布道师系列杨健天到分钟的改变下篇
上期回顾
《30 天到 3 分钟的改变!》系列主要讨论机器学习流程的三个阶段:数据获取和处理、模型训练和评估、模型部署和迭代。上期我们通过建模工具、算法和框架、高性能训练、管理特性重点介绍了模型训练相关的工具特性。本期将重点讨论模型部署和迭代!
模型部署和迭代
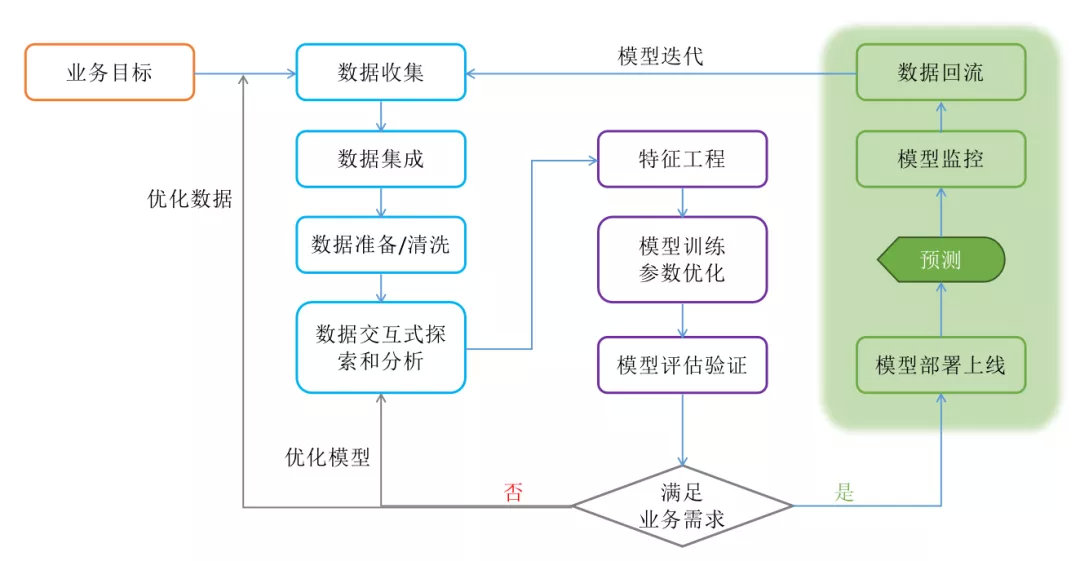 机器学习建模项目全流程
机器学习建模项目全流程
模型部署上线就像一辆概念车型开始量产投入市场,概念车如果不能投产除了供人 YY 解痒之外毫无意义。生产部署是模型产生业务价值的最后一公里,但往往最后一公里都是最痛苦最复杂的阶段。据统计超过 90% 的机器学习建模项目都止步于探索实验或 PoC 阶段,真正能够完成投产的项目不足 10%,可见模型部署上线存在着非常大的挑战。
挑战主要来自以下几个方面
● 训练和模型服务的运行时环境不一致:例如用 python 框架(scikit-learn、h2o 或者 keras)训练的模型要运行在 java/.net/c++/go 等语言的运行时环境里,或者是要在 hive 或 spark 中跑批运行。
● 模型的数据准备和特征工程 pipeline 在上线过程中非常复杂:训练和生产时使用不同的开发语言处理数据,复现和训练阶段完全一致的 pipeline 需要付出巨大的工程代价。java/c++/go 这些常用的应用开发语言中很难找到和训练时使用的数据科学工具包相匹配的类库和框架。
● 模型上线后的实际表现存在风险:在训练阶段即使在测试集上得到了令人满意的评估指标,也不代表模型上线后能表现出同样的效果。
● 模型的复杂度、精确度与服务性能之间的权衡取舍:深度神经网络模型越来越复杂,参数动则几亿甚至几十亿,模型文件也达到几十上百 G,在大幅提升了模型效果的同时给性能指标(吞吐量、时延)和资源占用上造成了非常大的压力。
● 模型要满足各种不同的消费方式:离线批量预测、在线服务调用、流式计算引擎调用。
●\* 模型需要不断迭代*:现实世界导致的数据分布的变化、用户习惯的改变、业务的调整都会使模型的表现受到影响,衰退是难免的。监控和持续迭代是保证模型性能的必备能力。
● 模型服务的基础设施需要具备企业级特性:高可用、负载均衡、弹性伸缩、高吞吐低延时。
APS 如何面对这些挑战
模型的运行时环境差异问题
也可以理解为模型跨平台问题,常用的办法是定义统一的模型输出格式然后为不同的语言提供 SDK 来解决。比如 PMML、MLeap 还有近年风头十足的 ONNX,都是这个思路。
但是这种方法并不能完全解决问题,比如 PMML(Predictive Model Markup Language)是大家最常用的输出格式。首先是性能问题,PMML 的运行时要比原生框架性能差,而且 PMML 是使用 XML 格式来描述模型的信息,输出的模型文件要大很多,加载模型的速度比较慢。另外是 PMML 有时会产生预测偏差,预测的结果和原生模型预测的结果不一致,这是个更严重的风险。还有 PMML 并不能支持所有算法,比如 xgboost、深度神经网络模型还有一些通过集成学习产生的模型有时无法使用 PMML 导出。
所以模型格式并不能解决所有问题,我们有时必须为模型服务复现训练时的运行环境,docker 容器是解决这个问题的最佳方案。
在 APS 中会为不同的算法预置好模型上线的运行时环境,包括 scikit-learn、keras、tensorflow、sparkml 以及 pmml、onnx 格式的模型运行环境,用户如果使用了更特殊的算法也可以自己定义运行时环境提交到 aps 的镜像仓库中即可。这样模型训练完成后 APS 会自动匹配对应的运行时环境把模型打包好一键完成上线,用户不用在考虑如果准备运行环境的问题了。
同时 APS 也提供把模型导出成通用格式 PMML 的功能,以便用户根据实际需求灵活使用模型,另外为了方便用户在 Java 开发中消费模型 APS 还提供了导出 Java SDK 的功能,直接导出 jar 包,引用后把模型当作一个函数使用。还有,在 spark 和 hive 中如果需要使用模型 APS 还可以把模型导出成 spark 或 hive 的 UDF 包。
关于数据 pipeline 的难题
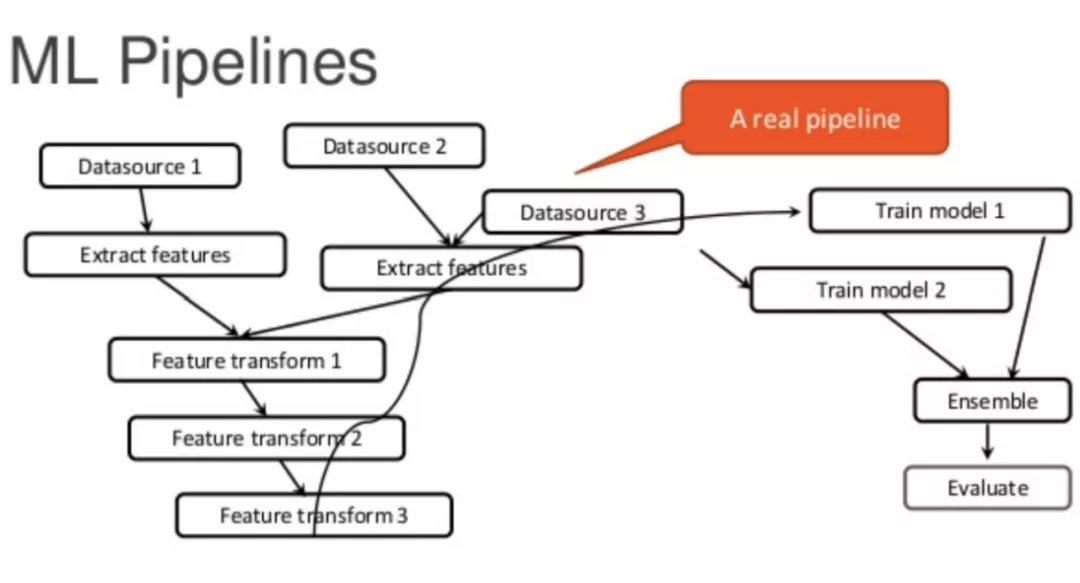 ML Pipelines 流程图
ML Pipelines 流程图
这个过程里面包含了两个部分:宽表加工和特征工程。在生产阶段离线跑批和在线服务对数据 pipeline 的实现方式不同,通常离线跑批更容易解决,在 APS 中我们如果使用工作流的方式建模,可以把宽表加工和特征工程的部分简单改造就能够迁移到生产环境,完成离线批量的模型预测任务。
但在线服务通常需要把模型包装成一个 RPC 服务,数据加工的 pipeline 中可能使用到 Spark 脚本、Python 脚本这些是无法直接迁移到一个 Java 进程内执行的,这部分要么就需要开发团队用 Java 或者其他应用开发语言重新实现一遍,当然代价更低的方法是把数据加工的部分尽可能的打包到模型文件中,APS 当前版本还不能够把宽表加工的部分全部打包到模型 pipeline 中,但已经可以实现常用的特征工程 Transformer 和算法模型一起打包成一个 dcpipeline 中实现生产上线。
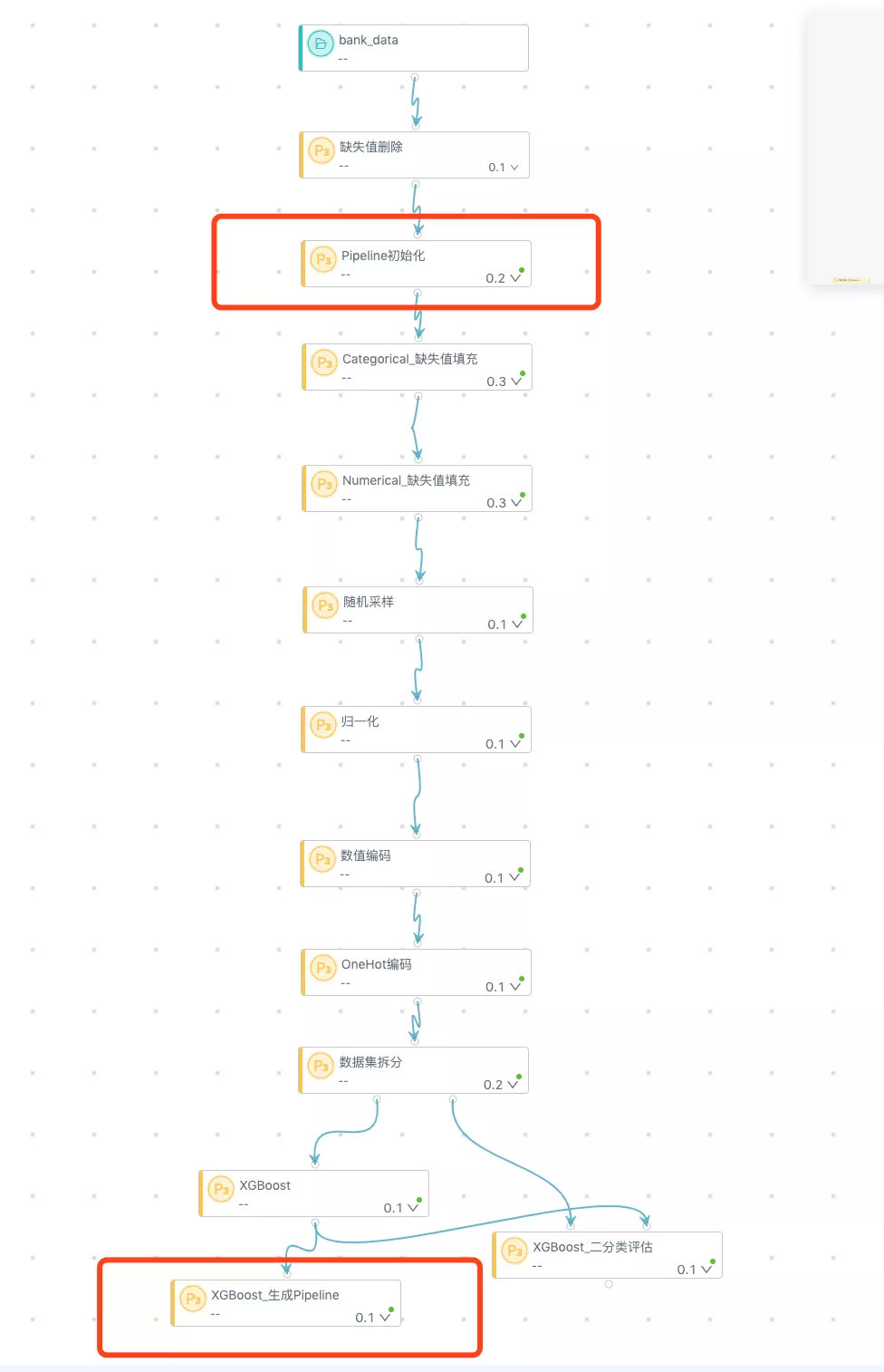
APS 通过“Pipeline 初始化”和“生成 Pipeline”两个模块可以实现把中间步骤打包成完成 Pipeline
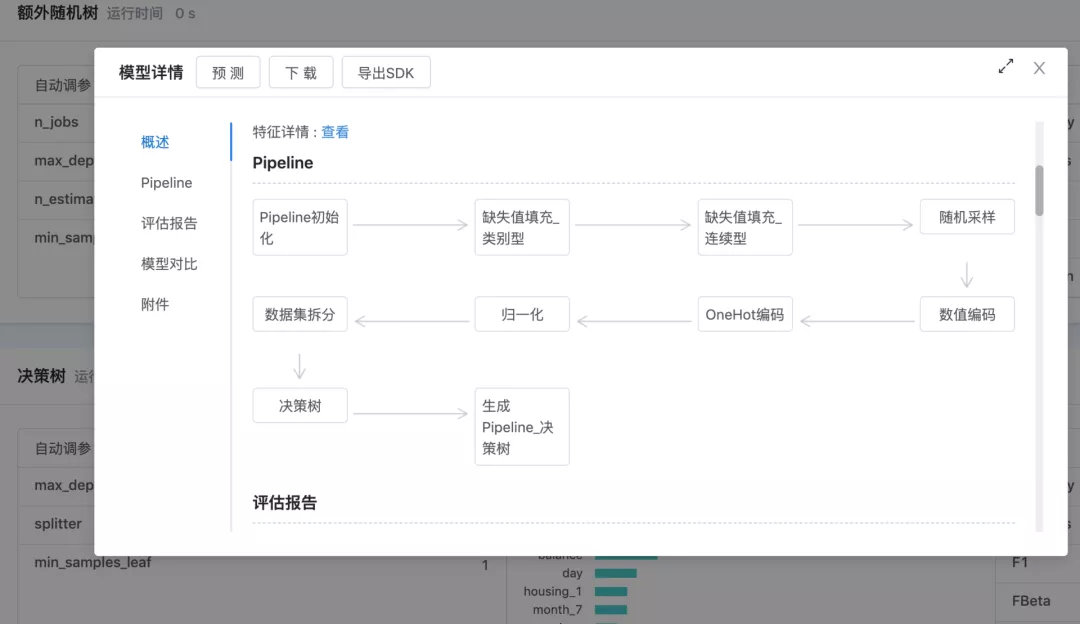
在 APS 中训练好的模型在详情信息中可以查看它完整的 Pipeline 信息
如何一起打包用户自定义的特征加工算法
目前可以通过把 pipeline 拆解成多个 stage,每个 stage 有不同的运行时环境要求,不同的 stage 放在不同的 contianer 中执行,再通过一个 engine 容器把几个 stage 整合起来来实现更复杂的 pipeline 上线。APS 中有专门的自定义 pipeline 上线的开发文档可以从研发团队处获取。
如何化解模型上线后实际表现不佳的风险和模型上线后的迭代过程可以结合起来讨论,通常解决此类问题的方法是利用 A/B Testing,冠军挑战等策略,在新的模型投产之前和现有模型或原有的方法在线上的表现做科学的对比,确保新的模型有更好的表现之后再正式上线。在 APS 中目前可以支持基于静态数据集的 AB 测试,用户可以在模型服务的界面中同时选择多个模型做性能评估。
模型的复杂度、精确度与服务性能之间的权衡取舍,是在对时延要求非常高的场景里比较常见的问题,比如在机器人对话场景,要求模型 inference 速度低于 20ms 才能实现比较流畅的对话体验,如果使用现在流行的 BERT 在性能优化上会存在巨大的挑战,到底选择损失模型的预测效果还是损失交互的流畅性是个非常纠结的问题。随着深度神经网络的表现越来越令人兴奋同时他的计算复杂度也越来越高,优化模型在线上表现的性能是一个必须解决的问题。目前比较常用的策略包括:
● 使用 GPU 提升模型的预测的速度。
● 使用优化过的底层计算库来提升性能,如 Intel 提供的 mkl、mkl-dnn 可以提升模型在 CPU 上的性能表现。
● 对模型进行裁剪和优化,tensorflow 专门提供了 Graph Transform Tool 帮助我们快速的优化训练好的模型。
● 单次请求转成微批处理。
_关于生产化阶段的话题确实很多限于篇幅暂时不一一展开,沿着这个话题
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B8%83%E9%81%93%E5%B8%88%E7%B3%BB%E5%88%97%E6%9D%A8%E5%81%A5%E5%A4%A9%E5%88%B0%E5%88%86%E9%92%9F%E7%9A%84%E6%94%B9%E5%8F%98%E4%B8%8B%E7%AF%87/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


