基于的爱奇艺实时计算平台建设实践

分享嘉宾:梁建煌 爱奇艺
编辑整理:张宇轩
内容来源:Flink Forward Asia
导读: 随着大数据的快速发展,行业大数据服务越来越重要。同时,对大数据实时计算的要求也越来越高。今天会和大家分享下爱奇艺基于Apache Flink的实时计算平台建设实践。
今天的介绍会围绕下面三点展开:
- Flink的现状与改进
- 平台化的探索和实践:实时计算平台
- Flink业务案例
01、Flink的现状与改进
1. Flink现状
首先和大家分享下爱奇艺大数据服务的发展史。
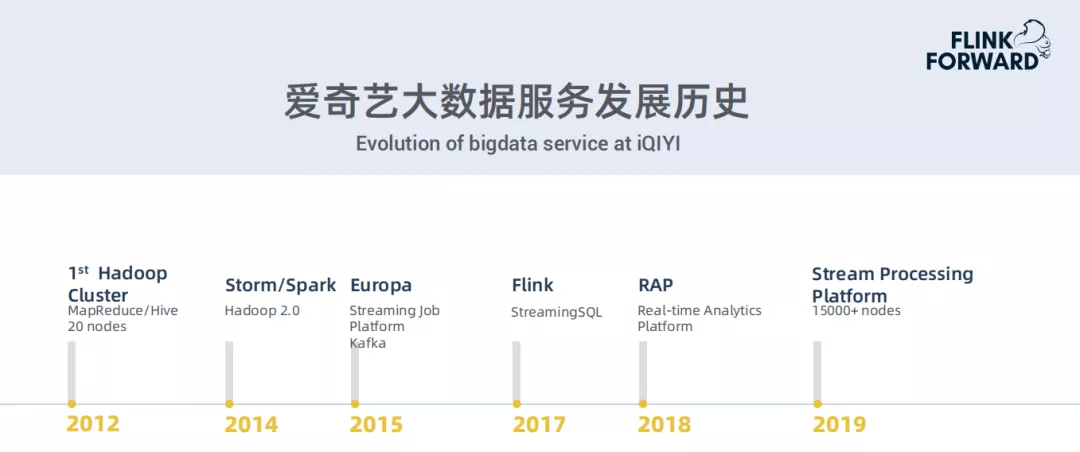
我们从2012年到2019年,大数据服务经过了一系列持续的改进和发展:
- 2012年搭建了第一个Hadoop集群,当时只有大概20几个节点,使用的计算框架是MapReduce和Hive等
- 到2013,2014年,开始使用Hadoop 2.0,上线了Storm和Spark,由于Storm的使用性和稳定性不够好,被放弃使用,转而使用Spark
- 2015年发布了第一个实时计算平台Europa,上线了Kafka
- 2017年使用了Flink,同时我们基于Spark和Flink打造了流式计算引擎StreamingSQL
- 2018年推出了自研的实时计算平台Real-time Analytics Platform (RAP)
- 2019年基于Flink达到了内部的流数据生态平台;
然后介绍一下Flink在爱奇艺的使用情况:

这是Flink在爱奇艺的一些使用情况,目前的节点规模大约15000多台,总的作业规模有800多个,每天的数据流的生产量大概在万亿级别,约2500TB左右。注:本数据仅代表嘉宾分享时的数据。
下面是目前爱奇艺基于Spark,Flink打造的实时计算平台框架:
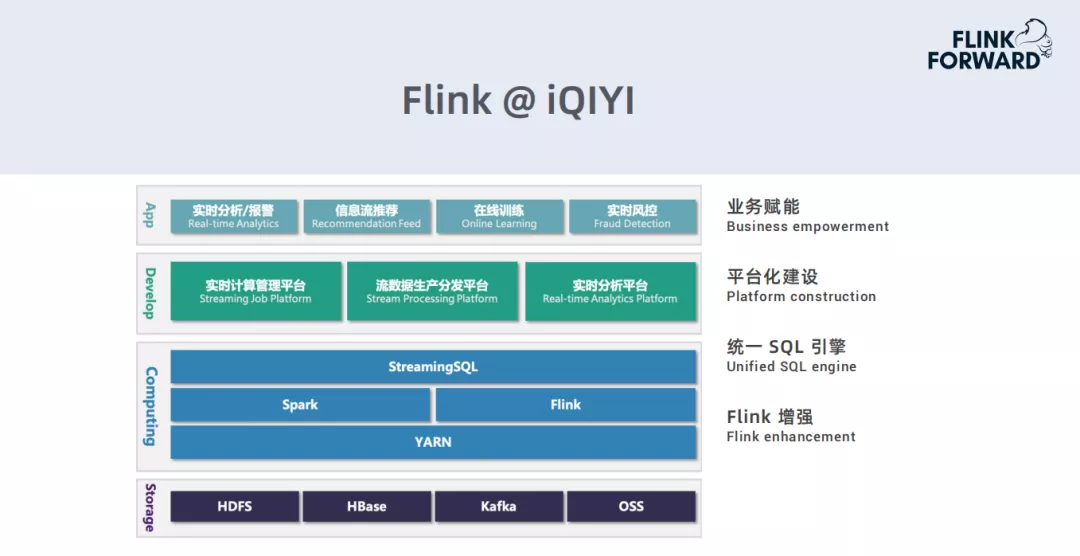
- 底层存储使用的HDFS,HBase,Kafka和OSS。
- 实时计算框架通过Spark和Flink部署,在这两个服务之上,构建了一个独立的流式系统引擎StreamingSQL。
- 在引擎之上,打造了多种类型的平台,用来实现管理计算的任务,流数据的生产分发和实时数据分析等不同需求。
- 实时计算在爱奇艺业务上有些典型的应用场景:实时分析、报警,信息流(如广告类)推荐,内部数据在线训练,实时风控(内容追踪等)。
2. Flink改进
Flink改进-监控和报警:
以前只是做了简单的状态监控,在出现问题之后,不知道内部状态是怎么样的。近期做了一些改进,并和内部的监控平台Hubble进行集成,主要有三个级别的监控指标:
- Job级别监控指标:Job状态、Checkpoint状态和耗时。如果没有进入到running状态,会对其进行重启操作,防止其查询卡在不健康状态下
- Operator级别监控指标:时延、反压、Source/Sink流量,对每个Operator进行指标聚合
- TaskManager级别监控指标:CPU使用率、内存使用率、JVM GC等
Flink改进-状态管理:

**问题一:**长时间运行Flink job,会因为各种原因导致它重启。Checkpoint只在Flink作业内部有效,一旦主动重启或异常重启时,上一个job的状态会全部丢失。
解决方法:作业重启时,找到上一次运行成功的Checkpoint,从中恢复。
缺陷:对于状态很大的作业,会使用RockDBStateBackend做增量Checkpoint;上一次的Checkpoint被依赖而无法删除,会导致状态堆积(生产环境中的一个作业的Checkpoint总共多达8TB)。
对于这个缺陷也就是:
问题二: Checkpoint无限依赖
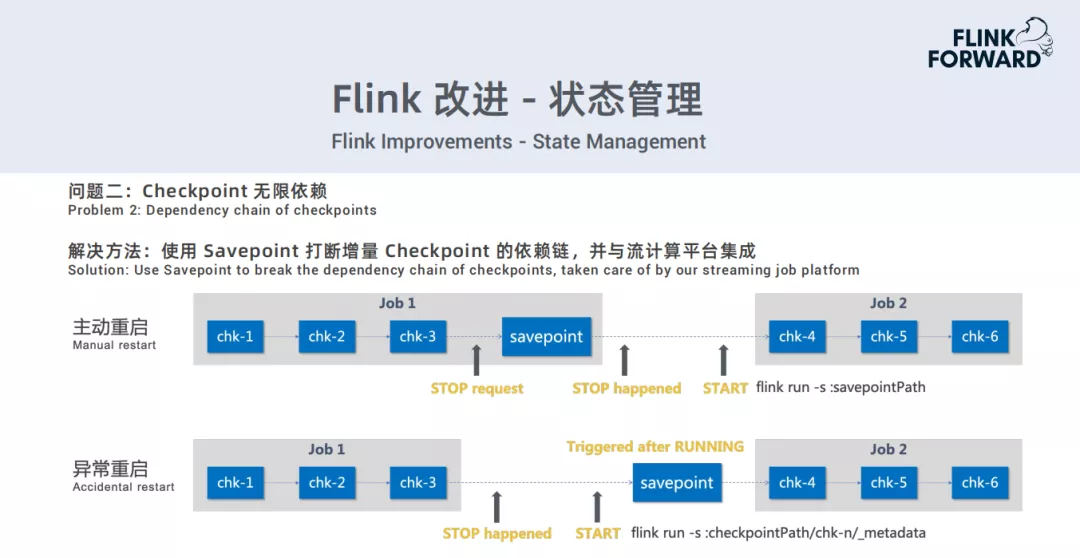
解决方法:使用Savepoint打断增量Checkpoint的依赖链,并与流计算平台集成。
主要有两种产品,一种是通过业务通过平台主动重启,重启之前对此job做一次Savepoint操作,启动时从Savepoint的路径去启动。
第二种是发生异常重启时,来不及做Savepoint。那么会在Checkpoint启动起来,一旦job进入到running状态以后,立即做一次Savepoint,解决依赖问题。
StreamingSQL:
StreamingSQL是基于Spark和Flink构建的一个统一的流数据ETL工具,具有以下一些特征:
- SQL化:业务上去写流计算任务时,不需要去写Scala程序,只需要编写一些SQL代码即可完成流计算ETL任务的开发。
- DDL:流表、临时表、维度表、结果表。
- UDF:系统预定义常用函数、用户自定义函数。
- 提供SQL编辑器。
下面是StreamingSQL的一个实例:

02、实时计算平台
1. 实时计算管理平台

上图是Spark、Flink任务开发和管理的web IDE的例子,用户可以在页面上配置一些参数和字段,进行任务的开发,上传,作业的重启,运行状态的查看等常规操作。
此外,还提供其他的一些管理:
- 文件管理:任务Jar包、依赖库。
- 函数管理:提供丰富的系统函数、支持用户注册UDF。
- 版本管理:支持任务、文件的版本对比以及回滚。
- 常规管理:监控大盘、报警订阅、资源审计、异常诊断。
2. 实时数据处理平台
为了确保数据发挥该有的价值,让数据的流转更加通畅,让业务处理数据、使用数据和分析数据更加便捷,我们改进服务,推出了数据处理平台和数据分析平台。
以下是实时数据处理平台演进过程:
2015 – 2016
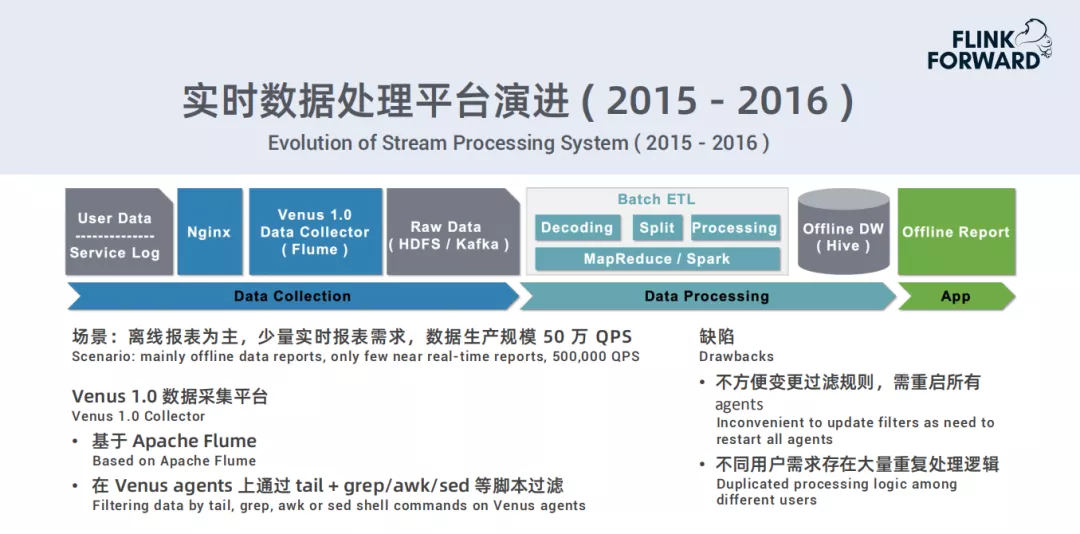
- 场景:离线报表为主,少量实时报表需求,数据生产规模50万QPS;
- Venus 1.0数据采集平台:基于Apache Flume;在Venus agents上通过tail+grep/awk/sed等脚本过滤;
- 缺陷:不方便变更过滤规则,需重启所有agents;不同用户需求存在大量重复处理逻辑。
2017 – 2018
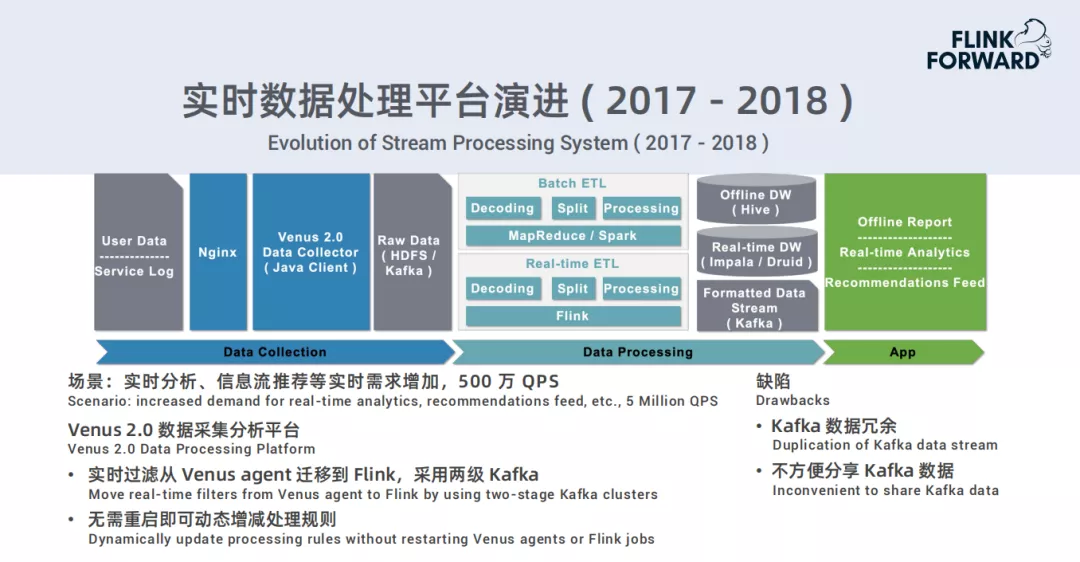
- 场景:实时分析、信息流推荐等实时需求增加,500万QPS
- Venus 2.0数据采集分析平台:实时过滤从Venus agent迁移到Flink,采用两级Kafka;无需重启即可动态增减处理规则
- 缺陷:Kafka数据冗余,不方便分享Kafka数据
2019
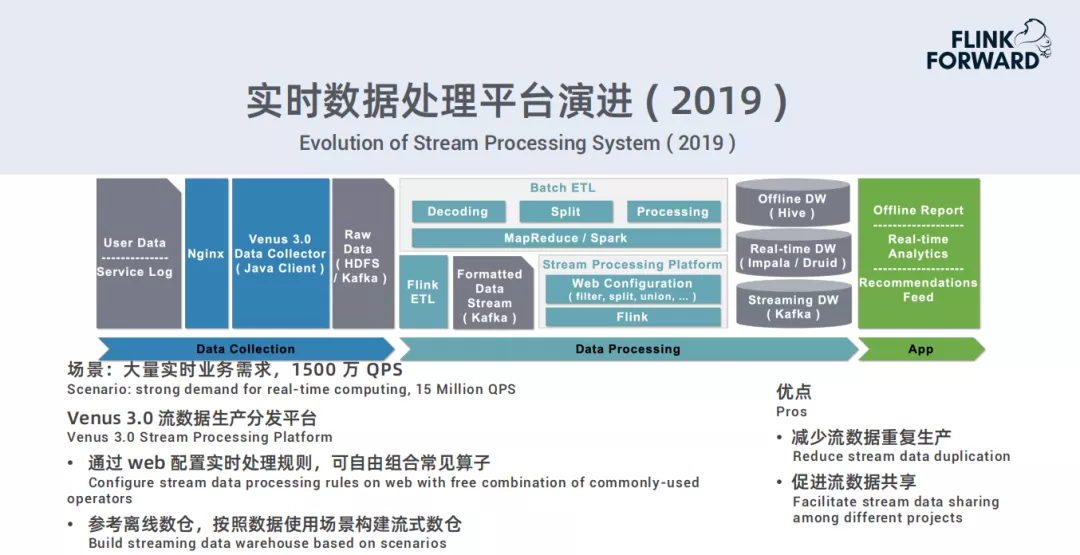
- 场景:大量实时业务需求,1500万QPS
- Venus 3.0流数据生产分发平台:通过web配置实时处理规则,可自由组合常见算子;参考离线数仓,按照数据使用场景构建流式数仓
- 优点:减少流数据重复生产,促进流数据共享
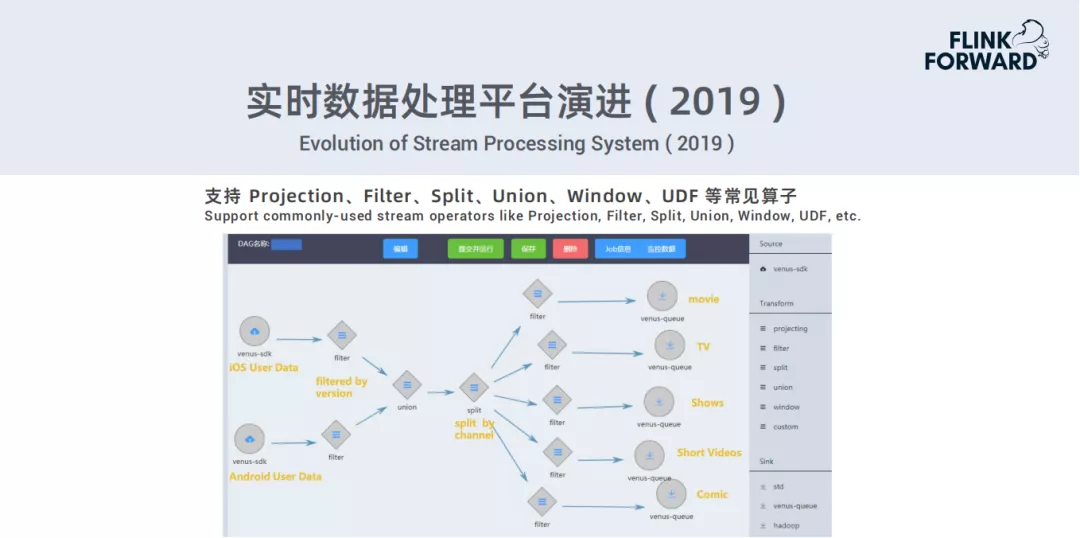
下面是一个例子,流数据处理平台的一个页面。目前平台支持Projection、Filter、Split、Union、Window、UDF等常见算子。
3. 实时分析平台
目前我们实时数据OLAP分析平台主要有两大类:一类是实时报表,主要有A/B测试、精细化运营等;另一类是实时报警,主要有VV/UV、播放故障等。
下图是现在的一个架构图:
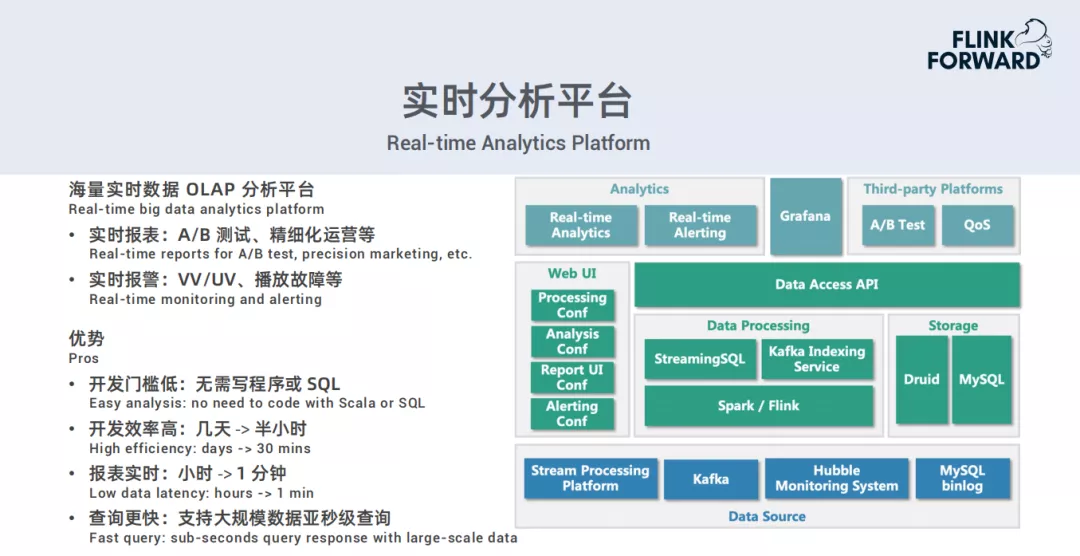
目前支持流处理平台,Kafka,Hubble监控系统,MySQL binlog这些数据源。用户可以通过UI配置处理规则,分析规则,需要展示的报表的风格,以及一些报警的规则。这些处理规则和分析规则等,后台会自动把它们的function对应的服务转成一个job,然后自动把结果上传到MySQL里。此外,用户可以在多平台上面进行分析查看、观测报警率等,也可以方便的通过api对接到自己的第三方的定制化平台里。
目前,我们实时分析平台拥有以下一些优势:
- 开发�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9F%BA%E4%BA%8E%E7%9A%84%E7%88%B1%E5%A5%87%E8%89%BA%E5%AE%9E%E6%97%B6%E8%AE%A1%E7%AE%97%E5%B9%B3%E5%8F%B0%E5%BB%BA%E8%AE%BE%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


