图文并茂带你了解依存句法分析
作者: 龚俊民(昵称: 除夕)
学校: 新南威尔士大学
单位:Vivo AI LAB 算法实习生
方向: 自然语言处理和可解释学习
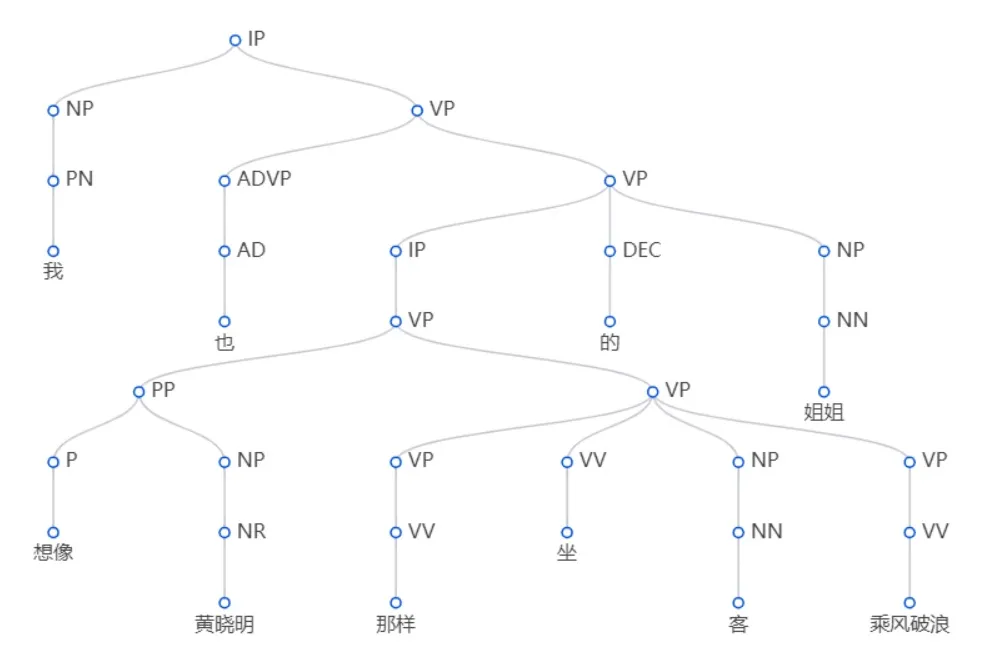
前言: 上一期我们讲了成分句法分析,它相当于考虑广义上的嵌套关系的命名实体识别。这一次我们来说一说依存句法分析,它相当于文本结构化任务中,与命名实体识别经常在一起的实体关系抽取任务。
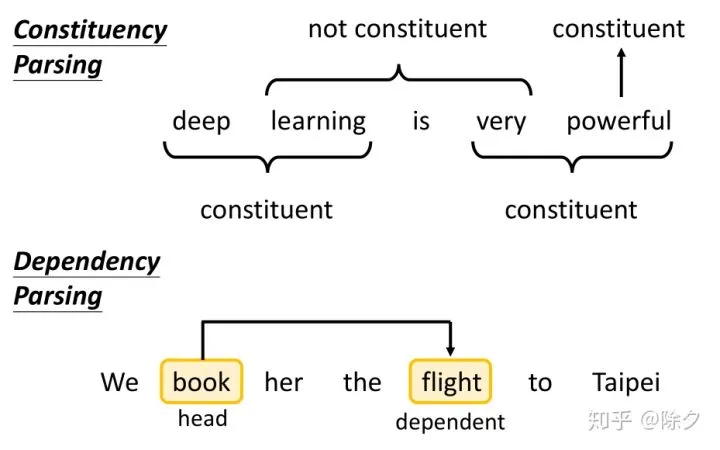 成分句法分析关心的是,某两个相邻词汇能不能接在一起构成成分(广义的mention)。而依存句法分析关系的是,两个词汇之间的关系(entity relation)。依存解析不关心两个词汇是否一定要相邻。比如 book 和 flight 没有直接相连,但是 flight 是 book 的宾语,book 是 flight 的主语。我们会用一个从 book 指向 flight 的箭头来表示这种依存关系。箭头的起始我们叫作 head。
成分句法分析关心的是,某两个相邻词汇能不能接在一起构成成分(广义的mention)。而依存句法分析关系的是,两个词汇之间的关系(entity relation)。依存解析不关心两个词汇是否一定要相邻。比如 book 和 flight 没有直接相连,但是 flight 是 book 的宾语,book 是 flight 的主语。我们会用一个从 book 指向 flight 的箭头来表示这种依存关系。箭头的起始我们叫作 head。
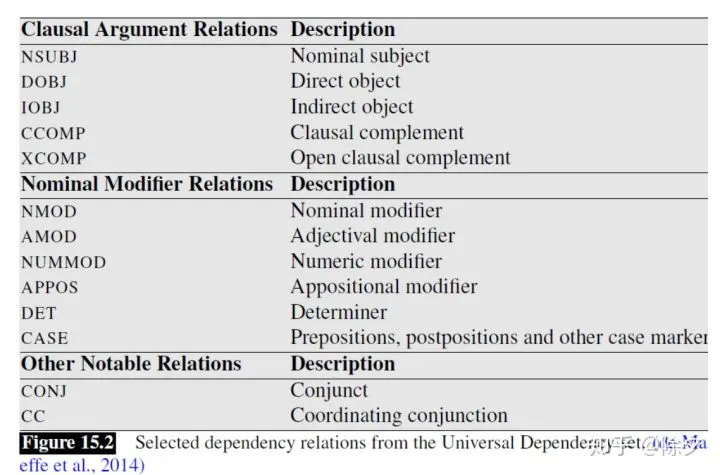 词汇和词汇之间的关系一览。
词汇和词汇之间的关系一览。
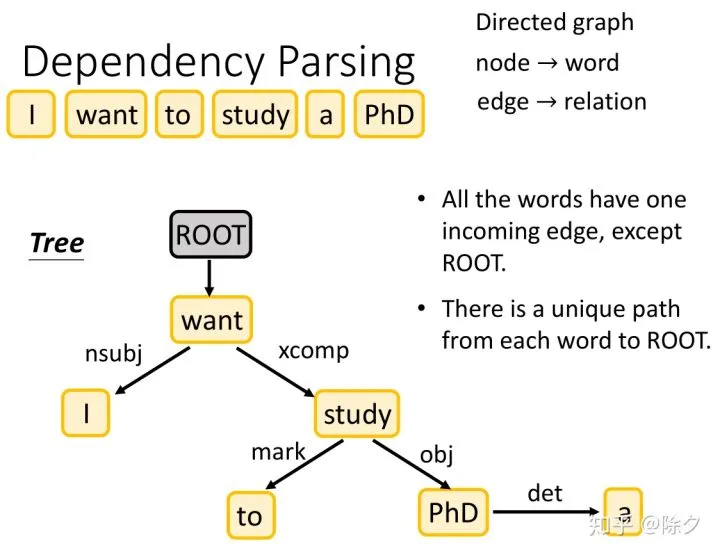 更具体地说,依存解析做的是把一个句子,变成一个有向图。图中每一个节点是一个词汇,每一条边,是一种关系。除了根节点,每一个节点词汇都只有一个入度的边。但每个词汇都可以指向多个其它词汇。它是一个树状的结构。每一个词汇都有唯一的一条路径回溯到根节点。
更具体地说,依存解析做的是把一个句子,变成一个有向图。图中每一个节点是一个词汇,每一条边,是一种关系。除了根节点,每一个节点词汇都只有一个入度的边。但每个词汇都可以指向多个其它词汇。它是一个树状的结构。每一个词汇都有唯一的一条路径回溯到根节点。
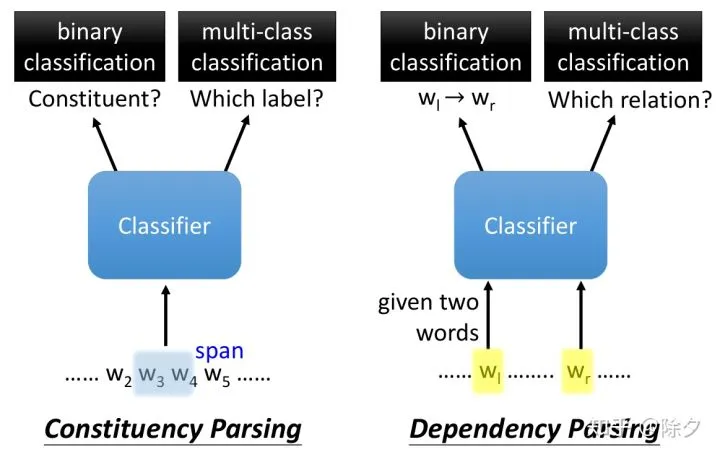 我们要怎样得到这样一棵依存解析树呢?实际上丢给分类器两个词汇和其上下文,它会先通过一个二分类器,用来输出左边到右边的token之间有无依存关系,若有依存关系,则第二个分类器会输出其关系的类别。
我们要怎样得到这样一棵依存解析树呢?实际上丢给分类器两个词汇和其上下文,它会先通过一个二分类器,用来输出左边到右边的token之间有无依存关系,若有依存关系,则第二个分类器会输出其关系的类别。
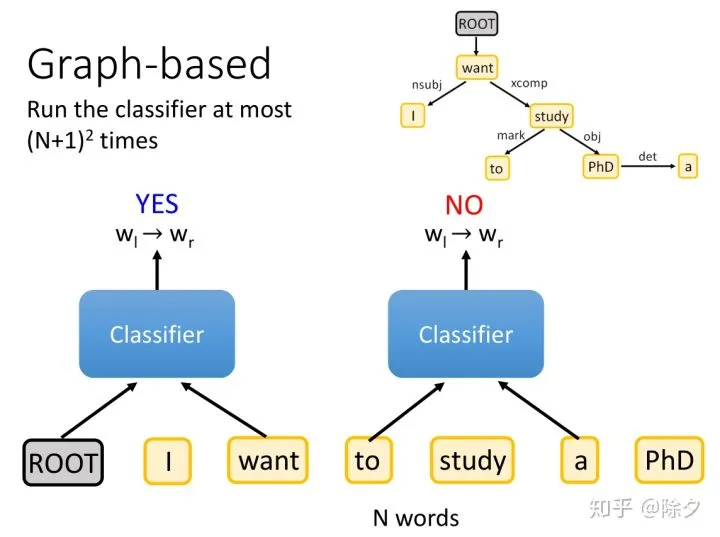 模型的输入是ROOT 加上 N 个词汇组成的句子。然后取出 (N+1)² 的单词对,一个个丢给分类器做关系分类。
模型的输入是ROOT 加上 N 个词汇组成的句子。然后取出 (N+1)² 的单词对,一个个丢给分类器做关系分类。
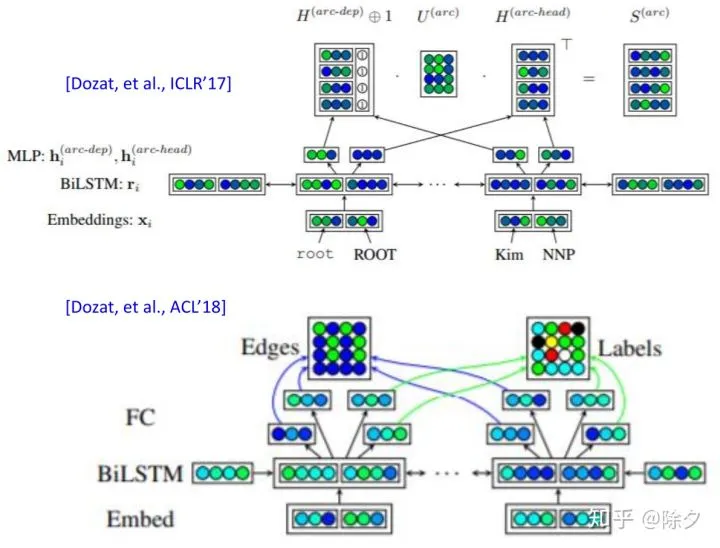 文献上的具体做法是这样的。它会先把序列丢给一个 BiLSTM,把每个 token 的嵌入抽出来,再两两丢给一个FC层做分类,判断这两个 token,要不要连在一起,如果要连在一起,它们的关系是什么?论文会把抽出token的嵌入乘上一个FC做线性映射,再把两个 token 做类似注意力的操作,会得到一个数值,这个数值表示这两个 token 有多大概率要连在一起。其关系的标签也是类似的做法。
文献上的具体做法是这样的。它会先把序列丢给一个 BiLSTM,把每个 token 的嵌入抽出来,再两两丢给一个FC层做分类,判断这两个 token,要不要连在一起,如果要连在一起,它们的关系是什么?论文会把抽出token的嵌入乘上一个FC做线性映射,再把两个 token 做类似注意力的操作,会得到一个数值,这个数值表示这两个 token 有多大概率要连在一起。其关系的标签也是类似的做法。
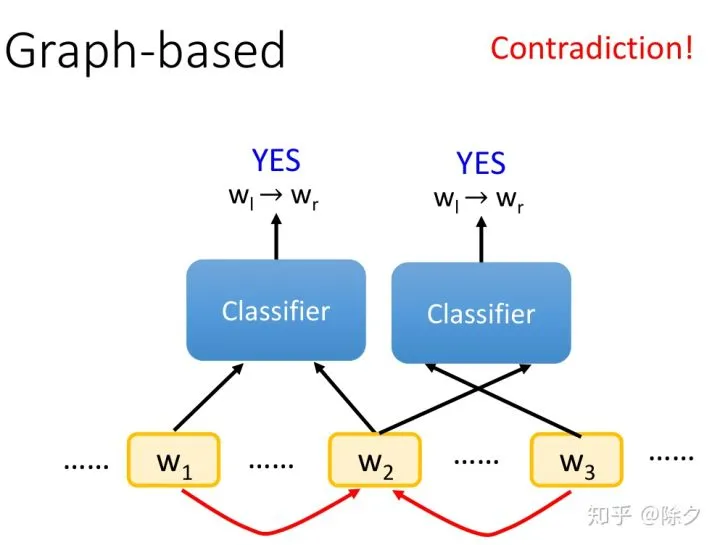 但如果我们把判断有无关系和判断关系是什么分开来处理,会容易出现矛盾的情况。比如 w1和w2之间有w1->w2的依存关系,而w2和w3又有w3->w2的依存关系。这样就会出现一个 token 入度是2的不可能情况。
但如果我们把判断有无关系和判断关系是什么分开来处理,会容易出现矛盾的情况。比如 w1和w2之间有w1->w2的依存关系,而w2和w3又有w3->w2的依存关系。这样就会出现一个 token 入度是2的不可能情况。
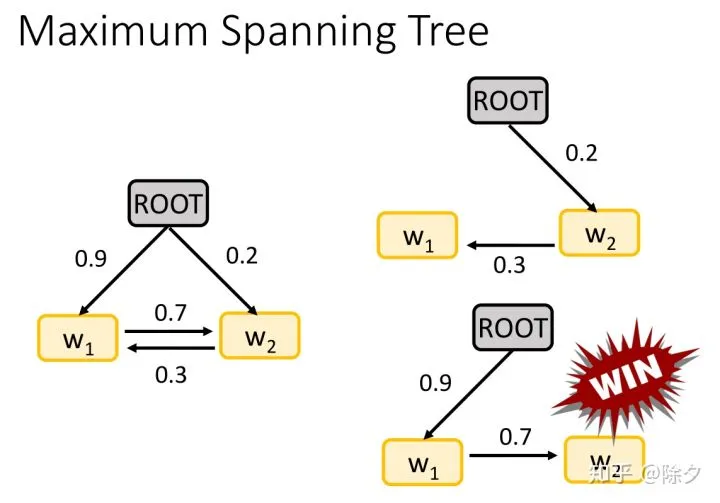 我们可以用类似最大生成树的算法来解。我们目标是从各种可能的候选树中,找出一棵路径置信度最大的树。
我们可以用类似最大生成树的算法来解。我们目标是从各种可能的候选树中,找出一棵路径置信度最大的树。
 类似的,我们也可以用基于转移的方式来做依存解析。这部分可以参照上一期的 成分句法分析。模型要根据 Buffer 和 Stack 的内容,来决定要采取哪一个 action。
类似的,我们也可以用基于转移的方式来做依存解析。这部分可以参照上一期的 成分句法分析。模型要根据 Buffer 和 Stack 的内容,来决定要采取哪一个 action。
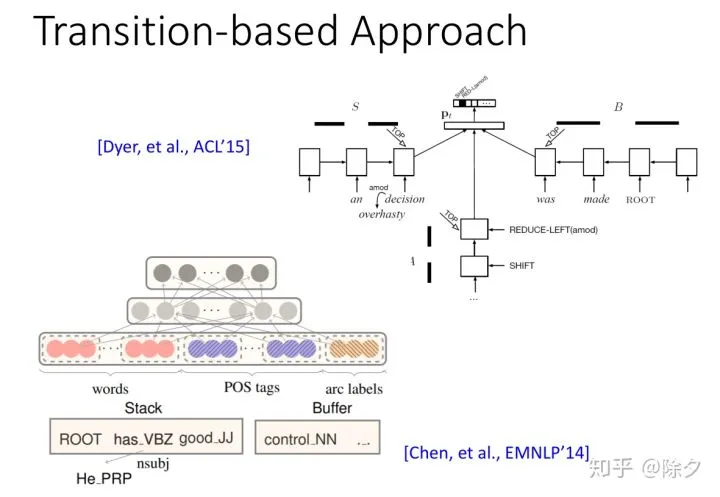 这种基于转移的方法,最早在14年的时候就有人做过。
这种基于转移的方法,最早在14年的时候就有人做过。
这种基于转移的方法,最知名的是 SyntaxNet。它知名的原因在,它有一个好的动画展示转移生成的过程。16年的时�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9B%BE%E6%96%87%E5%B9%B6%E8%8C%82%E5%B8%A6%E4%BD%A0%E4%BA%86%E8%A7%A3%E4%BE%9D%E5%AD%98%E5%8F%A5%E6%B3%95%E5%88%86%E6%9E%90/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


