图对比学习的最新进展

分享嘉宾:朱彦樵 中国科学院自动化研究所
编辑整理:吴祺尧 加州大学圣地亚哥分校
出品平台:DataFunSummit
导读: 本文跟大家分享下图自监督学习中最近比较热门的研究方向:图对比学习,在近期的进展以及组内在此方向上最近的一些工作。主要内容包括:① 图对比学习的基础知识介绍与方法梳理;② GRACE模型;③ 基于GRACE的改进模型:GCA;④ 实验结果;⑤ 图对比学习的总结与展望。
01 图对比学习的基础知识介绍与方法梳理
首先和大家介绍一下图表示学习的基础知识与方法。
1. Representation Learning on Graphs
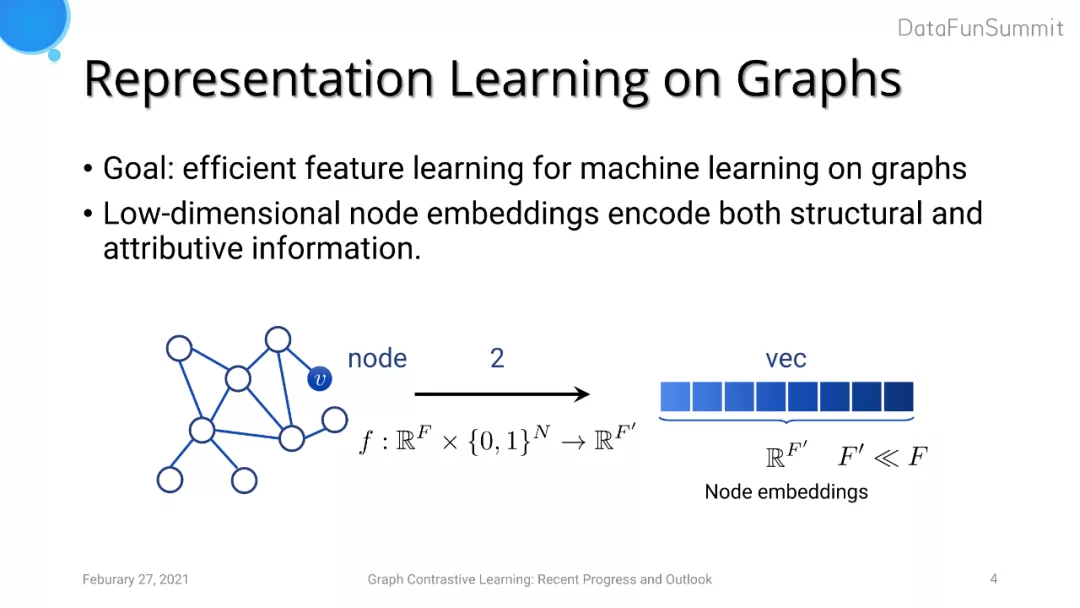
图表示学习旨在对图中节点得到一个低维的表达来编码节点的属性以及结构特征。如果想要得到一个图级别的特征表达,则我们可以对节点embedding进行pooling。
大多数图神经网络面临的问题在于它们均使用有监督学习的方式进行训练。但是监督学习存在以下两个问题:
- 现实中,我们想要获得大量高质量的标签往往费时费力、十分困难;
- 有监督表达学习倾向于使得模型学习到与标签相关的信息,但实际上我们需要模型学习到迁移性较强的、可重用的、有共性的知识。
为了解决这两个问题,现在越来越多人开始关注自监督学习。自监督学习本质上是使用代理任务(proxy tasks)来指导模型学习特征表达。代理任务通俗的来说就是将给定数据可以观测到的部分作为输入,而数据的另外一部分作为我们希望去学习到的对象。在图像领域代理任务常见的有:旋转角度的预测任务,乱序图像的还原任务(reorganization of shuffled patches)等。
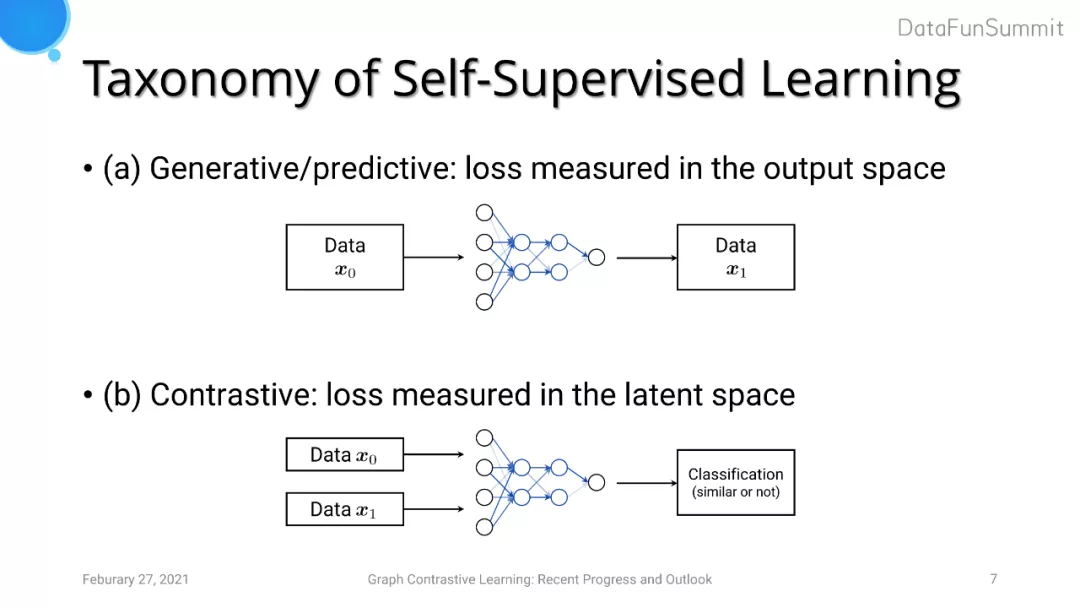
我们可以进一步将代理任务分为两类。第一大类的方法是Generative/predictive的任务,其损失是在输出空间进行度量,代表模型为Autoencoder(重建损失)以及对图像的重建等。另一大类是最近比较热门的Contrastive(对比学习)的任务,旨在引导模型去学习输入的一对数据的相关信息(是否来自于同一个数据源、是否是相似数据等)。对比学习相较于第一类任务的优点在于模型不需要学习细粒度级别的特征(如pixel-level features),而是更多关注在高层次抽象级别的特征中,因为这些特征足以区分不同物体与数据。
2. 对比学习的框架

SimCLR是一个目前使用较为广泛的对比学习框架。对比学习的框架由三个部分组成:
- 数据的随机扰动,通常是一个多阶段的扰动。例如对于图像,我们可以先对其进行旋转,再对其进行裁剪、变换色彩空间等。在每次模型迭代过程中,扰动是随机的。
- Encoder函数f和representation extractor 函数g。Encoder对进行过扰动的样本进行编码得到一个特征表达,之后使用g来增强表达能力(通常使用MLP),进而得到一个更加高层次的特征表达。
- 对比学习目标函数L,这个函数用于度量所给定样本对之间的相似性。我们的目标是希望经过扰动的两个样本经过模型后得到的表达尽可能一致。

对比学习目标函数类似metric learning中triplet loss的形式。在metric learning中我们希望一对正样本的embedding之间的距离拉近,而一对负样本的embedding之间的距离尽可能远。类似地,对比学习中常常采用的损失函数是InfoNCE loss,其可以看做是一个n分类问题。与triplet loss的目标对应,我们希望从一个正样本对和n-1个负样本对中间使得正样本对之间的embedding距离拉得更近。
3. 图对比学习
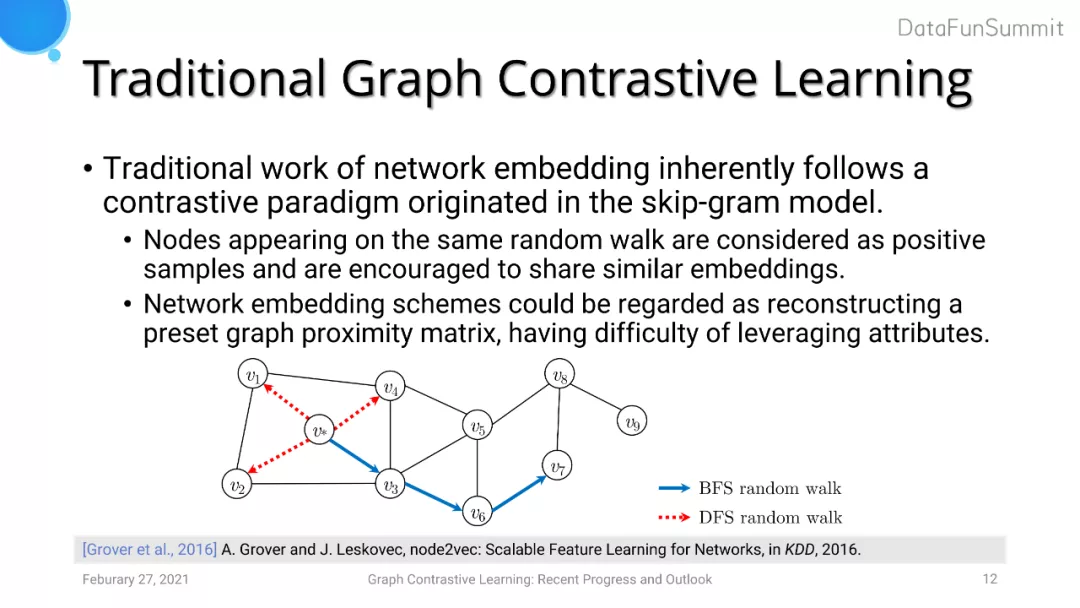
图对比学习的诞生时间实际上早于CV中的对比学习。之前network embedding的工作本质上运用到了对比学习的思想。例如node2vec中使用BFS或者DFS的随机游走,希望出现在同一walk序列中的节点具有相似的embedding,而不在同一walk上的节点embedding距离拉远。但是network embedding的方法中的encoder特征提取能力较弱,只是做了embedding lookup的操作,而不像DNN有着强大的特征表达能力。此外,已经有工作证明了network embedding的方法实际上是对图proximity矩阵的重建,这意味着这一方法仅仅利用到了图的结构信息,而并没有利用节点attribute信息。

目前大家更倾向于探索深度图对比学习的方法。GNN通过对邻居节点的信息进行聚合来学习节点的特征表达,所以它可以看作是一个更加强大的encoder。但是图对比学习尚处于发展的早期阶段,目前的工作主要在两方面进行探索创新:对比学习的目标以及数据增强。前者的设计关键点是定义将什么样的embedding在特征空间中的距离拉近或者拉远,而后者的难点在于设计图数据增强的策略(相较于CV的数据增强技术,图数据不同domain下蕴含的先验信息差异巨大)。
下面介绍几篇具有代表性的图对比学习的工作。
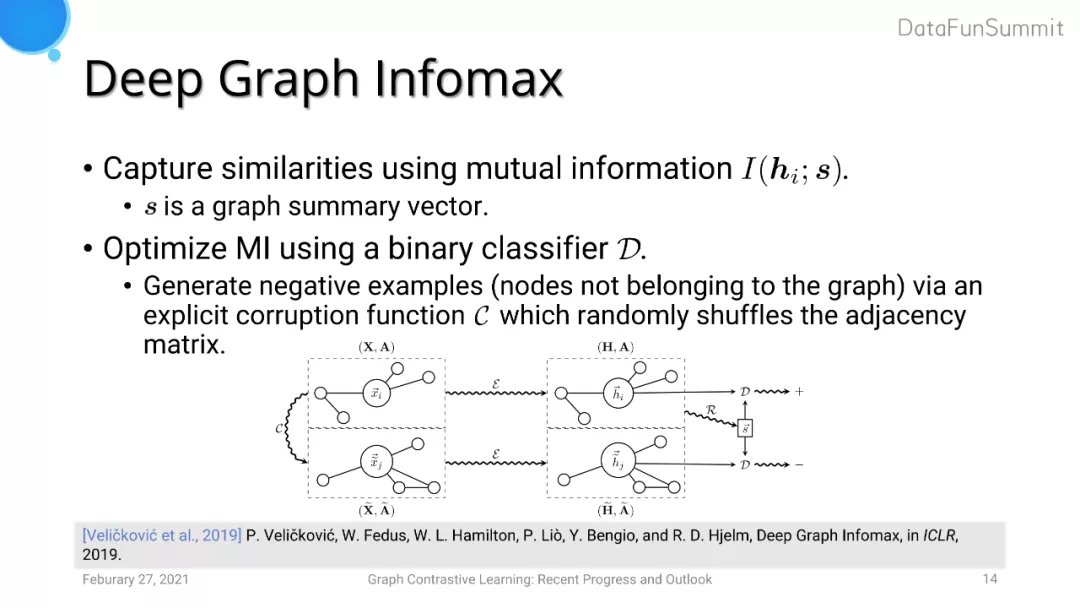
Deep Graph Infomax (DGI) 旨在使得模型生成的节点级别的表达以及图级别的表达在embedding空间的距离拉近。DGI使用MLP将节点特征和图特征做一个二分类任务,用来判断这两类特征是否来自于同一个图。它们生成负样本的策略是将图邻接矩阵进行random shuffle的操作。
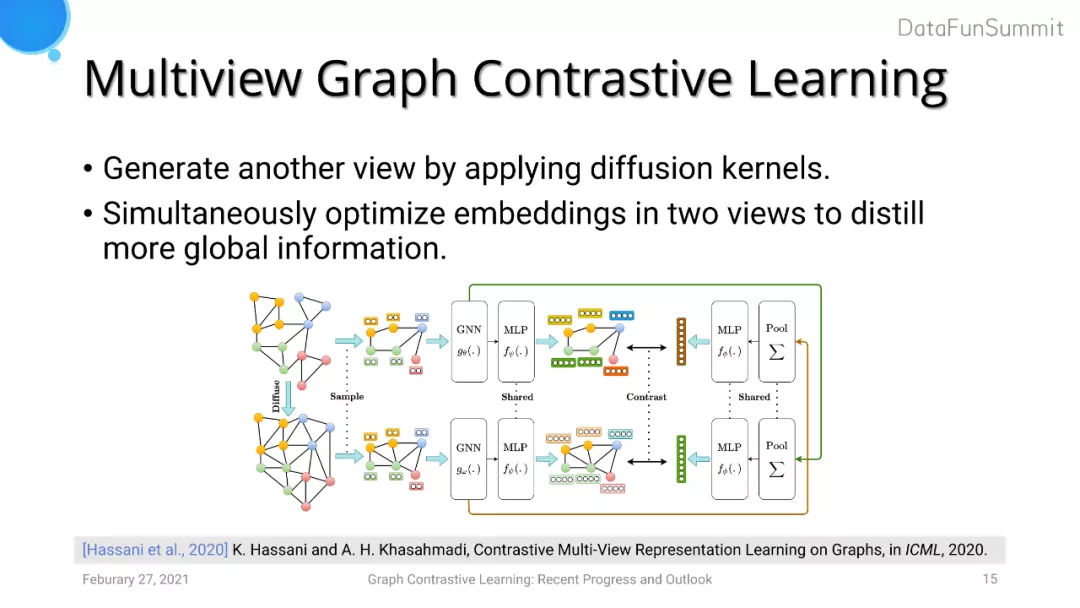
Multiview Graph Contrastive Learning (MVGCL) 采用diffusion kernel来生成一张图的另一个view。Diffusion kernel可以使每个节点感知到更多全局信息,相当于对图结构进行数据增强。在此基础上,MVGCL会对两个view进行采样得到两个子图。之后使用类似于DGI的方法,对两个子图两两之间做对比学习,即选取一个子图提取其节点embedding,对另一个子图生成全局图的embedding进行对比学习。通过这种方法,节点的表达可以吸收到更多图级别的信息,同时图级别的任务可以更好地利用到节点级别的表达。但是MVGCL的缺点是经过diffusion kernel后新生成的view是一个dense graph,使用深度图学习模型的计算复杂度较高。
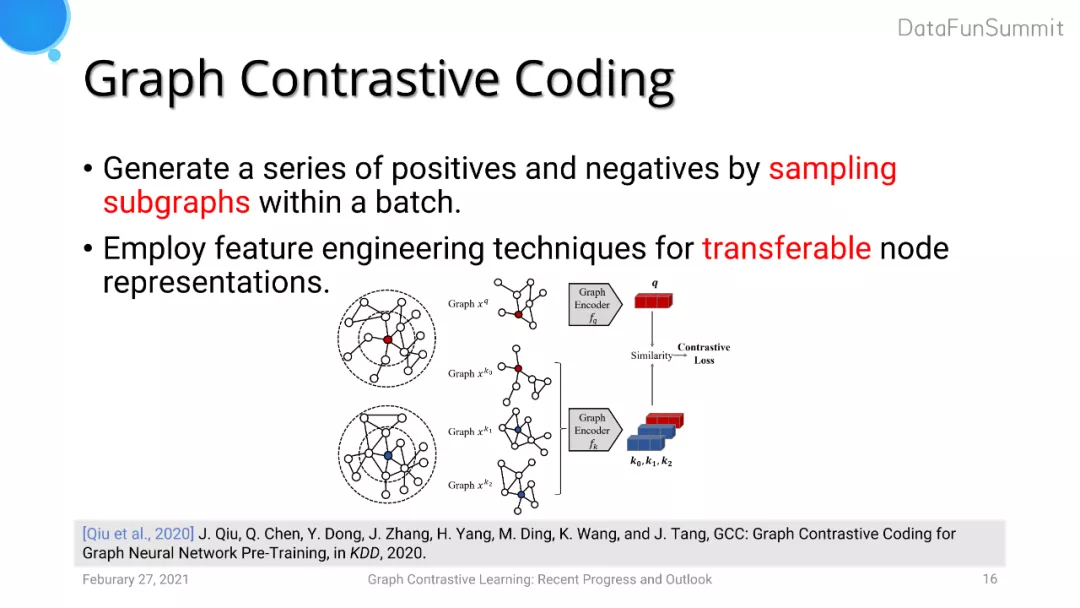
Graph Contrastive Coding (GCC) 考虑将对比学习方法引入图的预训练任务中,即训练数据与测试数据来自于不同的domain。GCC采用的正样本对是图中同一个anchor节点生成的子图,而负样本对则是图中不同anchor节点生成的一对子图。GCC由于考虑到了模型迁移性的问题,使用了特征工程的方法手工生成了一些节点特征。
4. 总结

针对之前提到的对比学习两大方向:Contrastive Objective以及Data Augmentation做一个小总结。
对于Contrastive Objectives的探索,DGI和MVGRL采用的是global-local的思想,即采用图节点的特征表示与图全局表示进行对比学习。但是这一做法要求生成图全局特征时聚合函数是个单射函数,否则模型无法保证充分利用图节点的embedding信息。而GCC以及我们提出的GRACE和同期GraphCL的工作采用了local-local的思路,即直接利用两个经过增强的view中节点的embedding特征,巧妙地绕开了设计一个单射读出函数的需求。

针对图对比学习中的数据增强,现有大多数模型仅仅采用了图结构信息的增强,例如打乱邻接矩阵、添加/删除边、图采样、使用diffusion kernel生成新的全局view等。我们的工作还考虑了节点attribute level的数据增强,包括随机扰动节点部分维度的特征、添加高斯分布的噪声等。
下面,重点分享下我们的两个工作:GRACE和GCA。
02 Deep Graph Contrastive Learning: GRACE
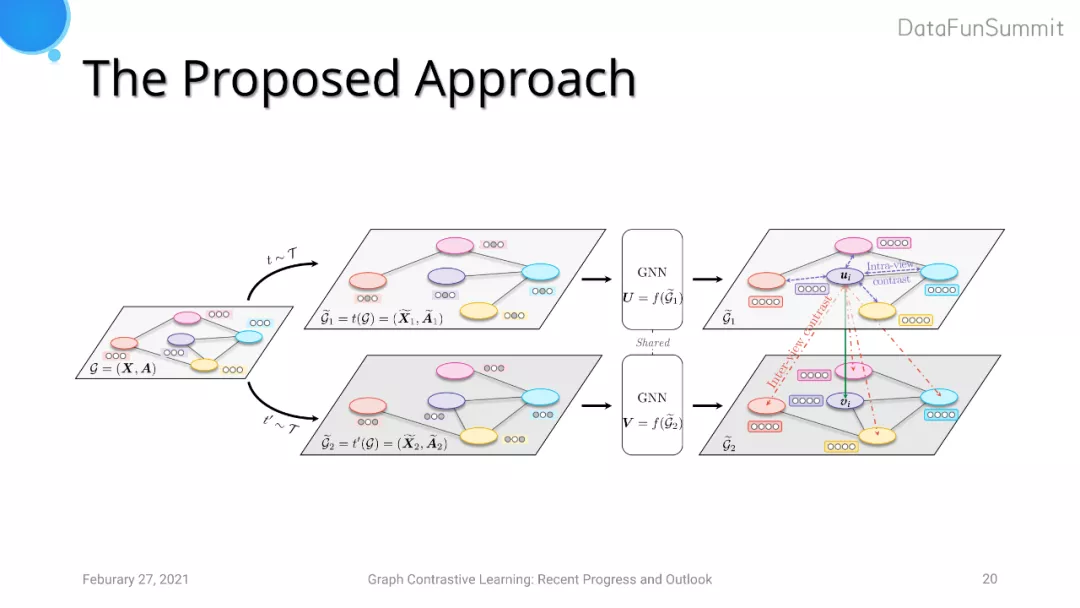
1. Contrastive Objective
GRACE借鉴了SimCLR的思想并将其运用在图对比学习中。但是由于图学习任务和视觉任务有着很大差异,即CV领域每张输入图片彼此是相互独立的,而图中节点和节点之间会互相影响。基于这一点,GRACE的对比损失进一步分为两类:第一部分负样本对比损失来自于生成的view之内(intra-view negatives),这代表着同一个view下anchor节点和其他节点可以生成一个负样本对;另一部分对比损失来自于跨view之间的节点对(inter-view negatives),这代表着两个view下anchor节点和其他节点看作一个负样本对。
2. Data Augmentation

针对图数据增强这一方面,GRACE采用了两种策略,分别对应于结构层面以及属性层面的数据扰动。首先,我们采取了随机删边的方法。这里不采用加边的原因是为了使模型计算复杂度尽量小。另外一方面,我们对图的节点特征进行了随机扰动。具体地,我们对节点特征的每一个维度进行随机的mask。
3. 理论基础


GRACE提出的Contrastive objective以及data augmentation的策略基于最大化输入样本分布与输出分布的互信息(InfoMax Principle)的理论基础:
- Contrastive objective本质上是在优化互信息的下界。这里U,V分别代表着经过扰动后随机生成的两个view。
- 若我们将两个输出特征之间相似度度量简化为向量的内积,GRACE的contrastive objective可以转化为triplet loss的形式。
03 Adaptive Augmentation: GCA
本质上来说,对比学习希望模型能学习到在外界施加扰动的情况下不敏感的特征表达。但是在图中每个节点和每一条边的重要程度不同,我们在data augmentation时进行去边的操作时应该尽可能多的去除不重要的边,进而可以保留图中重要的边与节点的结构信息以及属性信息。

GCA依然遵循GRACE的数据增强策略,即采取拓扑结构层面的数据增强(去边)以及节点属性层面的数据增强(mask节点特征)。我们希望在进行数据增强的操作时,对于每个边以及每个节点进行扰动的概率有所差别,且事件发生的概率应该偏向于不重要的边与节点特征。
1. Topology-level Augmentation


拓扑结构层面的数据增强主要基于node centrality的指标,其用来衡量一个节点在图中的重要性。边的重要性可以使用两个节点的centrality来综合得到。考虑到图中可能存在长尾分布(即存在heavily dense connections的节点),我们对边重要性进行取log的操作进行缩放。此外,我们还对计算出的removal probabilities进行了标准化操作来避免出现过大的概率值。
我们在实验中还尝试了三种Node centrality的度量方式:degree、eigenvector以及PageRank。在Karate club数据集中得到的centrality结果表明这三种度量方式的效果差异可以忽略不计。
2. Attribute-level Augmentation

GCA中属性层面的augmentation主要考虑了离散的情况,因为目前实验中使用的数据集的特征较为稀疏。例如一个citation network中,节点代表着paper,那么节点的属性便是一个关键词,其通常是一个0/1的稀疏特征。我们可以认为比较有影响力的文章中的关键词也十分重要,所以在计算节点特征重要性时可以使用节点的centrality进行计算。在稀疏特征条件下,我们计算每个特征维度出现的次数,并乘上节点本身的centrality。此后,对概率值的后处理操作类似于拓扑层面的数据增强,即我们也添加了log运算以及标准化操作。
04 实验结果
实验中我们选取了Wiki-CS、Amazon-Computers、Amazon-Photo、Coauthor-CS以及Coauthor-Physics五个数据集。Baseline采用了三类图学习的模型:基于network embedding的模型(DeepWalk和node2vec)、基于无监督学习的GNN模型(GAE, VGAE, GraphSAGE, DGI, GMI和MVGRL)以及基于有监督学习的GNN模型(GCN和GAT)。有监督学习的模型在训练时会直接加入分类器进行联合训练,而在无监督学习的模型中模型首先会单独学习embedding的表达,之后在加入采用l2正则化的logistic regression分类器进行有监督的训练。在实验中,我们采用的评价指标是节点的分类准确度。GRACE和GCA中的GNN layer采用的是两层GCN。
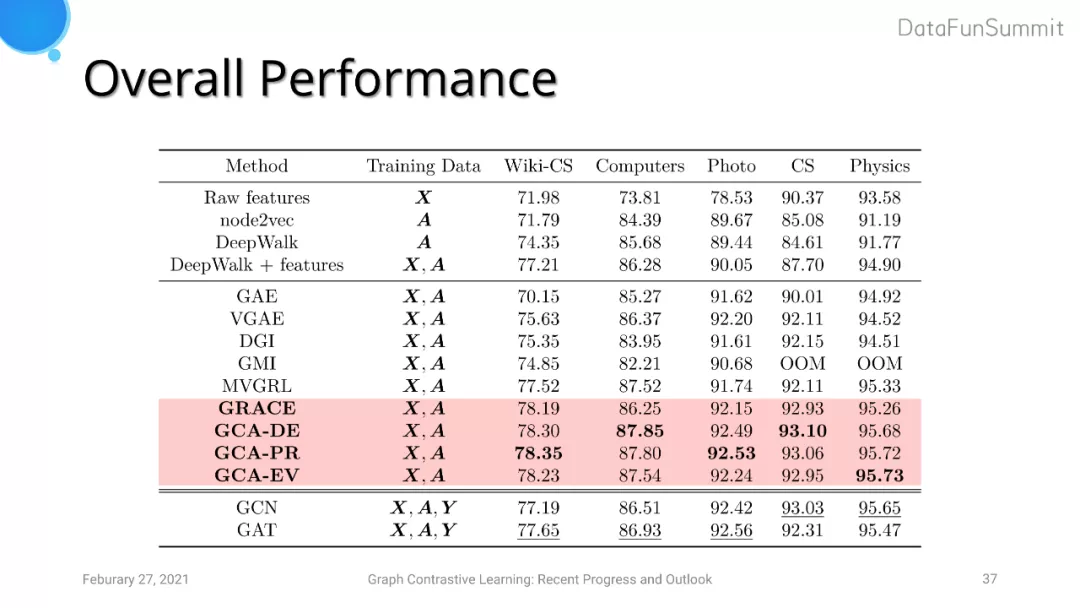

实验结果表明GRACE和GCA的分类效果明显优于其他模型。在消融实验中,我们分别对于拓扑结构以及节点属性的数据增强对比了uniform augmentation与adaptive augmentation的效果,结果表明adaptive augmentation对评价指标有大约半个点至一个点的提升。
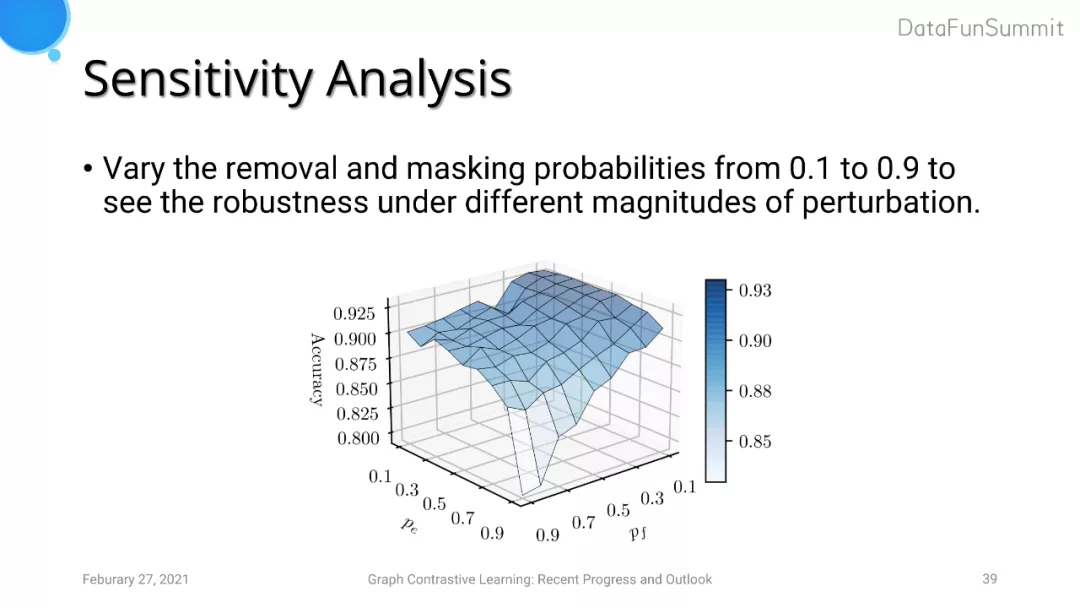
我们还对removal和masking的概率进行了敏感性分析,实验发现如果dropout的概率过大会导致模型无法学习到有用的表达。但是只要dropout概率设置适当,模型在一定的参数配置范围内效果差异不是很明显。
05 图对比学习的看法与总结
- 我们提出了基于图对比学习的模型框架GRACE以及其改进版本GCA,其中GCA在图数据增强的策略中采取了adaptive augmentation;
- 实验证明了local-local的contrastive objective可以更好地利用图节点层面的表达;
- 实验证明了针对图结构层面以及属性层面的数据增强策略对图对比学习都有正向影响;
- 在数据增强的过程中,edge removal以及feature masking的操作需要考虑到节点重要性,而我们采用的衡量指标是node centrality。保留尽量多的关键信息可以指导模型学习图的深层次特征表达;
- GRACE和GCA达到了SOTA的效果,成功缩小了无监督学习与有监督学习的差距。
图的自监督学习是一个十分有前景的研究方向,它可以使得模型在缺乏标注的情况下学习到较好的图embedding。这意味着图的自监督学习可以运用到更为广泛的场景中,例如推荐系统等。对于图的对比学习来说,它是由传统的network embedding的方法演化而来的新的图无监督学习范式。但是图对比学习还处于研究早期阶段,针对对比学习范式背后的机理的认知还停留在实验验证阶段,缺乏严谨理论的推导和证明。例如,我们应该如何更好地利用图拓扑空间信息以及图属性空间信息;如何在图中进行正样本对以及负样本对的采样;从理论上分析什么样的contrastive objectives效果更好(InfoNCE、Jensen-Shannon divergence等)。
06 Useful Resources
图自监督学习必读论文、survey和演讲:
https://github.com/SXKDZ/awesome-self-supervised-learning-for-graphs;
基于PyTorch的图对比学习库:
https://github.com/GraphCL/PyGCL;
参考资料:



07 问答环节
Q:目前图自监督学习模型对比如传统DeepWalk这类network embedding的方式在效果上有很明显的提升,你认为这是因为GNN encoder更为强大,还是目前自监督学习的技术相较于之前的传统自监督学习的技术有一个很大的提升?
A:传统的DeepWalk这类方法无法对attribute信息进行建模,想要利用到属性信息只能将节点特征直接拼接至结构特征中。但是我们发现这一简单的做法其实在某些数据上对最基本的DeepWalk模型也有很大的提升。这一结果表明利用attribute信息对模型效果的提升很大一方面取决于数据集中attribute特征是否重要。GNN的encoder擅长得到图结构特征和属性特征的更强大的表达,但是structural的信息足够重要的话,传统图学习的方法的效果也能接近使用GNN encoder做特征提取的效果。对于另一方面,模型的效果与数据集的规模有关。例如OGB这类规模较大的数据集,其图的半径较大。GCN这类模型受到图的感受野的限制较大,堆叠几层GCN只能学习到图的局部特征的表达;而node2vec这类方法通过随机游走可以采样到更多、更深层次的信息。这时,基于GNN的方法甚至还无法接近类似于node2vec的传统图学习方法。
Q:在推荐系统中有什么样的需求才会考虑去使用图对比学习的方法?
A:如果数据集中存在长尾分布,例如缺失user-item的交互、交互集中在热门items等,我们可以结合因果推断的方法使用对比学习的手段来提升模型效果。此外,针对冷启动问题,是否有必要将图的数据加入值得研究。因为在data augmentation中采取的方法是删边,但是如果我们删去的边本身对模型的学习有着很大的帮助,这一操作反而会使模型最终效果变得更差。总体来说,推荐系统其实也可以看做一个类似于自监督学习的范式,我们使用t时刻的数据来预测t+1时刻的行为。如果再加入一个基于自监督学习的对比学习有可能有些多余,但是这一方法值得去尝试。
Q:可不可以在如推荐系统中常见的异质图或者时序图上做对比学习?
A:我们也尝试了在图的multi-view上进行对比学习,目前正在评审过程中。如果对推荐系统中时序数据进行对比学习时,一个值得注意的点是如果单纯地将不同session之间或者不同augmentation之后生成的view之间直接作为负样本其实不是很合理。在推荐系统中我们基于的假设是相似的用户具有相似的user-item交互特征,但是我们要是十分武断地将其他y用户的session中的交互作为负样本便很不合理。所以,推荐系统中负样本对的选取需要考虑到推荐中的知识,例如计算用户兴趣等。
Q:基于图的预训练模型目前都采用自监督学习,你对此有什么看法?
A:图的数据与CV中的数据不同,领域与领域之间图结构的差异巨大。CV中针对图像的先验很容易迁移,但是图中的结构在不同领域呈现的结构特征千差万别。目前使用预训练做迁移学习的图模型均是在相似的领域中进行,例如医药生物领域。另一方面,对比学习只是图迁移学习的一种方法。有作者提出对比学习不一定是图预训练的最佳选择,效果取决于目标数据集的特征。总而言之,我认为针
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9B%BE%E5%AF%B9%E6%AF%94%E5%AD%A6%E4%B9%A0%E7%9A%84%E6%9C%80%E6%96%B0%E8%BF%9B%E5%B1%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


