基于的优化与实践

分享嘉宾:周晖栋 bilibili
编辑整理:宋灵城 贝壳找房/东南大学
出品平台:DataFunTalk
导读: 本文主要介绍Flink实时计算在bilibili的优化,将从以下四个方面展开:① Flink-connector稳定性优化;② Flink sql优化;③ Flink-runtime优化;④ 对未来的展望。
01 概述
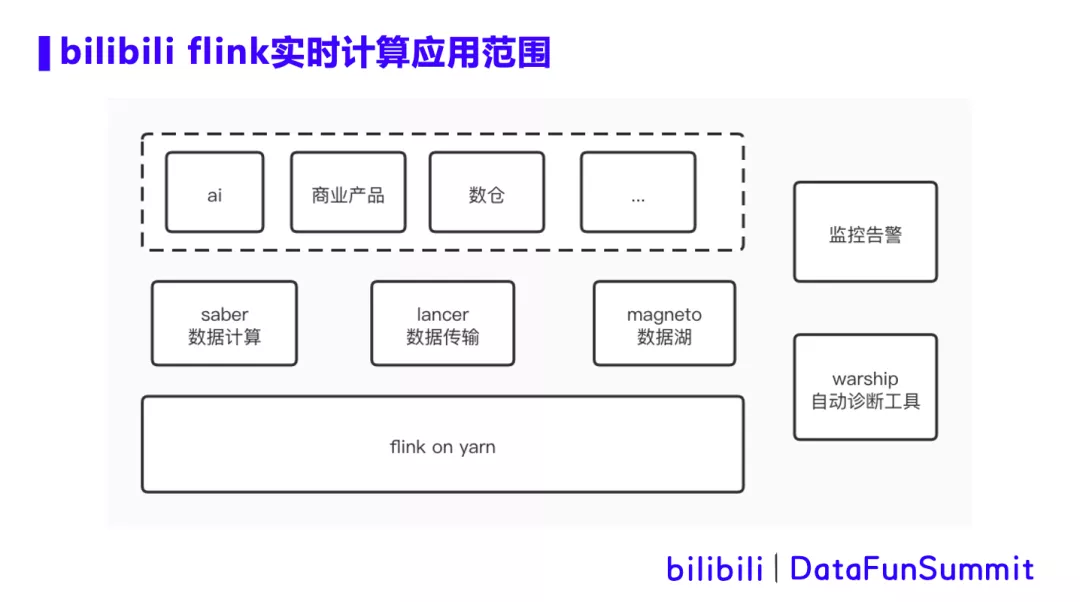
首先介绍下Flink实时计算在b站的应用场景。
在b站,Flink on yarn 主要支持3个场景,saber数据计算,lancer数据传输和magneto数据湖。
saber是b站的一个数据计算提交平台,主要支持业务方通过Flink sql和Flink jar的方式提交实时计算任务。目前平台有上千个任务在运行,并且仍在迅猛增长。
lancer是b站的数据传输系统,主要用于收集app端、服务端等各种数据上报,根据元数据的定义信息将数据写入kafka,hive等后端存储,用于下游处理使用。lancer承载了日增万亿数据规模。
magento是b站的数据湖项目,通过Flink将上游数据写入iceberg或者hudi。在基于hdfs的表上,magento支持数据的增删改操作,同时支持分钟级可见性。
以上三个系统支持了AI,商业产品和数据仓库等业务线的众多实时传输和实时计算业务场景。同时,针对平台上的Flink任务,我们配置了监控告警,以及warship自动诊断工具,用于辅助运维。今天主要分享在我们实践过程中遇到的痛点以及解决思路。
02 Flink-connector稳定性优化
1. hdfs集群局部热点问题
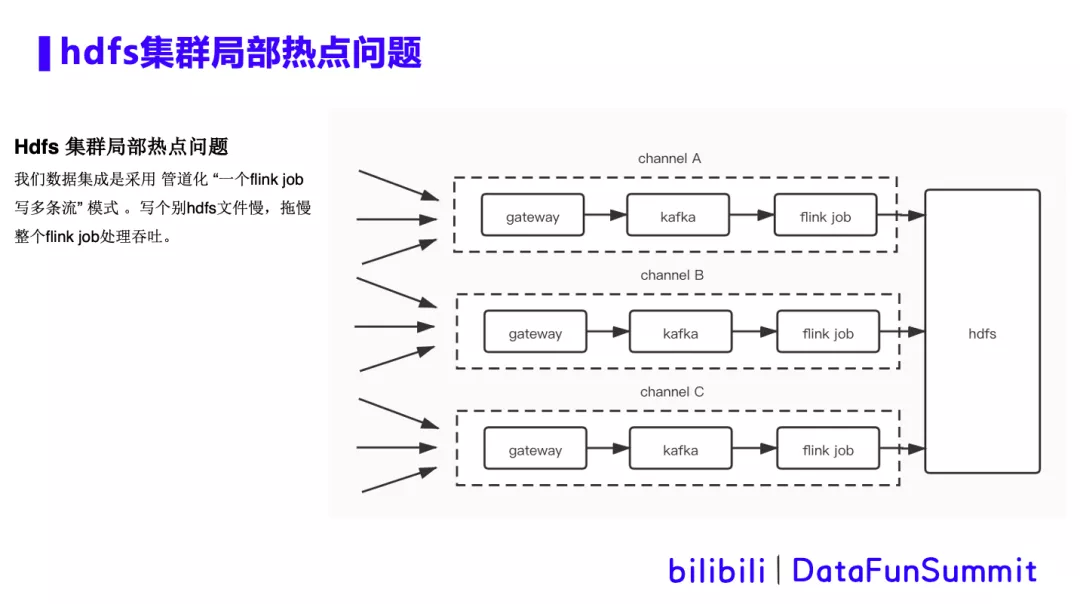
背景描述:Flink在写hdfs时遇到写个别hdfs文件慢的问题,也就是hdfs集群局部热点问题。由于b站数据集成是采用管道化的方式,即“一个Flink任务写多条流”的模式。数据集成过程中会出现几百个流存在于同一个kafka topic中的现象,并且由同一个Flink 任务分流写到多个hive表中。这就需要给任务设置很大的并行度,从而会同时打开超大数量的hdfs文件,这使得局部热点问题更加严重。当Flink任务做checkpoint时,hdfsSink会去做flush数据,close文件等操作,经常因为个别文件close慢,而拖累整体的吞吐。
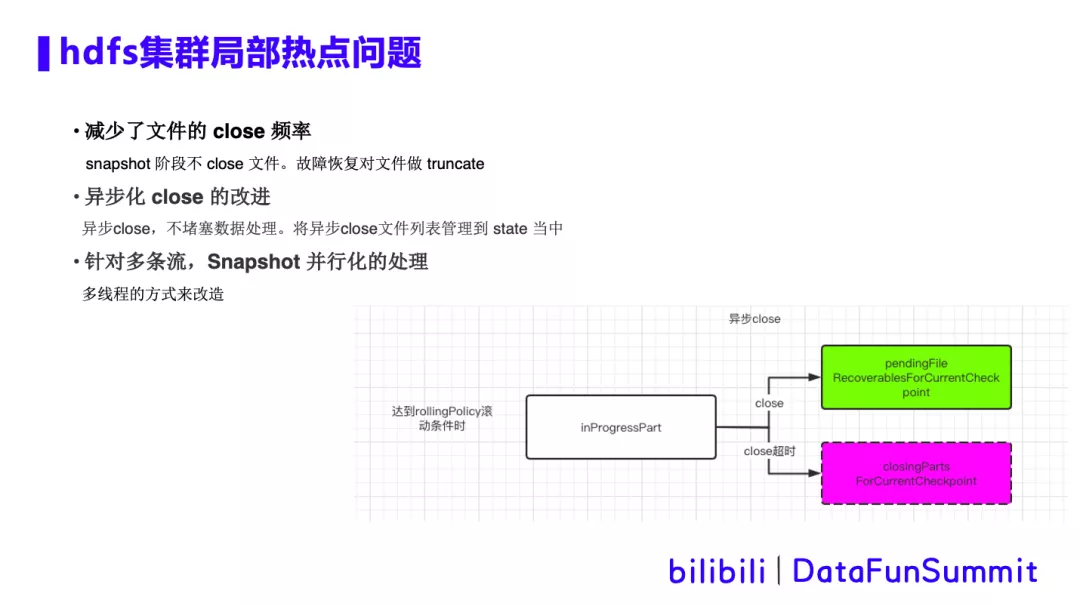
优化方案:针对hdfs局部热点问题,我们做了三点优化:
① 减少文件的close频率。在Snapshot 阶段,不会去close文件,仅将内存数据刷写到hdfs中,并记录写出文件的offset。在从checkpoint做故障恢复时,就需要对文件做Truncate,将文件截断到offset位置,再继续写入,相当于去掉多余的数据。这个方案可以减少文件close的频率,同时大大减少小文件的生成。
② 文件close的异步化改进,将close超时的文件放到异步队列中,从而保证 close 的动作不会堵塞整个主链路的处理,提升hdfs局部热点情况下的吞吐。异步close 文件操作,需要加入到 state中管理。即使故障恢复时,也能继续对文件进行关闭。
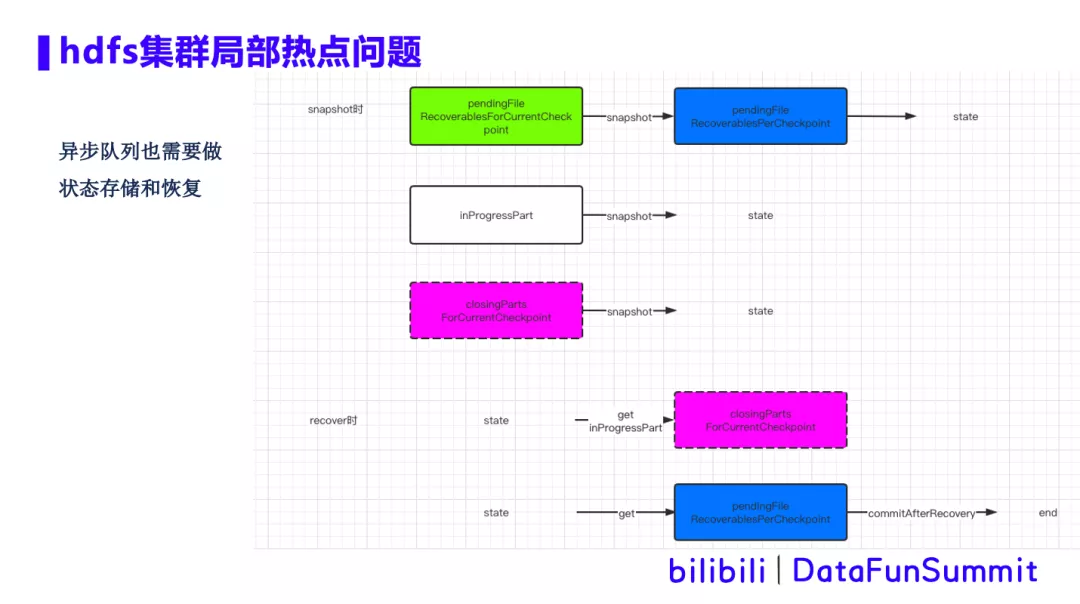
③ 针对多条流,Snapshot 还做了并行化的处理,多条流并行处理其实就是打开多个 bucket,flink框架原生是通过循环的方式来进行串行的处理,而并行化改造后通过多线程来处理,就可以增加处理速度,减少Checkpoint超时的发生。Snapshot时,文件close在异步队列存储和恢复的具体流程图,如下所示:
2. 分区read判断问题
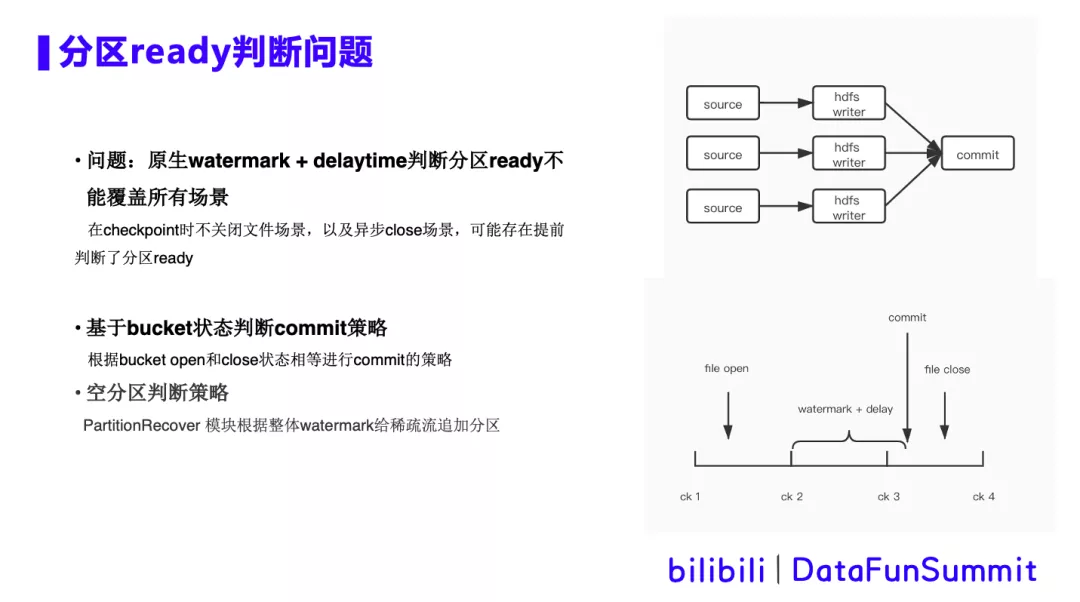
背景描述:右上角展示的是读取kafka数据写入hive的Flink任务的简单DAG图,由多并行度的hdfs writer算子和单并行度的commit算子组成。在commit算子接收上游所有算子checkpoint都已经完成,并且当前时间超过了watermark +delaytime时,我们就认为该hive分区已经ready了,可以commit hive分区了。然而在checkpoint时不关闭文件以及异步close的场景中,可能出现长时间文件未close的情况,那么超时后就会提前判断认为分区ready,从而提交hive分区,但由于文件未关闭,下游任务运行时就会出现报错。
优化方案:
① 基于bucket状态判断commit策略,即根据bucket的open和close状态相等进行commit的策略,保证bucket已经全部关闭,才会进行commit。
② 空分区判断策略。有些流的数据并不是连续的,可能数个小时都没有一条数据,这种情况会带来分区的Watermark没有办法正常推进,引发hive分区不创建的问题。因此我们引入PartitionRecover模块,会根据Watermark来推进分区的通知。针对有些流的Watermark不推进的情况,会在分区超时后未更新的情况下,通PartitionRecover模块来进行分区的追加,从而保证Watermark的正常推进。
3. 通用sink稳定性优化
背景描述:
① Flink任务Sink端会连接多样的分布式存储和消息中间件等,通常以多分片的形式分布在多台机器上。因此,会出现因集群侧局部热点问题,某台机器的压力过大,导致flink与该机器上分片的通信RT变长,从而引起任务局部或者整体反压,影响整体吞吐和稳定性。
② 针对某些吞吐巨大,一致性要求不高的场景,语义上满足At least Once即可,但需要极高的稳定性。
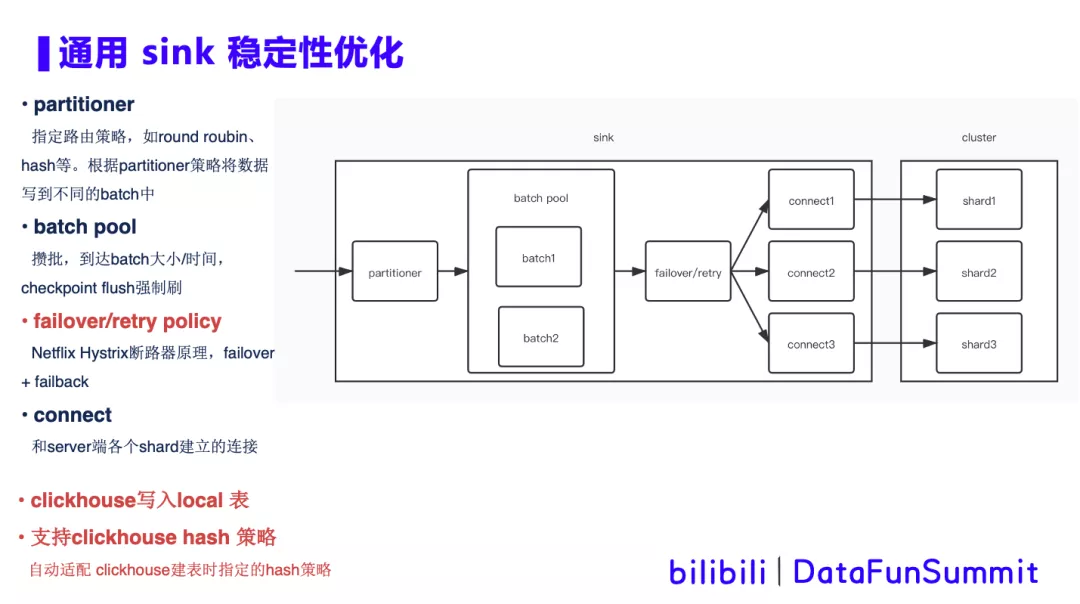
优化方案:
① partitioner
对数据指定路由策略,包括round roubin、hash等,然后根据partitioner指定的策略将数据写到不同的batch中。
② batch pool
Batch pool中是一个攒批的过程,到达batch大小或时间的阈值时批量发送,同时当触发checkpoint后,会flush强制刷出。
③ failover/retry policy
借鉴了Netflix Hystrix断路器原理,当数据发送timeout超时或者异常时,则将此对应connector加入黑名单,将发送失败的数据failover重新发送到其他shard上,一段时间后,再尝试failback。如果failback发送到之前异常的shard成功,则将对应的connector从黑名单中取出,恢复原状。通过failover+failback的策略,可在集群内部做小范围的容错。
④ connector
与server端各个shard建立一对一的连接。
⑤ 通用性方案在clickhouse的实践
在clickhouse上实现了写入local表,并支持clickhouse hash策略,自动适配clickhous建表时指定的hash策略。使其与读写分布式表一致,并支持查询优化。
03 Flink SQL 优化
1. interval join优化
背景描述:在ai实时生成模型训练数据场景中,需要将feed流和click流进行join,将信息的展现和用户的点击关联在一起并输出,构成正例和反例,作为模型训练的数据输出。由于feed流和click流到达的先后顺序不定,需要使用interval join将数据缓存一段时间,等待左流、右流到达完成join。优化的两个需求如下:
① 在sql语言上需要同时实现窗口内单次join和多次join,Flink interval join原生只支持单次join。
② 业务场景数据量非常大,可达到每秒几十万条的数据规模,在此规模下,原生interval join 效率很差,其通过每来一条数据,就遍历一次全部缓存数据的方式来做join,无法抗住大数据量场景。
优化方案:
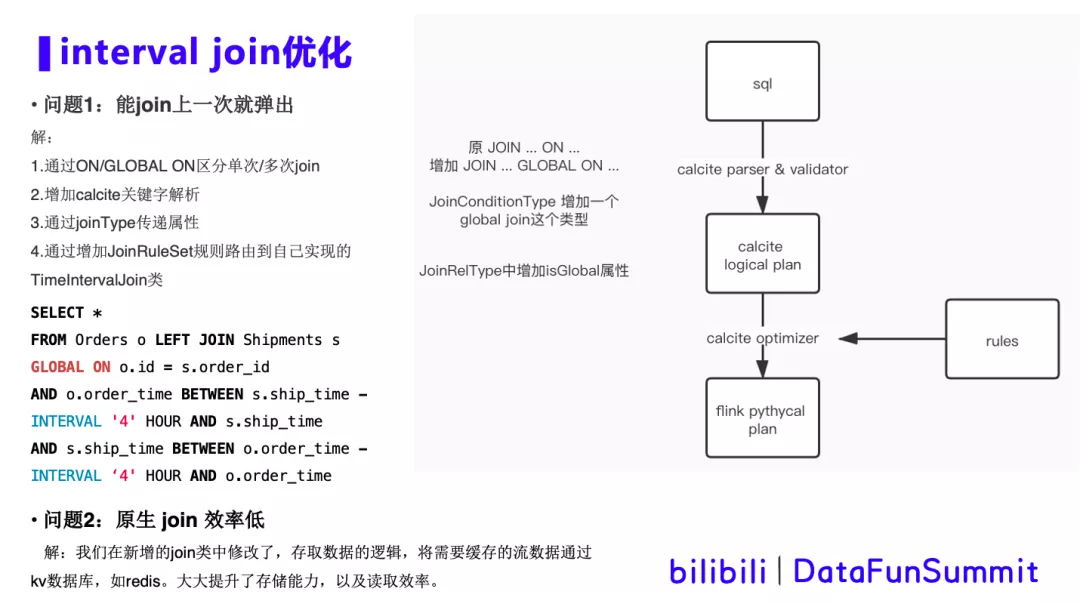
首先来了解一下Flink sql是如何解析并映射到对应的方法类,如上边的图所示:
① sql通过calcite parser 和validator过程,转换为calcite logical plan。
② 再通过rules优化规则进行优化,最后转换为Flink physical plan。
由于calcite当中的几种join的逻辑相对比较完备,修改这里面的逻辑很困难。想要在sql语义上完成同时支持单次join和多次join,我们选择在join的on逻辑基础上支持global的逻辑。通过join on 和join global on来区分两种类型的join方式。具体操作如下:
① 在JoinConditionType 增加一个global_join这个类型,并且在JoinRelType当中加一个属性isGlobal。这样一来,在javacc解析后拿到新增的global_join类型,待到Flink physical plan,从Flink当中去解析。最终通过 GLOBAL ON关键字将“多次join”的信息传递给 Flink底 层 TimeIntervalJoin类。
② 为了不影响原有interval join逻辑,通常做法是新增了一个类,我们在JoinRuleSet中,增加了一个新的JoinRule的解析,必须能解析出两个窗口的条件才能进入我们新增的join类中,这样可以做到和其他的join互斥。
③ 为了提高interval join效率问题,我们在新增的join类中修改了存取数据的逻辑,将需要缓存的流数据写入kv数据库,如redis。这大大提升了存储能力,以及读取效率。
2. kafka自定义分流优化
背景描述:
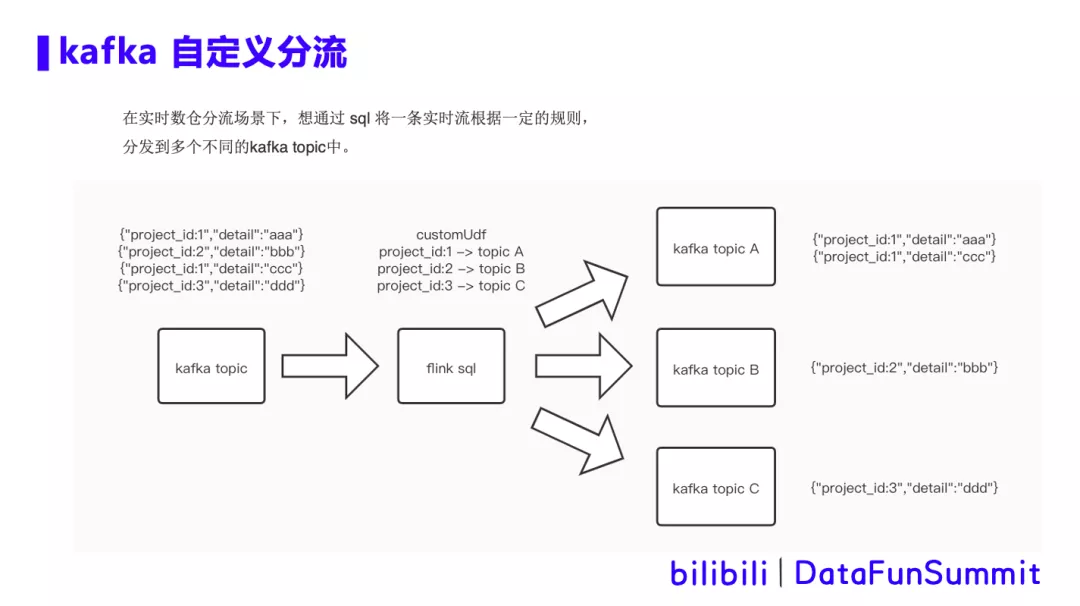
在实时数仓分流场景下,想通过sql将一条实时流根据一定的规则,分发到多个不同的kafka topic中。如图所示,通过自定义udf解析数据中project_id字段,将数据分流到a b c 三个topic中。
优化方案:

04 Flink runtime优化
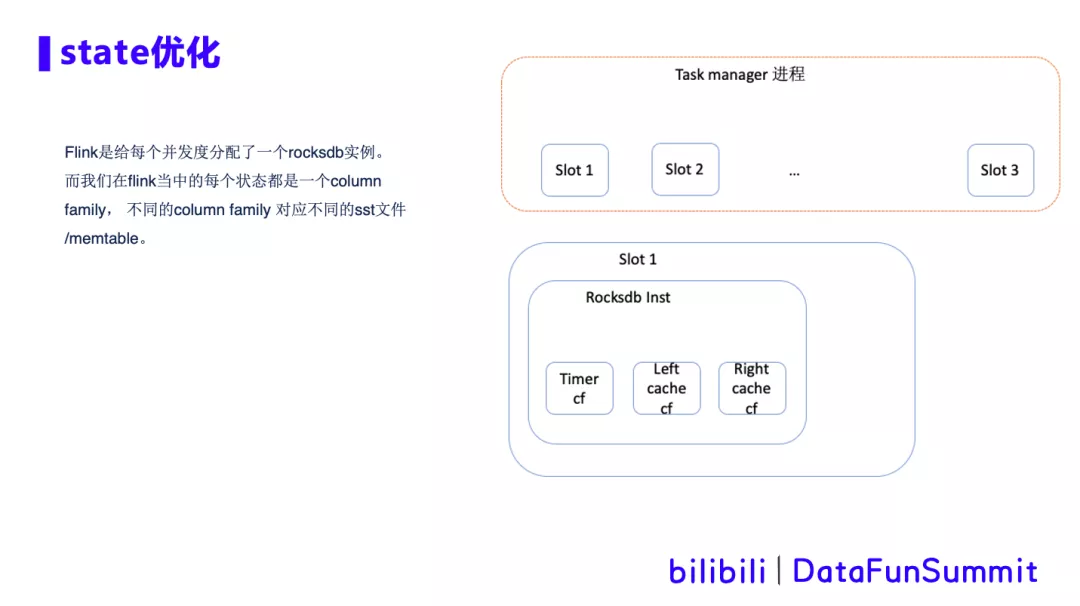
1. Flink state优化
针对Flink任务中超大state cache的场景,我们进行cache存储的调研和优化。在cache快速过期的场景下,比如interval join,之前提到的ai实时生成模型训练数据,feed流和click流做join,需要cache的数据量大,设定一个小时就过期,且没有update操作。Cache调研:
① redis
Redis的优点是可以存储下大量数据,通过kv查找join数据非常高效。缺点是全内存存储cache,非常的昂贵。而且redis作为外部存储,并不能很好的checkpoint联动,故障恢复时还需要考虑如何管理redis内的kv数据对,易用性不强。
② rocksdb
Rocksdb是基于LSM结构的kv存储引擎, 通过内存+磁盘模式存储,存储量大,成本低。
且同样可以通过kv高效查找数据。同时和checkpoint可以很好的结合,一个checkpoint对应一组rocksdb的sst文件,便于故障恢复的管理。
所以我们最终选择使用rocksdb最为state的cache。Rocksdb cache在Flink中的架构如下图所示:
rocksdb最显著的特征就是会compaction,rocksdb的存储是把记录按照key排序后分布到各个文件当中。如下图所示,rocksdb会将L0的小文件进行合并,保证L1开始各层文件中的key都是有序排列的,来提高读取时磁盘的读取效率。

但是在我们的场景中,当数据量增大,这种高频率的合并会占用大量的CPU资源,最终导致整个任务没法运行。针对这个问题,我们做了如下三个优化方案:
① FIFO compaction
在latency join的场景中,不需要数据的层层压缩,所以我们使用rocksdb的FIFO compaction策略。该策略适用于低负载数据的存储,所有的文件都位于 L0。当文件总大小超过配置值 CompactionOptionsFIFO::max_table_files_size时,最早的 SST 文件将会被删除。这种方式大大减少了CPU的使用。
② Bloom filter policy
rocksdb L0级的数据未经过排序,查找时需要遍历所有sst⽂件,效率极低。通过设置Bloom filter policy的方式提升效率。每个新创建的SST file都会包含一个Bloom filter,这个Bloom filter可以确定我们要查找的key是否有可能在这个sst文件,大大提升查询效率。
③ 磁盘打散
Flink的默认是随机为各个slot分配磁盘,我们改进使用round robin方式分配磁盘,确保同一个算子可以使用到各块不同的磁盘,充分打散rocksdb的IO。
2. 全局并行度
在sql任务中,可以设置默认并行度,也可以对各个算子单独设置并行度。对用户来说,学习成本大,设置的也不一定合理。具体痛点如下所示:
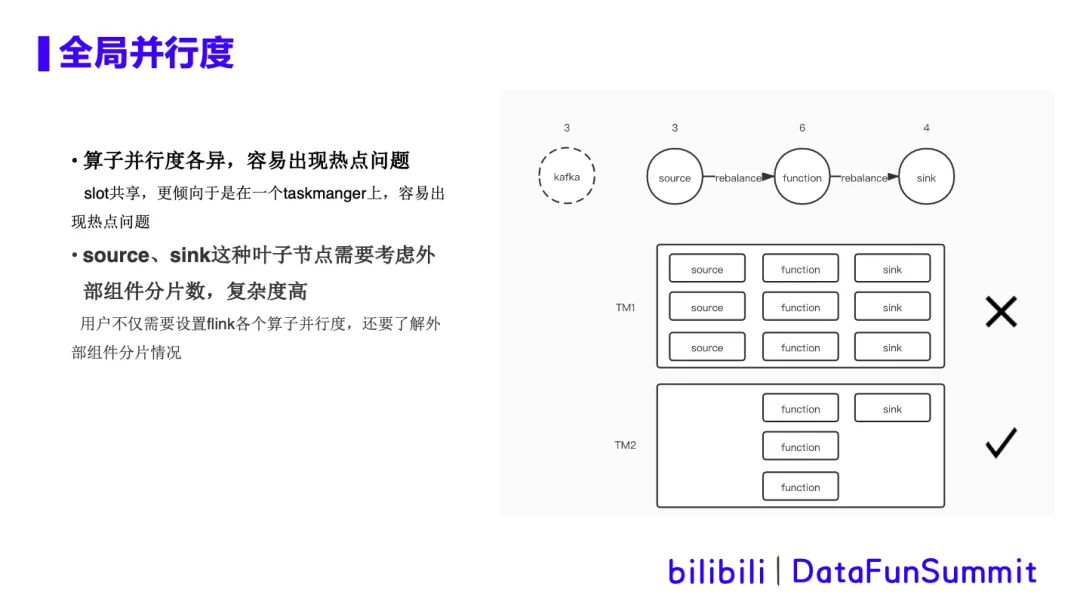
按照热点来看,上面这个task是有cpu热点,下面这个task cpu比较空闲。
**优化方案: **
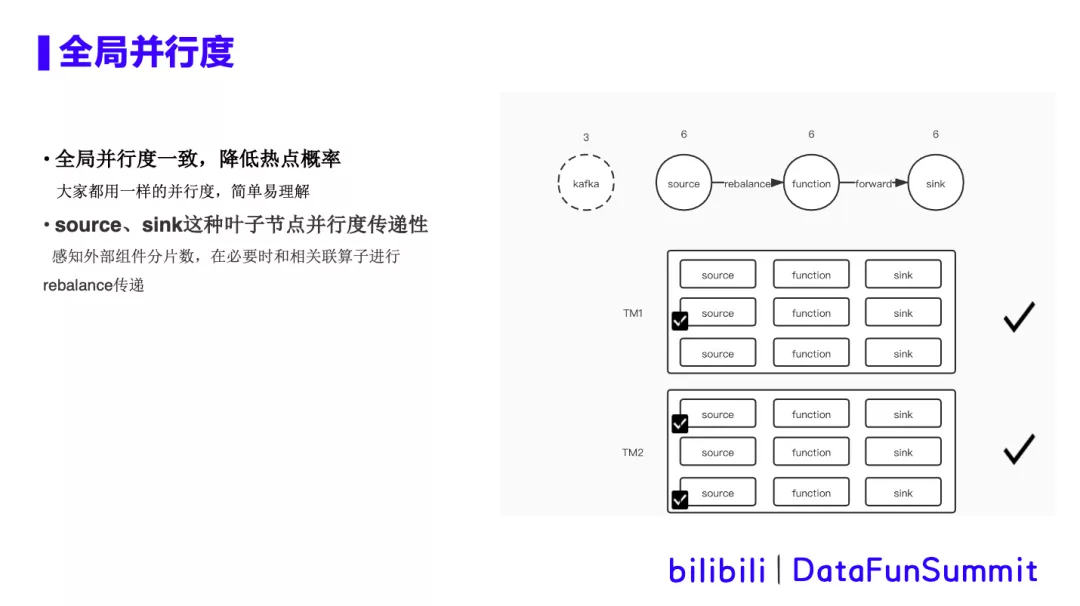
① 仅保留全局并行度概念,屏蔽算子级并行度。
用户只需要设置一个全局并行度即可,从全局来调整资源,易于理解。将算子均分在所有tm,降低cpu热点的概率。尽可能的让多个算子间并行度一致,利用Flink优化,将算子串联在一起,减少序列化和网络开销。
② source、sink这种叶子节点并行度自动感知,并具有传递性。必要时和相关联算子进行rebalance。自动感知的具体策略如下:
- 设置DEFAULT并行度:修改tableInfo当中并发度的默认值为-1,与正常的并发度设置做区分;
- KAFKA topic partition数感知:Kafka sink和source加入检测topic partition个数的逻辑,用于在生成DAG的时候与并发度做比较;
- DAG重启生成逻辑:在DAG最基础的调度单元中增加tpSize(topic partition size)这个属性,用与在DAG调度过程中,针对sink和source算子中不同并发度和tpSize做不同的处理。
3. warship作业智能诊断工具
随着平台作业的日益增多,作业类型愈加复杂化,对作业的运维管理难度越来越大。
大部分用户非资深Flink玩家,在遇到任务挂、checkpoint不成功、堆积、数据不准不符合预期等诸多问题时,无法自主分析解决,这大量消耗了平台值班人员以及用户自身的时间。
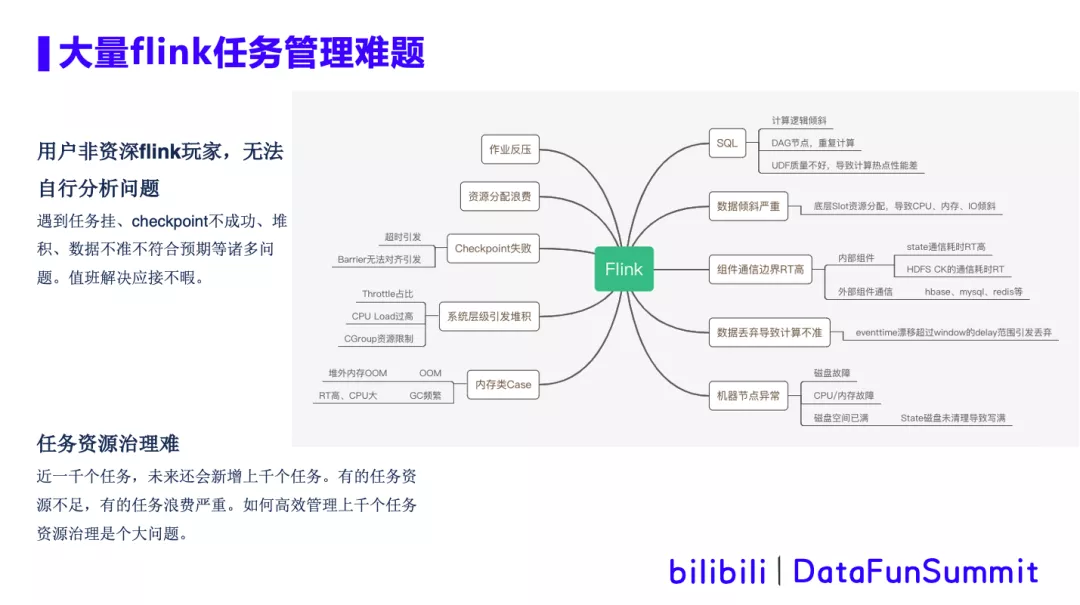
所以我们通过warship这个作业智能诊断工具,来辅助线上作业的半自助化运维。warship智能诊断工具,能够自动收集平台(系统层、应用层)上所有的度量标准,并对收集的数据进行分析,并将分析结果以一种简单且易于理解的形式展示出来。同时可以根据历史监控指标采集,分析出资源不够或者资源浪费的任务,给出资源调整建议,未来做到AutoScale任务自动扩缩容。Warship工具的原理如下图所示:
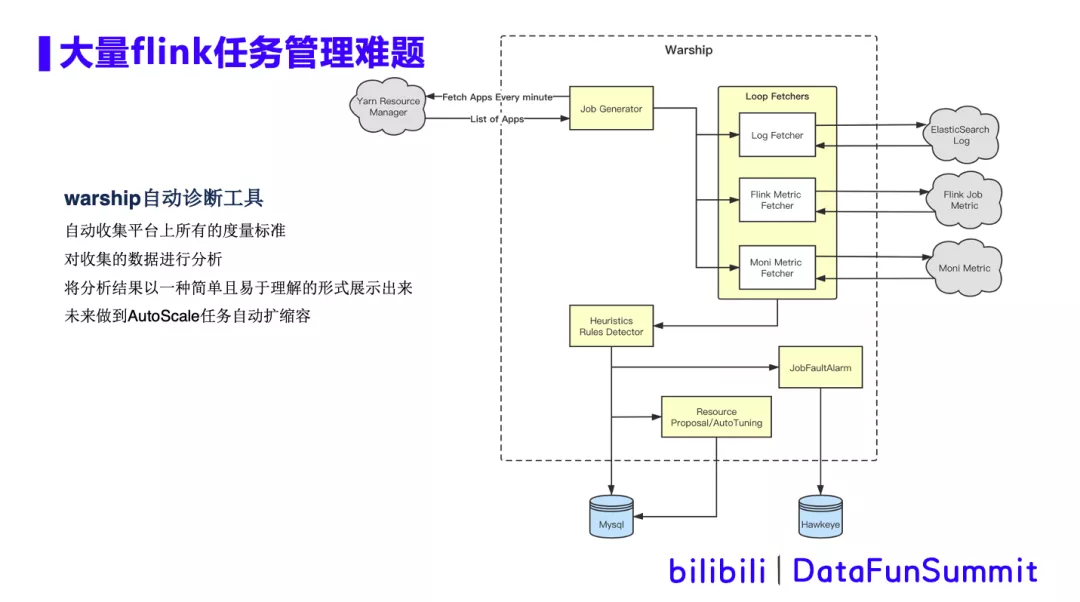
如上图,warship从yarn上获取正在运行的app列表,并采集es日志,Flink任务相关指标 ,以及机器级别指标等。这些采集的数据经过启发式算法规则计算、评分、时间归因或者层级归因后,调用告警平台,输出告警,同时进行自动调整并存入数据库。详细的过程如下图所示:
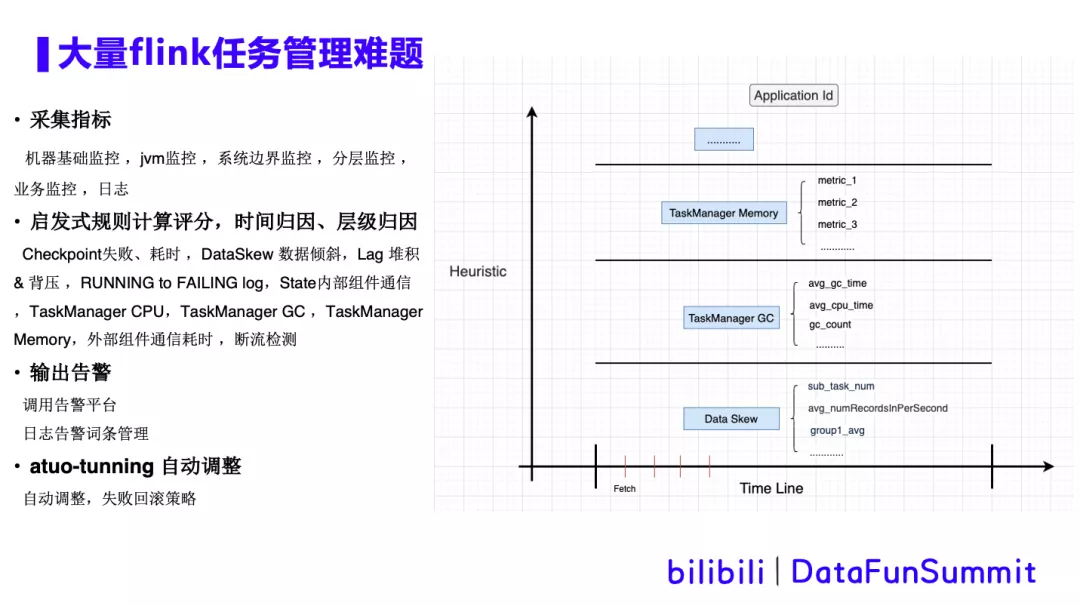
启发式算法介绍: 以checkpoint为例子。取近10次checkpoint,根据失败次数从100分往下扣分。失败的越多扣得越多。checkpoint耗时评分:ck的耗时/超时时间 越接近超时时间,评分越低。
将评分低的检测项根据时间排序,时间相同的根据层级排序,找到根因。
日志告警词条管理: 任务失败的日志中,RUNNING to FAILING 词条是一堆java堆栈信息,内容繁杂,用户分析困难。我们进行了告警词条翻译,将关键词匹配结果放在报警中,一起输出给用户,提供更友好的提示。
自定扩缩容介绍:
① 扩容前判断,是否满足扩容条件,倾斜不满足扩容条件,扩容前后DAG图是否变化,队列是否还有资源,扩容比例判断。
② 提交调整任务,同步等待任务提交结果。
③ 失败回滚,恢复到调整前状态,回滚提交。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9F%BA%E4%BA%8E%E7%9A%84%E4%BC%98%E5%8C%96%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


