在的探索与实践

分享嘉宾:江云胜@Hulu
编辑整理:许晏铭
出品平台:DataFunTalk
导读: Hulu是美国领先的互联网视频流媒体平台,拥有大量的电影、电视剧等视频资源,对这些内容的理解和表示是Hulu的一个重要研究方向。Content Embedding技术将内容表示为向量,以利于后续算法、模型的处理和分析。本次分享将介绍Hulu在content embedding方面的一些实践和尝试,包括embedding的生成及其在业务场景中的应用。
01 About Hulu
Hulu是一个视频流媒体平台,主要由三个要素构成,分别是用户 (users)、内容 (contents) 和广告 (ads)。Hulu的商业模式也是围绕着这三个要素进行的,即Hulu花钱购买内容资源并提供广告展示位,用户付费观看内容,广告主付费购买广告位。
1. Contents on Hulu
Hulu提供了种类丰富的内容资源,主要是电影、电视剧,以及一些体育、新闻、儿童相关的节目;既有点播的内容 (VOD contents),也有直播频道 (LIVE channels)。
2. Content understanding in Hulu
Hulu的内容理解可以分为四个不同的层次:
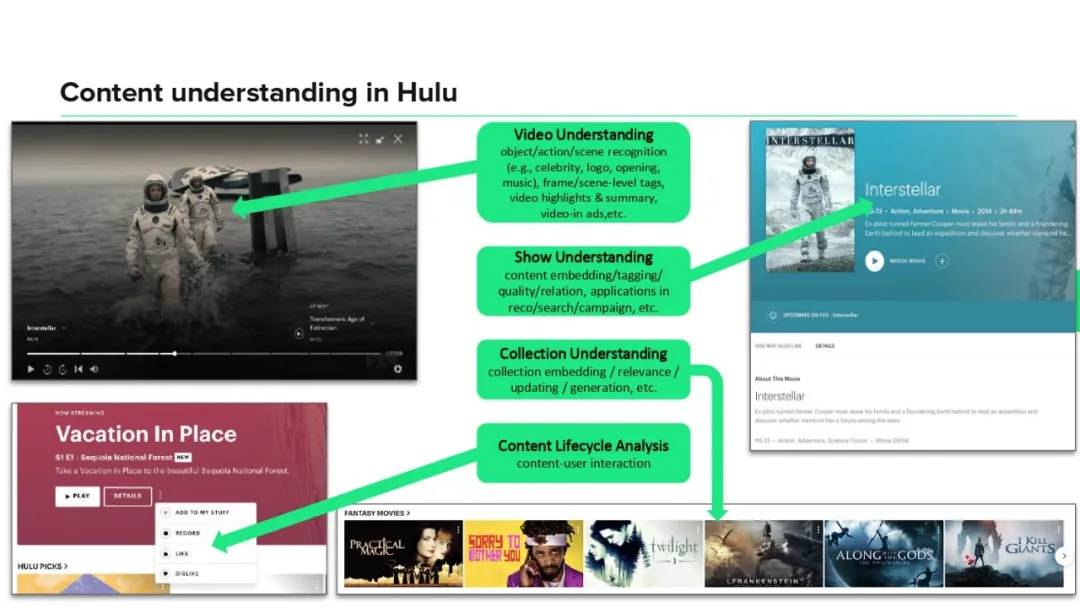
- 第1层,对视频的理解,比如检测和识别视频中出现的特定目标、事件、场景、明星演员、商标等,以及一些特定的片段(如片头、片尾、highlight片段等);
- 第2层,对整个剧集(包括电影、电视剧)的理解,比如为每个剧打一些标签 (tags) 或生成向量表征 (embeddings),或者分析剧与剧之间的相关性等;
- 第3层,对collection的理解,这里的collection是Hulu页面上每一行所展示的剧构成的集合,我们需要为每个collection也生成一个表征,并分析不同collection之间的关系,以及思考如何用算法来辅助collection的创建;
- 第4层,对内容在Hulu平台上生命周期的理解,主要是分析用户与内容之间的交互信息。
3. Contents & corresponding metadata/videos
Hulu上的每个剧集(电影/电视剧),除了最直接的视频资源外,还有一些与之相关的信息,包括剧的标题 (title)、简介 (description)、导演 (director)、演员 (actor)、主题 (topic)、类型 (genre)、标签/关键词 (tag/keyword)、获奖情况 (award)、分级情况 (rating)、字幕信息 (caption)、海报/封面图 (cover image) 等。
4. How to represent contents?
上面提到,与一个剧集相关的数据有很多(如下右图所示),它们具有不同的形式(标签类、文本类、图像、视频、音频等),从不同维度刻画剧集,具有丰富的信息。那么,如何综合考虑这些信息,给每个剧一个表征呢?表征,从某种意义上来说也是一种信息压缩,用更简洁、有效、本质的形式来刻画一个东西。典型的表征有如下几种:
- ID类型的表征,用一个id(一般是数字或字符串)来表示一个剧集。这类表征只能反映出两个剧是相同的或者不同的(看id是否相同),不能带来其它额外信息。One-hot encoding也是这类表征的一种形式。
- 标签类型的表征,用若干个关键词来刻画一个剧集,每个关键词具有一定的语义信息,比较方便人类理解。
- 向量类型的表征,用一个向量来标识一个剧集,这类表征可以很方便地用在后续的模型和计算中,对机器比较友好。我们接下来要介绍的content embedding就属于这一类表征。
02 Generation of content embeddings
1. Content embedding
Embedding是数学上的一个概念,指把一个数学结构经过某种映射嵌入到另一个数学结构中,这个映射需要保持某种意义下的结构不变性。类似地,content embedding是将剧集映射到一个低维稠密的向量空间中,并尽可能让内容相似的剧对应的embedding向量也比较接近。在Hulu,生成content embedding时需要考虑多种不同模态的数据,包括标签类数据(导演、演员、类型、标签/关键词等)、文本数据(标题、简介等)、图像(海报、封面图等)、视频、音频等;另外,考虑到电影/电视剧都是长视频,要压缩为一个低维向量需要很高的压缩率,并且在算法的训练和测试过程中都没有ground-truth可以参考,因此生成content embedding还是一个比较有挑战性的任务。
2. Tag-based embeddings (Graph Embedding)
Step 1:
首先,介绍如何利用剧集的标签类型数据来生成content embedding。前面提到,每个剧集都或多或少会有一些标签类型信息,比如导演、演员、类型、关键词/标签等,我们把它们称为该剧的属性 (attribute) 信息。由此,我们可以构建一个content-attribute graph,其中剧集和属性是该 graph 中节点,它们之间的对应关系用graph中的边来连接。由于不同的剧可能有相同的属性(比如两个剧有相同的导演或关键词),这些共同的属性节点可以将不同的剧连接起来,如下图所示,最终会构成一个非常庞大的content-attribute graph。
Step 2:
有了content-attribute graph之后,可以用node2vec 技术为graph中每个节点(包括剧节点和属性节点)学习出一个embedding向量,其中剧节点对于的向量即为我们需要的content embedding。大致的步骤是先根据graph采样获得一些path,然后调用word2vec方法学习得到节点的embeddings。我们略过细节,这里的基本思路是:如果graph中两个节点之间的path越多,则希望它们对应的embedding向量越接近。
3. To be improved …
上述基于content-attribute graph生成的content embedding,有如下几个不足的点:****
- 只使用了标签类型数据,没有考虑非标签类型的文本数据(如标题、简介等);
- 在标签类型数据中,GraceNote keywords和genres是最重要的,但它们的覆盖率并不高,很多剧会缺失这些数据;
- 构建content-attribute graph时候,并没有利用上这些标签的语义信息(只根据标签是否相同来构建graph中的连接边);
- 在建模过程中,不同类型的标签之间没有足够的信息交互。
4. Considering non-tag textual data
接下来,我们思考如何利用非标签类型的文本数据(标题、简介等)。我们尝试了两种处理方法:
- 方法一:直接根据文本数据生成content embedding;
- 方法二:先根据文本数据预测出一些标签,然后将预测的标签加到前面的content-attribute graph来生成更高质量的content embedding。

上图是我们尝试的方法一,对于剧集简介,先用BERT模型得到句中每个token的embedding,然后利用SIF算得每个句子的embedding,最后将剧集简介中所有句子的embedding做平均后得到整个剧集简介的embedding。这个方法的效果比较一般,接下来我们重点介绍方法二。
Metadata-BERT:
use metadata to predict/complement content tags
方法二,主要是先根据文本数据来预测剧集的一些标签信息,然后将这些标签加到content-attribute graph中,接着调用前面的tag-based embedding方法即可。我们对原始BERT模型进行了改进,使得它可以接受各种类型的数据作为输入,包括标签类型数据 (tag-like metadata) 和非标签类型的文本数据 (non-tag textual metadata) 。新的模型被称为Metadata-BERT,它能根据输入的metadata信息预测出更多的tags,可以作为原始标签数据的一个扩展和补充。Metadata-BERT模型利用GraceNote keywords数据进行训练,在测试集上的标签预测准确率达到83%(比原始BERT的61%有显著提升)。将Metadata-BERT预测出来的标签添加到之前的content-attribute graph中,能够进一步丰富graph的节点和边,从而产生质量更高的content embedding。
5. Further: how about visual/audio data?
除了上述提到的标签类型数据和非标签类型的文本数据,一个剧还有对应的音频资源和视频资源。与前面的数据不同,音视频信息是一帧一帧的,一部剧是由一个图片序列和音频序列构成的。如何将整个序列转化为一个embedding向量,这是我们需要重点考虑的地方。我们的做法是:先将整个视频的视频帧和音频帧抽出来,然后用一些神经网络(如Inception/VGGish)为每个视频帧和音频帧提取特征,最后用一些聚合模型(如NeXtVLAD/BERT等)将帧级的特征聚合为整部剧的embedding。整个模型可以借助一些诸如标签预测、推荐排序等任务来训练。
6. A try: two-level-BERTs for v/a embedding learning
我们做了一个尝试,用两层BERT模型来做推荐业务中的CTR预估任务,简单来说,就是先用一个BERT模型来聚合视频的帧级/片段级的特征,以得到每部剧的content embedding向量;然后再用一个BERT模型来聚合用户信息,主要是历史观看记录 (history_shows) 以及目标剧集 (target_shoW) ;最后再接MLP进行CTR预估。这个框架比较大,将content embedding的学习直接放到具体的推荐业务中,是一个end-to-end的学习过程;缺点是两个BERT模型体量太大,收敛不太稳定。
7. Overview: generation of content embeddings
上图是content embedding生成过程的一个概览图。图中的 content data包括剧的metadata信息、视频文件和字幕文件,其中metadata又分为标签型数据和非标签型的文本数据,而视频文件又包含视觉图像和音频信息。针对不同类型的数据,我们采用不同的模型,从而产生不同的 content embeddings,而这些不同的embedding也融合成一个终极embedding。在实际应用中,可以根据业务特点来使用不同类型的embeddings,或者使用最终的融合版embedding。
03 Applications of content embeddings
1. Content similarity
接下来我们介绍content embedding的一些应用。content embedding最直接的应用是可以简单方便地计算两个剧在内容上的相似性(比如计算embedding向量的余弦相似性)。下图右侧是完全基于content embedding向量计算出的与“钢铁侠”最相关的剧,可以看到大部分结果都还是比较合理的。在推荐业务中,很多时候需要计算show-to-show relevance,而内容相似性可以作为其中的一个重要因子(其它可能需要考虑的因子包括基于用户co-watching信息的相关性等)。Show-to-show relevance可以应用在Hulu的You May Also Like (YMAL)、UpNext等场景中,下图左侧是Hulu的YMAL页面。
2. Content embeddings as features in TV/Movies ranker, PCS, etc.
Content embedding的另外一个应用是可以作为很多算法、模型的输入特征。如上图所示,左边是Hulu推荐业务中对TV/Movie的排序模型,右边是对Home页面的collections的排序模型,这两个模型中都使用了content embeddings作为输入特征(图中绿色框所示)。
3. Content embeddings for content cold start (in Retriever)
Content embedding在内容冷启动方面也有着重要应用。以推荐系统的召回模型为例,如果召回模型只是基于用户的co-watching信息(如下图左侧分支),这样对于新加入的内容或冷门内容,可能采集不到足够多的用户观看记录,从而影响召回效果。这时候可以根据content embedding来构建另外一个基于内容信息的召回分支(如下图右侧分支),然后再用一些方法(比如gate函数)将两个分支融合起来(如下图中间的分支所示),从而提升对新内容或冷内容的召回效果。
**4. Colle
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9C%A8%E7%9A%84%E6%8E%A2%E7%B4%A2%E4%B8%8E%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


