届校招提前批推荐算法面试题总结
文末彩蛋:七月在线干货组最新升级的《2021大厂最新AI面试题 [含答案和解析, 更新到前121题]》免费送!
问题1:非递归的二叉树中序遍历
该题为Leetcode-94:二叉树的中序遍历
方法:迭代
需要一个栈的空间,先用指针找到每颗子数的最左下角,然后进行进出栈的操作。
代码如下:
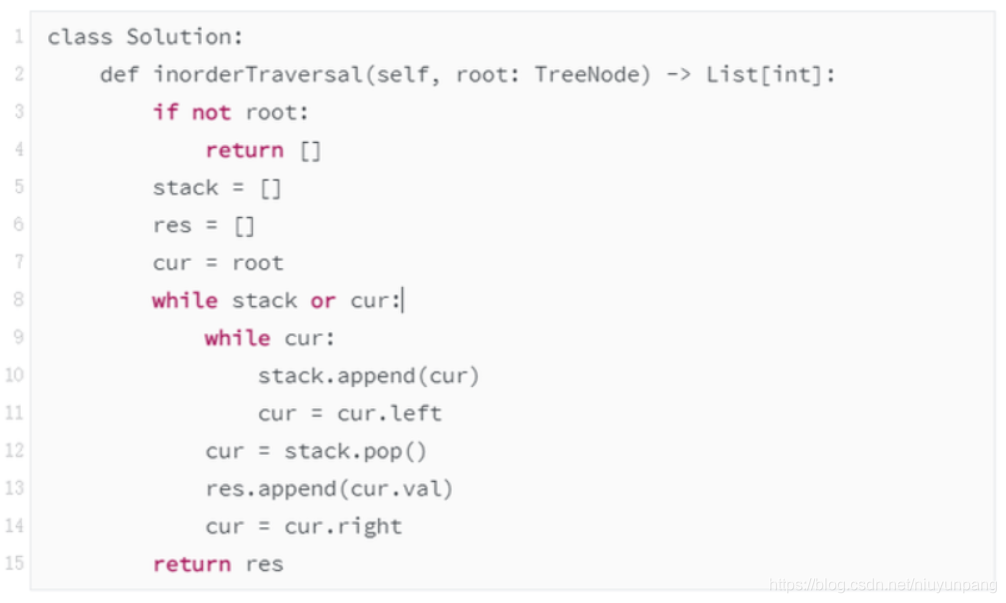
时间复杂度:O(n),n 为树的节点个数
空间复杂度:O(h),h 为树的高度
问题2:lightgbm相较于xgboost的优势
优点:直方图算法—更高(效率)更快(速度)更低(内存占用)更泛化(分箱与之后的不精确分割也起到了一定防止过拟合的作用);
缺点:直方图较为粗糙,会损失一定精度,但是在gbm的框架下,基学习器的精度损失可以通过引入更多的tree来弥补。
总结如下:
- 更快的训练效率
- 低内存使用
- 更高的准确率
- 支持并行化学习
- 可处理大规模数据
- 支持直接使用category特征
问题3:wide & deep模型wide部分和deep部分分别侧重学习什么信息
Wide&Deep模型的主要思路正如其名,是由单层的Wide部分和多层的Deep部分组成的混合模型。其中, Wide部分的主要作用是让模型具有较强的“记忆能力”,“记忆能力”可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率”的能力;
Deep部分的主要作用是让模型具有“泛化能力”,“泛化能力”可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力;正是这样的结构特点,使模型兼具了逻辑回归和深度神经网络的优点—– 能够快速处理并记忆大量历史行为特征,并且具有强大的表达能力。
问题4:点击率预估任务中负样本过多怎么办
正负样本不均衡问题一直伴随着算法模型存在,样本不均衡会导致:对比例大的样本造成过拟合,也就是说预测偏向样本数较多的分类。这样就会大大降低模型的泛化能力。往往accuracy(准确率)很高,但auc很低。
正负样本不均衡问题的解决办法有三类:
- 采样处理——过采样,欠采样
- 类别权重——通过正负样本的惩罚权重解决样本不均衡的问题。在算法实现过程中,对于分类中不同样本数量的类别分别赋予不同的权重
- 集成方法——使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集,从而训练出多个模型。例如,在数据集中的正、负样本分别为100和10000条,比例为1:100,此时可以将负样本随机切分为100份,每份100条数据,然后每次形成训练集时使用所有的正样本(100条)和随机抽取的负样本(100条)形成新的训练数据集。如此反复可以得到100个模型。然后继续集成表决
一般情况下在选择正负样本时会进行相关比例的控制,假设正样本的条数是N,则负样本的条数会控制在2N或者3N,即遵循1:2或者1:3的关系,当然具体的业务场景下要进行不同的尝试和离线评估指标的对比。
 想要逃避总有借口,想要成功总有办法! 今天给大家一个超棒的课程福利——【电商推荐系统特训】课程!8月10日开课,限时1分秒杀!
想要逃避总有借口,想要成功总有办法! 今天给大家一个超棒的课程福利——【电商推荐系统特训】课程!8月10日开课,限时1分秒杀!

课程通过四大实战项目实战掌握深度神经网络,且包含 **共享社群答疑 ➕ 免费CPU云平�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%B1%8A%E6%A0%A1%E6%8B%9B%E6%8F%90%E5%89%8D%E6%89%B9%E6%8E%A8%E8%8D%90%E7%AE%97%E6%B3%95%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


