实时计算引擎在贝壳的应用与实践
导读:本次分享的主题为实时计算引擎在贝壳的应用与实践。主要内容包括:
-
背景介绍
-
流式计算平台
-
实时分析监控平台-FAST
-
后续规划
——背景介绍——
贝壳找房由链家网升级而来,是以技术驱动的品质居住服务平台,聚合和赋能全行业的优质服务者,打造开放的品质居住服务生态,致力于为两亿家庭提供包括二手房、新房、租赁和装修全方位居住服务。
贝壳找房大数据架构团队负责公司大数据存储平台、计算平台、实时数据流平台的架构、性能优化、研发等,提供高效的大数据 OLAP 引擎、以及大数据工具链组件研发,为公司提供稳定、高效、开放的大数据基础组件与基础平台。
贝壳目前有1000多人的产品技术团队。从实时数据应用角度,公司内主要应用的实时数据,一个是线上的 日志,大概有两千多个线上的服务,每个服务又输出了很多的日志,日志数据是流式数据应用最多的。第二部分就是埋点,在 APP,web 端上报的经纪人作业情况和 C 端用户的行为,这部分通过前端的埋点技术上报。第三部分就是 业务 的数据,业务用 kafka 做消息队列产生的实时数据。
——流式计算平台——
1. 流式计算平台
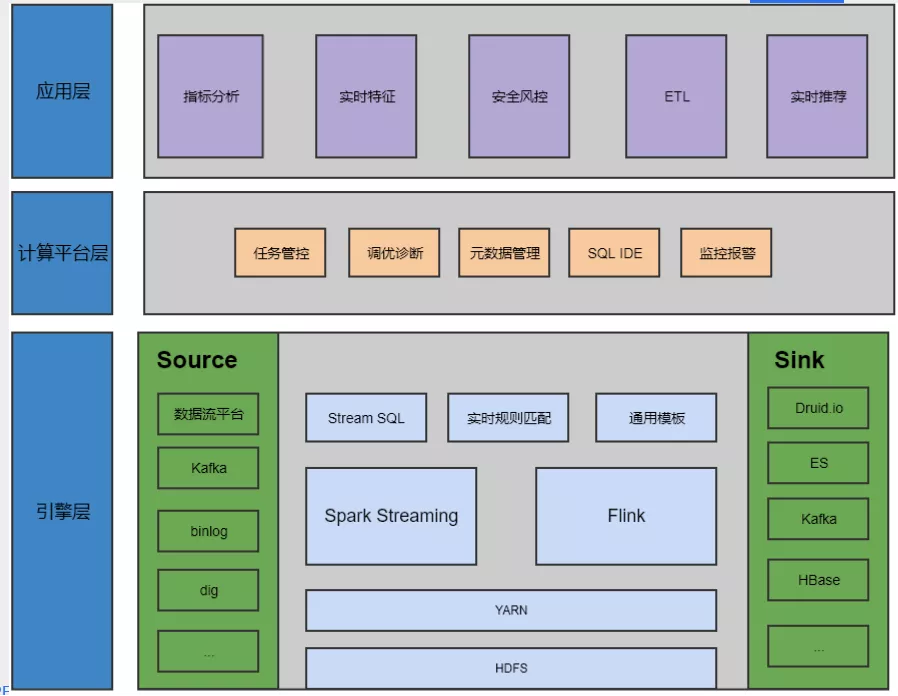
平台目前主要建设 Spark Streaming,Flink 两种在实时计算中比较常见的计算引擎。平台化的背景就是早期如果公司内有业务想用数据流进行计算,可能需要申请客户端,自己去搭建一个客户端,然后向集群上提交实时作业。这个产生的问题就是如果每个业务方都去自己这样做成本比较高,每个业务都需要关心自己作业的运维问题,还有监控,实时数据作业的监控建设的水平也是参差不齐。Spark Streaming,Flink 对于业务同学直接开发也有一定的学习成本,很难直接用上大数据的能力做实时计算。
我们计算平台流数据源主要都是用 Kafka。Kafka 数据中数据分为几类,一个是数据流,数据流指的是线上的业务日志、访问日志等,会收集到数据流平台。Binlog 是线上 MySQL、TIDB 产生的 binlog 作为实时数据源。Dig 是内部前端埋点项目的代号。
计算平台底层集群使用 YARN 做资源调度。再上层就是我们现在主要基于社区版 Flink、扩展了开源 Flink 的 SQL 能力。还有提供一些通用的实时处理模板。流计算的输出要覆盖线上业务所有需要的存储分析引擎,例如 ES、Kafka、Hbase 等等。在这些底层基础之上,首先要做的就是实时任务的管理管控。包括如何帮助平台上这些所有 Flink 或者 Spark 任务,进行资源的调优,对实时数据流中的数据的元数据化。另外还有在 Web 端提供的 SQL IDE、任务运行状态的监控报警。在计算平台之上业务方做的一些应用:指标分析,实时特征,安全风控,ETL、实时推荐等等。
2. 目前现状
目前 YARN 平台大概有七百多个节点,一千多个实时任务,每天的消息量千亿级,高峰单个任务消息量百万条/s。
3. 为什么要选择 Flink

Flink 提供了 Exactly-Once 一致性语义,并且具有非常完善的多种窗口机制,引入了 Event Time 与 WaterMark,还提供丰富状态的状态访问。Flink SQL 降低了实时计算的使用门槛,并且 Flink 社区非常活跃。
我们希望更多使用 SQL 的方式开发计算任务。SQL 的好处在于我们如果用写代码的方式计算需要从新建工程开始、引一些相关的依赖、编码、打包、提交。把这个事变成 SQL 的方式只需要 SQL 文本。我们用平台的 SQL 解析引擎去加载每个任务的 SQL 文本,就可以生成一个 SQL 任务。
4. 实时数据接入
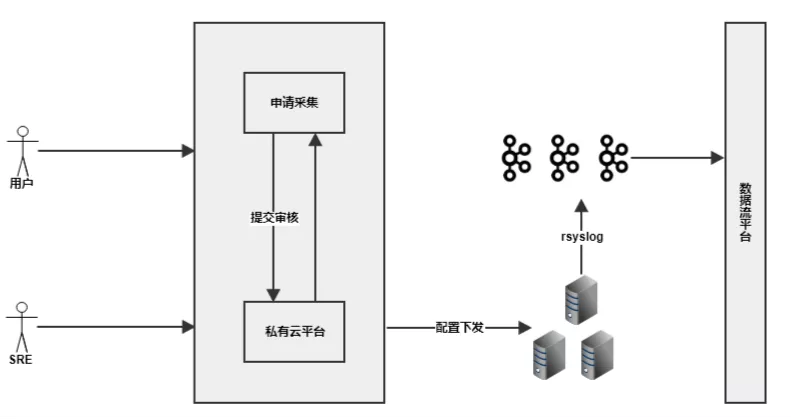
最终的数据流平台是 Kafka 集群。服务器上的日志这部分数据是怎么到达 Kafka 集群的呢?我们是通过一个私有云平台。业务方可以在私有云上提供项目名与文件路径,提交自己的采集申请,由运维人员审核之后,自动下发配置通过 rsyslog 将实时的日志上报到 topic 上,最终到数据流平台。
① 元数据化
对于数据流平台中的实时数据。我们会有一个初期的处理,对标准的数据格式比如 Json 数据、Tab 分隔,可以预先解析实时数据生成它的 Schema,如果后期进行实时计算用到 SQL,可以根据我们解析的元数据帮助用户自动的生成 DDL。节省了很多任务开发过程中繁琐的建表操作。
② 实时云端控制台
实时云端控制台其实是基于 Kafka 做的实时控制台消费。通常需要预览 Kafka 中的数据都是去客户端输入命令,在实际数据流的使用过程中,有很多用户有预览数据的需求,为了统一管理客户端我们把它迁移到了 web 端,可以通过 web 端实时消费 kafka 的数据,还可以做一些类似 grep 的简单过滤。
5. 数据通道
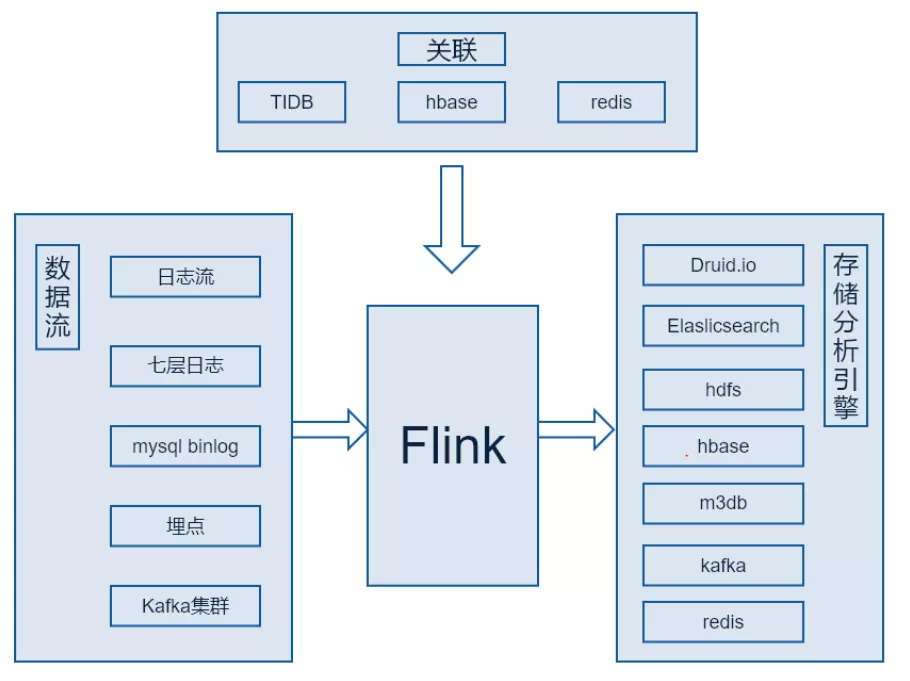
实时计算的能力其实可以把它总结成一个数据通道的能力。实时计算可能不会完全满足我们的实时分析的需求,比如通常的需求都是一个多维分析、即席查询的需求。最终我们的方案是通过 Flink 这个引擎去帮我们做这个数据处理与预计算,最终都会落到一个对应存储分析引擎。
存储分析引擎根据业务需求去选择合适的对应输出。包括实时 OLAP 引擎 druid.io、搜索与分析引擎 Elastic Search、时序数据库 M3db 等等。
6. 任务开发
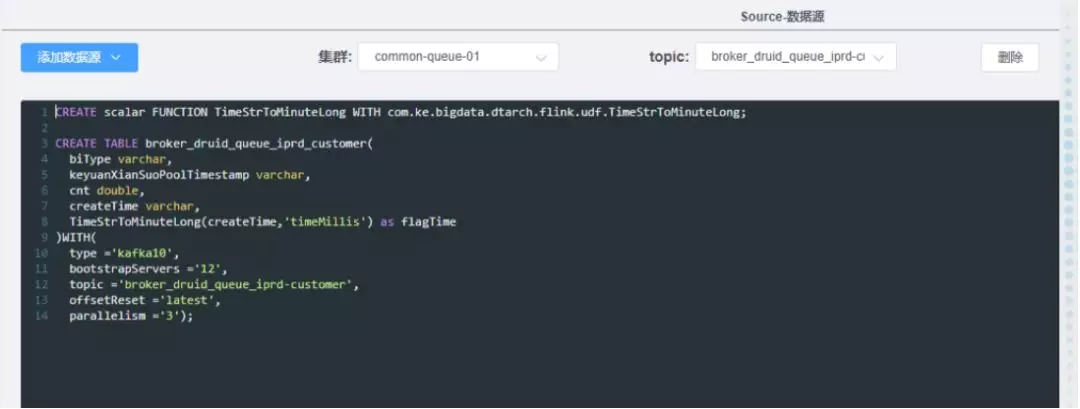
业务方或数据开发如何在平台上开发任务?有两部分,一个是通常的写代码打成 jar 包提交到平台上,平台帮它管理任务的流程。还有就是主要做的 SQL 的编辑环境,包括前边说到的元数据化在这里可以体现出来。我们把某个 topic 里的数据元数据化之后,这个 DDL 语句可以自动生成,包括将 UDF 关联上任务。
7. 任务管控
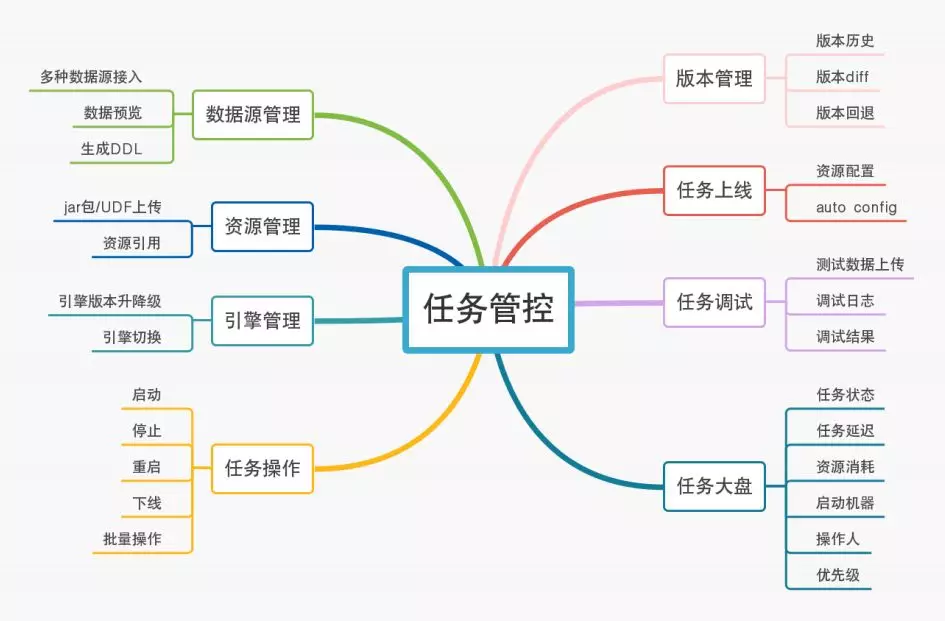
对于一个任务流程的管理主要包括上图的这些能力,我们主要支持 Spark2.3、Flink1.8 与 Flink1.9。新的任务优先用 Flink 解决,平台同时支持 Flink 的 per job、session 两种模式。session 模式用于小任务合并以合理利用集群资源,用户可以在平台完成实时任务的所有相关操作。
8. Flink SQL 生产实践

SQL 扩展:
在 Flink1.9 之前社区版对 SQL 的 DDL 没有支持,另外实际使用时,对维表关联、输入输出源会有一些定制需求。所以我们基于 Apache Calcite 扩展了 Flink SQL 的能力,定义了 DDL、实现了流与多种数据源维表的关联、UDF 注册等需求的研发。
关于维表的关联,我们使用 TiDB 作为线上 MySQL 的从库,通过关联 TiDB 实现与线上业务数据库的实时关联。对于 Hbase 的关联通过 Async IO 去异步读取 hbase 的数据,并用 LRU 策略去加载维表数据,并支持了 redis 的实时查询。
9. Flink 任务监控和调优
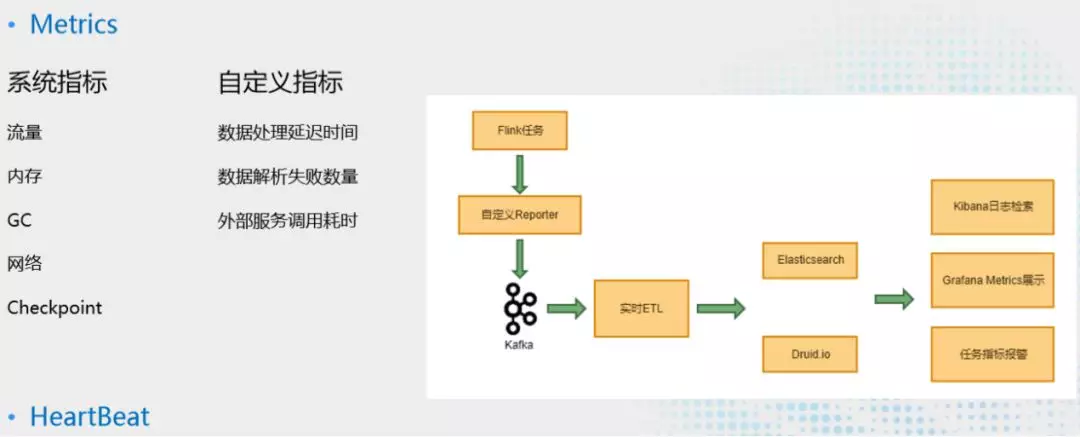
Flink 任务在集群中运行会产生各种指标,包括机器系统指标:Hostname、CPU、Memory、Network、IO,还有任务运行组件指标:JobManager、TaskManager、Job、Task、Operater等相关指标。这些 metrics 默认会在 Flink UI 中展示出来。除此之外 Flink 原生还支持了几种主流的第三方上报方式:JMXReporter、InfluxdbReporter 等等可以直接配置使用。另外还支持自定义 Report。
在 Flink 的 metrics 基础上,我们还根据业务场景自定义了数据处理实际延迟时间、数据解析失败量、外部服务调用耗时等指标。所有的指标通过自定义的 Reporter 上报到 Kafka,再通过一个实时的 ETL,把指标结构化后输出到 ES 和 Druid 里,按任务的维度在 Grafana 中分类展示,并提供明细的数据查询。根据这部分 metrics 数据,我们也会定义一些规则去监控任务的各种异常状态,做一些定制化的报警。
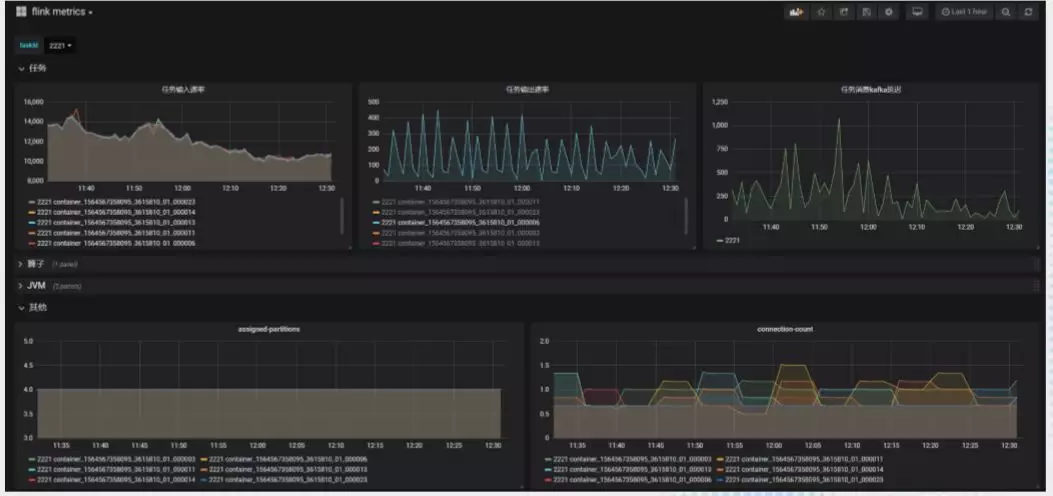
这个是收集上来一些指标的监控,包括任务的输入输出速率,算子,JVM,任务运行时的其它指标。
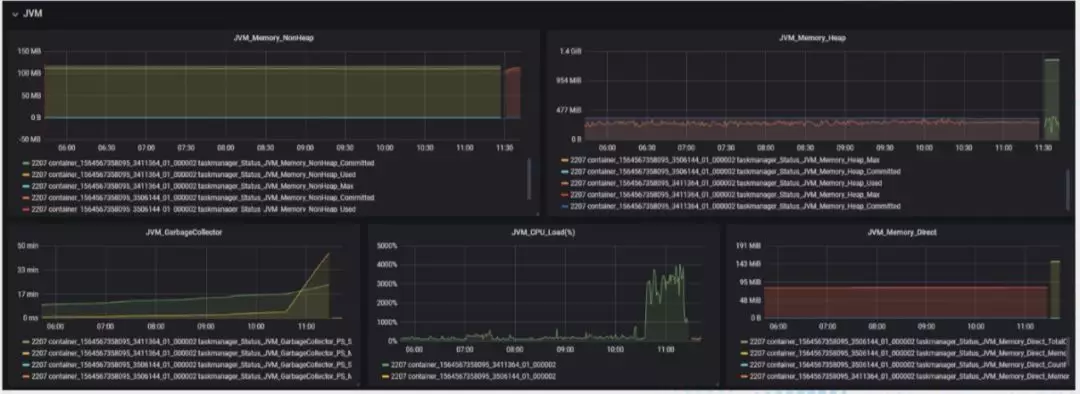
分析 Flink 任务的延迟,倾斜,或者失败的原因很多都是依靠这些指标,比如根据 JVM 的 metrics 情况对堆内存做出调整。
10. 应用场景-业务 BI 指标实时分析
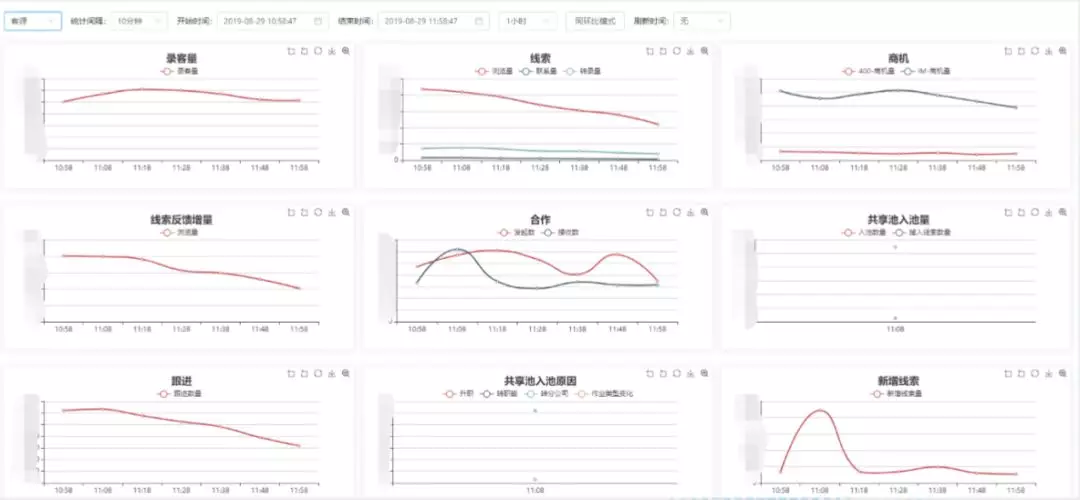
上图是流计算在业务指标实时分析上的应用场景。它是基于业务数据库 binlog 的实时分析,这些业务 binlog 能够反映出业务实时变化情况。如上图是其中客源的部分业务指标,通过流计算对 binlog 中对应业务表的 DML 操作的提取以及分析。可以实时掌握业务 BI 指标的变化趋势。
——实时分析监控平台**-FAST——**
实时计算除了满足业务的需求,还有一个非常通用的需求就是监控。我们内部的平台叫做 FAST 天眼平台。
1. 实时分析监控平台架构
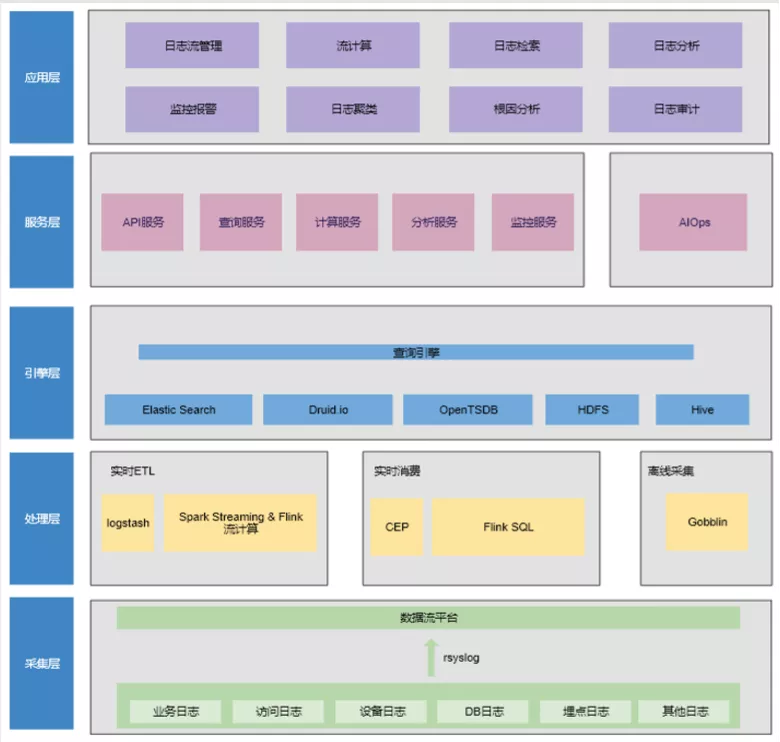
这个监控分析平台主要是分析日志。日志的种类包括业务的 log、Nginx 的 access log,还有一些 DB 的日志、中间件日志、网络设备等日志。这些日志通常通过 rsyslog 采集到 kafka 里,通过 Spark Streaming/Flink 实时消费。清洗计算后结构化的数据。会落到日志的的存储和分析引擎,在这一步也会用 gobblin 把 kafka 里的数据离线的备份到 hdfs。一是因为很多情况下实时不能保证数据的准确性。需要离线校准的时候需要一份 kafka 中的原始数据。二是可以满足日志长期存储后续用于审计。在服务层我们提供了一些基础服务,包括所有引擎对外提供的 API,查询,计算,分析,监控报警。依托这些清洗之后的数据,通过这些日志找出他们之间的关联关系,可以用来实践 AIOps。在应用方面,可以看到实时计算与日志结合具体能帮我们做哪些事。有日志的检索,日志聚类。比如日志一分钟报了一万条 Error,如果 RD 去排查问题不可能看完这一万条再找到问题,所以需要一些文本聚类。包括日志相关的分析。
2. 日志计算
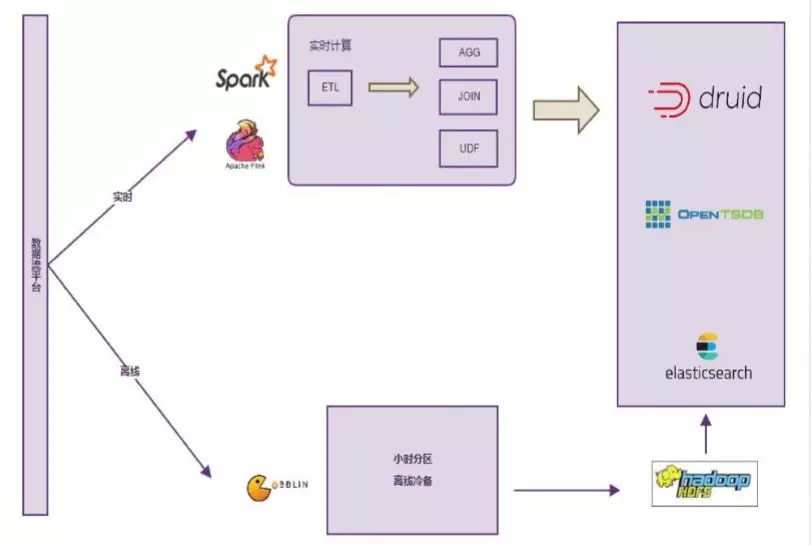
在日志的解析和计算方面我们提供了可视化的配置页面。可以通过正则、分隔符、json 的解析提取字段,由用户去解析自己的日志。这一部分计算引擎对用户是屏蔽的,因为对用户来说,只要配置规则即可,通过配置生成实时计算任务。对于规范化日志这些可以自动解析,如果是任意的非结构化日志就需要自己配置规则,然后用 Spark Streaming 或者是 Flink 去做 ETL,包括聚合,join 这些操作。离线的部分会每个小时把原始数据拉一份到 HDFS 冷备,在 hive 中用这些规则进行离线的 ETL。
3. 数据存储 - Elasticsearch 存储集群架构
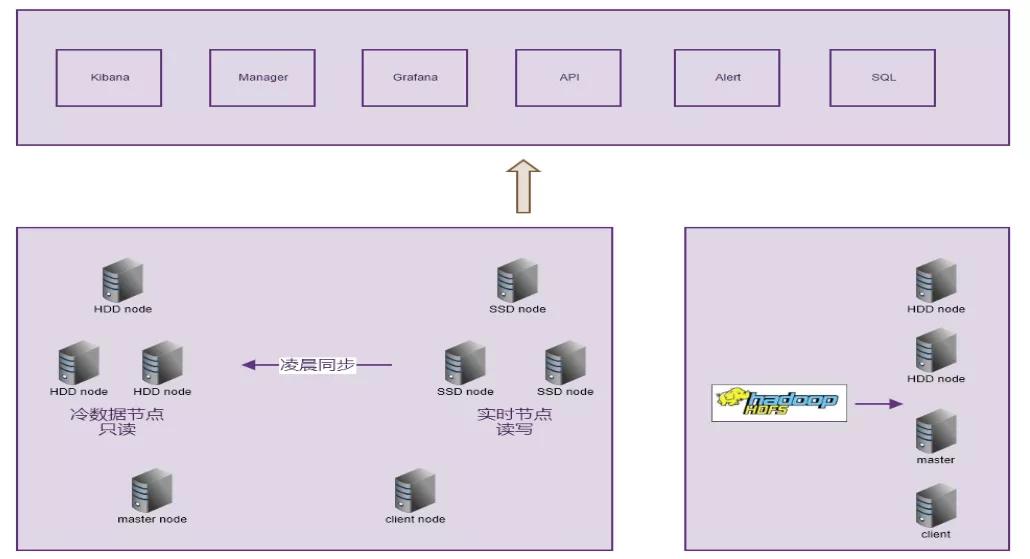
实时计算的流程最终把日志的明细数据存储到 ES 集群,最初我们的几套 ES 集群存储是全 nvme SSD 的。随着接入的服务越来越多,日志量越来越大。需要一个满足日志存储时间很长但成本不会明显增加的架构。具体的实现是通过对 ES 节点划分为 warm 与 hot 冷热两种节点。因为检索场景中,一般最近一两天的日志是查询频率比较高的,所以挂载大容量的 HDD 节点适合存储历史数据即查询频率较低且没有实时写入的索引。在凌晨业务低峰期把冷数据通过标签转到只读的冷数据节点。对于查询几个月之前的数据需求,这时需要之前冷备的那份 HDFS 上的数据,通过 hadoop-es 将他加载到 ES,基于 ES 集群上中的数据。我们也提供了检索 api 服务、下载服务,比如提供给 QA 通过脚本拉取日志进行版本比对的 diff 测试。
4. 数据存储 - Druid.io 集群架构
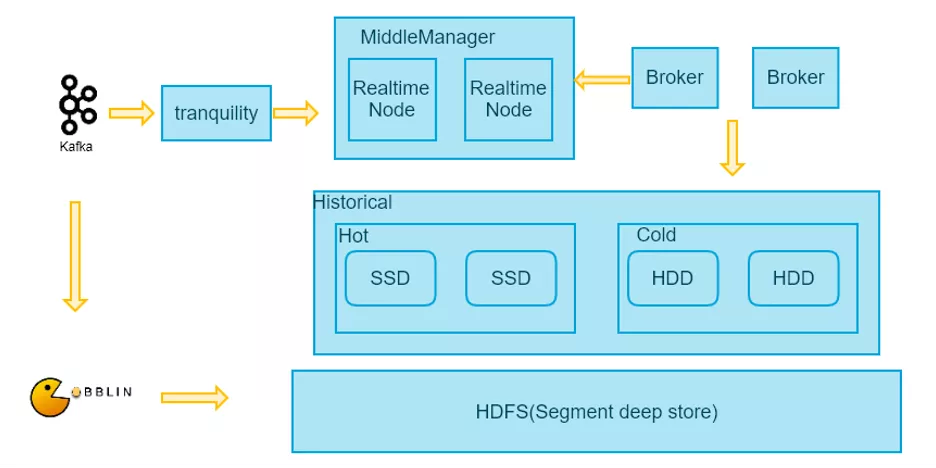
实时分析这方面现在用的是主要是 Druid.io。Druid 是一个实时 OLAP 的引擎。实时的将我们实时计算的结果经 Kafka,用 Tranquility 将数据写入 Druid 的 datasource。但因为 Druid 一般我们会设置一个时间窗口,如果有上层实时计算任务延迟,数据就可能会丢失,因此需要离线校准来保障数据准确性。一般用 MapReduce 将 hive 中离线结构化的数据重新索引到 Druid 对应的 datasource,覆盖实时写入的数据。Druid 在存储上也分为热数据的节点和冷数据的节点,hdfs 作为 deep store。
5. 异常检测
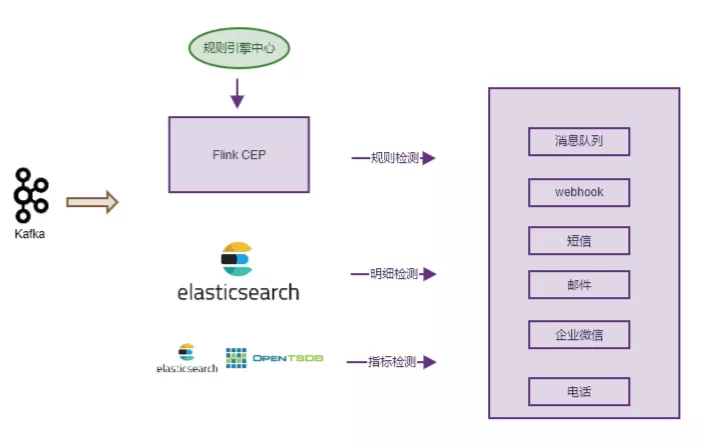
监控报警、异常检测是实时计算的主要应用点,我们自研的报警服务可以检测多种实时数据来源。覆盖明细类和指标类的异常检测,支持明细检测、指标聚合、同环比、流量抖动等等异常事件。可以根据业务需求灵活配置规则、订阅报警。Flink CEP 的能力我们也在监控场景引入进来应用在爬虫检测。实时检测到的异常事件会通过各种渠道通知订阅者:电话、企业微信、短信、邮件、callback 等。
6. 应用案例
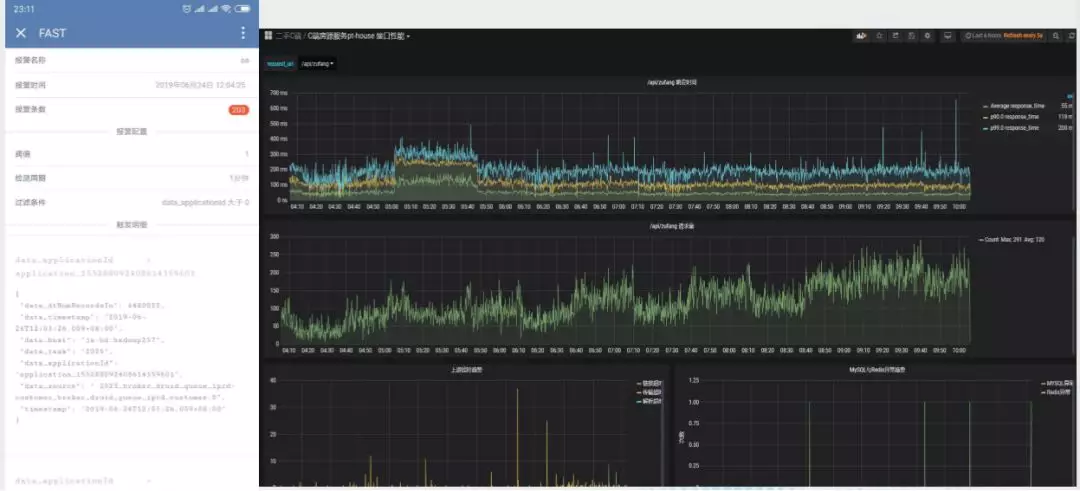
这个例子是 FAST 天眼平台在业务日志实时监控场景的一个实际案例,左边是业务方在企业微信里可以实时收到自己负责的项目线上的错误日志的推送,右边是实时计算的结果存到时序数据库中,用户可以根据自己的业务场景在 Grafana 中配各种 Dashboard。比如实时的流量、接口的瓶颈,包括一些 QPS,异常看板的展示。整个过程可以由平台用户自助完成。
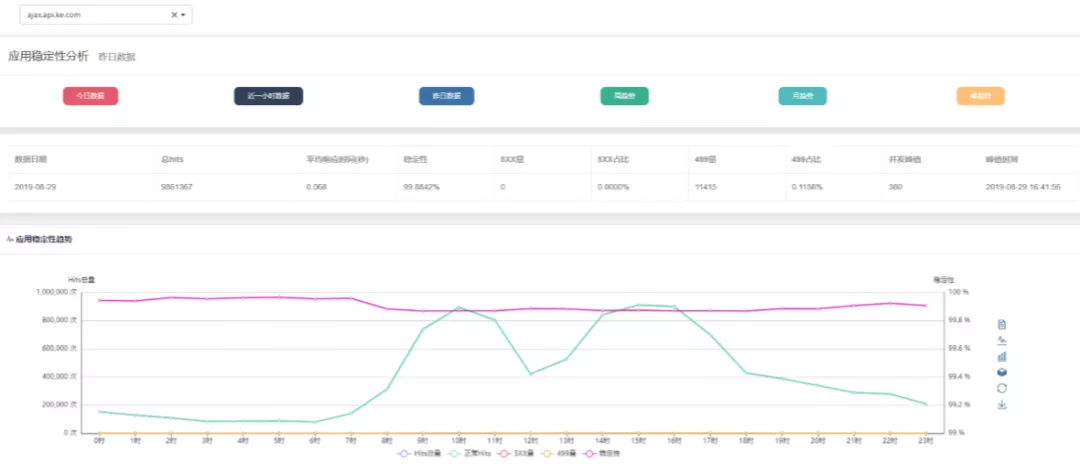
这个是我们全网服务稳定性分析能力,图中是某一个线上域名的分析报告的一部分。数据来源是公司的7层负载均衡的访问日志。可以用它来做整个公司下所有服务稳定性的分析。展示正常流量、异常流量、SLA 值、请求路径响应时间趋势、QPS 趋势等。可以由这类数据产生实时 QPS 排名,实时稳定性红黑榜等应用。通过实时+离线的结合。可以支持任意时间范围的服务稳定性分析。
——后续规划——
-
完善 SQL 解析引擎。持续丰富 SQL 解析能力,建设 SQL 调试能力、提升开发效率,降低流计算的使用门槛。
-
动态的资源管理。目前在资源分配场景,有些任务不需要那么多资源或者优化代码可以提升的计算效率,但是用户会把资源分配的很多。因此需要我们在这个平台能监测任务的资源实际利用率,进行动态的资源调整,合理利用资源。
-
实时任务问题诊断。希望通过收集和分析实时计算任务中历史常见的错误,后续在任务出现问题或报错时,平台能够给出建议解决方案。
-
智能监
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%AE%9E%E6%97%B6%E8%AE%A1%E7%AE%97%E5%BC%95%E6%93%8E%E5%9C%A8%E8%B4%9D%E5%A3%B3%E7%9A%84%E5%BA%94%E7%94%A8%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


