如何基于生成在线机器学习的样本
文章作者:曹富强@微博
内容来源:Flink中文社区
导读: 在线机器学习与离线相比,在模型更新的时效性,模型的迭代周期,业务实验效果等方面有更好的表现。所以将机器学习从离线迁移到在线已经成为提升业务指标的一个有效的手段。在线机器学习中,样本是关键的一环。本文将给大家详细的介绍微博是如何用 Flink 来实现在线样本生成的。
为何选择 Flink 来做在线的样本生成?
在线样本生成对样本的时效性和准确性都有极高的要求。同样对作业的稳定性及是否容灾也都有严格的指标要求。基于这个前提,我们对目前较为流行的几种实时计算框架(Storm 0.10, Spark 2.11, Flink 1.10)进行了分析比较,结论如下:
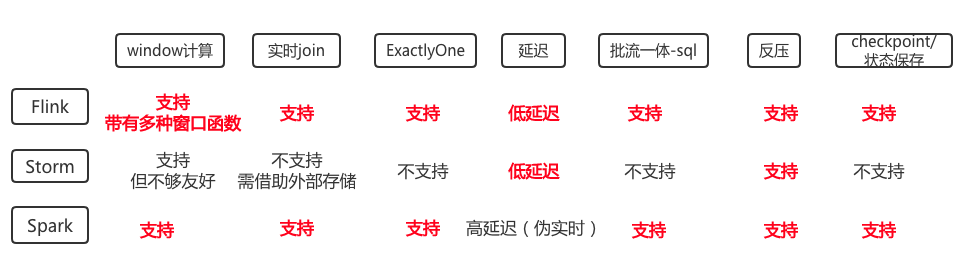
因此,我们决定使用 Flink 来作为在线样本生成的实时流计算框架。
如何实现?
在线样本生成,简单描述一个业务场景:对用户的曝光数据和点击数据实时的做关联,关联后将数据输出到 Kafka 中,给下游的在线训练作业用。
首先我们要确定两个数据流关联的时间窗口。这一步一般建议先离线对两个数据流的日志做关联,通过离线的方式对两份数据在不同的时间范围内做 join,来判断在线需要的时间窗口。比如业务接受的最低关联比例是 85%,并且通过离线测试确认 20 分钟内两个数据流可以关联 85%的数据,那么就可以采用 20 分钟作为时间窗口。这里的关联比例和窗口时间实际上是在准确性和实时性之间的一个 trade-off。
确定时间窗口后,我们并没有使用 Flink 的 time window 来实现多个数据流的 join,而是选择采用 union + timer 方式来实现。这里主要考虑两点:第一、Flink 自带的 join 操作不支持多个数据流。第二、使用 timer+state 来实现,自定义程度更高,限制更少,也更方便。
接下来,我们把样本生成过程细分为:
① 输入数据流
一般我们的数据源包括 Kafka,Trigger,MQ 等。Flink 需要从数据源中实时的读取日志。
② 输入数据流的格式化和过滤
- 读取日志后,对数据做格式化,并且过滤掉不需要的字段和数据。
- 指定样本 join 的 key。例如:用户 id 和 内容 id 作 key。
- 输出的数据格式一般为 tuple2(K,V),K:参与 join 的 key。V:样本用到的字段。
③ 输入数据流的 union
- 使用 Flink 的 union 操作,将多个输入流叠加到一起,形成一个 DataStream。
- 为每个输入流指定一个可以区分的别名或者增加一个可以区分的字段。
④ 输入数据流的聚合:keyby 操作
- 对 join 的 key 做 keyby 操作。接上例,表示按照用户 id 和内容 id 对多个数据流做 join。
- 如果 key 存在数据倾斜的情况,建议对 key 加随机数后先聚合,去掉随机数后再次聚合。
⑤ 数据存储 state + timer
- 定义一个Value State。
- keyby后的process方法中,我们会重写processElement方法,在processElement方法中判断,如果value state为空,则new 一个新的state,并将数据写到value state中,并且为这条数据注册一个timer(timer会由Flink按key+timestamp自动去重),另外此处我们使用的是ProcessingTime(表示onTimer()在系统时间戳达到Timer设定的时间戳时触发)。如果不为空则按照拼接的策略,更新已经存在的结果。比如:时间窗口内 用户id1,内容id1的第一条日志数据没有点击行为,则这个字段为0,第二条点击数据进入后,将这个字段更新为1。当然除了更新操作,还有计数、累加、均值等各种操作。如何在process里区分数据是来自曝光还是点击呢,使用上面步骤③定义的别名。
- 重写onTimer方法,在onTimer方法中主要是定义定时器触发时执行的逻辑:从value state里获取到存入的数据,并将数据输出。然后执行state.clear。
- 样本从窗口输出的条件有2个:第一,timer到期。第二,业务需要的样本都拼接上了。
此处参考伪代码:
public class StateSampleFunction extends KeyedProcessFunction<String, Tuple2, ReturnSample> {
/**
* 这个状态是通过过程函数来维护,使用ValueState
*/
private ValueState state;
private Long timer = null;
public StateSampleFunction (String time){
timer = Long.valueOf(time);
}
@Override
public void open(Configuration parameters) throws Exception {
// 获取state
state = getRuntimeContext().getState(new ValueStateDescriptor<>("state", TypeInformation.of(new TypeHint< ReturnSample >() {})));
}
@Override
public void processElement(Tuple2value, Context context, Collector< ReturnSample > collector) throws Exception {
if (value.f0 == null){
return;
}
Object sampleValue = value.f1;
Long time = context.timerService().currentProcessingTime();
ReturnSample returnSample = state.value();
if (returnSample == null) {
returnSample = new ReturnSample();
returnSample.setKey(value.f0);
returnSample.setTime(time);
context.timerService().registerProcessingTimeTimer(time +timer);
}
// 更新点击数据到state里
if (sampleValue instanceof ClickLog){
ClickLog clickLog = (ClickLog)values;
returnSample =(ReturnSample) clickLog.setSample(returnSample);
}
state.update(returnSample);
}
/**
* @param timestamp
* @param ctx
* @param out
* @throws Exception
*/
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector< ReturnSample > out) throws Exception {
ReturnSample value = state.value();
state.clear();
out.collect(value);
}
}
⑥ 拼接后的日志格式化和过滤
- 拼接后的数据需要按照在线训练作业的要求对数据做格式化,比如 json、CSV 等格式。
- 过滤:决定什么样的数据是合格的样本。例如:有真正阅读的内容才算是可用的样本。
⑦ 输出
样本最终输出到实时的数据队列中。下面是实际的作业拓扑和运行时状态:
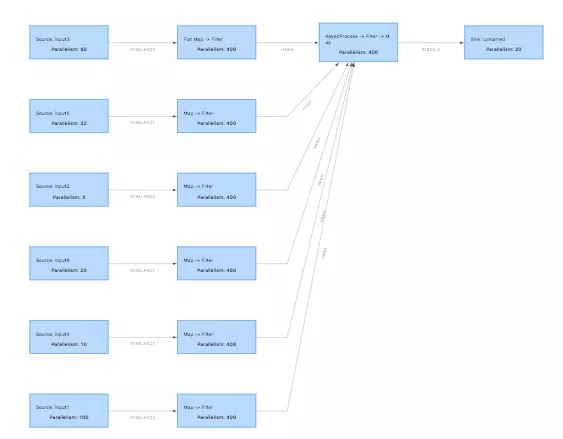
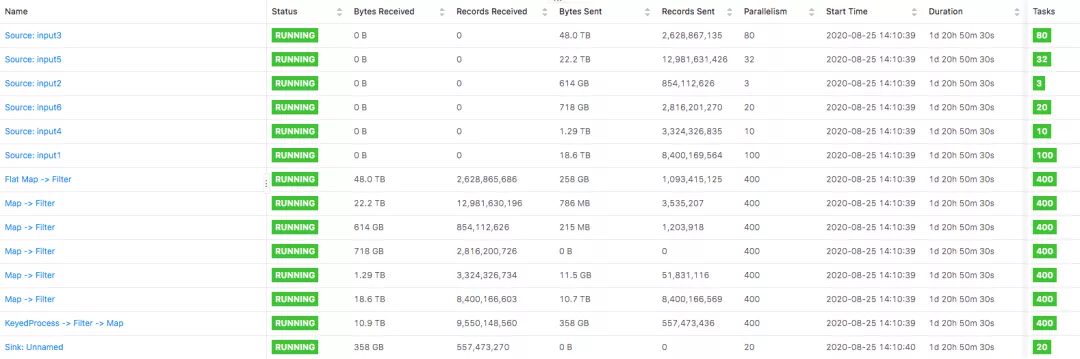
整个样本拼接过程的流程图:

StateBackend 的选取
使用 RocksDB/Gemini 作为 state 的 Backend 的优势和建议:
我们用大数据对 memory 和 RocksDB,Gemini 做了实验对比,结果显示 RocksDB 和 Gemin 在数据处理,作业稳定性和资源使用等方面比 memory 更合理。其中 Gemini 的优势最为明显。
此外,如果是大数据量的 state,建议使用 Gemini + SSD 固态硬盘。
样本的监控
1. Flink 作业的异常监控
- 作业失败监控
- Failover 监控
- Checkpoint 失败的监控
- RocksDB 使用情况的监控
- 作业消费 Kafka 的 Comsumer Lag 的监控
- 作业反压的监控
2. 样本输入端 Kafka 的消费延迟监控
3. 样本输出端 Kafka 的写入量的监控
4. 样本监控
- 拼接率监控
- 正样本监控
- 输出样本格式的监控
- 输出标签对应的值是否在正常范围
- 输入标签对应的值是否为 null
- 输出标签对应的值是否为空
样本的校验
样本生成后,如何验证数据是否准确
-
在线和离线的相互校验
将在线样本从输出的 Kafka 中接入到 HDFS 上离线存储。并按照在线 join 的时间窗口来分区。
-
用同等条件下生成的离线样本和在线样本做对比
-
白名单
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%A6%82%E4%BD%95%E5%9F%BA%E4%BA%8E%E7%94%9F%E6%88%90%E5%9C%A8%E7%BA%BF%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%9A%84%E6%A0%B7%E6%9C%AC/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


