基于强化学习的算法在推荐场景中的应用

文章作者:杨梦月、张露露
导读: 本文是对滴滴 AI Labs 和中科院大学联合提出的 WWW 2020 Research Track 的 Oral 长文 “Hierarchical Adaptive Contextual Bandits for Resource Constraint based Recommendation” 的详细解读。
在这篇文章中,滴滴 AI Labs 提出了一种基于强化学习的层次自适应的多臂老虎机的资源限制下的个性化推荐方法 ( HATCH )。该方法将资源限制下的用户推荐问题建模成一个资源限制下的上下文老虎机问题,并使用层次结构同时达到资源分配策略和个性化推荐策略同时优化的目的。
01 研究背景
多臂老虎机是一个非常典型的决策方法,被广泛的应用于推荐系统中。一般情况下,当多臂老虎机算法观察到系统当中的状态 ( state ) 时,会从候选的多个动作 ( action ) 当中选择一个在环境当中执行,之后得到环境的反馈回报 ( reward )。算法的目标是最大化累计回报,在推荐系统当中,state 一般对应用户上下文,比如用户特征等,action 对应于可供推荐的项目,比如广告,商品等等。reward 一般为用户在得到推荐结果之后的反馈,通常情况下会使用点击率等。多臂老虎机作为一种决策方法,其最重要的就是提供探索 ( exploration ) - 开发 ( exploitation ) 功能。开发是指策略 ( policy ) 采用当前预估出的最佳推荐,探索则是选择更多非最佳策略从而为深入挖掘用户喜好提供了可能性。
本文所考虑的问题是,有些时候推荐行为会在系统中产生资源消耗,该资源消耗会影响策略的表现。比如对于一个成熟的电商网站,一般情况下其每天的流量可以被看作一个定值,如果将流量看作一种资源,那么广告展示的行为就可以看作一种资源消耗。并且这种消耗是单元消耗,即一次推荐产生的资源消耗为 1。资源限制不仅会限制推荐的次数,并且会对探索开发功能产生很大的影响。
目前有很多贪心策略用于资源限制下的上下文多臂老虎机问题,即在训练的时候完全不考虑资源的分配,而采用"有即分配"的方法。该方法会产生比较大的问题,假设系统每天之内有一个资源预算总量,并且该资源总量比一天总共的推荐次数少得多,那么这种方法就会在算法执行的早期花掉所有的资源,从而忽视后来的高质量用户的请求。贪心策略可以被看作"短视"的策略,因为其分配策略不会考虑剩余的资源以及用户信息这种较为高级的信息。但是同时考虑资源分配和用户推荐实际上是一个比较复杂的问题,因为这两种策略在执行过程中会相互影响,从而很难直接得到比较好的策略结果。
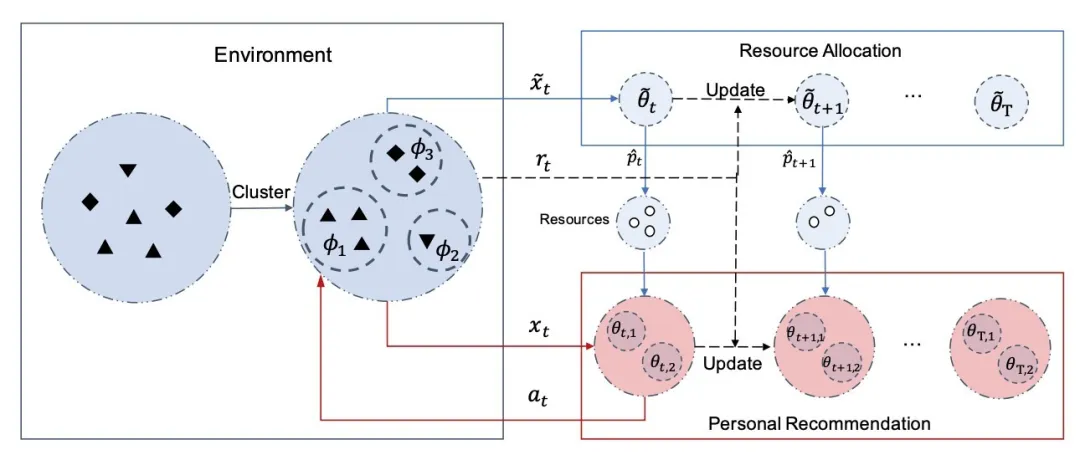
02 基于层次自适应的上下文多臂老虎机方法
本文为了资源分配的长期规划,解决贪心策略的短视问题,提出了一种层次自适应的上下文多臂老虎机方法。该方法能够使用层级结构同时优化资源分配策略与用户个性化推荐策略。该方法分别设置了两层策略,上层策略为资源分配,下层策略为个性化推荐,如上图所示。
1. 目标函数
该方法首先需要做一些预处理,即将系统中存在的大量用户特征信息收集起来,并将其进行聚类,得到不同的用户种类,并得到每个类别出现的概率 ∮ 和类别的特征中心点 x~。这么做的原因是,本文假设了在推荐系统当中,虽然用户反馈会根据推荐策略的不同而产生变化,但是用户的特征在一段时间满足一个固定不变的分布。这个假设使得在学习过程当中,用户类别的概率和类别特征的中心点不会产生变化。
通过这个假设,可以将上下文多臂老虎机的目标函数将最大化累计回报转化为最大化单轮期望回报,设每个类别的用户类别价值为 u,单轮期望回报如下:
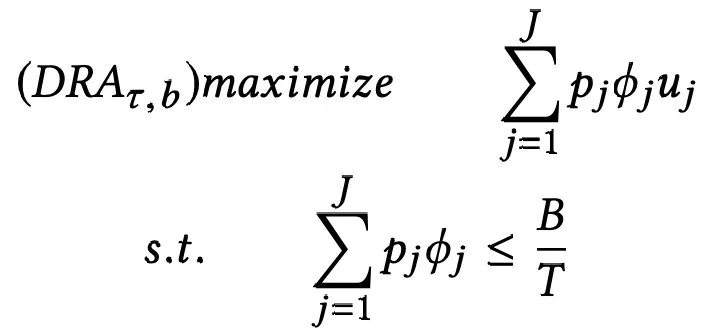
其中 p 表示分配资源的概率,但是由于 u 不能直接获得,所以设计了资源分配层用于估计 u。
2. 资源分配层
设为用户特征集合,为用户反馈集合,则该层在每一轮学习步 t 中,都通过一个线性方程预估出每个用户类别的价值,则存在以下的线性方程。
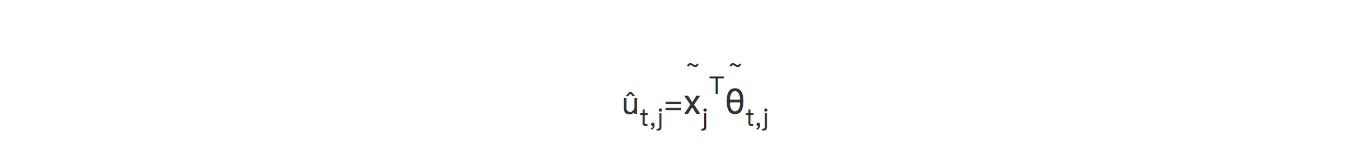
在得到估计用户价值的 û 之后,通过解决一个线性规划问题可以得到资源分配概率,在执行推荐结果之后,使用用户反馈更新该层参数\widetilde θ。
3. 个性化推荐层
该层使用一个标准的上下文多臂老虎机方法作为推荐方法,采用线性方程估计该方法当中基于用户特征的每个推荐项目 action 的预估回报,并采用探索策略进行推荐探索,其策略选择方法遵循下式:
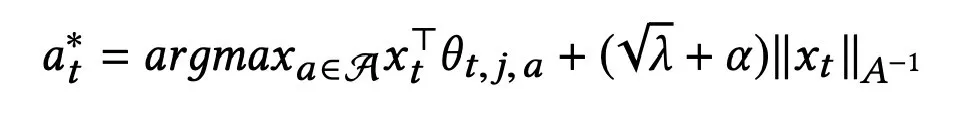
该式子当中第一项为期望回报预估,第二项为置信度,作为探索策略的方法。这种探索策略可以使得较少被执行过的 action 有比仅使用第一项估计产生的被选择概率更大的几率被选择。
在该用户被分配了资源之后,将以该个性化推荐结果进行推荐,并得到用户反馈。得到用户反馈之后,采用以下式更新个性化推荐层的参数:
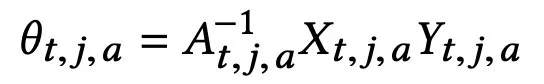
HATCH 的算法流程如下:

03 累计遗憾分析/Cumulative Regret
由于上下文多臂老虎机方法是一种在线学习方法,其没有一个标准的经验损失函数用来更新参数,所以一般情况下会使用累计遗憾的程度来描述模型效果。本文中累计遗憾为:
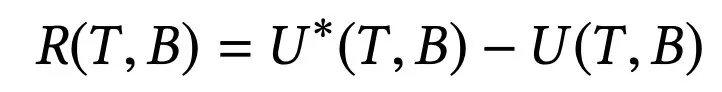
表示真实情况中的最佳回报与算法提供的最佳的 action 真实回报之间的差距。
本文通过证明,得到累计遗憾为
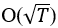 。
。
04 实验结果
本文分别在模拟数据与真实数据上都进行了实验。
模拟实验采用一个模拟数据生成器,该生成器满足线性生成规则,在该实验上分析累计遗憾在不同的实验设置下与基线之间的对比:
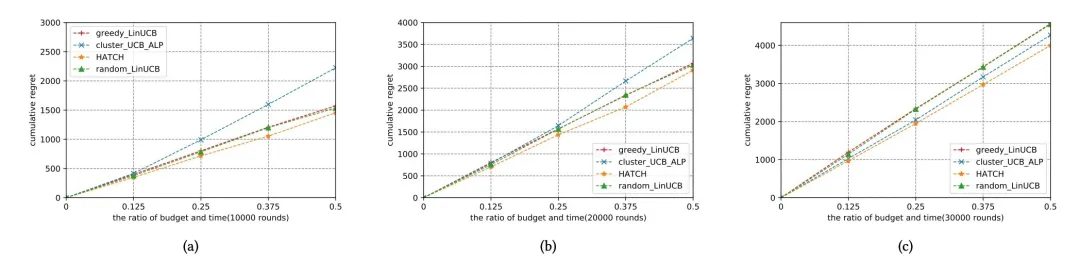
实验结果说明本文提出的 HATCH 能够得到低的累计遗憾。
真实数据采用 Yahoo Today Model 的公开数据集,并筛选出了推荐数量最多的 6 种新闻推荐 action 的 event ( x ( 用户特征 ),a ( 推荐新闻 ),r ( 是否点击 ) ) 进行拒绝采样的离线验证。
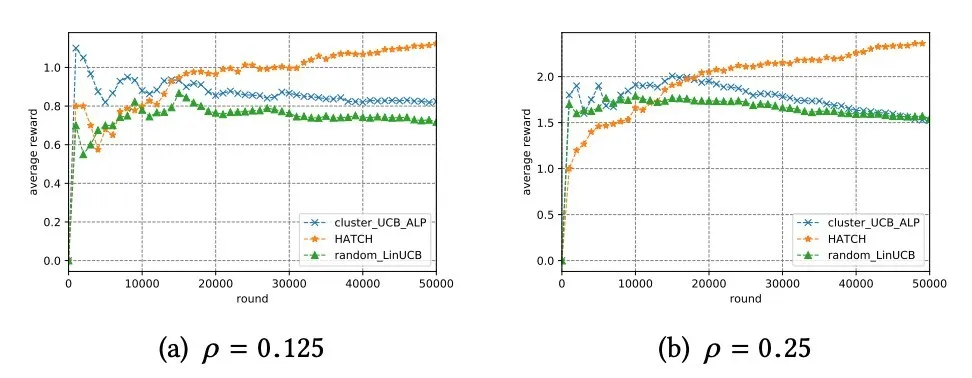
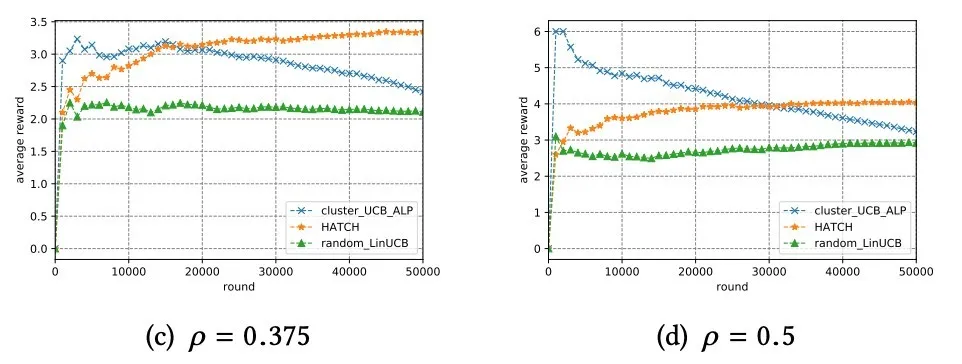
从图中看出,在不同的实验设置下,HATCH 均能达到最佳的平均 CTR。
并且本文分析了探索效果,发现在早期学习过程中,拥有较小估计价值的用户类别,也存在有稍微大的概率被分配资源的情况。说明不仅在个性化推荐层,事实上在资源分配层该算法也具有一定的探索性,这种探索性使得在分配资源的过程中能够首先对用户类别的价值做充分的探索之后才进行开发策略。避免在早期的策略不合适造成整个训练过程策略分布的偏差。
05 结论和下一步计划
滴滴团队指出,该方法虽然能够动态自适应的分配资源,但是真实世界的环境其实在随着时间的变化而变化。所以指出可以将该方法在动态变化的环境�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9F%BA%E4%BA%8E%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%E7%9A%84%E7%AE%97%E6%B3%95%E5%9C%A8%E6%8E%A8%E8%8D%90%E5%9C%BA%E6%99%AF%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


