基于内容的推荐算法
作者丨gongyouliu 欢迎关注他的公众号gongyouliu
作者在上篇文章 《 推荐系统产品与算法概述》 中对推荐算法做了比较全面的概述,本篇开始我们来详细讲解各类推荐算法。这篇文章我们主要关注的是基于内容的推荐算法,它也是非常通用的一类推荐算法,在工业界有大量的应用案例。
本文会从什么是基于内容的推荐算法、算法基本原理、应用场景、基于内容的推荐算法的优缺点、算法落地需要关注的点等5个方面来讲解。
希望读者读完可以掌握常用的基于内容的推荐算法的实现原理,并且可以基于本文的思路快速将基于内容的推荐算法落地到真实业务场景中。
01 什么是基于内容的推荐算法
首先我们给基于内容的推荐算法下一个定义,让读者有初步的印象,后面更容易理解我们讲的基于内容的推荐算法。
所谓基于内容的推荐算法(Content-Based Recommendations)是基于标的物相关信息、用户相关信息及用户对标的物的操作行为来构建推荐算法模型,为用户提供推荐服务。这里的标的物相关信息可以是对标的物文字描述的metadata信息、标签、用户评论、人工标注的信息等。用户相关信息是指人口统计学信息(如年龄、性别、偏好、地域、收入等等)。用户对标的物的操作行为可以是评论、收藏、点赞、观看、浏览、点击、加购物车、购买等。基于内容的推荐算法一般只依赖于用户自身的行为为用户提供推荐,不涉及到其他用户的行为。
广义的标的物相关信息不限于文本信息,图片、语音、视频等都可以作为内容推荐的信息来源,只不过这类信息处理成本较大,不光是算法难度大、处理的时间及存储成本也相对更高。
基于内容的推荐算法算是最早应用于工程实践的推荐算法,有大量的应用案例,如今日头条的推荐有很大比例是基于内容的推荐算法。
02 基于内容的推荐算法实现原理
基于内容的推荐算法的基本原理是根据用户的历史行为,获得用户的兴趣偏好,为用户推荐跟他的兴趣偏好相似的标的物,读者可以直观上从下图理解基于内容的推荐算法。
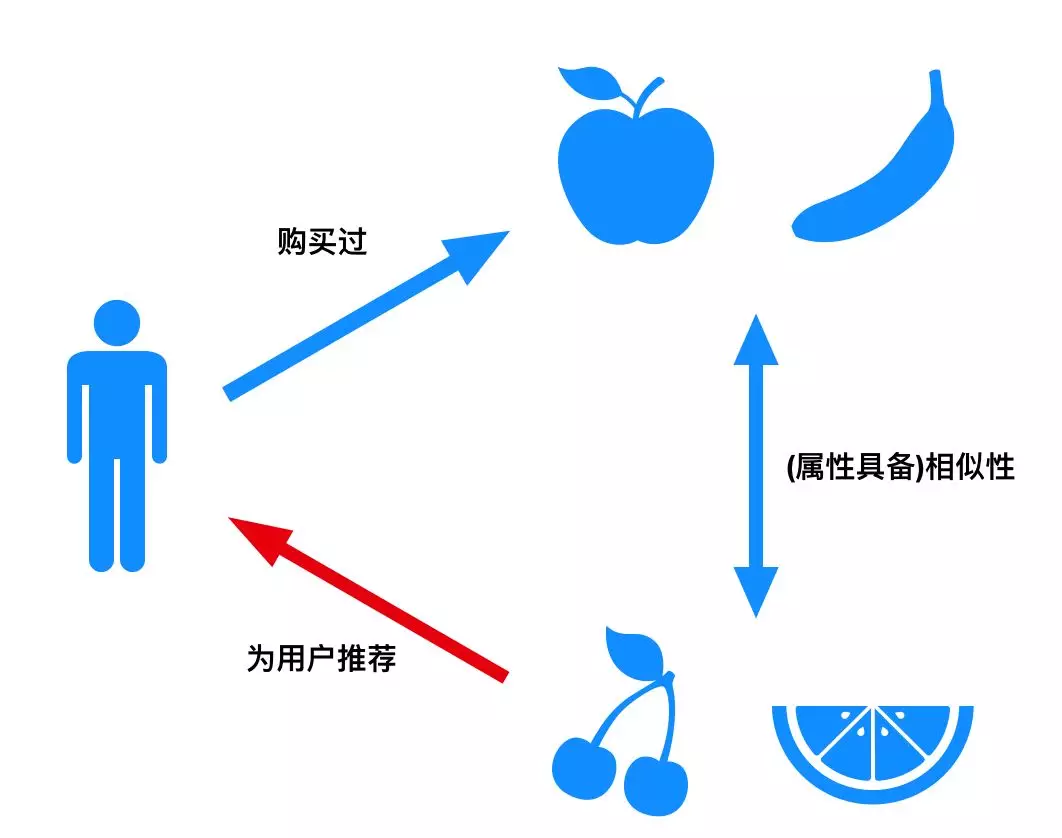
图1:基于内容的推荐算法示意图
从上图也可以看出,要做基于内容的个性化推荐,一般需要三个步骤,它们分别是:基于用户信息及用户操作行为构建用户特征表示、基于标的物信息构建标的物特征表示、基于用户及标的物特征表示为用户推荐标的物,具体参考图2:
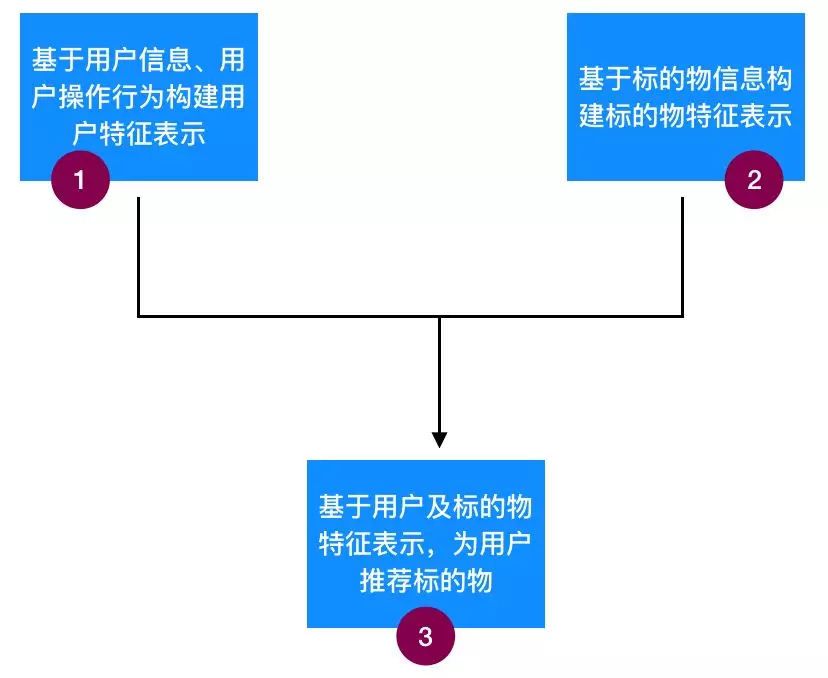
图2:基于内容的个性化推荐的三个核心步骤
本节我们先简单介绍一下怎么基于上图的步骤1、步骤2为用户做推荐(即步骤3中给用户做推荐的核心思想),然后分别对这三个步骤加以说明,介绍每个步骤都有哪些方法和策略可供选择。
1. 基于用户和标的物特征为用户推荐的核心思想
有了用户特征和标的物特征,我们怎么给用户做推荐呢?我认为主要的推荐思路有如下三个:
(1)基于用户历史行为记录做推荐
我们需要事先计算标的物之间的相似性,然后将用户历史记录中的标的物的相似标的物推荐给用户。
不管标的物包含哪类信息,一般的思路是将标的物特征转化为向量化表示,有了向量化表示,我们就可以通过cosine余弦相似度计算两个标的物之间的相似度了。
(2)用户和标的物特征都用显式的标签表示,利用该表示做推荐
标的物用标签来表示,那么反过来,每个标签就可以关联一组标的物,那么根据用户的标签表示,用户的兴趣标签就可以关联到一组标的物,这组通过标签关联到的标的物,就可以作为给用户的推荐候选集。这类方法就是所谓的倒排索引法,是搜索业务通用的解决方案。
(3)用户和标的物嵌入到同一个向量空间,基于向量相似做推荐
当用户和标的物嵌入到同一个向量空间中后,我们就可以计算用户和标的物之间的相似度,然后按照标的物跟用户的相似度,为用户推荐相似度高的标的物。还可以基于用户向量表示计算用户相似度,将相似用户喜欢的标的物推荐给该用户,这时标的物嵌入是不必要的。
讲清楚了基于内容的推荐的核心思想,那么下面我们分别讲解怎么表示用户特征、怎么表示标的物特征以及怎么为用户做推荐。
2. 构建用户特征表示
用户的特征表示可以基于用户对标的物的操作行为(如点击、购买、收藏、播放等)构建用户对标的物的偏好画像,也可以基于用户自身的人口统计学特征来表达。有了用户特征表示,我们就可以基于用户特征为用户推荐与他特征匹配的标的物。构建用户特征的方法主要有如下5种:
(1)用户行为记录作为显示特征
记录用户过去一段时间对标的物的偏好。拿视频行业来说,如果用户过去一段时间看了A、B、C三个视频,同时可以根据每个视频用户观看时长占视频总时长的比例给用户的行为打分,这时用户的兴趣偏好就可以记录为
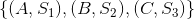 ,其中S1、S2、S3分别是用户对视频A、B、C的评分。
,其中S1、S2、S3分别是用户对视频A、B、C的评分。
该方案直接将用户历史操作过的标的物作为用户的特征表示,在推荐时可以将与用户操作过的标的物相似的标的物推荐给用户。
(2)显式的标签特征
如果标的物是有标签来描述的,那么这些标签可以用来表征标的物。用户的兴趣画像也可以基于用户对标的物的行为来打上对应的标签。拿视频推荐来举例,如果用户过去看了科幻和恐怖两类电影,那么恐怖、科幻就是用户的偏好标签了。
每个标的物的标签可以是包含权重的,而用户对标的物的操作行为也是有权重的,从而用户的兴趣标签是有权重的。
在具体推荐时,可以将用户的兴趣标签关联到的标的物(具备该标签的标的物)推荐给用户。
(3)向量式的兴趣特征
可以基于标的物的信息将标的物嵌入到向量空间中,利用向量来表示标的物,我们会在后面讲解嵌入的算法实现方案。有了标的物的向量化表示,用户的兴趣向量就可以用他操作过的标的物的向量的平均向量来表示了。
这里表示用户兴趣向量有很多种策略,可以基于用户对操作过的标的物的评分以及时间加权来获取用户的加权偏好向量,而不是直接取平均。另外,我们也可以根据用户操作过的标的物之间的相似度,为用户构建多个兴趣向量(比如对标的物聚类,用户在某一类上操作过的标的物的向量均值作为用户在这个类别上的兴趣向量),从而更好地表达用户多方位的兴趣偏好。
有了用户的兴趣向量及标的物的兴趣向量,可以基于向量相似性计算用户对标的物的偏好度,再基于偏好度大小来为用户推荐标的物。
(4)通过交互方式获取用户兴趣标签
很多APP在用户第一次注册时让用户选择自己的兴趣标签,一旦用户勾选了自己的兴趣标签,那么这些兴趣标签就是系统为用户提供推荐的原材料。具体推荐策略与上面的(3)一样。
(5)用户的人口统计学特征
用户在登陆、注册时提供的关于自身相关的信息、通过运营活动用户填写的信息、通过用户行为利用算法推断得出的结论,如年龄、性别、地域、收入、爱好、居住地、工作地点等是非常重要的信息。基于这些关于用户维度的信息,我们可以将用户特征用向量化表示出来,向量的维度就是可获取的用户特征数。
有了用户特征向量就可以计算用户相似度,将相似用户喜欢的标的物推荐给该用户。
3. 构建标的物特征表示
标的物的特征,一般可以利用显式的标签来表示,也可以利用隐式的向量(当然one-hot编码也是向量表示,但是不是隐式的)来刻画,向量的每个维度就是一个隐式的特征项。前面提到某些推荐算法需要计算标的物之间的相似度,下面我们在讲标的物的各种特征表示时,也简单介绍一下标的物之间的相似度计算方法。顺便说一下,标的物关联标的物的推荐范式也需要知道标的物之间的相似度。下面我们从4个方面来详细讲解怎么构建标的物的特征表示。
(1)标的物包含标签信息
最简单的方式是将将标签按照某种序排列,每个标签看成一个维度,那么每个标的物就可以表示成一个N维的向量了(N是标签的个数),如果标的物包含某个标签,向量在相应标签的分量上的值为1,否则为0,即所谓的one-hot编码。有可能N非常大(如视频行业,N可能是几万、甚至几十万上百万),这时向量是稀疏向量(一般标的物只有少量的几个或者几十个标签),我们可以采用稀疏向量的表示来优化向量存储和计算,提升效率。有了标的物基于标签的向量化表示,很容易基于cosine余弦计算相似度了。
实际上标签不是这么简单的,有很多业务标签是分级的,比如电商(如淘宝),有多级的标签(见下面图3),标签的层级关系形成一颗树状结构,这时该怎么向量化呢?最简单的方案是只考虑叶子节点的标签(也是最低层级的标签),基于叶子节点标签构建向量表示。更复杂的方法,可以基于层级结构构建标签表示及计算标的物相似度。
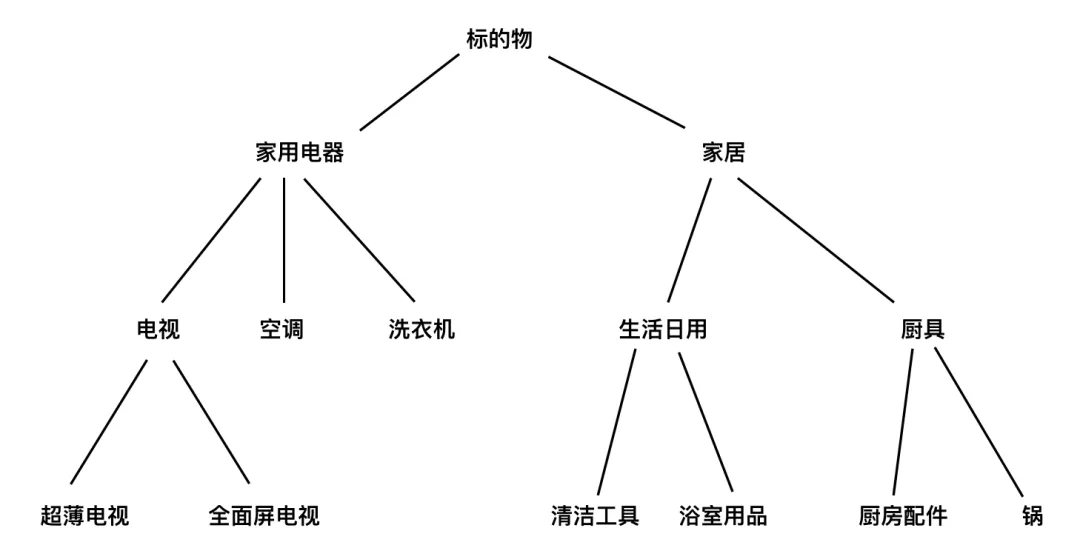
图3:标签的层级表示关系
标签可以是通过算法获取的,比如通过NLP技术从文本信息中提取关键词作为标签。对于图片/视频,它们的描述信息(标题等)可以提取标签,另外可以通过目标检测的方法从图片/视频中提取相关对象构建标签。
标签可以是用户打的,很多产品在用户与标的物交互时可以为标的物打标签,这些标签就是标的物的一种刻画。标签也可是人工标注的,像Netflix在做推荐时,请了上万个专家对视频从上千个维度来打标签,让标签具备非常高的质量。基于这么精细优质的标签做推荐,效果一定不错。很多行业的标的物来源于第三方提供商,他们在入驻平台时会被要求按照某些规范填写相关标签信息(比如典型的如电商)。
(2)标的物具备结构化的信息
有些行业标的物是具备结构化信息的,如视频行业,一般会有媒资库,媒资库中针对每个节目会有标题、演职员、导演、标签、评分、地域等维度数据,这类数据一般存在关系型数据库中。这类数据,我们可以将一个字段(也是一个特征)作为向量的一个维度,这时向量化表示每个维度的值不一定是数值,但是形式还是向量化的形式,即所谓的向量空间模型(Vector Space Model,简称VSM)。这时我们可以通过如下的方式计算两个标的物之间的相似度。
假设两个标的物的向量表示分别为:
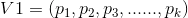
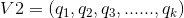
这时这两个标的物的相似性可以表示为:
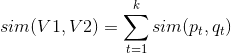
其中代表的是向量的两个分量之间的相似度。可以采用Jacard相似度等各种方法计算两个分量之间的相似度。上面公式中还可以针对不同的分量采用不同的权重策略,见下面公式,其中是第t个分量(特征)的权重,具体权重的数值可以根据对业务的理解来人工设置,或者利用机器学习算法来训练学习得到。
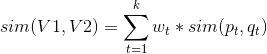
(3)包含文本信息的标的物的特征表示
像今日头条和手机百度APP这类新闻资讯或者搜索类APP,标的物就是一篇篇的文章(其中会包含图片或者视频),文本信息是最重要的信息形式,构建标的物之间的相似性有很多种方法。下面对常用的方法做一些讲解说明。
a. 利用TF-IDF将文本信息转化为特征向量
TF-IDF通过将所有文档(即标的物)分词,获得所有不同词的集合(假设有M个词),那么就可以为每个文档构建一个M维(每个词就是一个维度)的向量,而该向量中某个词所在维度的值可以通过统计每个词在文档中的重要性来衡量,这个重要性的度量就是TF-IDF。下面我们来详细说明TF-IDF是怎么计算的。
TF即某个词在某篇文档中出现的频次,用于衡量这个词在文档中的重要性,出现次数越多的词重要性越大,当然我们会提前将“的”、“地”、“啊”等停用词去掉,这些词对构建向量是没有任何实际价值的,甚至是有害的。TF具体计算公式如下,tk 是第k个词,dj 是第j个文档,下式中分子是 tk 在中出现的次数,分母是 dj 中词的总个数。
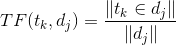
IDF代表的是某个词在所有文档中的“区分度”,如果某个词只在少量几个文档中出现,那么它包含的价值就是巨大的(所谓物以稀为贵),如果某个词在很多文档中出现,那么它就不能很好地衡量(区分出)这个文档。下面是IDF的计算公式,其中N是所有文档的个数,是包含词的文档个数,这个公式刚好跟前面的描述是一致的:稀有的词区分度大。
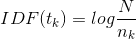
有了上面对TF和IDF的定义,实际的TF-IDF就是上面两个量的乘积:
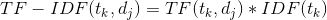
有了基于TF-IDF计算的标的物的向量表示,我们就很容易计算两个标的物之间的相似度了(cosine余弦相似度)。
b. 利用LDA算法构建文章(标的物)的主题
LDA算法是一类文档主题生成模型,包含词、主题、文档三层结构,是一个三层的贝叶斯概率模型。对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess):
[1] 对每一篇文档,从主题分布中抽取一个主题;
[2] 从上述被抽到的主题所对应的单词分布中抽取一个单词;
[3] 重复上述过程直至遍历文档中的每一个单词。
我们通过对所有文档进行LDA训练,就可以构建每篇文档的主题分布,从而构建一个基于主题的向量(每个主题就是向量的一个分量,而值就是该主题的概率值),这样我们就可以利用该向量来计算两篇文档的相似度了。主题模型可以理解为一个降维过程,将文档的词向量表示降维成主题的向量表示(主题的个数是远远小于词的个数的,所以是降维)。想详细了解LDA的读者可以看参考文献1、2。
c. 利用doc2vec算法构建文本相似度
doc2vec或者叫做 paragraph2vec, sentence embeddings,是一种非监督式算法,可以获得 句子、段落、文章的稠密向量表达,它是 word2vec 的拓展,2014年被Google的两位大牛提出,并大量用于文本分类和情感分析中。通过doc2vec学出句子、段落、文章的向量表示,可以通过计算向量之间距离来表达句子、段落、文章之间的相似性。
这里我们简单描述一下doc2vec的核心思想。doc2vec受word2vec启发,由它推广而来,我们先来简单解释一下word2vec的思路。
word2vec通过学习一个唯一的向量表示每个词,每个词向量作为矩阵W中的一列(W是所有词的词向量构成的矩阵),矩阵列可以通过词汇表为每个词做索引,排在索引第一位的放到矩阵W的第一列,如此类推。将学习问题转化为通过上下文词序列中前几个词来预测下一个词。具体的模型框架如下图:
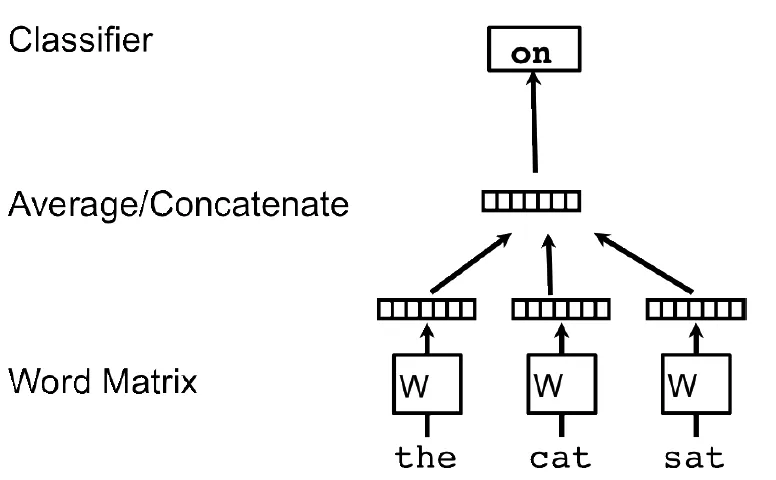
图4:word2vec算法框架
(图片来源于参考文献5)
简单来说,给定一个待训练的词序列,词向量模型通过极大化平均对数概率
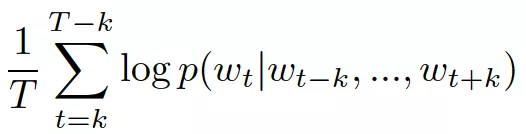
将预测任务通过softmax变换看成一个多分类问题
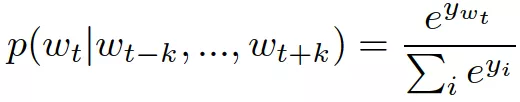
上式中是词i的归一化的对数概率,具体用下式来计算,其中U、b是参数,h是通过词向量的拼接或者平均来构建的
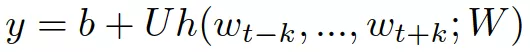
word2vec算法随机初始化词向量,通过随机梯度下降法来训练神经网络模型,最终得到每个词的向量表示。
doc2vec类似地,每个段落/文档表示为向量,作为矩阵D的一列,每个词也表示为一个向量,作为矩阵W中的一列。将学习问题转化为通过上下文词序列中前几个词和段落/文档来预测下一个词。将段落/文档和词向量通过拼接或者平均来预测句子的下一个词(下图是通过“the”、“cat”、“sat”及段落id来预测下一个词“on”)。在训练的时候我们固定上下文的长度,用滑动窗口的方法产生训练集。段落向量/句向量在上下文中共享。
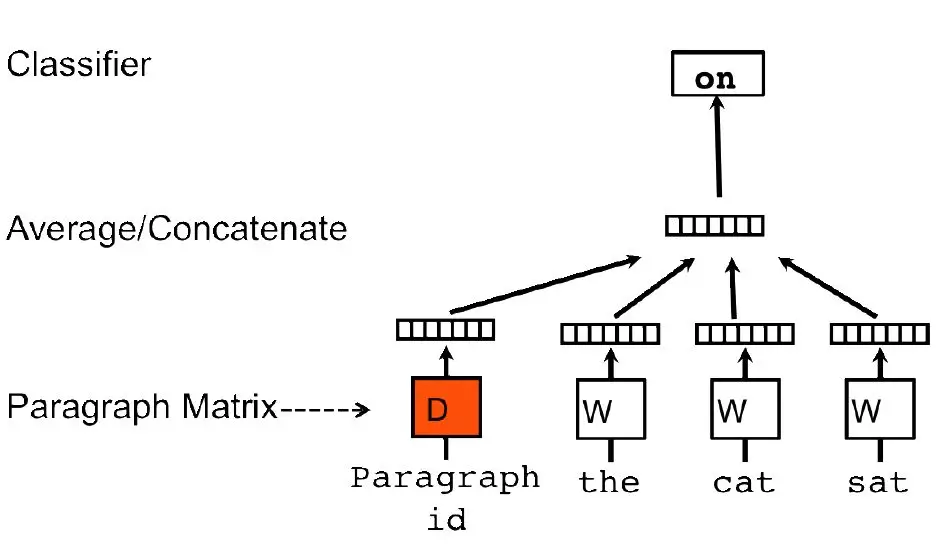
图5:doc2vec模型结构
(图片来源于参考文献5)
对算法原理感兴趣的读者可以看看参考文献3、4、5。工程实现上有很多开源框架有word2vec或者doc2vec的实现,比如gensim中就有很好的实现,作者公司就用gensim来做word2vec嵌入用于相似视频的推荐业务中,效果非常不错,读者可以参考 https://radimrehurek.com/gensim/models/doc2vec.html。
(4)图片、音频、或者视频信息
如果标的物包含的是图片、音频或者视频信息,处理起来会更加复杂。一种方法是利用它们的文本信息(标题、评论、描述信息、利用图像技术提取的字幕等文本信息等等,对于音频,可以通过语音识别转化为文本)采用上面(3)的技术方案获得向量化表示。对于图像或者视频,也可以利用openCV中的PSNR和SSIM算法来表示视频特征,也可以计算视频之间的相似度。另外一种可行的方法是采用图像、音频处理技术直接从图像、视频、音频中提取特征进行向量化表示,从而容易计算出相似度。总之,图片、图像、音频都可以转化为NLP问题或者图像处理问题(见下面图6),通过图像处理和NLP获得对应的特征表示,从而最终计算出相似度,这里不详细讲解。
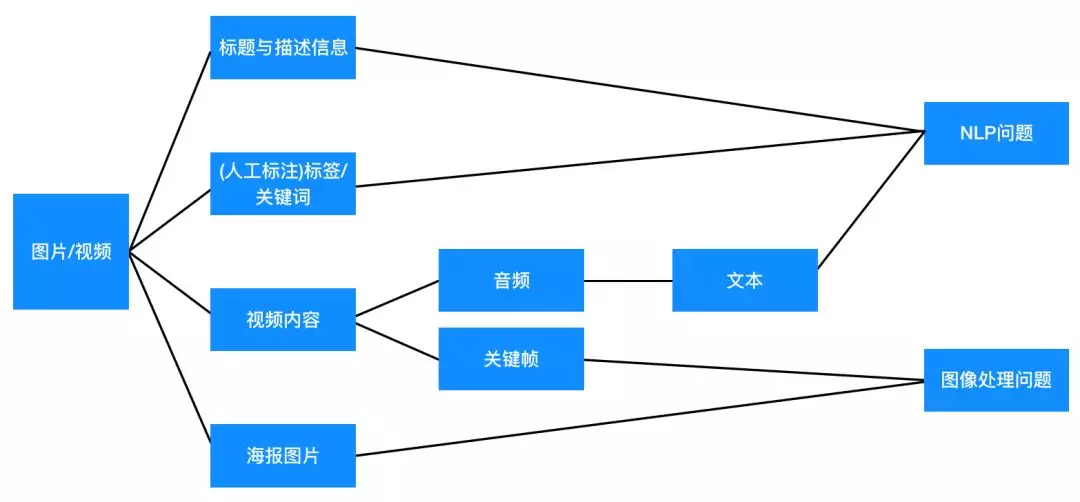
图6:视频/图片问题都可以转化为
NLP或图像处理问题
4. 为用户做个性化推荐
有了上面用户和标的物的特征表示,剩下就是基于此为用户做个性化推荐了,一般有5种方法和策略,下面我们来一一讲解。这里的推荐就是完全个性化范式的推荐,为每个用户生成不一样的推荐结果。
(1)采用跟基于物品的协同过滤类似的方式推荐
该方法采用基于用户行为记录的显式特征表示用户特征,通过将用户操作过的标的物最相似的标的物推荐给用户,算法原理跟基于物品的协同过滤类似,计算公式甚至是一样的,但是这里计算标的物相似度是基于标的物的自身信息来计算的,而基于物品的协同过滤是基于用户对标的物的行为矩阵来计算的。
用户u对标的物s的喜好度sim(u,s)可以采用如下公式计算,其中U是所有用户操作过的标的物的列表,是用户u对标的物的喜好度,是标的物与s的相似度。
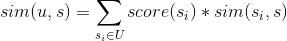
有了用户对每个标的物的相似度,基于相似度降序排列,就可以取topN推荐给用户了。
除了采用上面的公式外,我们在推荐时也可以稍作变化,采用最近邻方法(K-NearestNeighbor, KNN)。对于用户操作/喜欢过的每个标的物,通过kNN找到最相似的k个标的物。
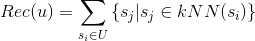
其中是给用户u的推荐,是标的物最近邻(最相似)的k个标的物。
(2)采用跟基于用户协同过滤类似的方法计算推荐
如果我们获得了用户的人口统计学向量表示或者基于用户历史操作行为获得了用户的向量化表示,那么我们可以采用跟基于用户的协同过滤方法相似的方法来为用户提供个性化推荐,具体思路如下:
我们可以将与该用户最相似的用户喜欢的标的物推荐给该用户,算法原理跟基于用户的协同过滤类似,计算公式甚至是一样的。但是这里计算用户相似度是基于用户的人口统计学特征向量表示来计算的(计算用户向量cosine余弦相似度)或者是基于用户历史行为嵌入获得的特征向量来计算的,而基于用户的协同过滤是基于用户对标的物的行为矩阵来计算用户之间的相似度。
用户u对标的物s的喜好度sim(u,s)可以采用如下公式计算,其中U是与该用户最相似的用户集合,是用户对标的物s的喜好度,是用户与用户u的相似度。
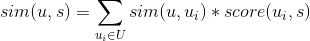
有了用户对每个标的物的相似度,基于相似度降序排列,就可以取topN推荐给用户了。
与前面一样我们也可以采用最近邻方法(K-NearestNeighbor, KNN)。通过kNN找到最相似的k个用户,将这些用户操作/喜欢过的每个标的物推荐给用户。
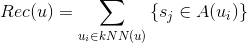
其中是给用户u的推荐,是用户相似的k个用户。是用户操作/喜欢过的标的物的集合。
(3)基于标的物聚类的推荐
有了标的物的向量表示,我们可以用kmeans等聚类算法将标的物聚类,有了标的物的聚类,推荐就好办了。从用户历史行为中的标的物所在的类别挑选用户没有操作行为的标的物推荐给用户,这种推荐方式是非常直观自然的。电视猫的个性化推荐就采用了类似的思路。具体计算公式如下,其中是给用户u的推荐,H是用户的历史操作行为集合,Cluster(s)是标的物s所在的聚类。
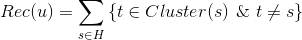
(4)基于向量相似的推荐
不管是前面提到的用户的显示的兴趣特征(利用标签来衡量用户兴趣)或者是向量式的兴趣特征(将用户的兴趣投影到向量空间),我们都可以获得用户兴趣的向量表示。
如果我们获得了用户的向量表示和标的物的向量表示,那么我们就可以通过向量的cosine余弦相似度计算用户与标的物之间的相似度。一样地,有了用户对每个标的物的相似度,基于相似度降序排列,就可以取topN推荐给用户了。
基于向量的相似的推荐,需要计算用户向量与每个标的物向量的相似性。如果标的物数量较多,整个计算过程还是相当耗时的。同样地,计算标的物最相似的K个标的物,也会涉及到与每个其他的标的物计算相似度,也是非常耗时的。整个计算过程的时间复杂度是,其中N是标的物的总个数。
上述复杂的计算过程可以利用Spark等分布式计算平台来加速计算。对于T+1级(每天更新一次推荐结果)的推荐服务,利用Spark事先计算好,将推荐结果存储起来供前端业务调用是可以的。
另外一种可行的策略是利用高效的向量检索库,在极短时间(一般几毫秒或者几十毫秒)内为用户索引出topN最相似的标的物。目前FaceBook开源的FAISS库( https://github.com/facebookresearch/faiss)就是一个高效的向量搜索与聚类库,可以在毫秒级响应查询及聚类需求,因此可以用于个性化的实时推荐。目前国内有很多公司将该库用到了推荐业务上。
FAISS库适合稠密向量的检索和聚类,所以对于利用LDA、Doc2vector算法构建向量表示的方案是实用的,因为这些方法构建的是稠密向量。而对于TF-IDF及基于标签构建的向量化表示,就不适用了,这两类方法构建的都是稀疏的高维向量。
(5)基于标签的反向倒排索引做推荐
该方法在《推荐系统产品与算法概述》这篇文章中也简单做了介绍,这里再简单说一下,并且给出具体的计算公式。基于标的物的标签和用户的历史兴趣,我们可以构建出用户基于标签兴趣的画像及标签与标的物的倒排索引查询表(熟悉搜索的同学应该不难理解)。基于该反向索引表及用户的兴趣画像,我们就可以为用户做个性化推荐了。该类算法其实就是基于标签的召回算法。
具体推荐过程是这样的(见下面图7):从用户画像中获取用户的兴趣标签,基于用户的兴趣标签从倒排索引表中获取该标签对应的标的物,这样就可以从用户关联到标的物了。其中用户的每个兴趣标签及标签关联到的标的物都是有权重的。
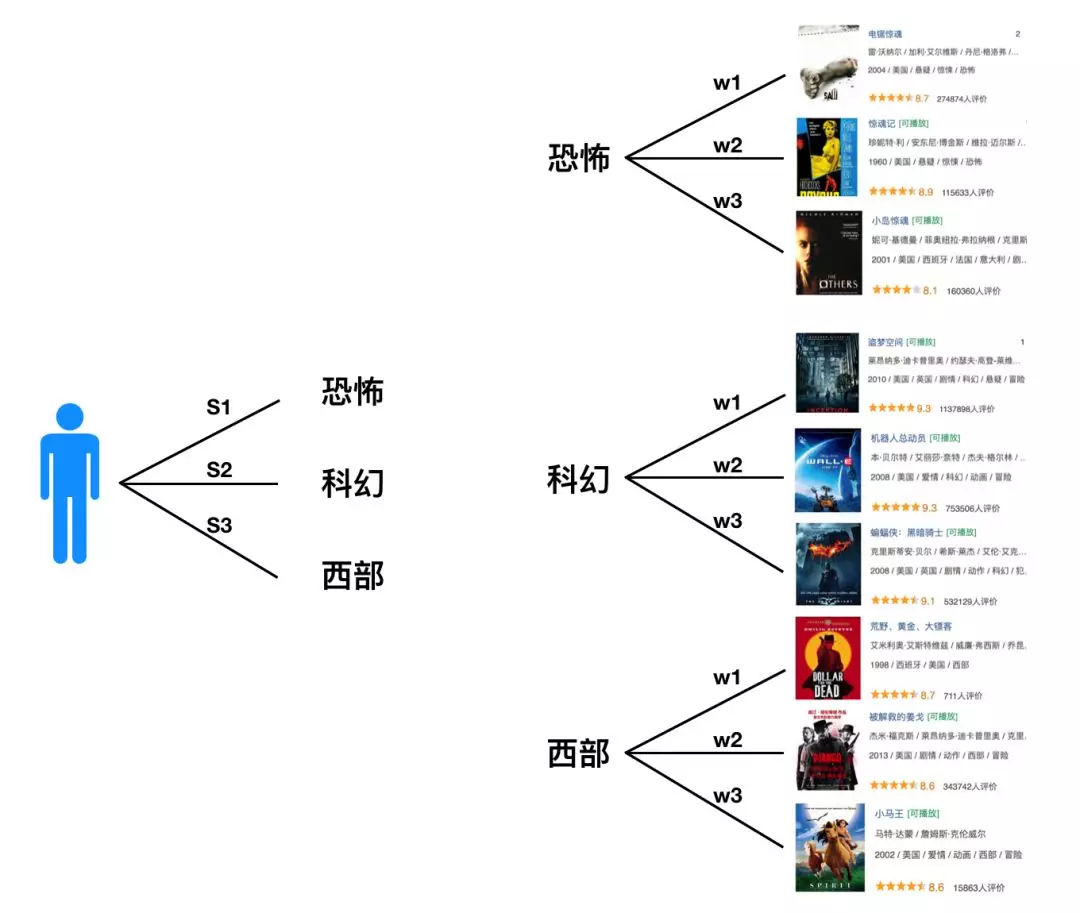
图7:基于倒排索引的电影推荐
假设用户的兴趣标签及对应的标签权重如下,其中是标签,是用户对标签的偏好权重。
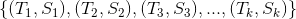
假设标签关联的标的物分别为
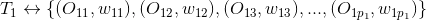
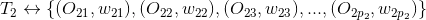
……
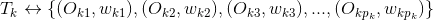
其中、分别是标的物及对应的权重,那么
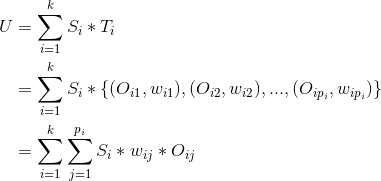
上式中U是用户对标的物的偏好集合,我们这里将标的物看成向量空间的基,所以有上面的公式。不同的标签可以关联到相同的标的物(因为不同的标的物可以有相同的标签),上式中最后一个等号右边需要合并同类项,将相同基前面的系数相加。合并同类项后,标的物(基)前面的数值就是用户对该标的物的偏好程度了,我们对这些偏好程度降序排列,就可以为用户做topN推荐了。
到此我们介绍完了基于内容的推荐算法的核心原理,那么这些算法是怎么应用到真实的产品中的呢?有哪些可行的推荐产品形态?这就是下节的主要内容。
03 基于内容的推荐算法应用场景
基于内容的推荐是最古老的一类推荐算法,在整个推荐系统发展史上具有举足轻重的地位。虽然它的效果可能没有协同过滤及新一代推荐算法好,但是它们还是非常有应用价值的,甚至是必不可少的。基于内容的推荐算法主要用在如下几类场景。
1. 完全个性化推荐
就是基于内容特征来为每个用户生成不同的推荐结果,我们常说的推荐系统就是指这类推荐形态。上面一节第四部分已经完整地讲解了怎么为用户做个性化推荐,这里不再赘述。
2. 标的物关联标的物推荐
标的物关联标的物的推荐也是工业界最常用的推荐形态,大量用于真实产品中。
上一节第三部分讲了很多怎么构建标的物之间相似度的方法,其实这些方法可以直接用来做标的物关联标的物的推荐,只要我们将与某个标的物最相似的topN的标的物作为关联推荐即可。
3. 配合其他推荐算法
由于基于内容的推荐算法在精准度上不如协同过滤等算法,但是可以更好的适应冷启动,所以在实际业务中基于内容的推荐算法会配合其他算法一起服务于用户,最常用的方法是采用级联的方式,先给用户协同过滤的推荐结果,如果该用户行为少没有协同过滤推荐结果,就为该用户推荐基于内容的推荐算法产生的推荐结果。
4. 主题推荐
如果我们有标的物的标签信息,并且基于标签系统构建了一套推荐算法,那么我们就可以将用户喜欢的标签采用主题的方式推荐给用户,每个主题就是用户的一个兴趣标签。通过一些列主题的罗列展示,让用户从中筛选自己感兴趣的内容(见下面图8)。Netflix的首页大量采用基于主题的推荐模式。主题推荐的好处是可以将用户所有的兴趣点按照兴趣偏好大小先后展示出来,可解释性强,并且让用户有更多维度的自由选择空间。
当然,在真实产品中可以采用比下面图8这种简单标签直接展示更好的方式。具体来说,我们可以为每个标签通过人工编辑生成一句更有表达空间的话(如武侠标签,可以采用“江湖风云再起,各大门派齐聚论剑”这样更有深度的表述),具体前端展示时映射到人工填充的话而不是直接展示原来的标签。
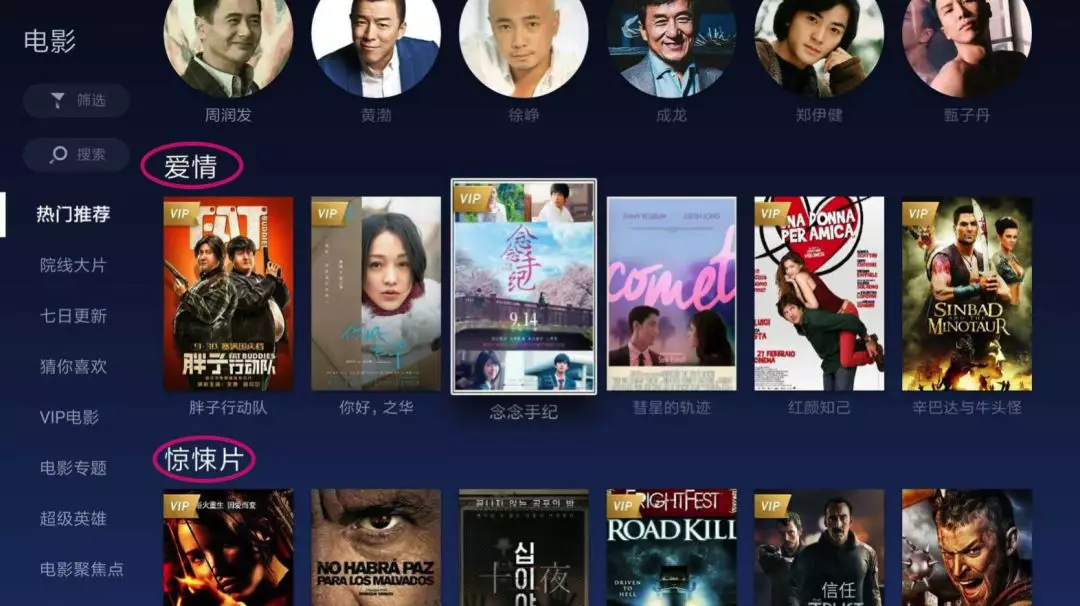
图8:电视猫主题推荐(红色圈圈中就是基于标签的用户兴趣)
5. 给用户推荐标签
另外一种可行的推荐策略是不直接给用户推荐标的物,而是给用户推荐标签,用户通过关注推荐的标签,自动获取具备该标签的标的物。除了可以通过推荐的标签关联到标的物获得直接推荐标的物类似的效果外,间接地通过用户对推荐的标签的选择、关注进一步获得了用户的兴趣偏好,这是一种可行的推荐产品实现方案。
04 基于内容的推荐算法的优势与缺点
基于内容的推荐算法算是一类比较直观易懂的算法,目前在工业级推荐系统中有大量的使用场景,在本节我们对基于内容的推荐算法的优缺点加以说明,方便读者在实践中选择取舍,构建适合业务场景的内容推荐系统。
1. 优点
基于上面的介绍,基于内容的推荐算法是非常直观的,具体来说,它有如下6个优点。
(1)可以很好的识别用户的口味\\\**
该算法完全基于用户的历史兴趣来为用户推荐,推荐的标的物也是跟用户历史兴趣相似的,所以推荐的内容一定是符合用户的口味的。
(2)非常直观易懂,可解释性强
基于内容的推荐算法基于用户的兴趣为用户推荐跟他兴趣相似的标的物,原理简单,容易理解。同时,由于是基于用户历史兴趣推荐跟兴趣相似的标的物,用户也非常容易接受和认可。
(3)可以更加容易的解决冷启动
只要用户有一个操作行为,就可以基于内容为用户做推荐,不依赖其他用户行为。同时对于新入库的标的物,只要它具备metadata信息等标的物相关信息,就可以利用基于内容的推荐算法将它分发出去。因此,对于强依赖于UGC内容的产品(如抖音、快手等),基于内容的推荐可以更好地对标的物提供方进行流量扶持。
(4)算法实现相对简单
基于内容的推荐可以基于标签维度做推荐,也可以将标的物嵌入向量空间中,利用相似度做推荐,不管哪种方式,算法实现较简单,有现成的开源的算法库供开发者使用,非常容易落地到真实的业务场景中。
(5)对于小众领域也能有比较好的推荐效果
对于冷门小众的标的物,用户行为少,协同过滤等方法很难将这类内容分发出去,而基于内容的算法受到这种情况的影响相对较小。
(6)非常适合标的物快速增长的有时效性要求的产品
对于标的物增长很快的产品,如今日头条等新闻资讯类APP,基本每天都有几十万甚至更多的标的物入库,另外标的物时效性也很强。新标的物一般用户行为少,协同过滤等算法很难将这些大量实时产生的新标的物推荐出去,这时就可以采用基于内容的推荐算法更好地分发这些内容。
2. 缺点
虽然基于内容的推荐实现相对容易,解释性强,但是基于内容的推荐算法存在一些不足,导致它的效果及应用范围受到一定限制。主要的问题有如下4个:
(1)推荐范围狭窄,新颖性不强\\\**
由于该类算法只依赖于单个用户的行为为用户做推荐,推荐的结果会聚集在用户过去感兴趣的标的物类别上,如果用户不主动关注其他类型的标的物,很难为用户推荐多样性的结果,也无法挖掘用户深层次的潜在兴趣。特别是对于新用户,只有少量的行为,为用户推荐的标的物较单一。
(2)需要知道相关的内容信息且处理起来较难
内容信息主要是文本、视频、音频,处理起来费力,相对难度较大,依赖领域知识。同时这些信息更容易有更大概率含有噪音,增加了处理难度。另外,对内容理解的全面性、完整性及准确性会影响推荐的效果。
(3)较难将长尾标的物分发出去
基于内容的推荐需要用户对标的物有操作行为,长尾标的物一般操作行为非常少,只有很少用户操作,甚至没有用户操作。由于基于内容的推荐只利用单个用户行为做推荐,所以更难将它分发给更多的用户。
(4)推荐精准度不太高
基于工业界的实践经验,相比协同过滤算法,基于内容的推荐算法精准度要差一些。
05 算法落地需要关注的重要问题
基于内容的推荐算法虽然容易理解,实现起来相对简单,但在落地到真实业务场景中,有很多问题需要思考解决。下面这些问题是在落地基于内容推荐算法时必须思考的,这里将他们列举出来,并提供一些简单的建议,希望可以帮到读者。
1. 内容来源的获取
对于基于内容的推荐来说,有完整的、高质量的内容信息是可以构建精准的推荐算法的基础,那我们有哪些方法可以获取内容来源呢?下面这些策略是主要获取内容(包括标的物内容和用户相关内容)来源的手段。
(1)标的物“自身携带”的信息
标的物在上架时,第三方会准备相关的内容信息,如天猫上的商品在上架时会补充很多必要的信息。对于视频来说,各类metadata信息也是视频入库时需要填充的信息。我们要做的是增加对新标的物入库的监控和审核,及时发现信息不全的情况并做适当处理。
(2)通过爬虫获取标的物相关信息
通过爬虫爬取的信息可以作为标的物信息的补充,特别是补充上面(1)不全的信息。有了更完整的信息就可以获得更好的特征表示。
(3)通过人工标注数据
往往人工标注的数据价值密度高,通过人工精准的标注可以大大提升算法推荐的精准度。但是人工标注成本太大。
(4)通过运营活动或者产品交互让用户填的内容
通过抽奖活动让用户填写家庭组成、兴趣偏好等,在用户开始注册时让用户填写兴趣偏好特征,这些都是获取内容的手段。
(5)通过收集用户行为直接获得或者预测推断出的内容
通过请求用户GPS位置知道用户的活动轨迹,用户购物时填写收货地址,用户绑定的身份证和银行卡等,通过用户操作行为预测出用户的兴趣偏好,这些方法都可以获得部分用户数据。
(6)通过与第三方合作或者产品矩阵之间补充信息
目前中国有大数据交易市场,通过正规的数据交易或者跟其他公司合作,在不侵犯用户隐私的情况下,通过交换数据可以有效填补自己产品上缺失的数据。
如果公司有多个产品,新产品可以借助老产品的巨大用户基数,将新产品的用户与老产品用户关联起来(id-maping或者账号打通),这样老产品上丰富的用户行为信息可以赋能给新产品。
2. 怎么利用负反馈
用户对标的物的操作行为不一定代表正向反馈,有可能是负向的。比如点开一个视频,看了不到几秒就退出来了,明显表明用户不喜欢。有很多产品会在用户交互中直接提供负向反馈能力,这样可以收集到更多负向反馈。下面是今日头条和百度APP推荐的文章,右下角有一个小叉叉(见下面图9中红色圈圈),点击后展示上面的白色交互区域,读者可以勾选几类不同的负向反馈机制。
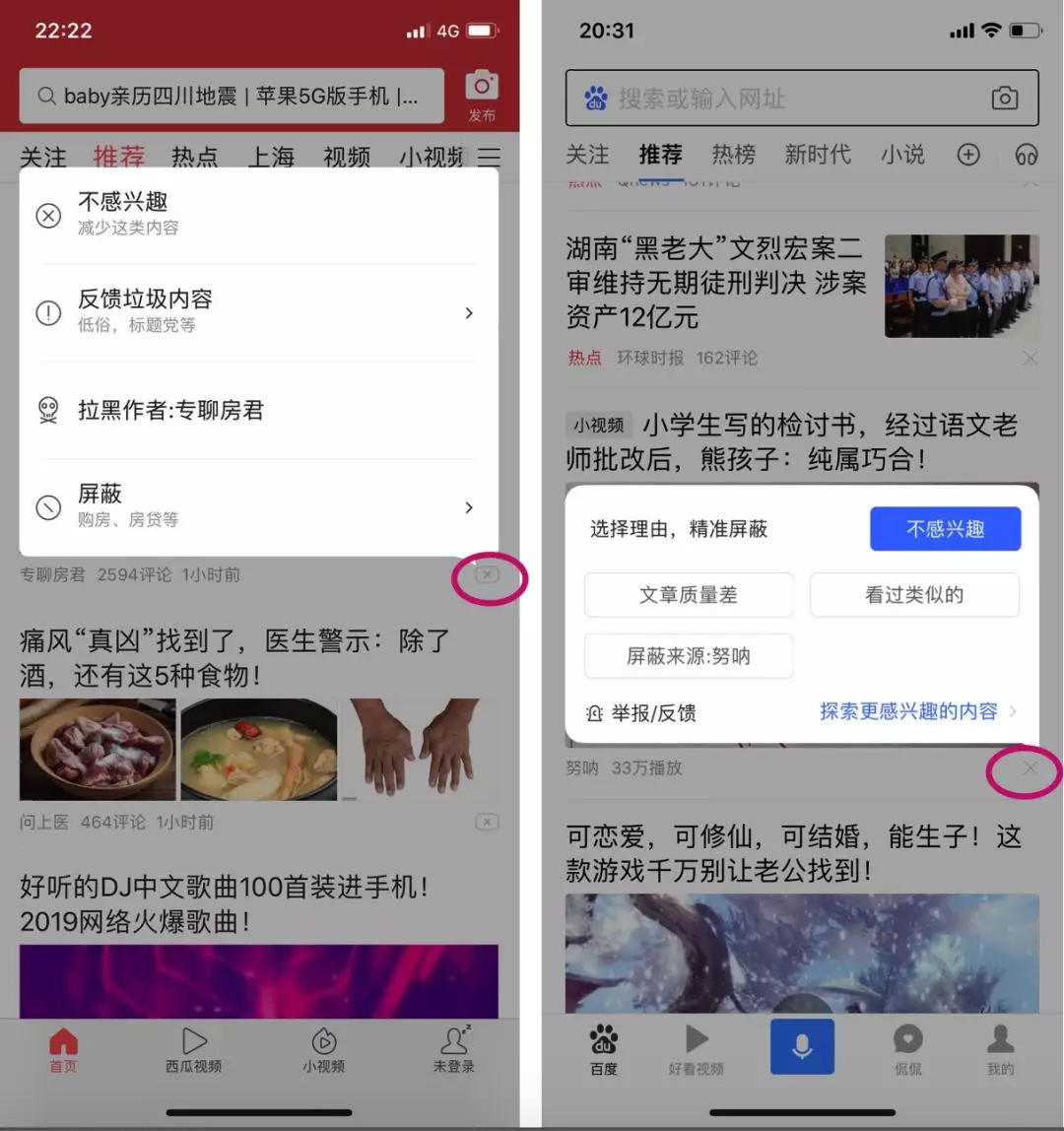
图9:负向反馈的交互形式:利用用户负向反馈来优化产品体验
负向反馈代表用户强烈的不满,因此如果推荐算法可以很好的利用这些负向反馈就能够大大提升推荐系统的精准度和满意度。基于内容的推荐算法整合负向反馈的方式有如下几种:
(1) 将负向反馈整合到算法模型中
在构建算法模型中整合负向反馈,跟正向反馈一起学习,从而更自然地整合负向反馈信息。
(2) 采用事后过滤的方式
先给用户生成推荐列表,再从该推荐列表中过滤掉与负向反馈关联的或者相似的标的物。
(3) 采用事前处理的方式
从待推荐的候选集中先将与负向反馈相关联或者相似的标的物剔除掉,然后再进行相关算法的推荐。
3. 兴趣随时间变化
用户的兴趣不是一成不变的,一般用户的兴趣是随着时间变化的,那怎么在算法中整合用户的兴趣变化呢?可行的策略是对用户的兴趣根据时间衰减,最近的行为给予最大的权重。还可以分别给用户建立短期兴趣特征和长期兴趣特征,在推荐时既考虑短期兴趣又考虑长期兴趣,最终推荐列表中整合两部分的推荐结果。
对于新闻资讯等这类时效性强的产品,能够整合用户的实时兴趣变化可以大大提升用户体验,这也是现在信息流类推荐产品大行其道的原因。
4. 数据清洗\\\**
基于内容的推荐算法依赖于标的物相关的描述信息,这些信息更多的是以文本的形式存在,这就涉及到自然语言处理了,文本中可能会存在很多歧义、符号、脏数据,我们需要事先对数据进行很好的处理,才能让后续的推荐算法产生好的效果。
5. 加速计算与节省资源
在实际推荐算法落地时,我们会事先为每个标的物计算N(=50)个最相似的标的物,事先将计算好的标的物存起来,减少时间和空间成本,方便后续更好地做推荐。同时也可以利用各种分布式计算平台和快速查询平台(如Spark、FAISS库等)加速计算过程。另外,算法开发过程中尽量做到模块化,对业务做抽象封装,这可以大大提升开发效率,并且可能会节省很多资源。
6. 怎么解决基于内容的推荐越推越窄的问题
前面提到基于内容的推荐存在越推越窄的缺点,那怎么避免或者减弱这种影响呢?当然用协同过滤等其他算法是一个有效的方法。另外,我们可以给用户做兴趣探索,为用户推荐兴趣之外的特征关联的标的物,通过用户的反馈来拓展用户兴趣空间,这类方法就是强化学习中�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9F%BA%E4%BA%8E%E5%86%85%E5%AE%B9%E7%9A%84%E6%8E%A8%E8%8D%90%E7%AE%97%E6%B3%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


