如何实现一个搜索自动补全器
葛霖霖
导语 | 自动补全功能对于使用移动设备的用户来说很友好,用户可以很方便的在难以键入的小屏幕上完成搜索,并能节省用户大量的时间。根据 Google 官方报告,自动补全功能可以减少大约 25% 的打字,累积起来预计每天可以节省 200 多年的打字时间。本文将介绍如何实现一个自动补全器,希望与大家一同交流。文章作者:葛霖霖,腾讯运营开发工程师。
一、自动补全
1. 什么是自动补全
自动补全的功能其实很常用,如下图所示:

搜索引擎根据我们输入的关键字进行一些提示,这样用户只需要输入部分内容就可以进行选择。
2. 几种常用的自动补全方式
Google 官方目前并没有公开搜索自动补全的算法实现,但是业界在这方面都有自己的实现。
以下图为例,我们可以看下业界是如何做的:

淘宝、京东、拼多多、百度都有做自动补全器,这里我们可以看到,基本上所有的自动补全器都支持 前缀匹配。那么前缀匹配可以如何实现呢?
常用的实现方式可以列成三种:
- MySQL实现;
- Redis实现;
- Elasticsearch实现。
下文将分别介绍这三种实现方式。
二、MySQL实现
MySQL 的实现方式主要是利用 MySQL LIKE 语句来实现。比如:
SELECT * FROM table WHERE keyword LIKE "ssss%" LIMIT 10
使用 MySQL 实现自动补全器,实现简单,但数据量不宜过大。数据量大时,性能较差,并且在做热频词的时候,根据热度查询需要额外处理。
三、Redis实现
使用 Redis 实现时,我们可以利用有序集合,让 score 都为 0,这样就可以按元素值的字典序排序。然后我们可以根据排序号的字符,以添加后缀的方式,找到我们想要的内容。
如下图所示,这里是一个 zset 集合元素:
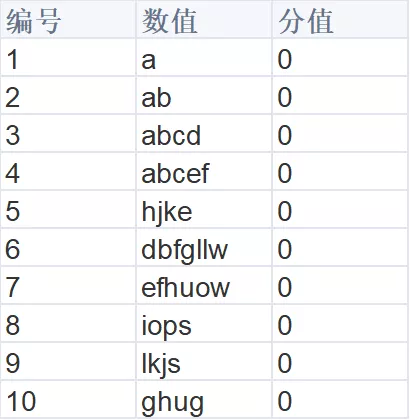
当所有的数值分值为 0 的时候,zset 会按照字典升序排列。如果我们需要查找上面的 a,就应该能找出 [ a, ab,abcd,abef ] 这四个元素,查找上面的 ab,就应该能找出 [ab,abcd,abef] 这三个元素。
假设我们要匹配 ab,如果我们能知道所有匹配 ab 的 member 在 zset 里的起始位置,那就好办了。那么怎么知道能匹配 ab 的字符都有什么,都在 zset 的什么位置呢?可以参照下面的做法:
- 首先,ASCII 码里小写字母 a 的前面是符号: `,字母 z 的后面是符号:{ ;
- 于是我们查找 ab 匹配的元素,插入 aa{ 和 ab{ ;
- 找到 aa{ 和 ab{ 的下标,通过 Zrange() 得出相关区间的内容;
- 如果是中文,可全部将字符转为 16 进制字符来进行存储,取出的时候再转码。
这里如果需要做热频词的话,可以重新创建一个 zset 专门用来存储每个词对应的热度。最后,将查询结合和这个记录热度的集合做交集,得出按热度排列的结果。
使用 Redis 实现,和 MySQL 一样,如果自动补全器还需要有纠错功能的话,就不太容易实现了。
四、ES实现
如何用 ES 来实现自动补全功能呢,答案就在于 Suggesters API 。ES 设计了 4 种类别的 Suggester 。其中 Completion Suggester 主要针对的场景就是自动补全,它支持按给定的热度排序。
因为自动补全的请求对后端响应速度要求比较苛刻,因此它采用了与其他 Suggester 不同的数据结构,索引并非通过倒排来完成,而是将 analyze 过的数据编码成 FST 和索引一起存放。
对于一个 open 状态的索引,FST 会被 ES 整个装载到内存里的,进行前缀查找�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%A6%82%E4%BD%95%E5%AE%9E%E7%8E%B0%E4%B8%80%E4%B8%AA%E6%90%9C%E7%B4%A2%E8%87%AA%E5%8A%A8%E8%A1%A5%E5%85%A8%E5%99%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


