回顾百度智能写作如何通过人工智能技术为媒体内容创作赋能

分享嘉宾: 彭卫华 百度 主任研发架构师
编辑整理: 马宇峰
内容来源:百度大脑&DataFun AI Talk《 智能写作:人工智能为媒体内容创作赋能》
出品社区: DataFun
注:文末附有百度知识图谱部的职位信息,感兴趣的小伙伴可以关注下。

百度知识图谱致力于构建最大最全最好的中文知识图谱,汇聚知识,连接万物。通过知识映射真实世界、理解世界,让复杂的世界更简单。今天我主要分享知识图谱部智能写作方向的相关研究工作和应用实践。
近几年国内外的各大科技公司与媒体公司都纷纷布局智能写作,例如国外的美联社,国内的新华社,技术公司BAT等等。为什么智能写作如此受到关注,它能为媒体内容创作带来什么样的价值,下面开始我们的分享。
背景:
随着科技的发展,人工智能已经进入到认知阶段,AI不仅仅被认为是一种算法、平台、解决方案,也是一种生态和生产力,可以大大推动传统产业的进步并改造它。
从最初的运算智能,到后期的感知智能(人脸识别、语音识别),再到当前探索的认知智能,有了长足的发展。然而,机器目前还无法与人类一样理解思考,也无法无中生有创造出新的知识,所以目前我们仍处在弱人工智能阶段。尽管如此,AI已经展示出其强大的生产力,并已经涉足到我们的各个生活场景中,包括智能搜索、智能推荐、智慧医疗等,也包括我今天要介绍的智能写作。
写作任务大概可以从“采集、构思、表述”三个阶段来描述,无论是侧重于权威性的机构媒体,还是拥有独特风格的自媒体,都一直饱受创作效率的困扰。受限于主题选材、写作过程中出现的敏感词、错别字等因素,创作内容的成本一直居高不下。在自媒体领域,由于消费者关注力的马太效应,部分自媒体创作者逐利而去蹭热点,导致中长尾内容不足。例如文章配图,一些创作者找图片是直接在百度图片里面搜索,再选择粘贴到文章中,这样的创作效率是极为低下的,消费者的马太效应对整个内容的中长尾生态也影响较大,长期来看损害内容与流量的生态价值。
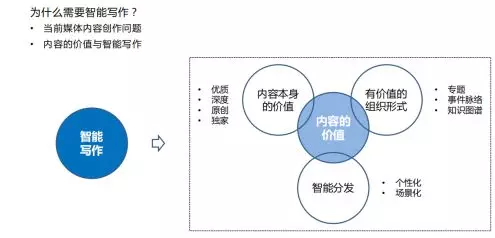
从内容价值的角度出发,可以简单理解为:
1. 内容本身的价值(质量、深度等);
2. 有价值的组织形式(专题、脉络、知识图谱等);
3. 内容的智能分发(个性化、场景化)。
针对这三种场景,智能写作均可以发挥它的作用。创作过程中,可以提升效率;组织过程中,可以自动化组织;智能分发中,可以应用动态内容生成的技术,让用户对分发的内容更感兴趣。
现阶段,智能写作相比于人类,还有很大差距,人类擅长进行长文本、情感类的文章写作,写出高质量的有个性的文章。智能写作在信息与数据的处理上更占优势,可以大大提升聚合、时效类文章的创作效率。
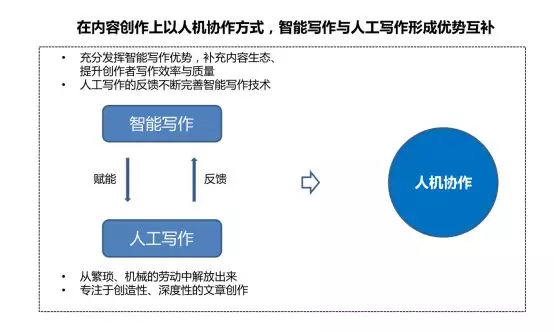
智能写作可以通过人机协作的方式,有效地将智能的效率优势与人工的创造性、深度性结合起来,降低人工繁琐、机械的劳动,不断补充优化内容生态。
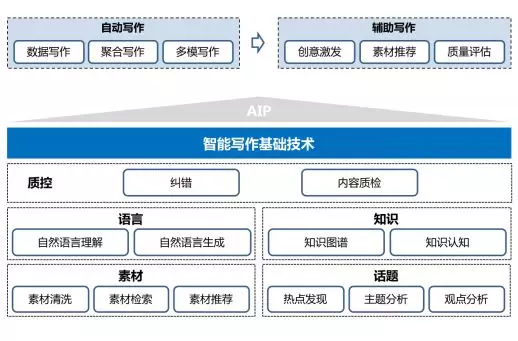
从技术布局上来讲,主要分为两个部分,基础技术部分与智能写作部分。其中基础技术包括语言理解与生成、素材清洗与检索、知识认知与话题挖掘,并且需要有一定的质控保证。语言部分的技术是核心,延展开非文本类数据之外,是多模理解与多模生成。智能写作部分主要包括自动写作与辅助写作,前者主要用于数据写作、聚合写作,后者主要体现在创意激发、素材推荐、质量评估等场景上。
自动写作部分

自动写作服务于内容生态,并已经在百家号、阿拉丁、地图等多个业务场景下落地。从产出的文章类型来看,主要分为快讯类、聚合类,此外还会包括科普类、视频转写的一些内容。
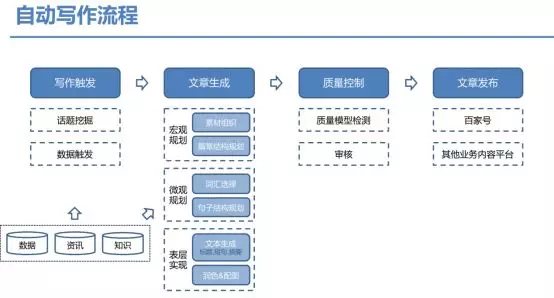
从写作的流程来看,首先是写作触发,接着文章生成,然后是质量控制,最后是文章发布。其中最开始的是写作触发,具体包括热点发现、主题分析、观点分析等,以生成满足用户需求的文章。此外最重要的部分是文章生成,分为下面三个部分:
1. 宏观规划,具体包括素材组织与篇章结构规划;
2. 微观规划,具体包括词汇选择与句子结构规划;
3. 表层实现,具体包括文本生成与润色配图等。
素材组织依赖于知识驱动产生的主题关联,文本生成则依赖于自然语言生成,结合通识知识图谱与行业知识图谱,以及包含事件等因素的复杂知识图谱,来完成文本到文本、数据到文本,以及多模到文本的文章生成。
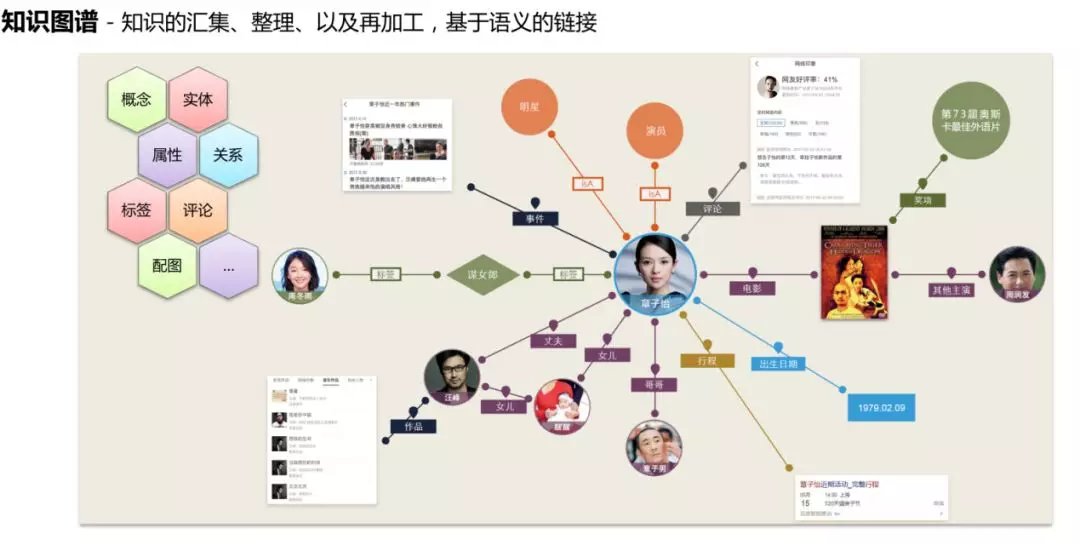
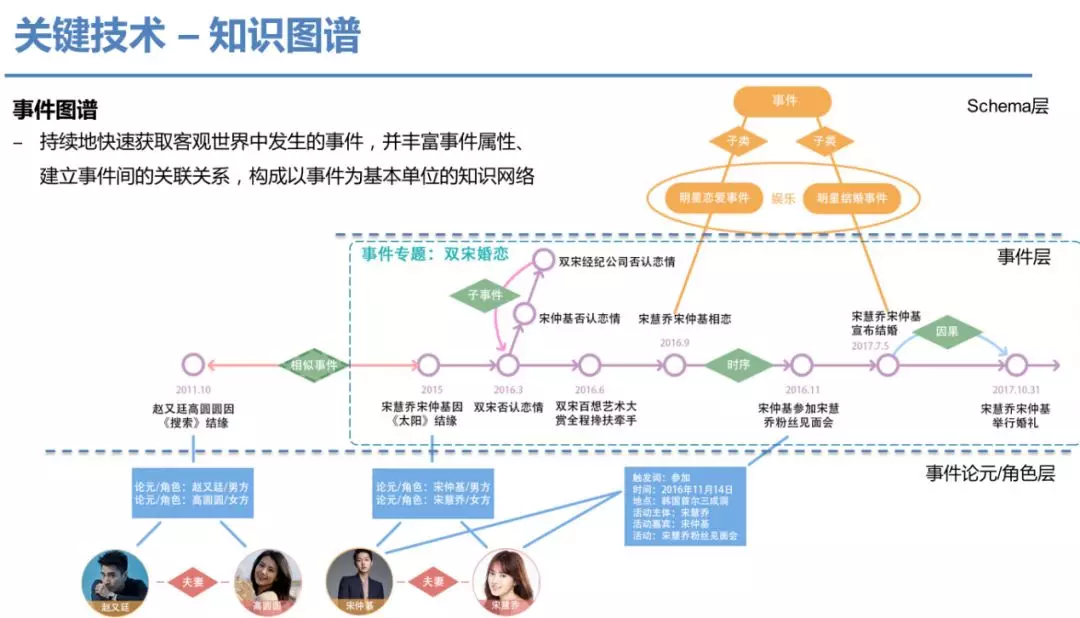
在深入写作关键技术之前,首先我们探讨下知识图谱的定义。简单来说,知识图谱就是知识的汇集、整理以及再加工,图谱中的每条边,均是基于语义的链接,是一个极其复杂的知识语义网络。事件图谱与传统知识图谱完全不一样,可以持续地动态地获取客观世界的事件,并丰富事件属性、建立事件间关联关系,构成以事件为基本单位的知识网络。目前百度知识图谱数据包含亿级别实体以及千亿级别的事实,以专家权威、百科实体、垂类挖掘与全网属性挖掘为组成部分,可以做到高时效性的秒级更新,在智能写作中扮演着核心角色,贯穿智能写作的全部流程。
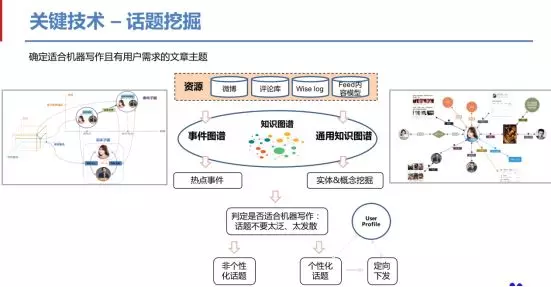
下面简单介绍下话题挖掘,话题挖掘是指挖掘提取出用户有需要的、且适合机器写作的主题。首先从微博、feed内容等资源中,通过知识图谱提取、匹配出热点事件与概念,接下来判断是否适合机器写作,过滤掉太发散、太泛的话题;生成的话题包括非个性化与个性化的话题,其中个性化话题是通过用户画像进行定向下发。
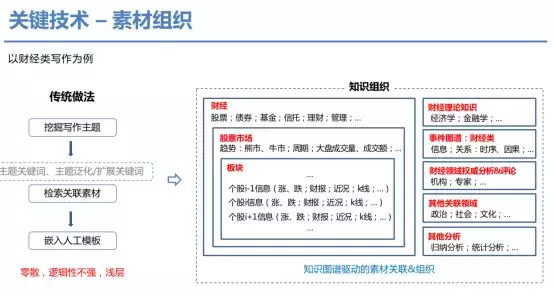
第二主要介绍素材组织。以财经类写作为例,传统做法是首先挖掘写作主题与相关关键词,通过检索关联素材,嵌入人工模板中,得到的文章往往零散而逻辑性不强,浮于浅层。在我们的做法中,主要通过知识图谱来驱动,通过事件触发,匹配财经、市场、板块等领域素材,进一步融合理论知识与权威评论,考虑一些归纳分析等方法,得到最终的素材关联与组织形式。
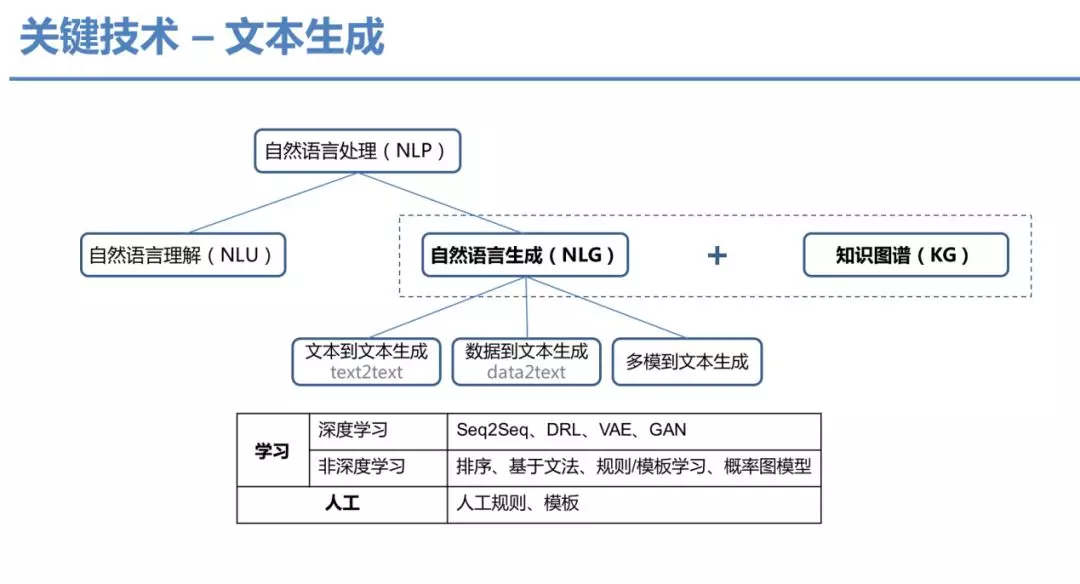
第三个关键技术是文本生成。文本生成的关键技术主要是自然语言生成(NLG)与知识图谱(KG)。自然语言理解(NLU)与自然语言生成(NLG)是我们常用的自然语言处理(NLP)的两个主要方向。NLG主要包含text2text、data2text、多模到文本三种形式,考虑知识图谱作为先验知识进行相关生成。从人工方案角度讲,主要有人工规则与模板两种。从机器学习方法上来讲,深度学习方向主要包含:seq2seq、DRL、VAE、GAN等相关技术,非深度学习技术方向包括:排序、基于文法、规则/模板学习、概率图模型等。
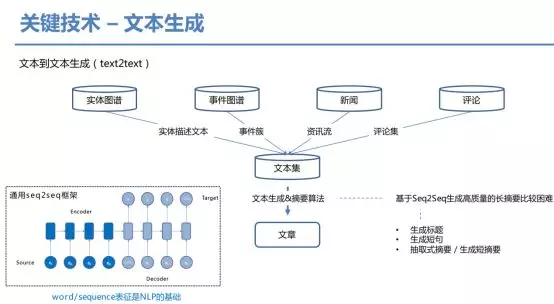
下面详细介绍文本生成的相关技术,主要是text2text的形式。首先通过实体图谱、事件图谱、行文、评论集等数据源获取文本集,接下来通过文本生成和摘要算法获取相应的文章。当然基于seq2seq的方法生成高质量的长摘要比较困难,但可以生成短句与标题。也可以通过抽取式摘要的方法,生成相关短摘要内容。可以看到seq2seq主要依赖于encoder与decoder两个步骤,贯穿其中的是sequence的表征,学习这种表征的方法我们称之为表示学习。
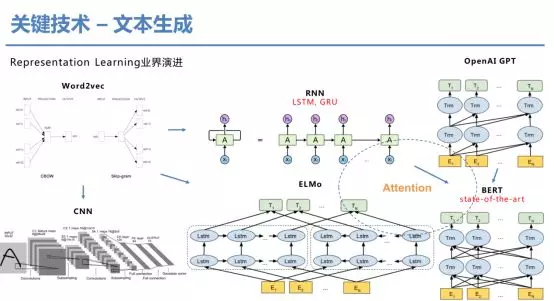
表征学习在近几年得到非常快速的演进。比较早期的word2vec模型,它可以有效地计算单词之间的语义相似度,但由于是词袋模型丢失了词的依赖关联关系;CNN模型可以局部建模词的依赖关系,但无法解决长距离依赖问题,应运而生的是RNN模型,以及配套的LSTM、GRU方法。去年一个重大的突破就是ELMo,提出解决一词多义的问题,突破了word2vec只有单一embedding的限制。然而基于RNN的方法其并行化做得不够,并且各种基于RNN的改进方案均无法表现出类似于人类的注意力感知机制,后续就诞生了transformer方法,诞生了GPT模型,然而其只考虑了单向学习。最终的集大成者是BERT模型,考虑了一些巧妙的创新,融合了前面的各种改进,得到了当前最佳的表示学习模型(计算复杂度相当高)。
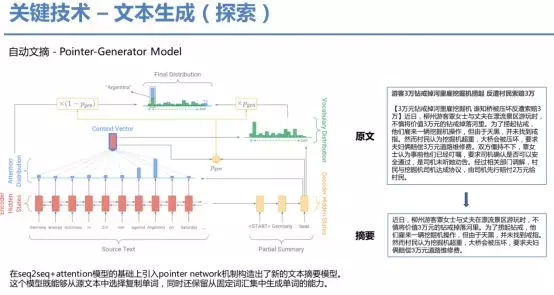
下面介绍目前我们在探索的摘要生成方法。其是在seq2seq+attention模型的基础上引入pointer network机制构造出了新的文本摘要模型。这个模型既能够从源文本中选择复制单词,同时还保留从固定词汇集中生成单词的能力,在loss上对重复出现的词进行打压,取得了不错的效果。
接着介绍我们是如何从事件脉络生成聚合类文章。针对嫦娥四号发射时间,首先从事件图谱中检索相关的时间点与事件,生成相应的事件脉络。之后通过篇章规划、自动文摘,生成相关的聚合文章,这个流程也可以用在娱乐明星的新闻生成上。
之后介绍的是data2text方法。主要还是基于模板的方法进行生成,首先通过对现有资讯中的文本组织形式学习,通过bootstrap算法自动生成相关的模板,再加以人工修正与设置触发条件。当有新的数据进入,则根据模板生成相应的文章。
然后介绍的是多模到文本生成方法。主要依赖于知识图谱与视频理解技术,通过视频分析,从标题、关键帧、字幕等数据源,获取相应的多模实体解析。再通过知识图谱进行关联,进行联合推断产出相关的文字。
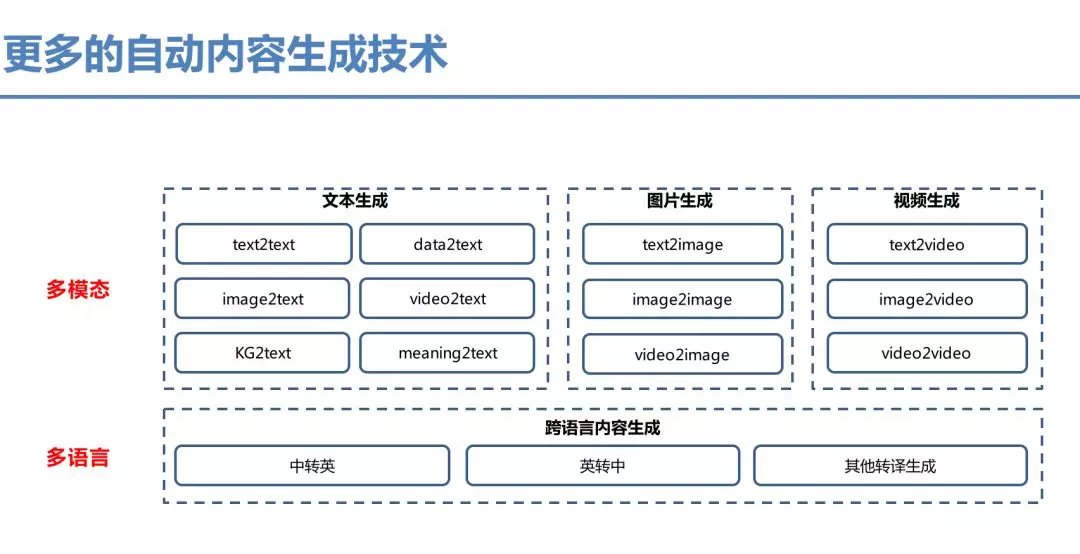
整体说,内容生成技术主要从两个角度考虑,多模态的理解与跨语言内容的生成。多模态包含各种数据到文本的技术,包括视频、图片、数据等。跨语言的内容主要包含各种跨语言转译的生成技术。

目前自动写作秒级生成文章,中长尾内容占比提升2倍以上,累计发文量百万量级,累计阅读量十亿量级,日均产出千级别文章,日均阅读数百万量级,覆盖数十类领域,点展比略好于人工,阅读完成率略差于人工文章。
辅助写作
辅助写作主要是指输出智能写作技术,赋能内容创作者提升写作效率与质量。已在百家号、若干媒体落地。与智能写作不同,主要面向于人配合完成写作相关步骤。
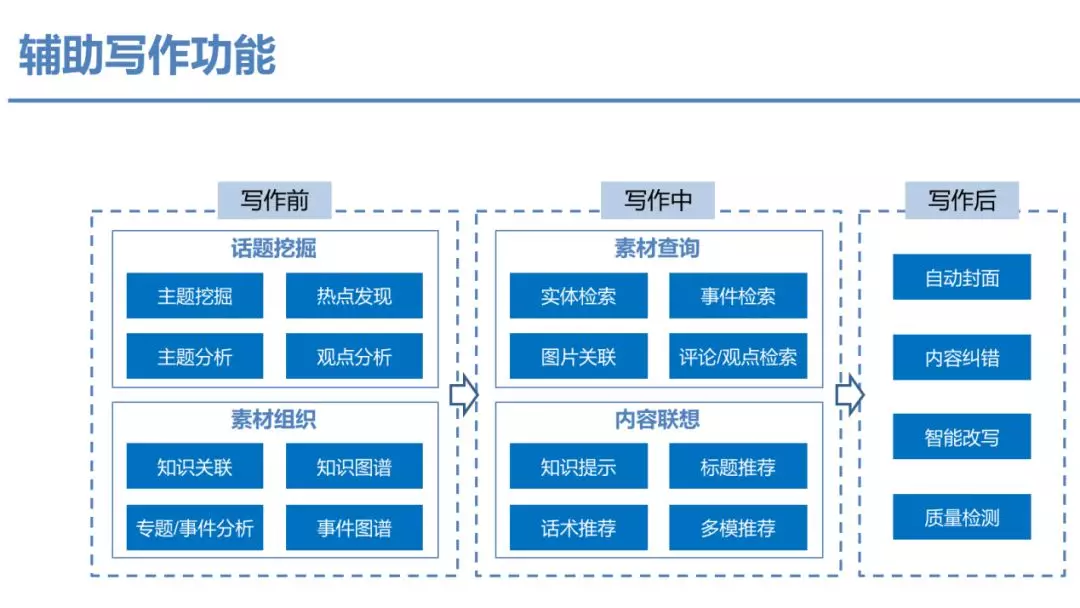
辅助写作�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9B%9E%E9%A1%BE%E7%99%BE%E5%BA%A6%E6%99%BA%E8%83%BD%E5%86%99%E4%BD%9C%E5%A6%82%E4%BD%95%E9%80%9A%E8%BF%87%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD%E6%8A%80%E6%9C%AF%E4%B8%BA%E5%AA%92%E4%BD%93%E5%86%85%E5%AE%B9%E5%88%9B%E4%BD%9C%E8%B5%8B%E8%83%BD/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


