如何以及为什么需要创建一个好的验证集
作者: Rachel Thomas
编译:ronghuaiyang
导读
导读: 验证集的划分真的就是调用一个train_test_split函数这么简单么,其实并不是。
正文: 一个非常常见的场景:一个看起来非常好的机器学习模型在现实的生产环境中使用时是完全失败的。其后果包括老板对现在的机器学习持怀疑态度,不愿再尝试。怎么会这样呢?
导致开发结果与生产结果之间脱节的最可能的原因之一是错误地选择了验证集(甚至更糟,根本没有验证集)。根据数据的性质,选择验证集可能是最重要的一步。虽然sklearn提供了一个 train_test_split 方法,但该方法只获取数据的一个随机子集,对于许多实际问题来说,这是一个糟糕的选择。
训练集、验证集和测试集的定义可能非常微妙,而且这些术语有时使用不一致。在深度学习社区中,“测试时间推断”通常指的是对生产中的数据进行评估,这不是测试集的技术定义。如前所述,sklearn有个 train_test_split 方法,但没有 train_validation_test_split 方法。Kaggle只提供训练和测试集,但是要做得好,你需要将它们的训练集分解为你自己的验证集和训练集。此外,Kaggle的测试集实际上被细分为两个子集。许多初学者可能会感到困惑,这一点也不奇怪!我将在下面讨论这些微妙之处。
首先,什么是“验证集”?
当创建一个机器学习模型时,最终的目标是使它在新数据上是准确的,而不仅仅是在你用来构建它的数据上可以工作的很好。下面是一组数据的3个不同模型的例子:
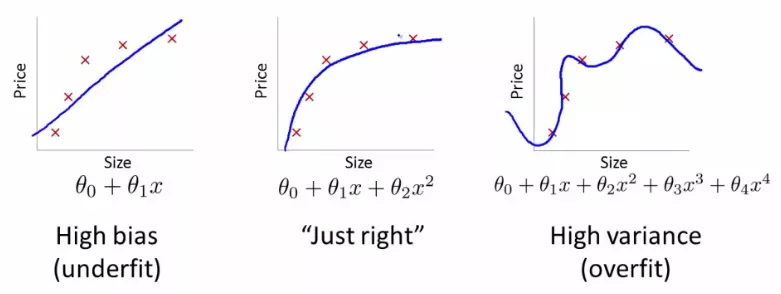
under-fitting and over-fitting
图中数据点的误差对于最右边的模型来说是最小的(蓝色曲线几乎完美地通过了红色点),但这并不是最好的选择。这是为什么呢?如果你要收集一些新的数据点,它们很可能不在右边图表的曲线上,而是更接近中间图表的曲线。
其基本思想是:
-
训练集用于训练给定的模型
-
验证集用于在模型之间进行选择(例如,随机森林还是神经网络更适合你的问题?)你想要一个有40棵树的随机森林还是50棵树的随机森林?)
-
测试集告诉你,你做的怎么样。如果你尝试了许多不同的模型,你可能会偶然得到一个在你的验证集上表现良好的模型,而拥有一个测试集有助于确保情况并非如此。
验证和测试集的一个关键属性是它们必须代表你在将来看到的 新数据。这听起来似乎是一个不可能的命令!根据定义,你还没有看到这些数据。但你还是知道一些关于这些数据的事情。
什么时候随机的子集不够好?
看几个例子是有益的。虽然这些例子中有许多来自Kaggle竞赛,但它们代表了你在实际工作中所看到的问题。
时间序列
如果你的数据是一个时间序列,选择一个随机的数据子集就太简单了(你可以看看你试图预测的之前和之后的数据日期),并不代表大多数业务样本的情况(实际的业务是使用历史数据建立一个模型用于未来的预测)。如果你的数据包含日期,并且你正在构建一个模型以供将来使用,那么你会希望选择一个连续的部分,其中包含最新的日期作为你的验证集(例如,可用数据的最近两周或上个月)。
假设你想把下面的时间序列数据分成训练集和验证集:
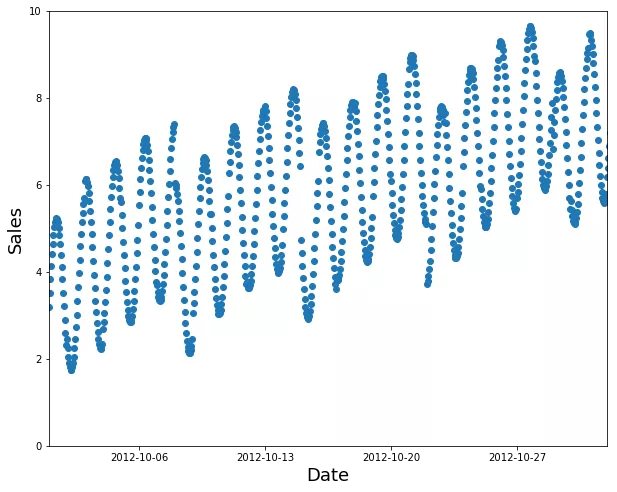
时间序列数据
随机的子集是一个糟糕的选择(太容易填补空白,并不能说明你在生产中需要什么):
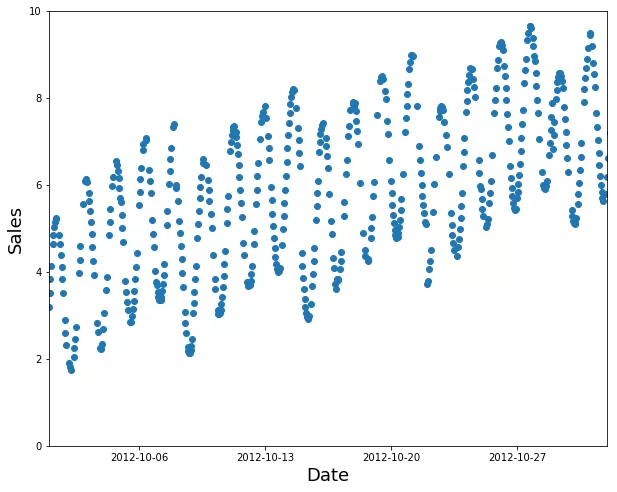
训练集的糟糕的选择
使用较早的数据作为训练集(和较晚的数据作为验证集):
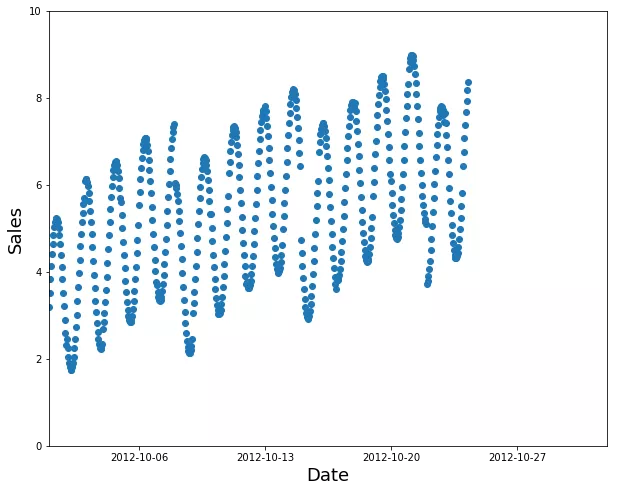
训练集的一个更好的选择
Kaggle有个比赛,预测厄瓜多尔杂货连锁店的销售额。Kaggle的“训练数据”从2013年1月1日到2017年8月15日,测试数据从2017年8月16日到2017年8月31日。一个好的方法是将2017年8月1日至8月15日作为你的验证集,并将所有之前的数据作为你的训练集。
新的人员,新的船,新的…
您还需要考虑在生产环境中进行预测的数据可能与您必须训练模型使用的数据在性质上有所不同。
在Kaggle的分心驾驶员竞赛中,数据是驾驶员开车的图片,因变量是一个类别,如发短信、吃饭或安全向前看。如果你是一家根据这些数据构建模型的保险公司,请注意,你最感兴趣的是模型在你以前没有见过的驾驶员身上的表现(因为你可能只有一小部分人的训练数据)。Kaggle竞赛也是如此:测试数据由没有在训练集中使用的人员组成。


同一个人一边开车一边打电话的两张图片。
如果你把上面的一张图片放在你的训练集里,另一张放在验证集里,你的模型看起来会比它在新人身上表现得更好。另一种观点是,如果你让所有的人来训练你的模型,你的模型可能会对那些特定的人的特征过拟合,而不仅仅是学习到状态(发短信,吃东西,等等)。
类似的动态也在“Kaggle渔业竞赛“中发挥作用,该竞争旨在确定渔船捕捞的鱼类种类,以减少对濒危种群的非法捕捞。测试集由没有出现在训练数据中的船只组成。这意味着你希望你的验证集包括不在训练集中的船只。
有时可能不清楚你的测试数据是如何不同。例如,对于使用卫星图像的问题,你需要收集更多的信息,以确定训练集是否只包含特定的地理位置,还是来自地理上分散的数据。
交叉验证的危险
sklearn之所以没有 train_validation_test 是假定你会经常使用 交叉验证,用不同的训练集的子集作为验证集。例如,三折交叉验证,数据分为3组:A、B和C,,模型第一次在A和B组合起来的训练集上训练,在验证集C上评估C ,接下来,模型在A和C组合起来的训练集上训练,在验证集B上评估,等等。模型的表现是三个的平均。
然而,交叉验证的问题在于,它很少适用于现实世界中的问题,原因如上述各节所述。交叉验证只在可以随机打乱数据以选择验证集的情况下有效。
Kaggle的“训练数据集”=你的训练数据+验证数据
Kaggle竞赛的一大优点是,它迫使你更严格地考虑验证集(以便做得更好)。对于那些刚接触Kaggle的人来说,这是一个举办机器学习竞赛的平台。Kaggle通常将数据分成两组,你可以下载:
-
一个 训练集,其中包括自变量,以及因变量(你试图预测什么)。例如,厄瓜多尔杂货店试图预测销售额,自变量包括商店id、商品id和日期,因变量是卖出的数量。例如,试图确定一个司机是否在开车时做出了危险的行为,自变量可以是司机的照片,因变量是一个类别(如发短信、吃东西或安全向前看)。
-
一个 测试集,它只有自变量。你将对测试集进行预测,你可以将这些预测提交给Kaggle,并得到你的成绩分数。
这是开始机器学习所需要的基本思想,但是要想做得好,需要理解的复杂性要大一些。你会希望创建自己的训练和验证集(通过分割Kaggle“训练”数据)。你只需使用较小的训练集(Kaggle训练数据的子集)来构建模型,在提交给Kaggle之前,你可以在验证集(Kaggle训练数据的子集)上对其进行评估。
最重要的原�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%A6%82%E4%BD%95%E4%BB%A5%E5%8F%8A%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%E5%88%9B%E5%BB%BA%E4%B8%80%E4%B8%AA%E5%A5%BD%E7%9A%84%E9%AA%8C%E8%AF%81%E9%9B%86/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


