
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B9%B2%E8%B4%A7%E6%A8%A1%E5%9E%8B%E9%AA%8C%E8%AF%81%E7%9A%84%E5%B8%B8%E7%94%A8%E6%AD%A6%E5%99%A8%E5%92%8C/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


