基于知识图谱的语义理解技术及应用

分享嘉宾:冯知凡 百度 主任研发架构师
编辑整理:付一韬
内容来源:DataFunTalk·年终论坛
出品平台:DataFun
导读: 知识图谱在人工智能应用中的重要价值日益突显。百度构建了超大规模的通用知识图谱,并在搜索、推荐、智能交互等多项产品中广泛应用。同时,随着文本、语音、视觉等智能技术的不断深入,知识图谱在复杂知识表示、多模语义理解技术与应用等方面都面临新的挑战与机遇。本文将介绍百度基于知识图谱,从文本到多模态内容的理解技术及应用的最新进展。
本文主要内容包括:
- 背景
- 知识图谱文本语义理解
- 知识图谱视频语义理解
- 总结
背景
1. 多模语义理解需求强烈
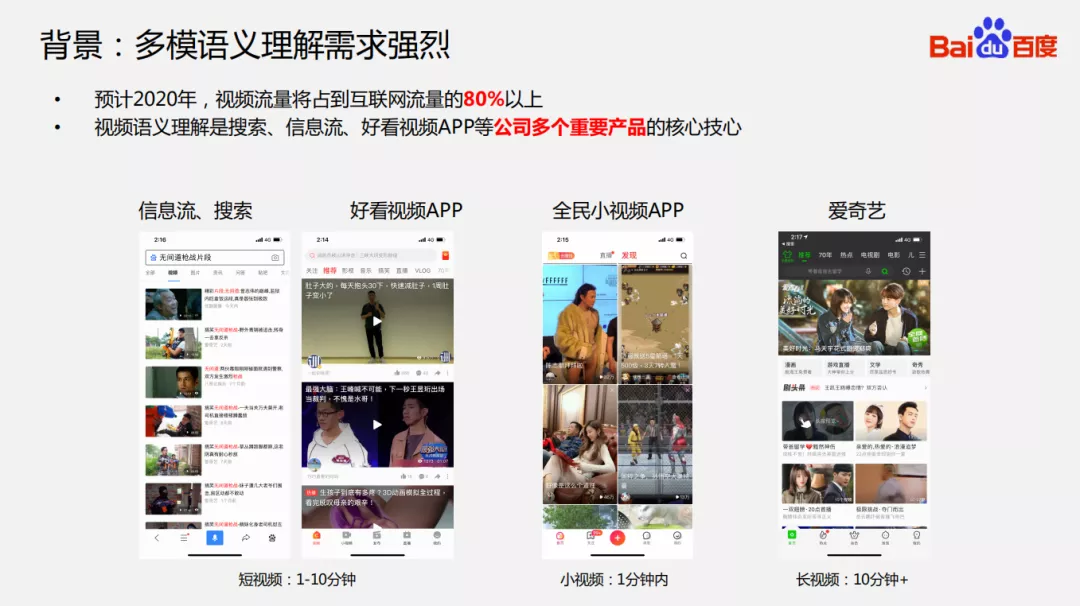
多模语义理解需求强烈。对于百度而言就有很多视频产品,比如信息流、全民小视频、爱奇艺等等,对应长视频、短视频、小视频等,这类视频的深度理解对于公司的视频业务,是非常核心的基础技术。
2. 深度语义理解需要知识
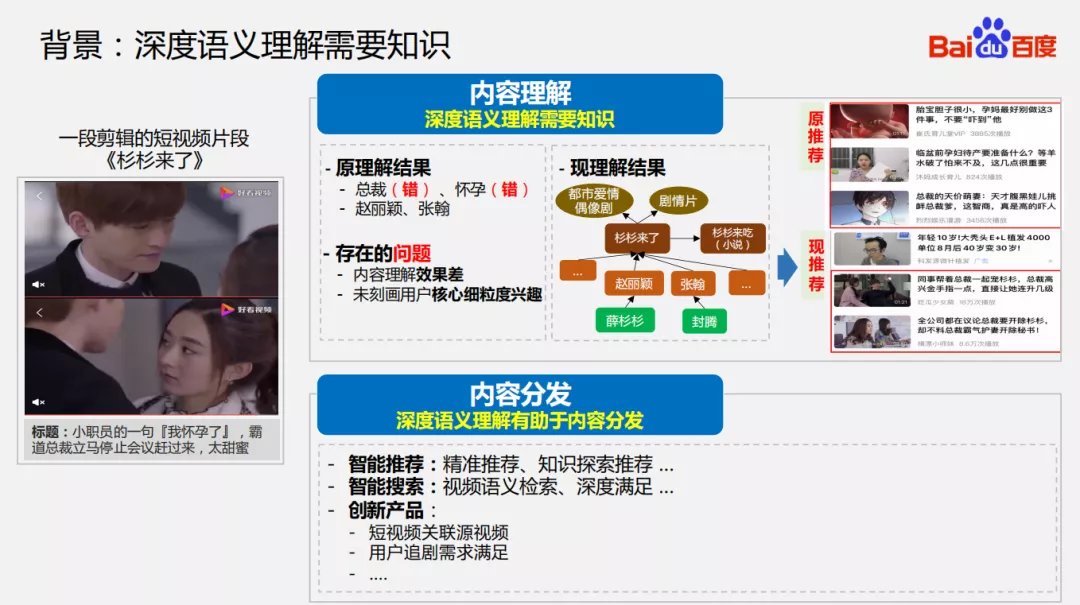
在实际应用场景中,我们发现要实现视频的深度语义理解,在纯感知技术的基础上,知识发挥着重要的价值。比如上面的短视频片段,从内容理解来看,传统的视频理解更多是基于感知,比如通过人脸识别和从 OCR 识别出关键词/字。在实际场景中我们发现这些效果上还有较大优化空间,同时,这样识别出的结果没有刻画出用户对视频核心的细粒度兴趣,比如影视剧的角色、关系等知识。但是基于知识图谱的语义理解就可以解决这类的问题,它能够对视频做深度结构化的解析,然后上层的推荐、搜索可以应用这些知识作为特征辅助内容的高效分发。
3. 目标与价值
根据上面描述,我们的目标是基于知识图谱对用户/资源从多维度进行知识增强的语义分析,协助提供上层智能应用所需语义计算与推理能力。相比传统的理解,它的价值有两个方面:一是它可以真正理解资源背后的知识;二是它可以基于知识图谱进行计算和推理。
知识图谱文本语义理解
1. 知识增强的多维度语义分析
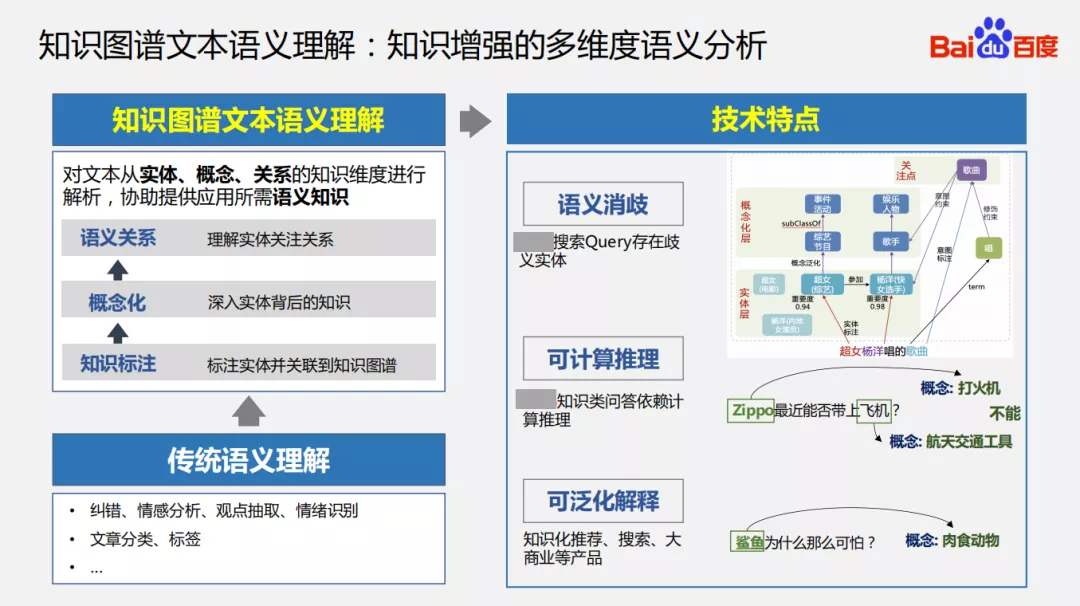
不同于传统的文本语义理解,我们的知识图谱文本语义理解是对文本从实体、概念、关系的知识维度去做全方位的解析,协助提供应用所需语义知识。首先对文本进行实体类的标注,然后将实体关联到知识图谱,这样通过关联关系以及知识图谱获取实体对应信息;其次进行概念化,理解实体背后的知识;最后会理解实体之间的关系,包括实体的属性、侧面等。通过建立知识图谱的文本语义理解,会有三方面的技术特点:语义消歧、可计算推理和可泛化解释。
2. 多种文本形态与业务场景下,诸多挑战
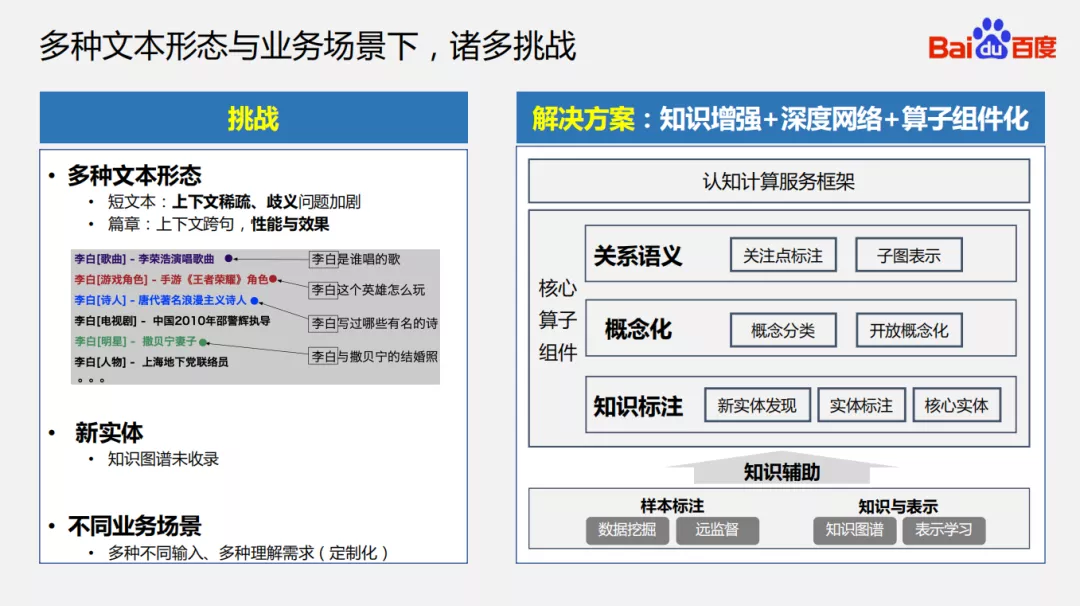
在实际的场景之下,我们会面临诸多的挑战:
① 多种文本形态
短文本:上下文非常稀疏,歧义问题加剧;
篇章:很多篇章的理解需要上下文跨句或者跨段落才能理解,在实际工程场景之下,对性能和效果需要很高的要求,而性能是决定该策略是否可以上线的重要因素之一。
② 新实体:知识图谱不可能收录全部实体,如果在文本中新实体没有被识别,这对文本的理解会有负面的影响。
③ 不同业务场景:多种不同的输入和多种定制化的需求。
我们的解决方案是首先使用一些知识增强的技术去提升语义理解的效果,其次是深度神经网络,最后将一些核心算子进行抽象并组件化,通过组件化的方式定制化去支持不同的业务。
3. 实体标注:基于知识增强的标注技术
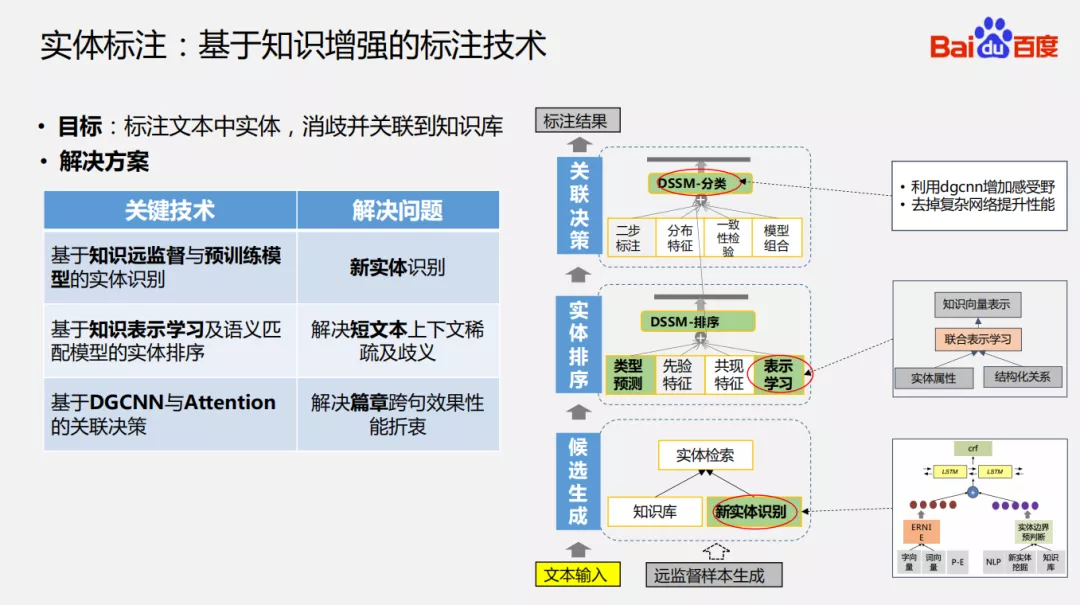
在知识图谱中实体标注的目标:标注文本中的实体,消歧并且关联到知识库。这其中有一些关键的技术,流程如下:
首先,先对输入的文本进行实体的识别,比如“李白这首歌好听吗?”,对于“李白”这个实体,它背后有很多候选实体,可能是诗人、歌曲、游戏里的英雄角色或者是普通的人。在候选实体中有一个很重要的问题——新实体的识别,这里面我们通过知识远监督的方式生成大量训练样本并且结合百度预训练模型 ERNIE 来提升新实体识别的效果。
其次,有了这些候选实体之后会对所有候选实体进行排序,这里面我们引入的是知识向量表示,联合实体属性和结构化关系去训练出实体 embedding 表示,然后使用语义匹配模型做统一的度量进行实体的排序。
最后,对候选实体得分最高的实体进行一个判定,是否将该实体关联到知识库中。
4. 概念化:基于概念图谱的细粒度概念化
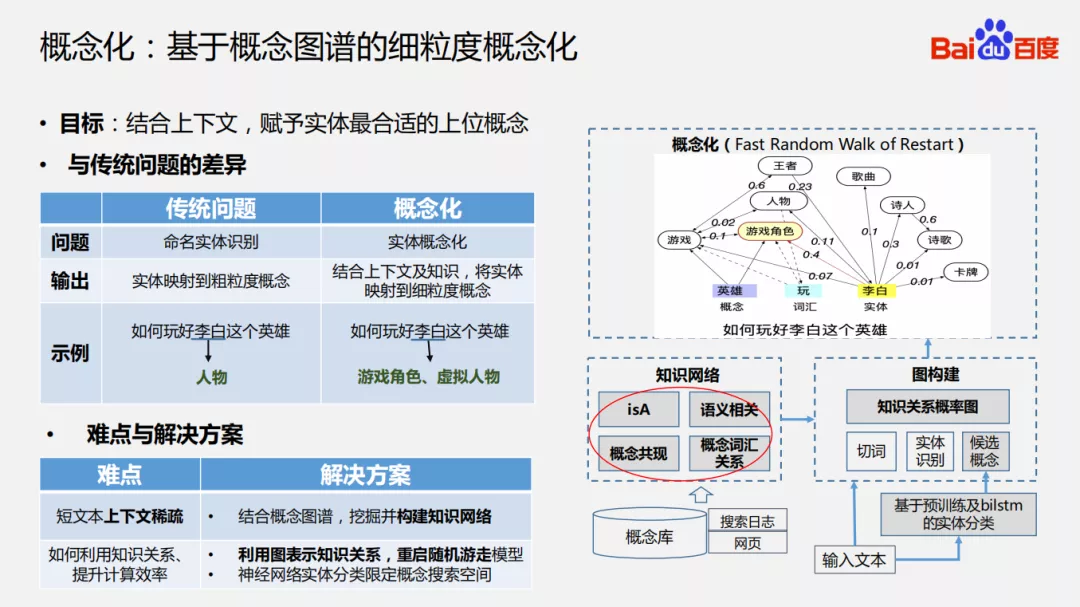
接下来是概念化,与传统的命名实体识别是有差异的,比如“如何玩好李白这个英雄”,在命名实体识别中会将“李白”识别成人物,在概念化中根据当前上下文,动态识别出实体对应的上位概念,即这里对于“李白”会识别出游戏角色、虚拟人物。所以,概念化会从更细的粒度的刻画文本中这个实体在当前上下文中最合适的上位概念,做到符合当下场景下的知识理解。
在实际应用中,我们会构建一套知识网络去提供知识来增强文本的理解。对于输入文本通过知识网络会转化成一个图,图上的节点会是实体、属性还有一些动词形容词等等。有了这些节点之后,在图上进行随机游走,最终随机游走收敛完之后会得到每个实体在当前上下文最合适的上位概念。
5. 概念化-关键技术:知识网络
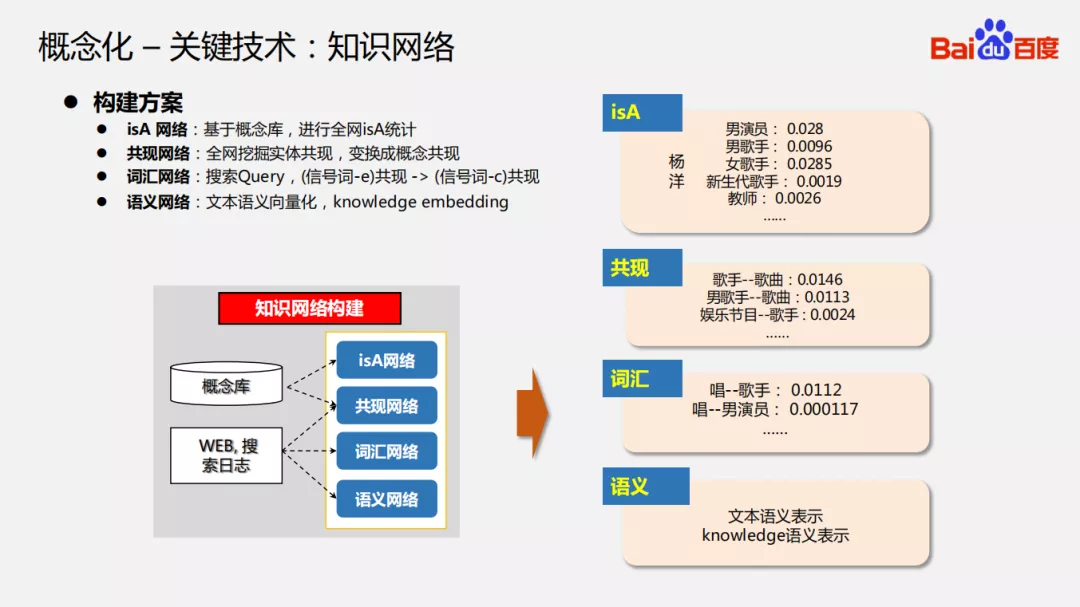
对于概念化最关键的技术就是知识网络的构建,方案如下:
- isA 网络:实体上下位的知识,比如杨洋是男演员、男歌手;
- 共现网络:挖掘全网下实体的共现,同时转换成概念的共现,比如歌手与歌曲的共现;
- 词汇网络:构建出大量实体、概念和信号词之间的共现关系,这里的信号词更多是形容词/动词;
- 语义网络:预训练的文本语义向量 ERNIE 和上面提到的训练出实体的向量表示。
6. 面向多种应用场景
在面向各种应用场景中,我们会将这些核心技术抽象出算子,通过算子组件化的方式去满足不同场景下文本语义理解。
应用示例:

知识图谱视频语义理解
1. 知识增强的视频深度理解
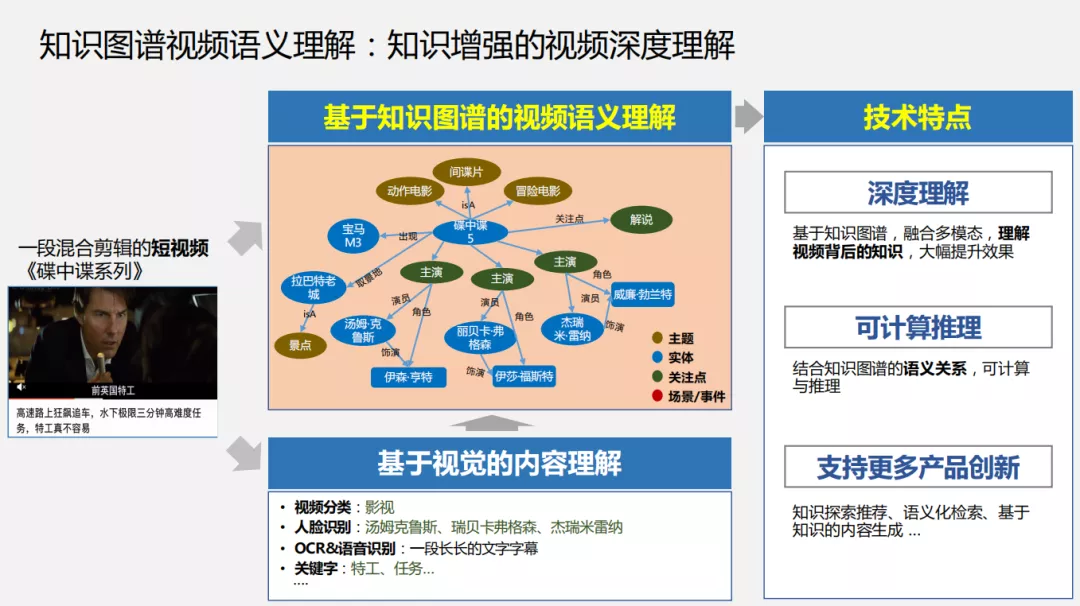
传统的视频理解会对视频分类,比如上面的视频会分类到影视,会通过人脸识别出汤姆克鲁斯,再通过 OCR 和语音识别出文本并提取出一些关键字,但是这样的理解并没有真正理解视频背景的知识,如前文所述在实际场景中也会存在问题。
我们会把视频转换成知识子图,通过知识图谱对这张子图进行知识扩充,并使用推理和计算来置信计算及冲突检测。它有三个技术特点:深度理解、可计算推理和支持更多产品创新。
示例:
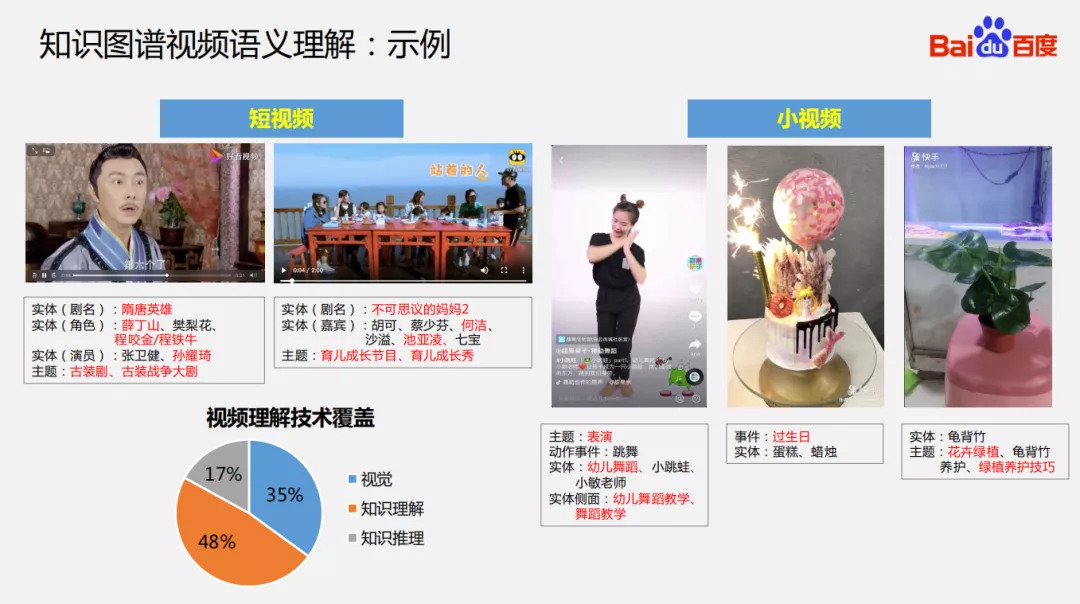
2. 知识图谱视频语义理解的挑战

在实际的场景之下,会有两方面的挑战:
① 知识构建与利用:对于视频语义理解需要哪些知识?如何构建这些知识?如何利用这些知识去深度理解视频?
② 多模态:视频本身是典型的多模态,包括文本、视觉和语音,在这些多模态信息如何融合、去噪、理解?
3. 基于知识及计算推理的深度语义理解
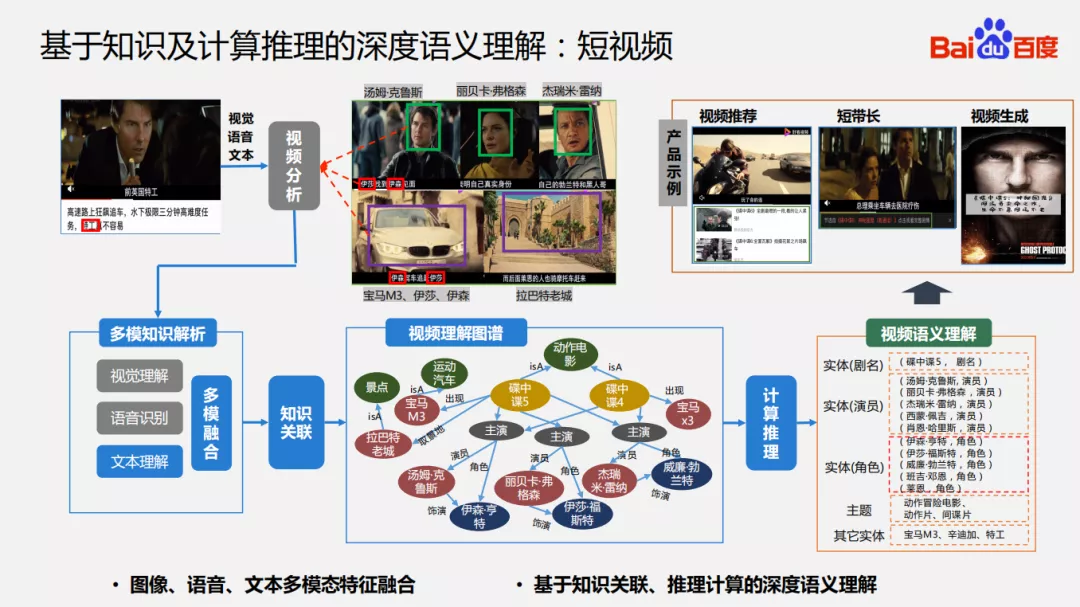
视频语义理解完整的流程,包括:
对短视频进行多模态的分析,包括视觉理解、语音理解和文本理解这些感知上面的理解;然后将这些结果利用知识关联技术建立到视频理解图谱当中;最后有了这些关联关系、知识和多模解析的结果,会做多模态融合并且在这张图上进行计算推理。
在小视频的语义理解中,流程同短视频的语义理解相同,但与短视频会有一些差异,因为小视频更偏向于主题、场景类的理解。
4. 视频理解图谱:区别于传统图谱
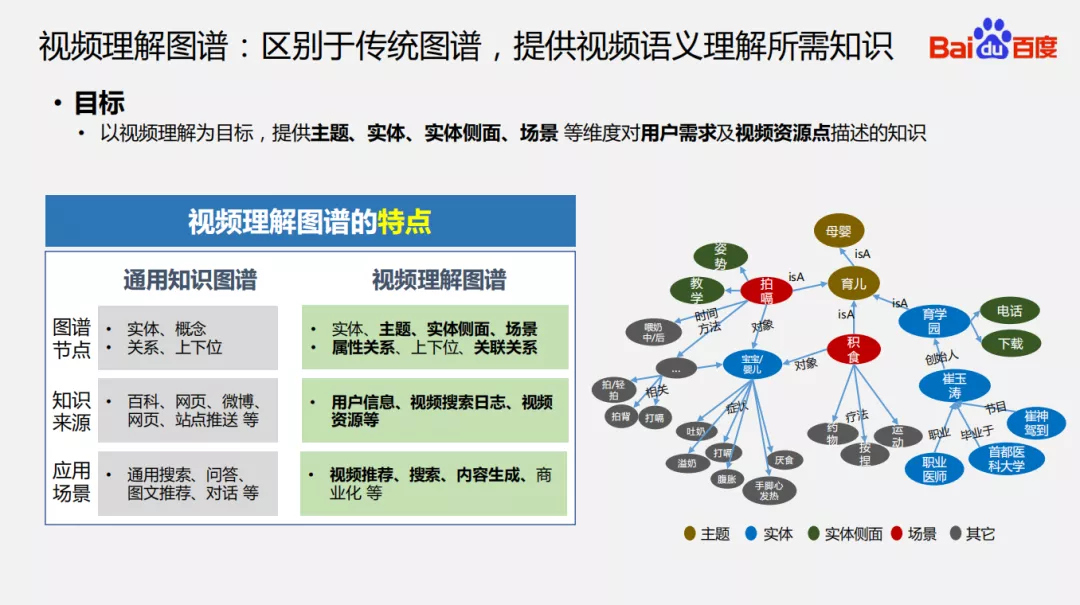
视频理解的目标是提供主题、实体、实体侧面、场景等维度对用户需求及视频资源点描述的知识,不同于传统的知识图谱,视频理解图谱在图谱节点方面更关注于主题、实体侧面、场景类的知识,以及这些知识的关系如属性关系、上下位关系和关联关系等;在知识来源方面专注视频搜索日志、用户评论、视频资源本身来挖掘图谱等;在应用场景方面更多关注视频推荐、搜索和内容生成等。
5. 视频理解图谱:聚焦重点知识建设
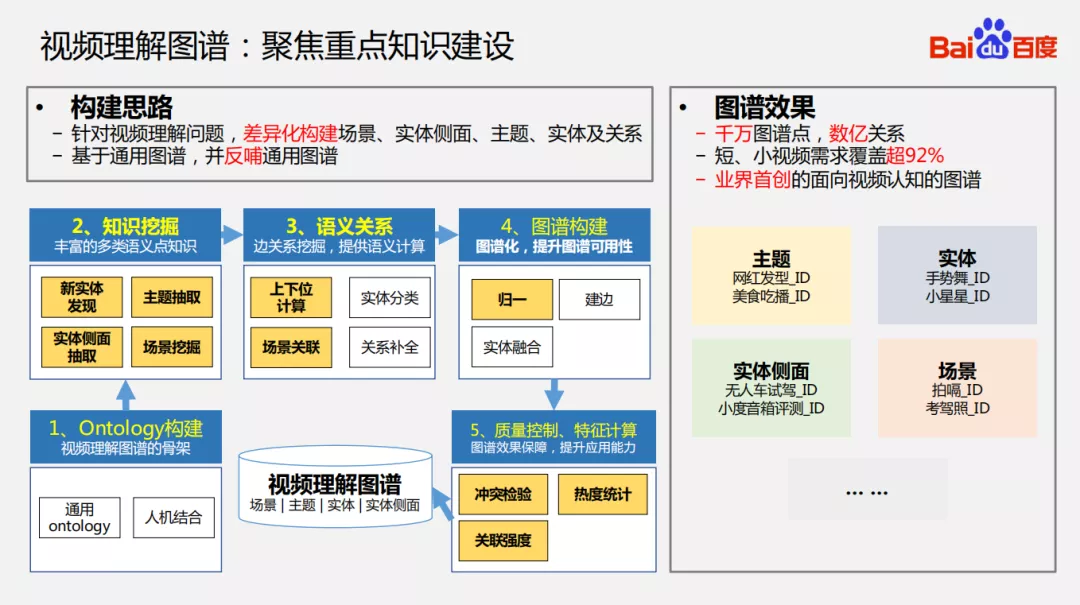
上面提到了视频理解图谱与传统图谱之间的关系,所以我们的构建思路就是差异化的构建,重点构建场景、实体侧面、主题、实体以及它们的关联关系,最后将这个图谱反哺到通用的图谱当中。整个过程如下:
① Ontology 构建:借鉴与通用图谱的 ontology 构建然后使用人机结合的方式构建出视频理解图谱的骨架;
② 知识挖掘:有了骨架后开始各种知识的挖掘,包括新实体挖掘、实体侧面抽取、主题抽取和场景挖掘等;
③ 语义关系:有了上面的知识节点,开始建立关系,例如上下位的关系、场景的关系等;
④ 图谱构建:有了节点和关系,开始进行图谱化构建,这里重点会对实体进行归一/关联和建边;
⑤ 质量控制、特征计算:在建立完视频图谱之后,为了图谱的应用,会再进行冲突检验、热度特征统计和关联强度特征计算等。
6. 关键技术:多种知识发现与挖掘技术
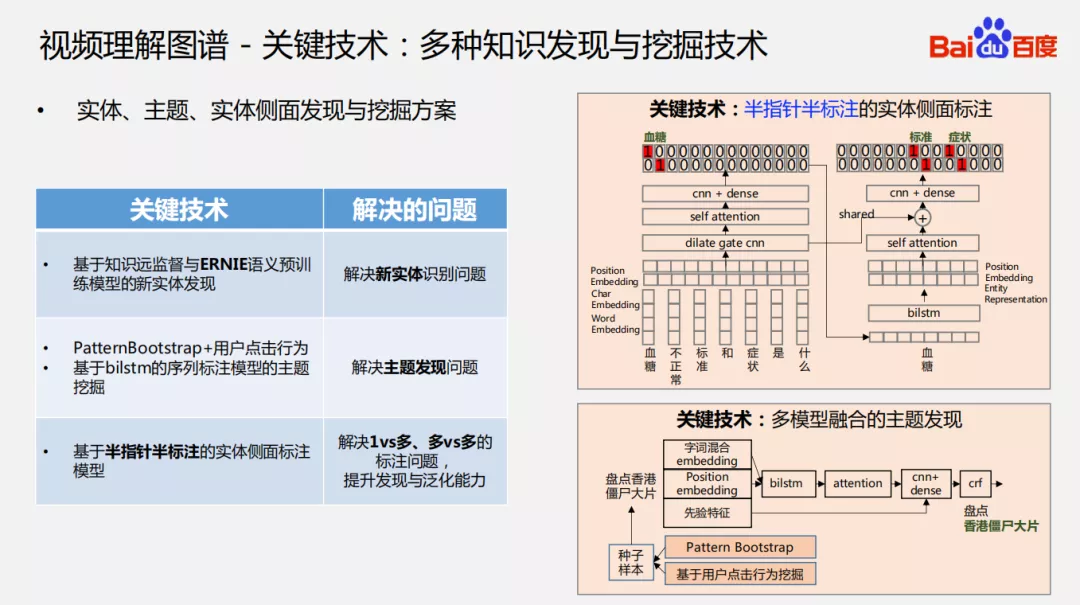
实体、主题、实体侧面发现与挖掘:
- 新实体挖掘:上面已介绍;
- 主题发现:结合用户的点击行为解决主题发现冷启动问题,然后使用序列标注的方式进行主题挖掘;
- 实体侧面挖掘:基于阅读理解的模型,使用半指针半标注的方式进行实体侧面标注。
7. 实体理解
❶ 基于多模融合与计算推理,理解视频主体
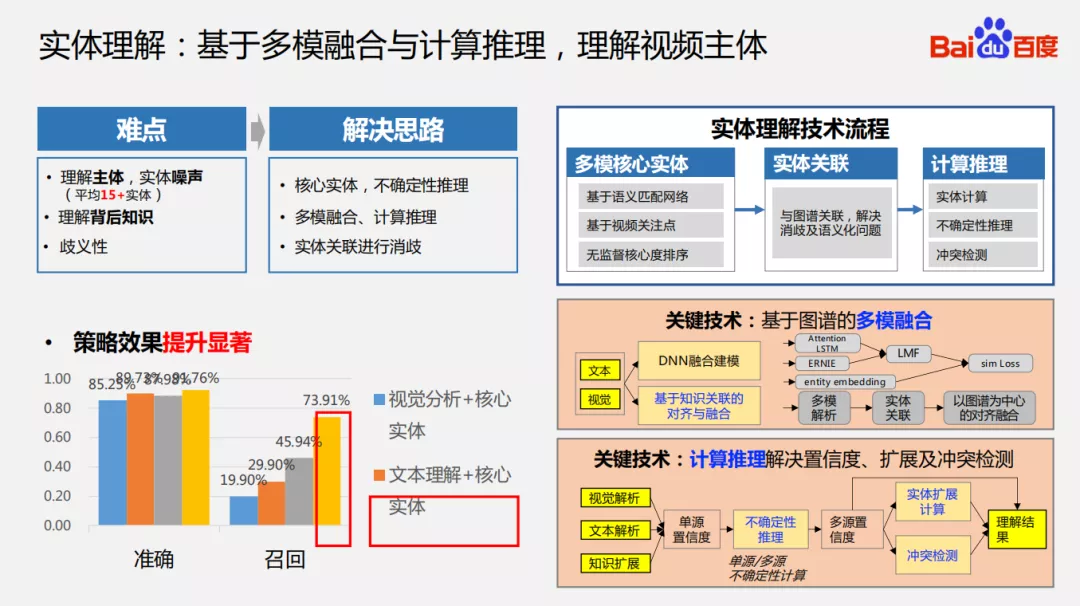
一个视频中会存在很多的实体,对视频的主旨理解而言,有重要的实体也有不重要的实体。我们需要区分出哪些实体是视频的主体,哪些实体是噪声;进一步需要理解实体背后的知识,因为看到一段视频,在里面出现的人和事甚至一些动作并不能完整描述视频的主旨;最后就是需要对歧义进行消除。
我们的解决思路是:
① 多模态解析:使用语义匹配网络、视频关注点和�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9F%BA%E4%BA%8E%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1%E7%9A%84%E8%AF%AD%E4%B9%89%E7%90%86%E8%A7%A3%E6%8A%80%E6%9C%AF%E5%8F%8A%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


