如何扩充知识图谱中的同义词
来源: 丁香园大数据 2019-12-02
前言
在之前的文章中,我们介绍了数据驱动的上下位三元组抽取、关系抽取、实体属性值抽取、名词短语抽取的算法思路。这些工作的目的都是为了使实体词在知识库中更加丰满,能够更好地为语义搜索推荐、智能问答等场景做支撑。以上这些工作多以考虑挖掘更多的知识数据,而我们还未讨论如何将新老知识合并加以整合,比如 “拉肚子” 与 “腹泻” 实则同一意义,但是因为在字面上差距较大,在各抽取任务中不容易合并,会被当做两个不同的实体词入库。进而在很多涉及到 实体检索、 Query 扩展 等任务的工作中,三元组的召回都会受到影响。本文主要讨论一下 同义词挖掘 工作的一般思路以及学术界现有的工作进展。
同义词从哪里来?
上文提到的 “拉肚子” 和 “腹泻” 两个词,从汉字、拼音、字形上都存在巨大差异,一般很难使用规则的手段的做关联,更常见的方式是首先离线准备好这批数据。比如在搜索场景中,提前准备好一份 同义词映射表,当输入 Query 遇到 “拉肚子”、 闹肚子 等都向 **“腹泻”**对齐。准备这份同义词表的确是个比较头疼的事情,词的语义、句子的语义本身就是在文字之上的抽象,人能够从少量文字中推理出同义词的信息,因为我们有不断获取的知识做支撑,但是计算机很困难(在知识图谱还未完善时)。因此, 同义词表 常常需要业务人员手工收集,这种方式准确率高,但是因为自然语言的灵活性,对一些长尾数据很难保障召回率,后期会变成遇到一个 case,向词表里补一个词的情况。
既然人工枚举同义词的能力有限,从哪些数据里可以找到现成的同义词呢?这里分为两个思路,首先是从现成的 结构化数据 里寻找,最简单的可以找现有的知识图谱数据,比如 OpenKG ( http://openkg.cn/) 、OwnThink ( https://www.ownthink.com/) 里就可以找到不同领域下的开放知识图谱数据

这些数据集常有设置 别名 一类的字段:
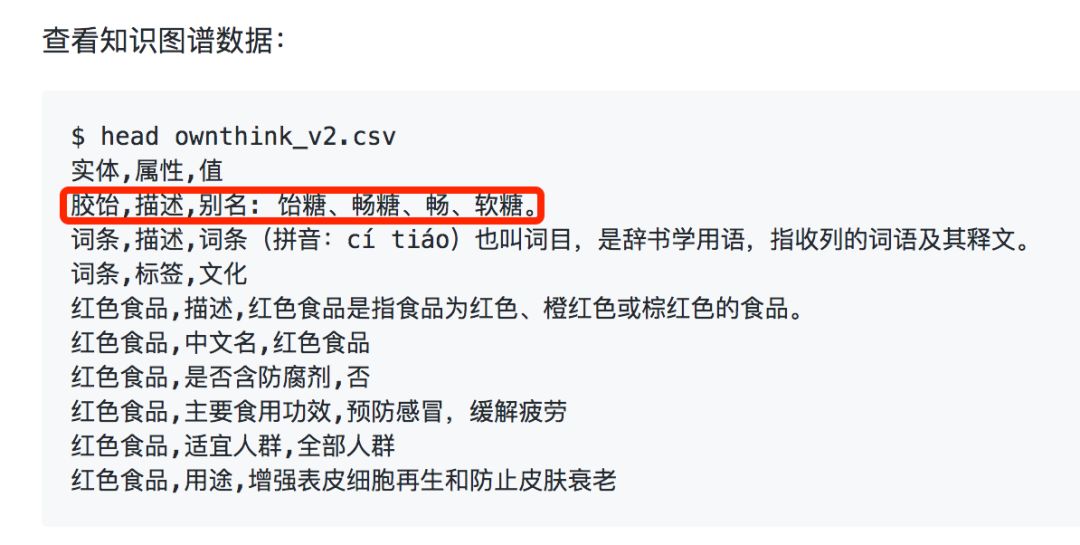
除此之外,另一种结构化数据稍微麻烦一些,在百度百科、维基百科页面中也很容易找到别名信息:
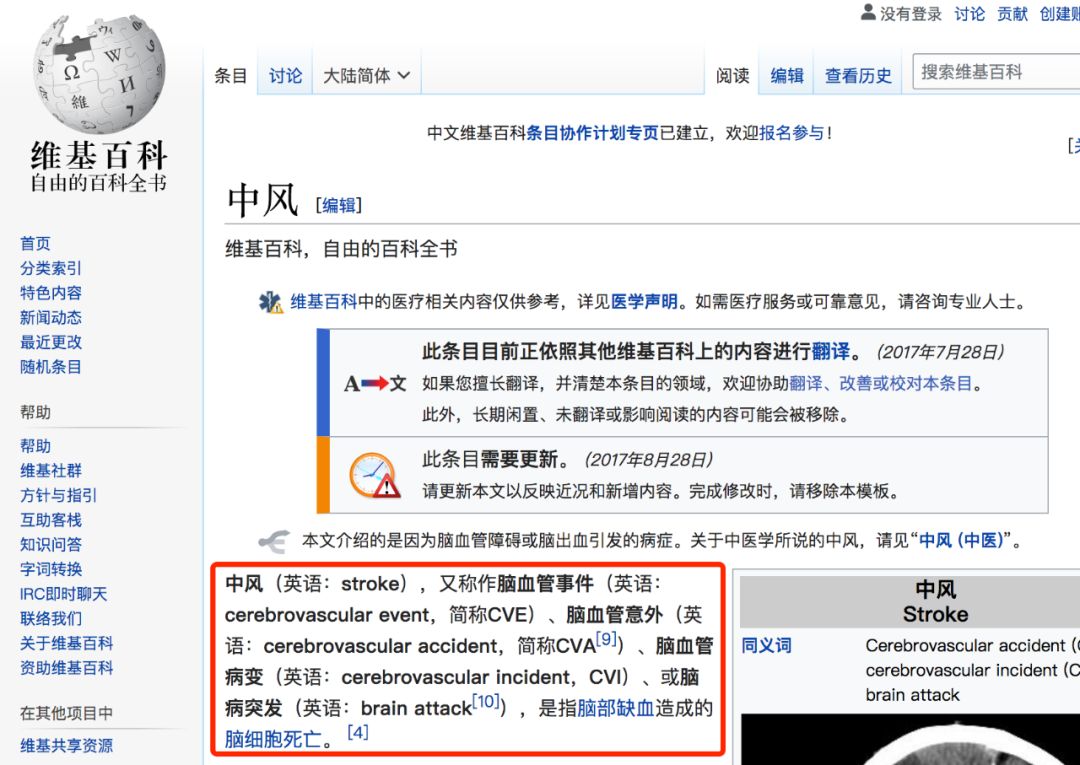
这部分数据虽然需要做一些清洗,但是毕竟是经过专家整理,正确率可以保障。
如果现成数据集中无法满足,另一种思路只能从 非结构化数据 中获取。这一途径的关键点就在于 上下文 的使用,观察下面这个例子:
拉肚子 最常见的原因为 肠道感染,可能是 病毒、 细菌 或 寄生虫感染
回忆我们是如何思考 拉肚子 这个词的同义词的,假设这个词对我们来说是陌生的,一个很自然的方式是去看句子中对这个词的描述,以及其他的实体词的类型,发现与消化内科相关知识接近,也许它与 腹泻 大可能有相近的意思,交给计算机做的话无非也是遵循相同的逻辑方法。
OK,那么从数据层面来说,使用 非结构化数据 获取同义词的方案,一个关键点就在于如何建立 平行语料,通俗的讲就是两个文本段落在描述同一个事物,这个过程说起来容易,但是其实如果对语料数据不加梳理,最后收集的文本数据中很难有好的覆盖度。因此,我们应该“主动出击”去寻找更有可能产生平行语料的场景,比如在 丁香医生 产品中健康问答场景
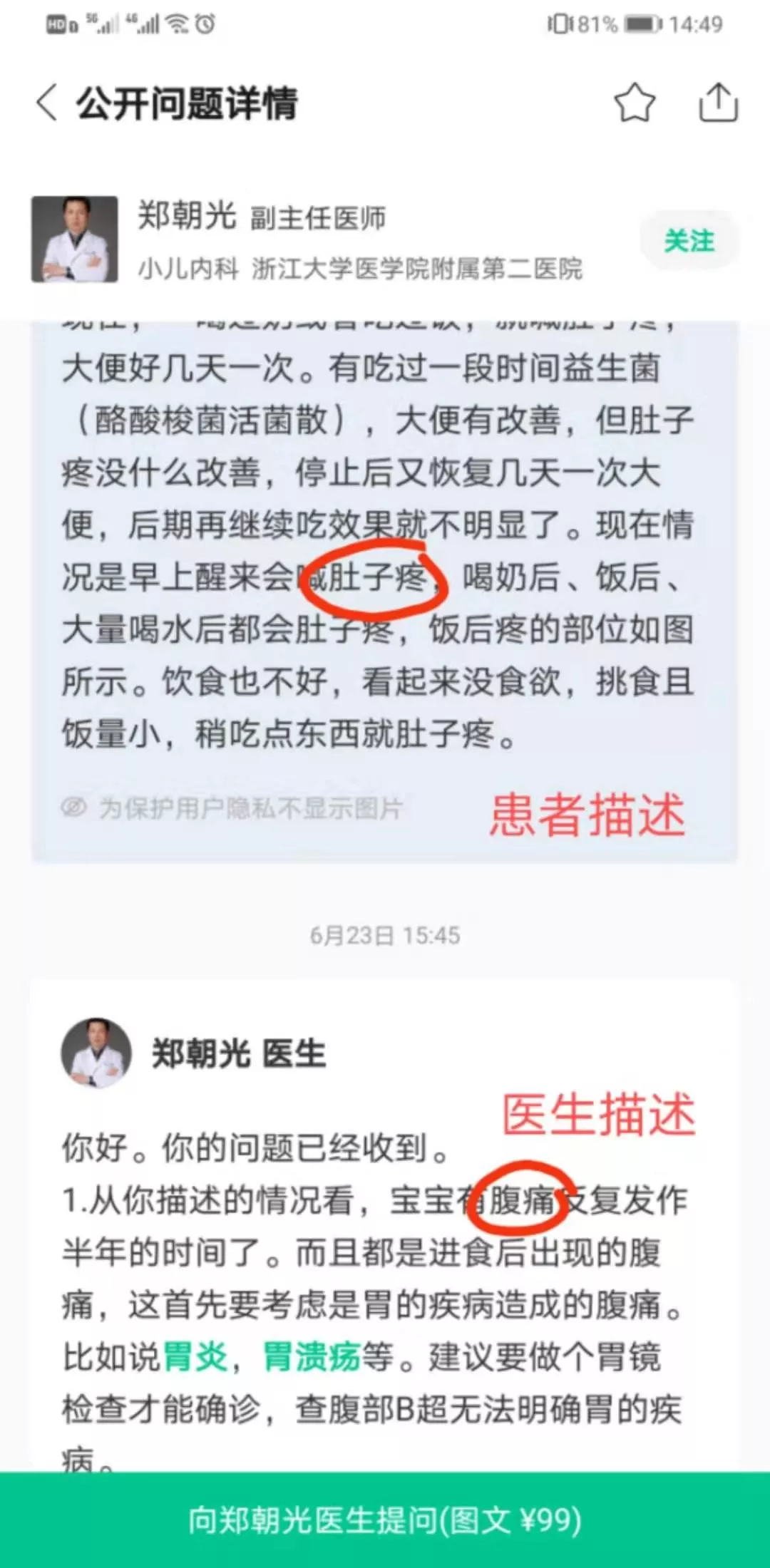
其中有大量的医生与患者的对话数据,他们在表述上有所差异,但是因为在这个业务场景内,讨论的核心是固定的,因此可以天然地形成平行语料。
如果目前手头没有类似的场景,而又想构造尽量平行的语料数据的话,一个比较 tricky 的方案是借助现有的搜索引擎,比如我们用百度搜索**“闹肚子”**这个关键词:
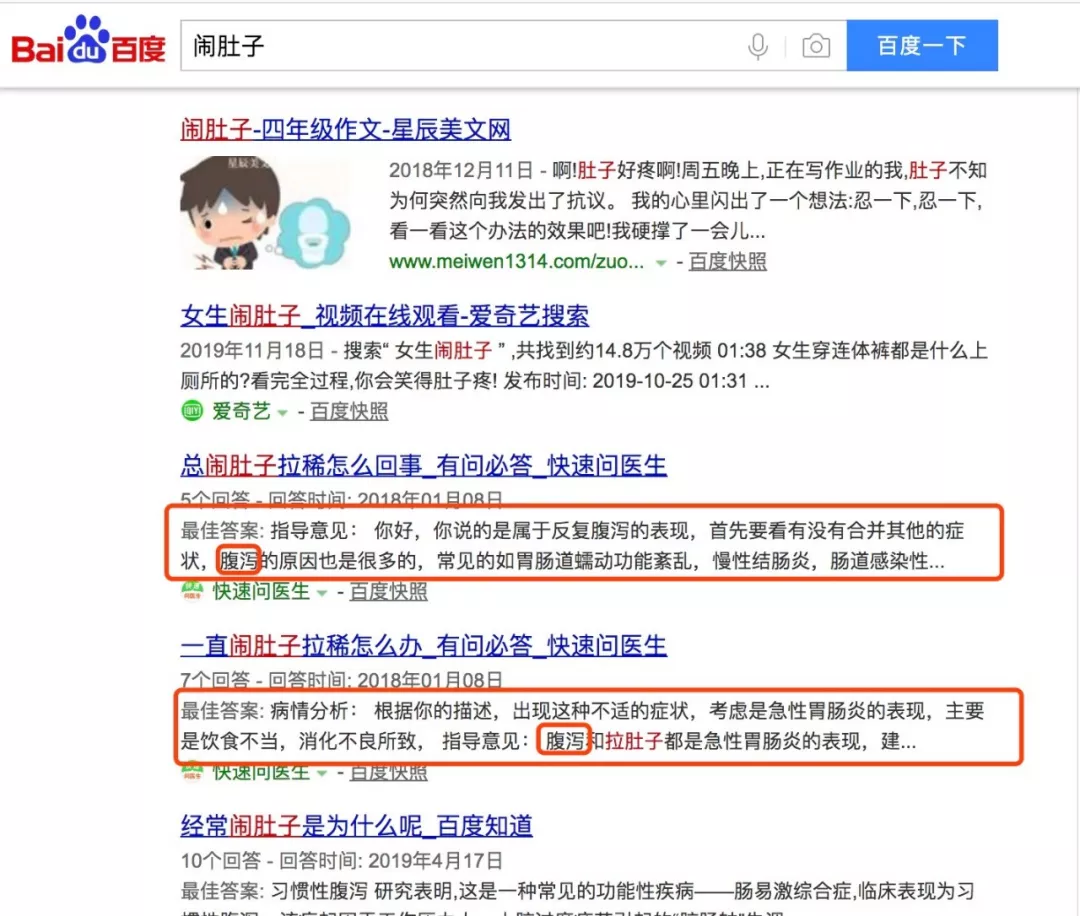
现有的搜索引擎大多也集成了同义词映射、扩展查询等功能,虽然爬取后数据的清洗也比较费劲,但是在数据不足的情况下也不失为一种策略。
常见的同义词挖掘思路
本文着重讨论一下在 非结构化数据集 上,常见的挖掘思路有哪些。一般来说,这一类工作分为以下几个步骤:
1) 从文本中提取 mention 词,简单的做法可以直接使用分词,选取一些特定分词结果做同义词挖掘。如果需要考虑语料中可能出现的新词或者不同语言表述,则需要配合 Pattern挖掘、 NER 或 名词短语抽取 等方式获取候选词。
2) 准备好已有的同义词表作为种子数据
3) 获取所有种子词和候选词的特征,通常该任务的特征会从两个角度考虑,分别是 local context 和 global context,通俗的讲就是局部特征和全局特征,前者着重于词本身,常见字级别特征、词级别特征等;后者则是考虑目标词在数据集中的分布特征或者词所在句子、段落的语义特征
4) 根据各自实际工作中数据集的特点,已有的 paper 从不同的角度进行建模,比如使用分布特征与 pattern 特征交叉验证,或是只考虑改进词本身的预训练向量,或是重点考虑候选词与目标同义词集合的分布差异。此处在下一节具体展开讨论。
如何建模
本节我们搜罗了目前学术界的几篇同义词挖掘的工作,做了如下简单总结:
Pattern 的使用
提到从文本数据中抽取数据,一个很朴素的想法就是使用 模板,这点我们在之前的文章知识图谱构建综述中也讨论过。其实 同义词 也算是一种特殊的三元组关系,使用 Pattern 抽取的方式在正确率上可以保障,但是它的主要问题在于模板的数量以及 语义漂移。另外,因为同义词这种关系的特殊性,使用模板抽取的方式对语料数据也有额外的要求,比如我们使用特定的触发词:

或者特定的抽取模板:
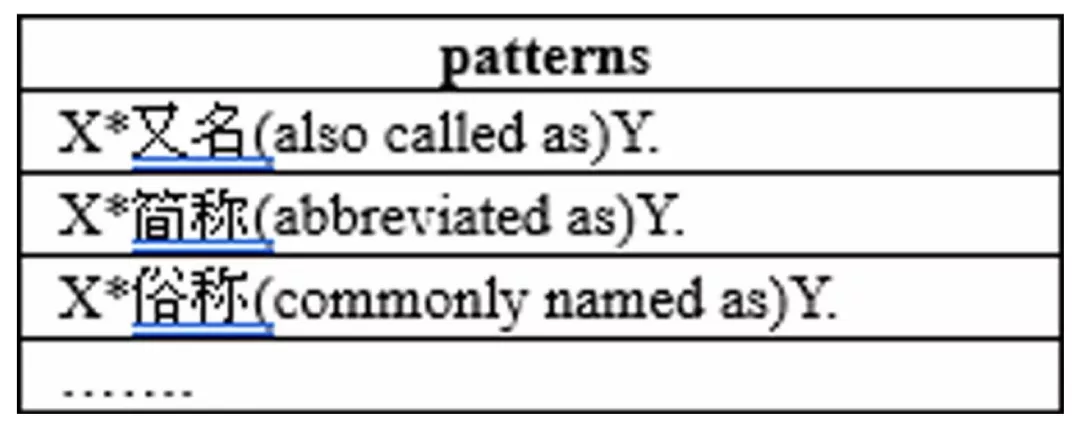
这些句式只会在 百科类 或 词条解释类 的文本中高频出现,在其他类型文本中并不容易找到如此工整的表述。
虽然有缺陷,但是 pattern 还是有可取之处,常见的增强方式的设计部分 种子pattern 后,使用 bootstrapping 的方式挖掘更多的 pattern。随后 pattern 抽取的数据不可直接使用,而是作为产生新候选词的途径。
《Multi-Distribution Characteristics Based Chinese Entity Synonym Extraction from The Web》
这篇工作的主要内容是从利用百科类数据中的结构化、非结构化文本中获取同义词。整体流程如下:
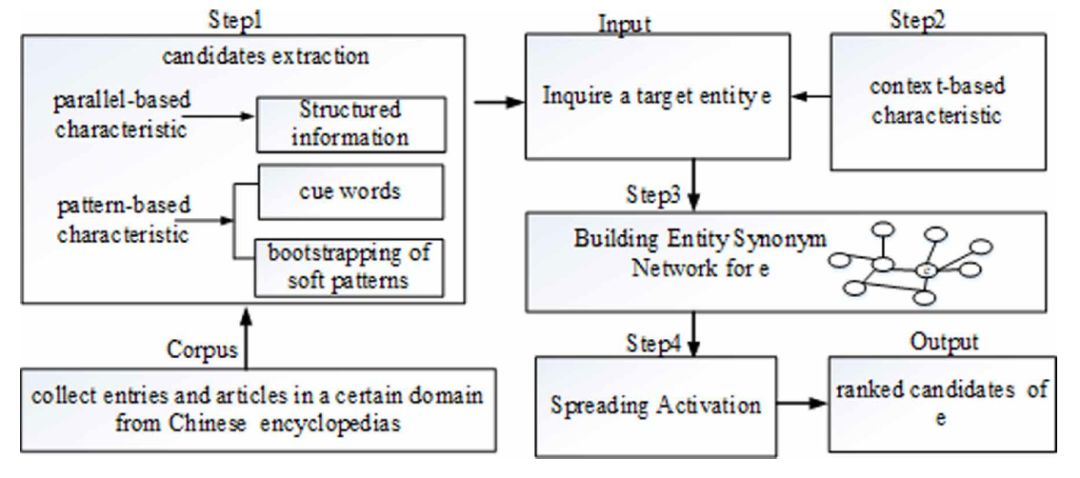
作者提到了使用 bootstrapping 的方式产生更多的 Soft pattern,利用所有的模板去产生更多的同义词候选。值得注意的是从同义词候选集进行筛选是这一类工作的核心,本文在获得同义词候选集后,会继续抽取每一组同义词的上下文特征,利用这些特征的相似度构建一个相似图结构:
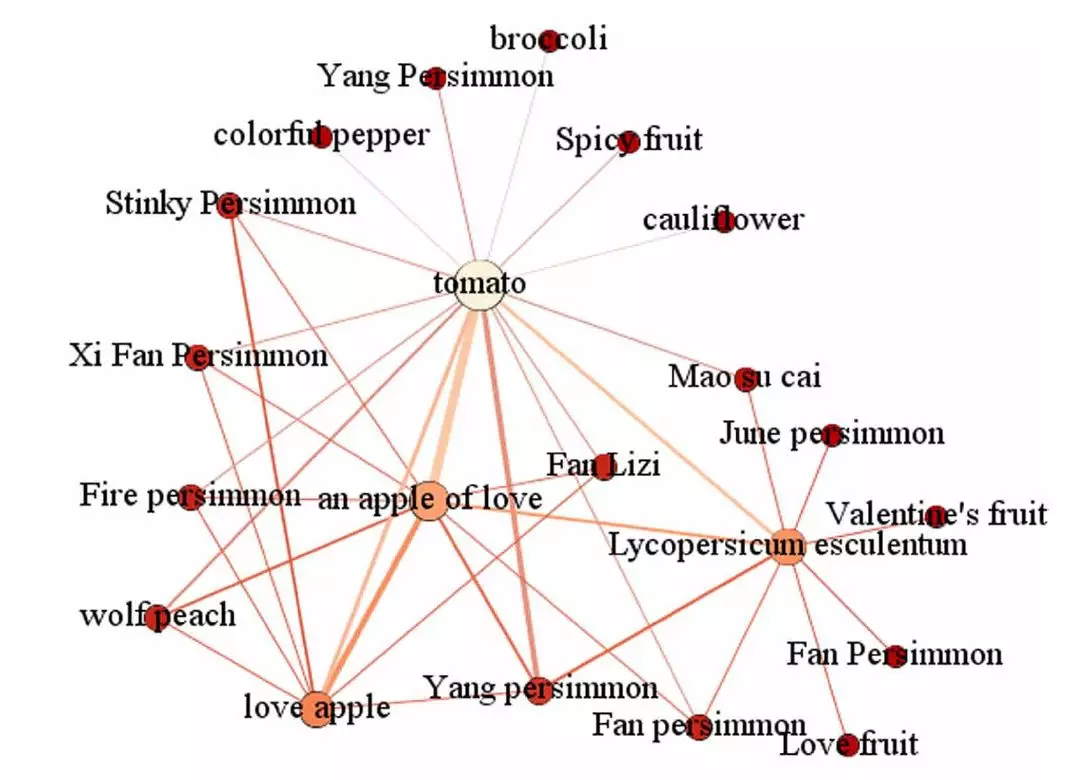
在这个图的基础上,作者设计了相应的 Spreading Activation 算法:

在扩散激活模型得到的同义词对还会再使用一个 重排模型 才会得到最终的结果。
更好的预训练
除了使用 模板,另一个很自然的想法就是使用 词向量 了,在不少讲解 Query扩展 的技术文章中,都会简要地提到使用 word2vec 获取当前查询词相近的词,从而获得更多的召回。这个方式的确简单有效,这里我们把它聊得更细致一点。
《Hierarchical Multi-Task Word Embedding Learning for Synonym Prediction》
这篇工作的重点在于如何为同义词挖掘这个任务获得更好的预训练词向量。熟悉 Skip-gram 等词向量训练方法的同学应该都知道,这种方式的本事其实是利用一个有限长度的滑动窗口去获得某个词的表示,这是一个反向映射的过程,而这个过程本身与语义无关。当数据量足够大的时候,我们可能恰巧得到了一个词的同义词,但是更多的时候,我们只能说两个词在语义上比较“相关”,比如**“感冒” 和“发烧”**在医疗领域高频共现,简单的词向量求相似其实难以发现它们的区别。本文就是在 Skip-gram 的基础上加以改进,以试图加入更多语义相关的信息:
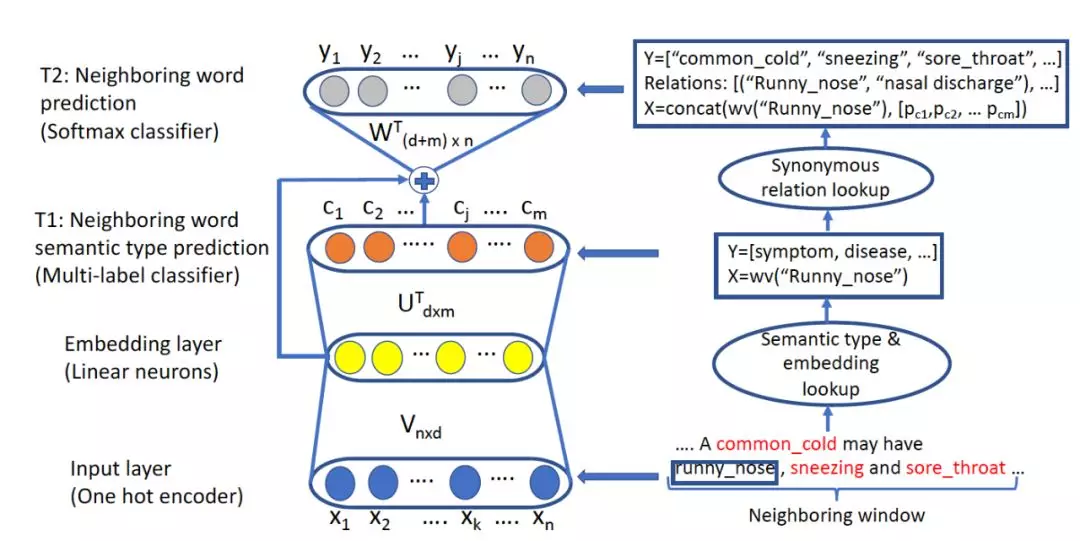
作者把原始的 Skip-gram 模型修改成 multi-task 的两项任务,一项用于预测目标词所在句子中的各个实体类型,另一项用于词本身的预测,如此加入了实体的语义信息,在作者的测试集中,模型可以显著提高词向量之间的语义相似性。
《SurfCon: Synonym Discovery on Privacy-Aware Clinical Data》
除了加入语义特征,另一个增强预训练的方式是在数据本身做更多的挖掘
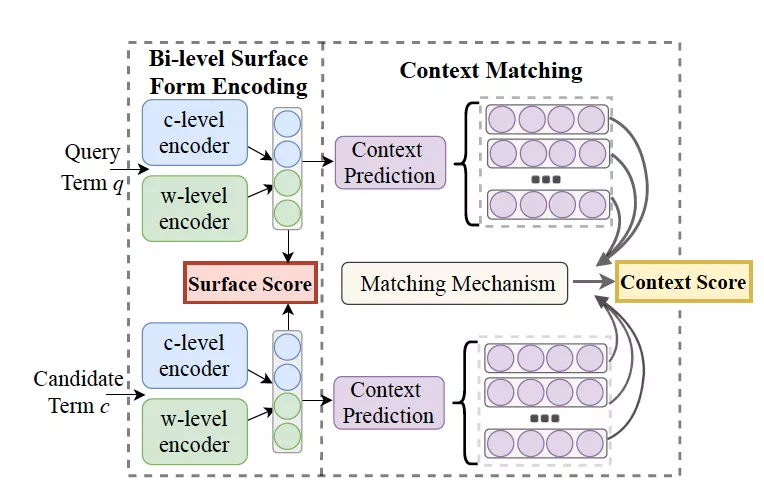
本文由于医疗电子病历的特殊的应用场景,更加关注 Query 短文本中的实体词。因此作者拓展了字级别、词级别,以及医疗实体在电子病历中的共现特征来增强词向量的预训练过程。同样,作者也会在最后使用一个排序模块来增强整个系统的健壮性。
善用知识库中的种子数据
除了上文提到的 pattern、上下文特征、实体类型语义特征,知识图谱中已有的同义词对数据,也是值得思考使用的数据源。
《Automatic Synonym Discovery with Knowledge Bases》
本文是韩嘉炜老师团队在 KDD2017 年发表的一篇工作:
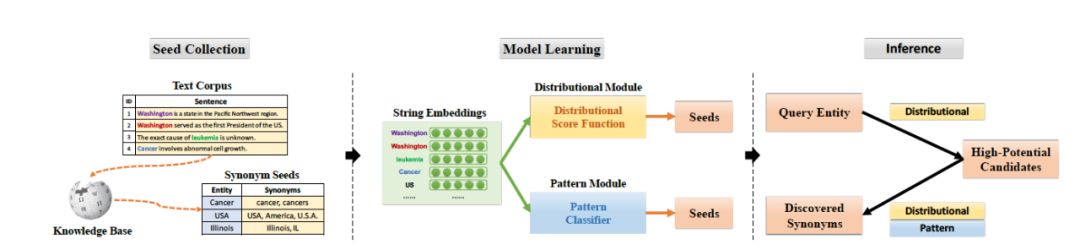
与前面提到的工作相似,文章中同样也是对词级别和句子级别特征完成了预训练向量,对于 pattern 也使用了 bootstrapping 的方法做扩充。不同的是在 Model Learning 的阶段里,作者收集了分布式方法和模板方法中产生的 Seeds 数据,这些种子同义词对数据会被进而训练成二分类的分类器,从而在进一步对候选词进行约束,提高准确率。
《Mining Entity Synonyms with Efficient Neural Set Generation》
同样是韩嘉炜老师团队的工作,发表在 AAAI2019 的同义词挖掘工作:
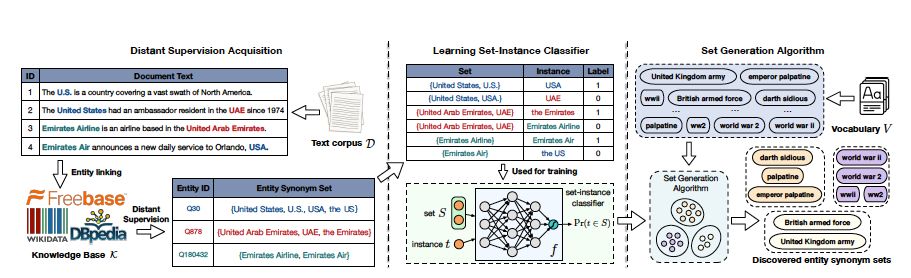
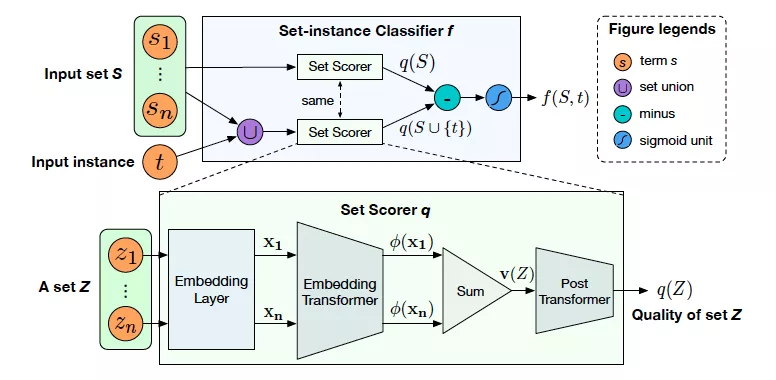
这篇工作进一步增强了对知识图谱中已有同义词数据集的利用。文章中提到了 entity synonym set 的概念,在整个流程中,作者意在利用库中众多的同义词簇的整体分布,来评估实体词是否属于某一同义词簇。文章的亮点在于 集合 Set 的表示学习,以及新实体进入 Set 的判定方法。
总结
综上所述,在实际工业场景的工作中,同义词挖掘工作应该先从数据源层面开始,寻找现有可以利用的结构化数据加以清洗,这可能是�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%A6%82%E4%BD%95%E6%89%A9%E5%85%85%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E4%B8%AD%E7%9A%84%E5%90%8C%E4%B9%89%E8%AF%8D/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


