基于打造的伴鱼实时计算平台的设计与实现
摘要: 去年开始着手打造伴鱼公司级的实时计算平台,平台代号 Palink,由 Flink + Palfish 组合而来。
在伴鱼发展早期,出现了一系列实时性相关的需求,比如算法工程师期望可以拿到用户的实时特征数据做实时推荐,产品经理希望数据方可以提供实时指标看板做实时运营分析。
这个阶段中台数据开发工程师主要是基于 Spark 实时计算引擎开发作业来满足业务方提出的需求。然而这类作业并没有统一的平台进行管理,任务的开发形式、提交方式、可用性保障等也完全因人而异。
伴随着业务的加速发展,越来越多的实时场景涌现出来,对实时作业的开发效率和质量保障提出了更高的要求。为此,我们从去年开始着手打造伴鱼公司级的实时计算平台,平台代号 Palink,由 Palfish + Flink 组合而来。
之所以选择 Flink 作为平台唯一的实时计算引擎,是因为近些年来其在实时领域的优秀表现和主导地位,同时活跃的社区氛围也提供了非常多不错的实践经验可供借鉴。目前 Palink 项目已经落地并投入使用,很好地满足了伴鱼业务在实时场景的需求。
一、核心原则
通过调研阿里云、网易等各大厂商提供的实时计算服务,我们基本确定了 Palink 的整个产品形态。同时,在系统设计过程中紧紧围绕以下几个核心原则:
- 极简性:保持简易设计,快速落地,不过度追求功能的完整性,满足核心需求为主;
- 高质量:保持项目质量严要求,核心模块思虑周全;
- 可扩展:保持较高的可扩展性,便于后续方案的迭代升级。
二、系统设计
平台整体架构
以下是平台整体的架构示意图:
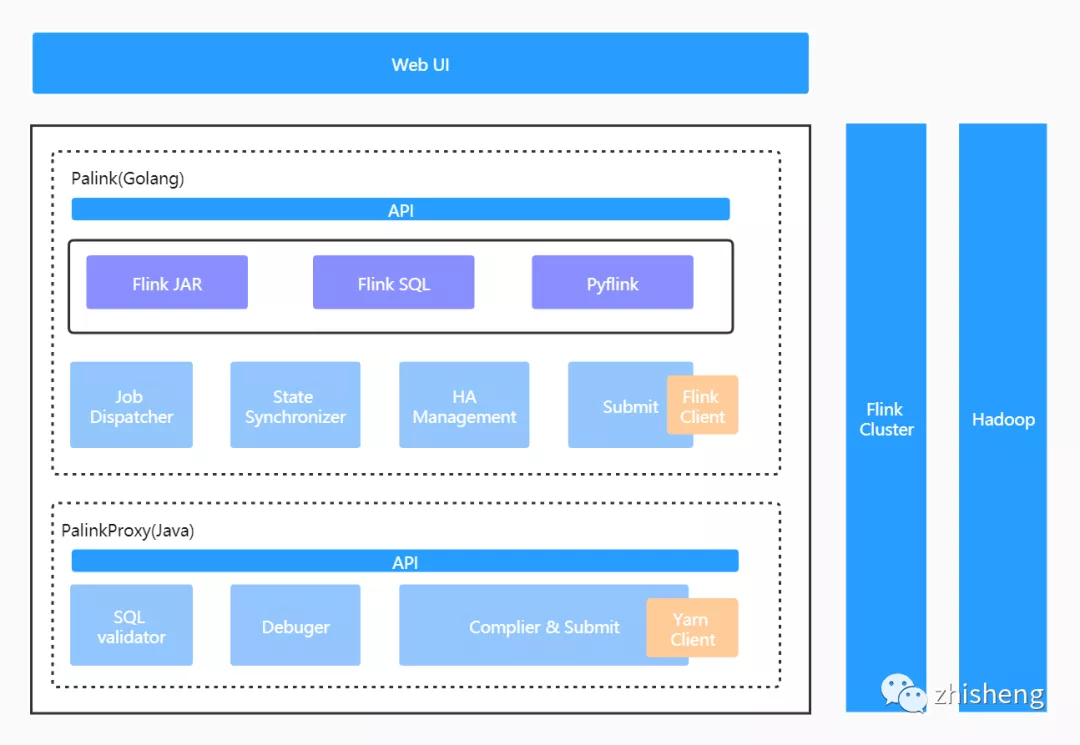
整个平台由四部分组成:
- Web UI:前端操作页面;
- Palink (GO) 服务:实时作业管理服务,负责作业元信息及作业生命周期内全部状态的管理,承接全部的前端流量。包括作业调度、作业提交、作业状态同步及作业 HA 管理几个核心模块;
- PalinkProxy(JAVA) 服务:SQL 化服务,Flink SQL 作业将由此模块编译、提交至远端集群。包括 SQL 语法校验、SQL 作业调试及 SQL 作业编译和提交几个核心模块;
- Flink On Yarn:基于 Hadoop Yarn 做集群的资源管理。
这里之所以将后台服务拆分成两块,并且分别使用 GO 和 JAVA 语言实现,原因主要有三个方面:
- 一是伴鱼拥有一套非常完善的基于 GO 语言实现的微服务基础框架,基于它可以快速构建服务并拥有包括服务监控在内的一系列周边配套,公司目前 95% 以上的服务是基于此服务框架构建的;
- 二是 SQL 化模块是基于开源项目二次开发实现的(这个在后文会做详细介绍),而该开源项目使用的是 JAVA 语言;
- 三是内部服务增加一次远程调用的成本是可以接受的。
这里也体现了我们极简性原则中对快速落地的要求。事实上,以 GO 为核心开发语言是非常具有 Palfish 特色的,在接下来伴鱼大数据系列的相关文章中也会有所体现。
接下来本文将着重介绍 Palink 几个核心模块的设计。
作业调度&执行
后端服务接收到前端创建作业的请求后,将生成一条 PalinkJob 记录和一条 PalinkJobCommand 记录并持久化到 DB,PalinkJobCommand 为作业提交执行阶段抽象出的一个实体,整个作业调度过程将围绕该实体的状态变更向前推进。其结构如下:
type PalinkJobCommand struct {
ID uint64 `json:"id"`
PalinkJobID uint64 `json:"palink_job_id"`
CommandParams string `json:"command_params"`
CommandState int8 `json:"command_state"`
Log string `json:"log"`
CreatedAt int64 `json:"created_at"`
UpdatedAt int64 `json:"updated_at"`
}
这里并没有直接基于 PalinkJob 实体来串联整个调度过程,是因为作业的状态同步会直接作用于这个实体,如果调度过程也基于该实体,两部分的逻辑就紧耦合了。
调度流程
下图为作业调度的流程图:
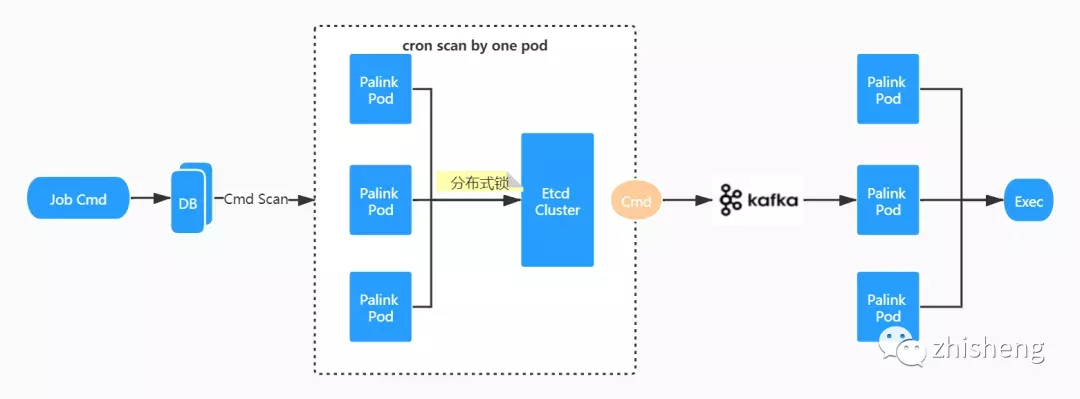
palink pod 异步执行竞争分布式锁操作,保证同一时刻有且仅有一个实例获取周期性监测权限,满足条件的 Command 将直接被发送到 Kafka 待执行队列,同时变更其状态,保证之后不再被调度。此外,所有的 palink pod 将充当待执行队列消费者的角色,并归属于同一个消费者组,消费到消息的实例将获取到最终的执行权。
执行流程
作业的执行实则是作业提交的过程,根据作业类型的不同提交工作流有所区别,可细分为三类:
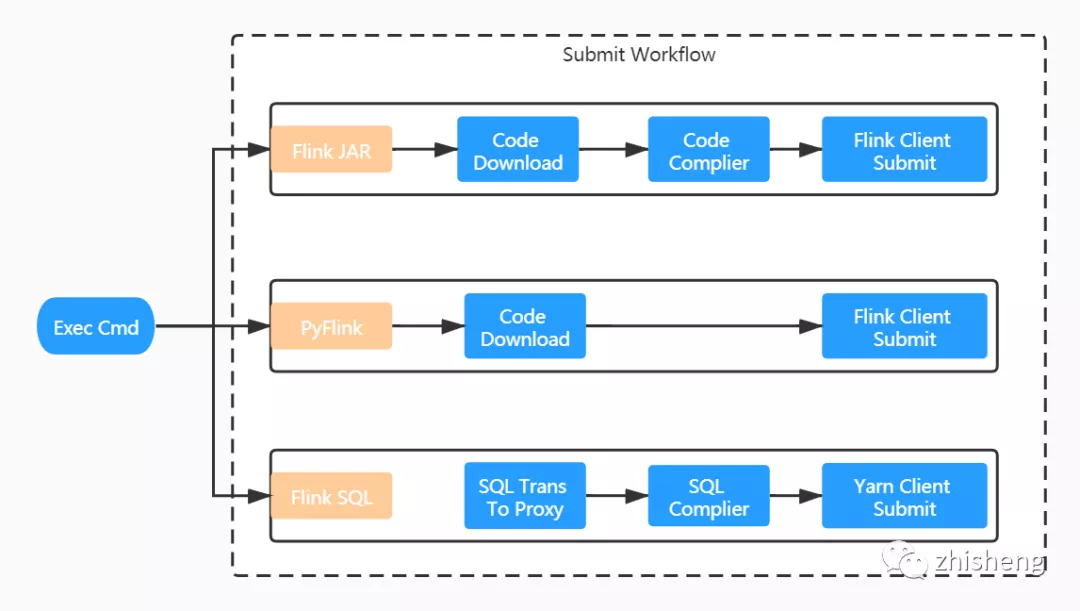
- Flink JAR 作业:我们摒弃了用户直接上传 JAR 文件的交互方式。用户只需提供作业 gitlab 仓库地址即可,打包构建全流程平台直接完成。由于每一个服务实例都内嵌 Flink 客户端,任务是直接通过 Flink run 方式提交的。
- PyFlink 作业:与 Flink JAR 方式类似,少了编译的过程,提交命令也有所不同。
- Flink SQL 作业:与上两种方式区别较大。对于 Flink SQL 作业而言,用户只需提交相对简单的 SQL 文本信息,这个内容我们是直接维护在平台的元信息中,故没有和 gitlab 仓库交互的地方。SQL 文本将进一步提交给 PalinkProxy 服务进行后续的编译,然后使用 Yarn Client 方式提交。
Command 状态机
PalinkJobCommand 的状态流转如下图所示:
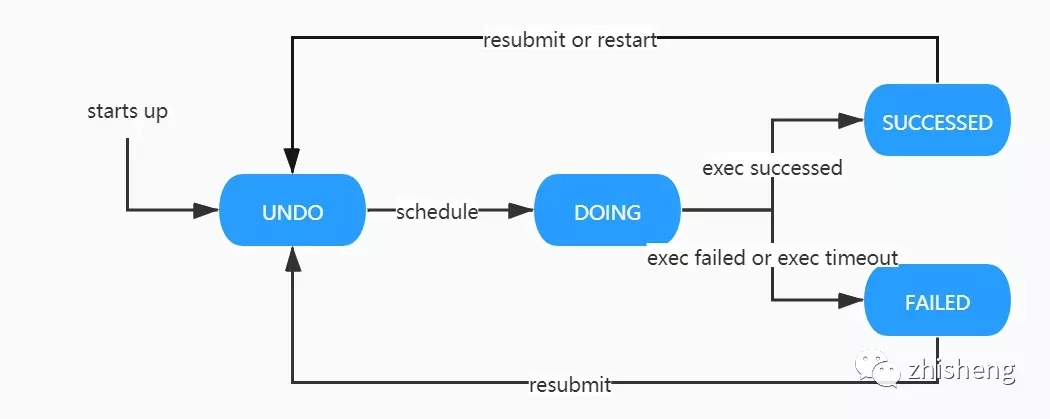
- UNDO:初始状态,将被调度实例监测。
- DOING:执行中状态,同样会调度实例监测,防止长期处于进行中的脏状态产生。
- SUCCESSED:执行成功状态。随着用户的后续行为,如重新提交、重新启动操作,状态会再次回到 UNDO 态。
- FAILED:执行失败状态。同上,状态可能会再次回到 UNDO 态。
作业状态同步
作业成功提交至集群后,由于集群状态的不确定性或者其他的一些因素最终导致任务异常终止了,平台该如何及时感知到?这就涉及到我们即将要阐述的另一个话题 “状态同步“。
状态同步流程
这里首先要回答的一个问题是:同步谁的状态?
有过离线或者 Flink on yarn 开发经验的同学一定知道,作业在部署到 yarn 上之后会有一个 application 与之对应,每一个 application 都有其对应的状态和操作动作,比如我们可以执行 Yarn UI 上 Kill Application 操作来杀掉整个任务。
同样的,当我们翻阅 Flink 官方文档或者进入 Flink UI 页面也都可以看到每一个任务都有其对应的状态和一系列操作行为。最直接的想法肯定是以 Flink 任务状态为准,毕竟这是我们最想拿到的。
但仔细分析,其实二者的状态对于平台而言没有太大区别,只是状态的粒度有所不同而已,yarn application 的状态已经是对 Flink 状态做了一次 state mapping。可是考虑到,Flink 在 HA 的时候,作业对外暴露的 URL 会发生变更,这种情况下只能通过获取作业对应的 application 信息才能拿到最新的地址。
与此同时,一次状态同步的过程不仅仅只是希望拿到最新的状态,对于任务的 checkpoint 等相关信息同样是有同步的诉求。看来二者的信息在一次同步的过程中都需要获取,最终的状态同步设计如下:
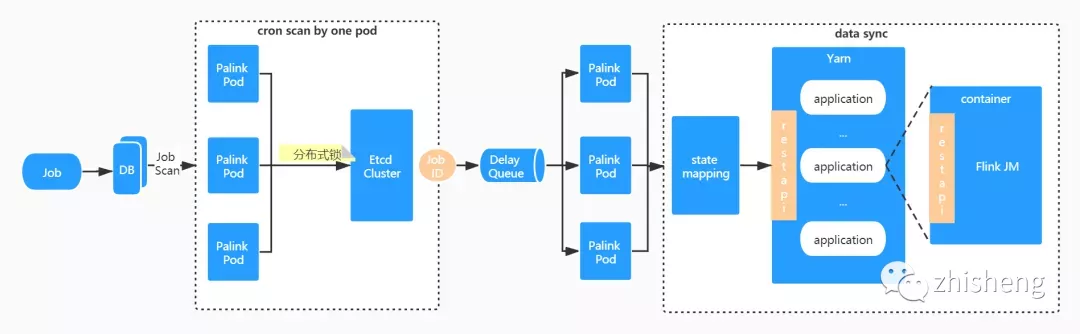
前置流程和作业调度流程类似,有且仅有一个实例负责周期性监测工作,符合条件的 Job ID(注,并非所有的作业都用同步的必要,比如一些处于终态的作业)将发送到内部延迟队列。之所以采用延迟队列而非 Kafka 队列,主要是为了将同一时间点批量同步的需求在一定时间间隔内随机打散,降低同步的压力。最后,在获取到作业的完整信息后,再做一次 state mapping 将状态映射为平台抽象的状态类型。
由于状态同步是周期性进行的,存在一定的延迟。因此在平台获取作业详情时,也会同步触发一次状态同步,保证获取最新数据。
Job 状态机
PalinkJob 的状态流转如下图所示:
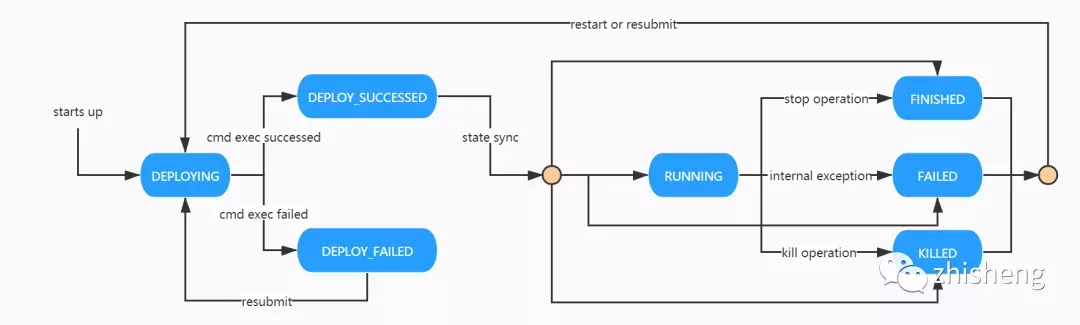
- DEPLOYING:作业初始状态,将随着 PalinkJobCommand 的状态驱动向 DEPLOY_SUCCESSED 和 DEPLOY_FAILED 流转。
- DEPLOY_SUCCESSED:部署成功状态,依赖作业「状态同步」驱动向 RUNNING 状态或者其他终态流转。
- DEPLOY_FAILED:部署失败状态,依赖用户重新提交向 DEPLOYING 状态流转。
- RUNNING:运行中状态。可通过用户执行暂停操作向 FINISHED 状态流转,或执行终止操作向 KILLED 状态流转,或因为内部异常向 FAILED 状态流转。
- FINISHED:完成状态,作业终态之一。通过用户执行暂停操作,作业将回到此状态。
- KILLED:终止状态,作业终态之一。通过用户执行终止操作,作业将回到此状态。
- FAILED:失败状态,作业终态之一。作业异常会转为此状态。
作业 HA 管理
解决了上述问题之后,另一个待讨论的话题便是 “作业 HA 管理”。我们需要回答用户以下的两个问题:
- 作业是有状态的,但是作业需要代码升级,如何处理?
- 作业异常失败了,怎么做到从失败的时间点恢复?
Flink 提供了两种机制用于恢复作业:Checkpoint 和 Savepoint,本文统称为保存点。Savepoint 可以看作是一种特殊的 Checkpoint ,只不过不像 Checkpoint 定期的从系统中生成,它是用户通过命令触发的,用户可以控制保存点产生的时间点。
任务启动时,通过指定 Checkpoint 或 Savepoint 外部路径,就可以达到从保存点恢复的效果。我们对于平台作业 HA 的管理也是基于这两者展开的。下图为管理的流程图:
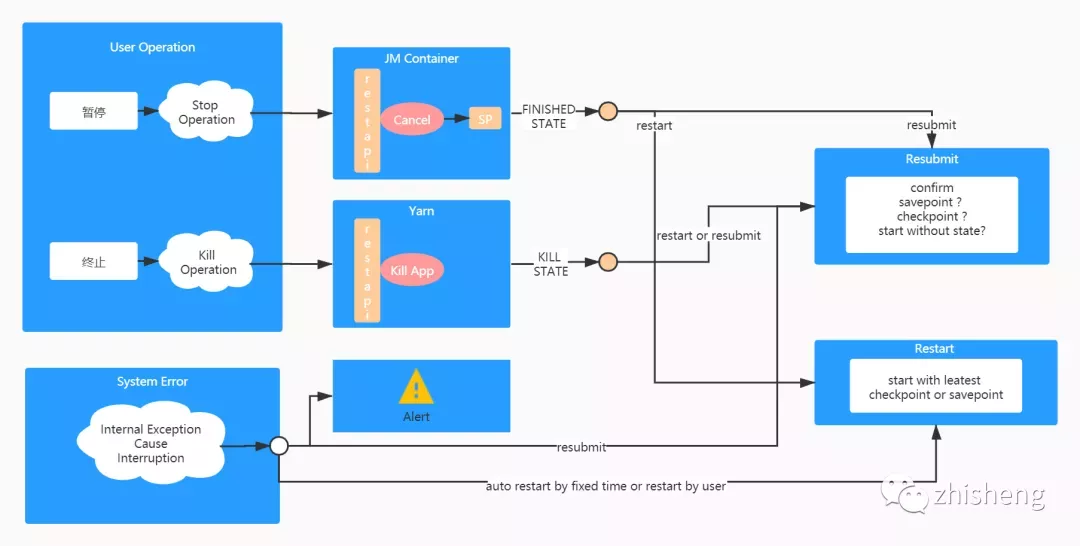
用户有两种方式来手动停止一个作业:暂停和终止。
- 暂停操作通过调用 Flink cancel api 实现,将触发作业生成 Savepoint。
- 终止操作则是通过调用 yarn kill application api 实现,用于快速结束一个任务。
被暂停的作业重启时,系统将比较 Savepoint 和 Checkpoint 的生成时间点,按照最近的一个保存点启动,而当作业被重新提交时,由于用户可能变更了代码逻辑,将直接由用户决定是否按照保存点恢复。对于被终止的作业,无论是重启或者是重新提交,都直接采取由用户决定的方式,因为终止操作本身就带有丢弃作业状态的色彩。
失败状态的作业是由于异常错误被迫停止的。对于这类作业,有三重保障:
- 一是任务自身可以设置重启策略自动恢复,外部平台无感知;
- 二是,对于内部重启依旧失败的任务在平台侧可再次设置上层重启策略;
- 三是,手动重启或重新提交。仅在重新提交时,由用户决定按照那种方式启动,其余场景皆按照最近的保存点启动。
任务 SQL 化
Flink JAR 和 PyFlink 都是采用 Flink API 的形式开发作业,这样的形式必然极大地增加用户的学习成本,影响开发的效率。需要不断输入和培养具有该领域开发技能的工程师,才能满足源源不断的业务需求。
而产品定位不仅仅是面向数据中台的开发工程师们,我们期望可以和离线目标用户保持一致,将目标群体渗透至分析人员乃至业务研发和部分的产品经理,简单的需求完全可以自己动手实现。要达到这个目的,必然开发的形式也要向离线看齐,作业 SQL 化是势在必行的。
我们期望 Flink 可以提供一种类似于 Hive Cli 或者 Hive JDBC 的作业提交方式,用户无需写一行 Java 或 Scala 代码。查阅官方文档,Flink 确实提供了一个 SQL 客户端以支持以一种简单的方式来编写、调试和提交表程序到 Flink 集群,不过截止到目前最新的 release 1.13 版本,SQL 客户端仅支持嵌入式模式,相关的功能还不够健全,另外对于 connector 支持也是有限的。因此,需要寻求一种更稳定、更高可扩展性的实现方案。
经过一番调研后,我们发现袋鼠云开源的「FlinkStreamSQL」基本可以满足我们目前的要求。此项目是基于开源的 Flink 打造的,并对其实时 SQL 进行了扩展,支持原生 Flink SQL 所有的语法。
实现机制
下图为 Flink 官方提供的作业角色流程图,由图可知,用户提交的代码将在 Client 端进行加工、转换(最终生成 Jobgraph )然后提交至远程集群。
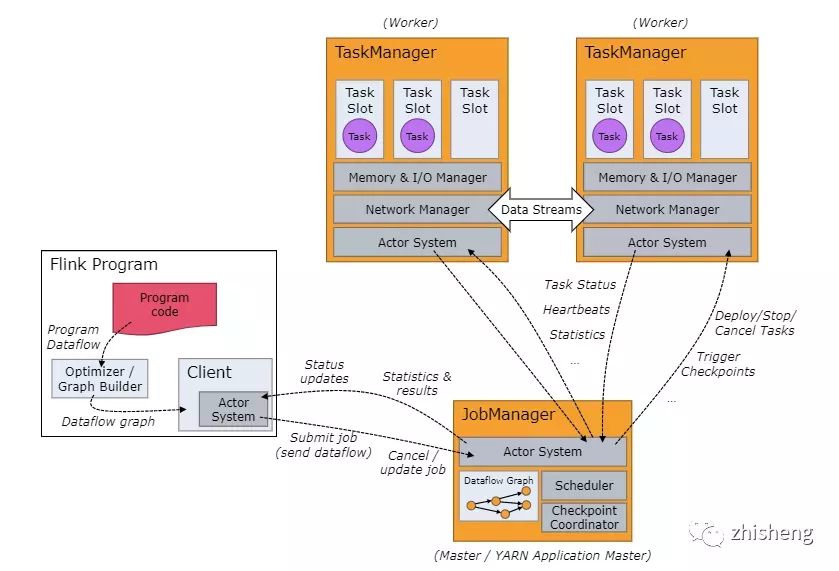
那么要实现用户层面的作业 SQL 化,底层的实现同样是绕不开这个流程。实际上 FlinkStreamSQL 项目就是通过定制化的手段实现了 Client 端的逻辑,可以将整个过程简要地描述为:
构建 PackagedProgram
利用 PackagedProgramUtils 生成 JobGraph。
通过 YarnClusterDescriptor 提交作业。
其中,第一步是最关键的,PackagedProgram 的构造方法如下:
PackagedProgram.newBuilder()
.setJarFile(coreJarFile)
.setArguments(execArgs)
.setSavepointRestoreSettings(savepointRestoreSettings)
.build();
execArgs 为外部输入参数,这里就包含了用户提交的 SQL。而 coreJarFile 对应的就是 API 开发方式时用户提交的 JAR 文件,只不过这里系统帮我们实现了。coreJarFile 的代码对应项目中的 core module,该 module 本质上就是 API 开发方式的一个 template 模板。module 内实现了自定义 SQL 解析以及各类 connector plugin 注入。更多细节可通过开源项目进一步了解。
定制开发
我们基于 FlinkStreamSQL 进行了二次开发,以满足内部更多样化的需求。主要分为以下几点:
- 服务化:整个 SQL 化模块作为 proxy 独立部署和管理,以 HTTP 形式暴露服务;
- 支持语法校验特性;
- 支持调试特性:通过解析 SQL 结构可直接获取到 source 表和 sink 表的结构信息。平台可通过人工构造或线上抓取源表数据的方式得到测试数据集,sink 算子被 localTest connector 算子直接替换,以截取结果数据输出;
- 支持更多的 connector plugin,如 pulsar connector;
- 其他特性。
除了上文提到的一些功能特性,平台还支持了:
- DDL 语句注入
- UDF 管理
- 租户管理
- 版本管理
- 作业监控
- 日志收集
这些点就不在本文详细阐述,但作为一个实时计算平台这些点又是必不可少的。
三、线上效果
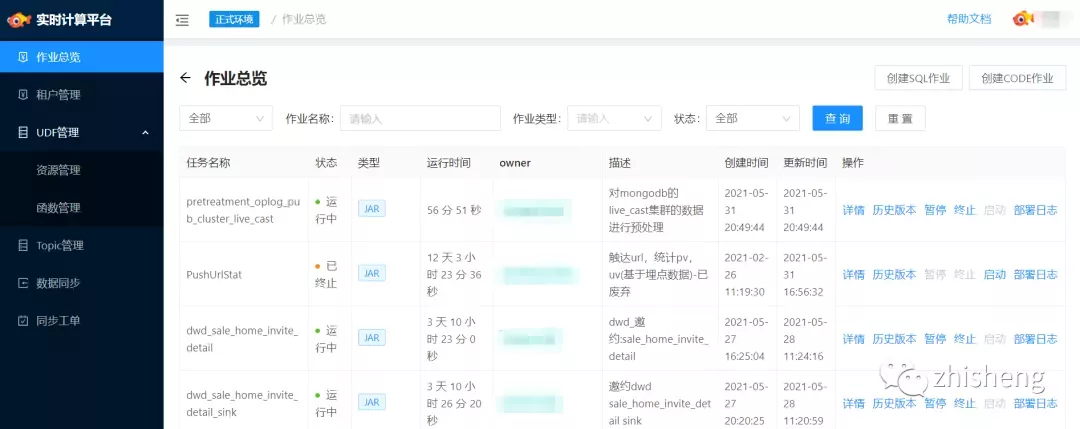
■ 作业总览
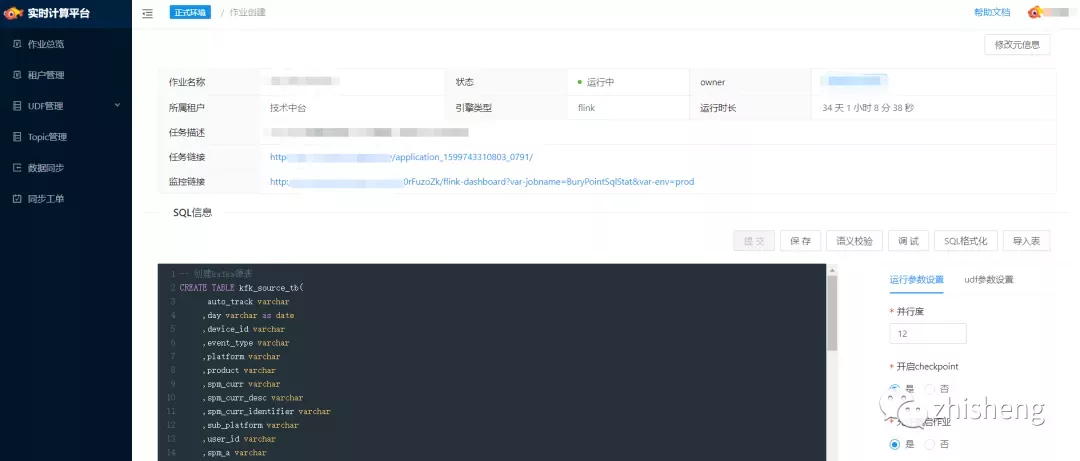
■ 作业详情
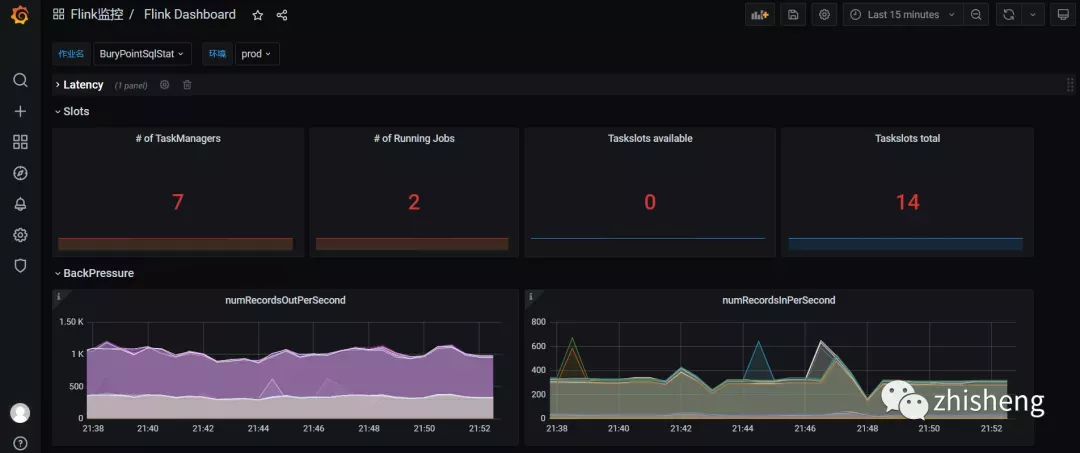
■ 作业监控
四、未来工作
随着业务的继续推进,平台将在以下几方面继续迭代优化:
- 稳定性建设:实时任务的稳定性建设必然是未来工作中的首要事项。作业参数如何设置,作业如何自动调优,作业在流量高峰如何保持稳定的性能,这些问题需要不断探索并沉淀更多的最佳实践;
- 提升开发效率:SQL 化建设。尽管 SQL 化已初具雏形,但开发起来依旧具备一定的学习成本,其中最明显的就是 DDL �
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9F%BA%E4%BA%8E%E6%89%93%E9%80%A0%E7%9A%84%E4%BC%B4%E9%B1%BC%E5%AE%9E%E6%97%B6%E8%AE%A1%E7%AE%97%E5%B9%B3%E5%8F%B0%E7%9A%84%E8%AE%BE%E8%AE%A1%E4%B8%8E%E5%AE%9E%E7%8E%B0/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


