回顾机器学习与推荐系统实践

分享嘉宾: 刘志强奇虎360 推荐算法架构师
编辑整理: 周峰
内容来源: DataFun AI Talk《机器学习与推荐系统实践》
出品社区: DataFun
注:欢迎转载,转载请注明出处。
1. 摘要
本次分享内容为机器学习在推荐系统的应用。主要介绍推荐系统实践中遇到基本问题,以及基于机器学习技术的解决方案。过程中涉及到“概率图模型、神经网络等”等方法在解决“用户冷启、精准兴趣与个性化、资源协同”等问题中的取舍。最后指出如何对实际的推荐系统进行有效的评估等问题。
2. 推荐系统
2.1 推荐系统介绍
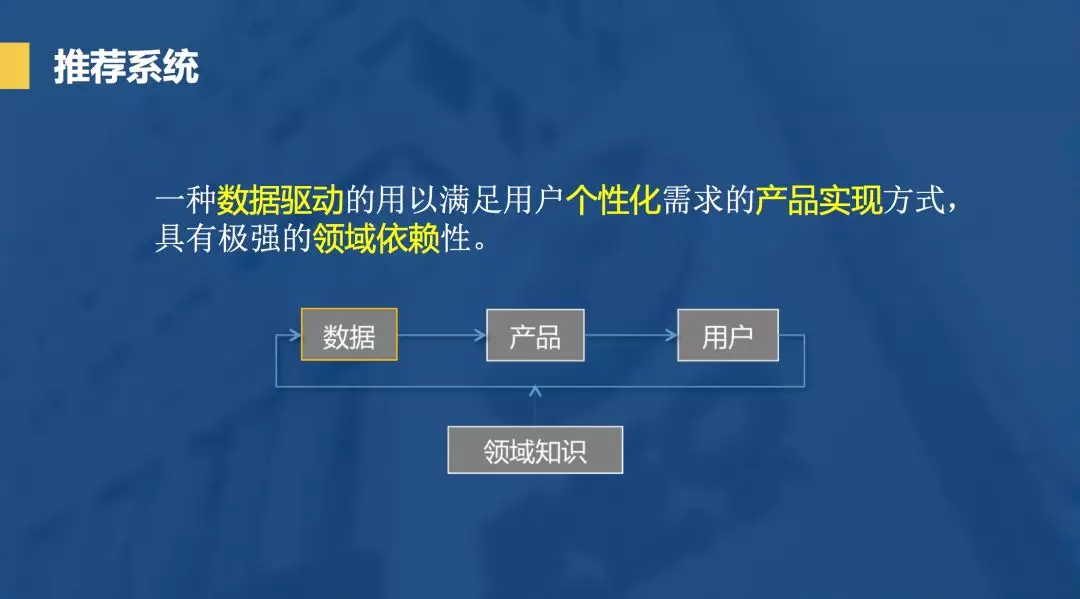
推荐系统不仅仅是推荐算法,我们应当将其看成一个产品。或者说它是一种数据驱动的用以满足用户个性化需求的产品实现方式,有极强的领域依赖性。好的推荐系统要了解用户,理解用户, 尊重用户。
2.2 推荐系统问题
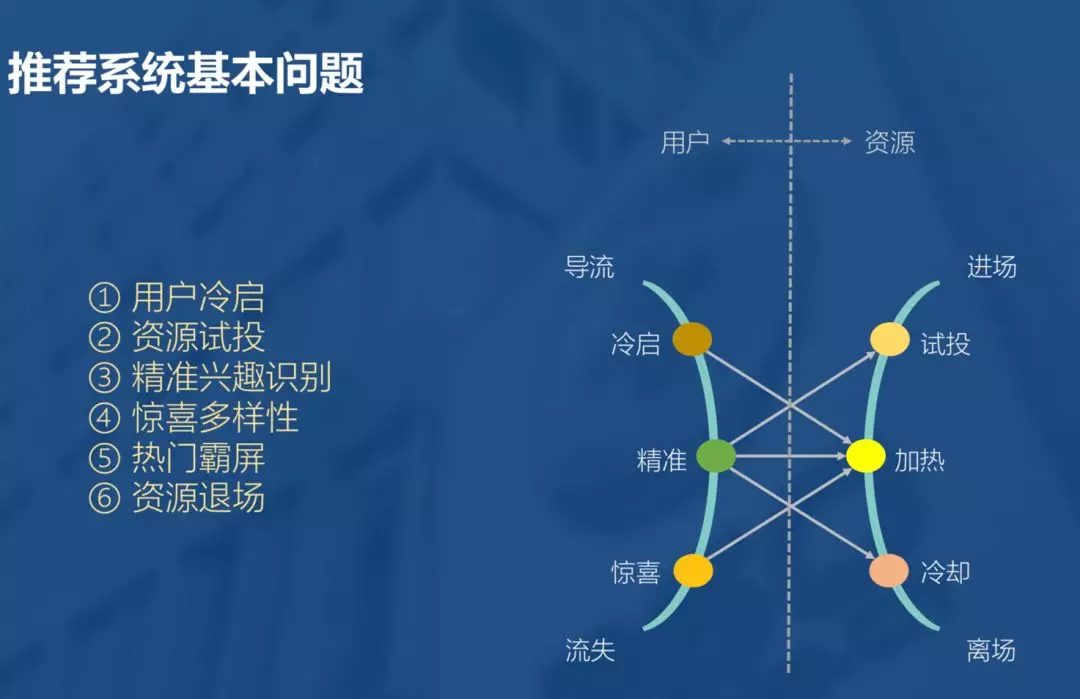
推荐系统本质是将人和物品关联起来,而系统对用户的理解也是由浅入深,初来时彼此陌生,需要有一个冷启的过程,逐渐把握用户的喜好。随着用户行为的丰富,系统对用户兴趣的描述也越来越客观,此时便可能得到更准确的用户偏好,进而完成更精准的推荐。然而物极必反,用户对于一个平台的认知与期望也是一样。随着用户的深度使用,势必对推荐系统生出更高的期待和要求。这时,便可能需要系统在满足深度用户某种刁钻的口味,与大众用户的普遍期待中做出某种取舍。用户也就不可避免的出现了流失。因为系统的能力终归有限,而用户的期望无限。
此外资源也会经历类似的过程,新进场的资源虽然天然有某种内容的属性,但其被用户接受,仍然不可避免需要经历一个过程。过程中有些资源会被淘汰,有些则会成长为热门。在不断地引入新资源的过程中,再热门的资源都会有过期的一天。就好比,再会保养的人,也逃不过岁月的流逝。甚至,为了保持系统的实时性,热门的资源需要主动地让出在系统中的曝光份额。
在推荐系统的优化过程中,用户的取舍与资源的冷热,都是需要仔细设计以服务于系统的整体目标。
3.算法实践
3.1 用户冷启动
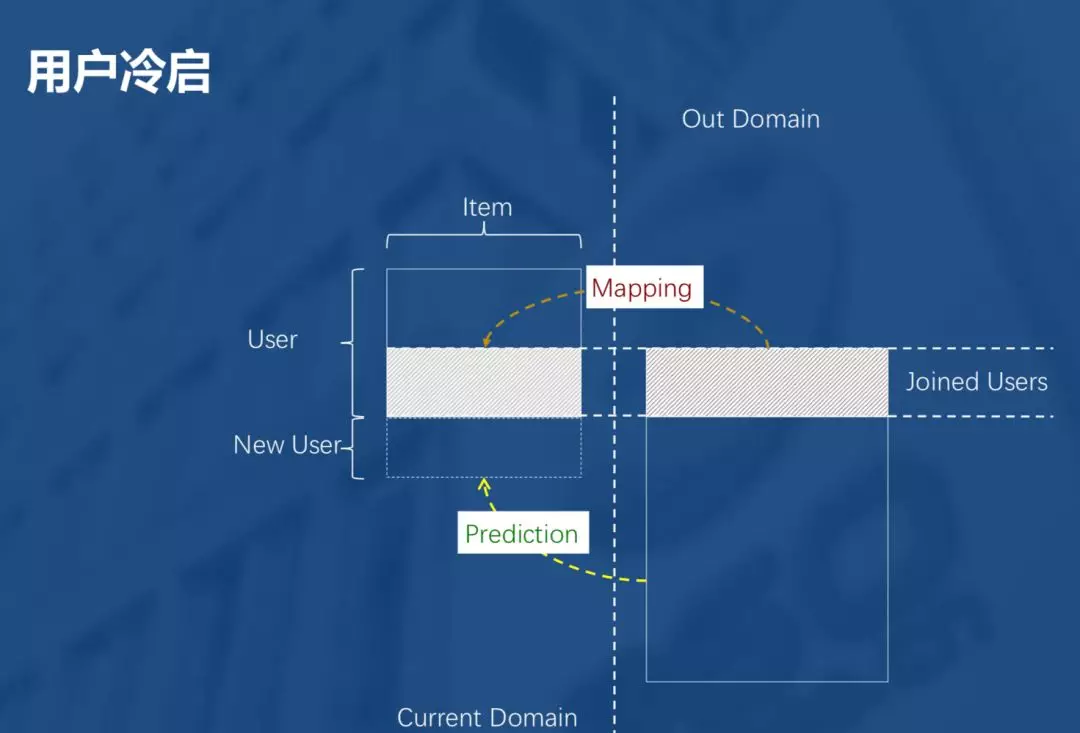
如图,将用户和物品抽象成一个User-Item的矩阵,表达用户users对物品items的喜好程度。用户冷启动要解决的是当来了新的用户new users,如何得到新用户对物品items的喜好程度。一个常见的解决办法是能不能从其他维度或领域的数据来判断新用户对现存物品的喜好。具体解释就是某个用户可能在已有领域current domain和另一领域out domain都有相关行为,可对两个不同领域的行为建立一个mapping,当新用户来的时候,如果在另一领域有相关行为,可用该mapping作出prediction,得到新用户对item的喜好程度。
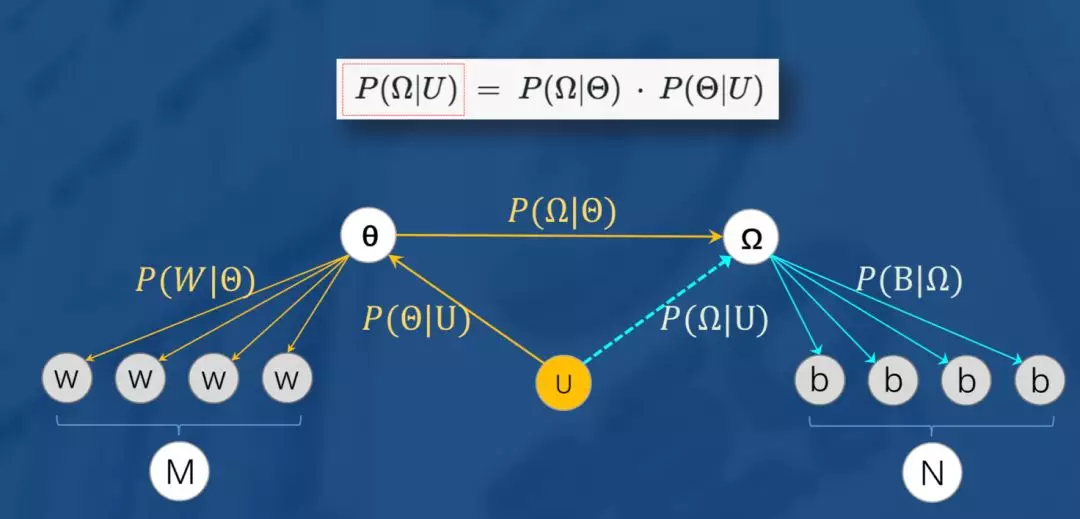
数学上对mapping进行建模如上图,用户U喜欢的M个W依托于用户兴趣分布,只要得到映射,这样便可以通过公式间接得到, 我们再将这个模型抽象成如下概率图模型。
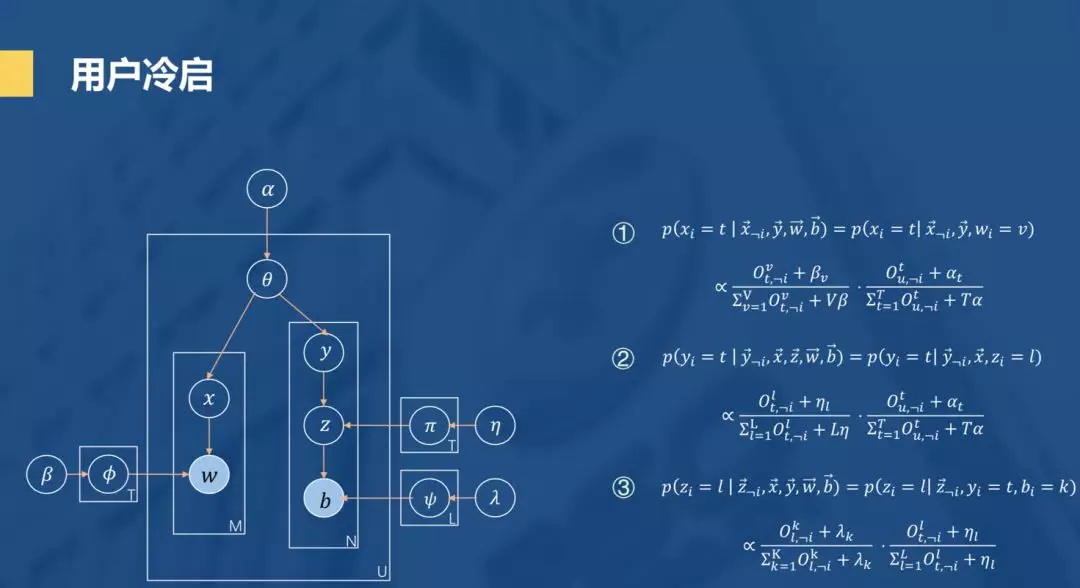
可以发现,如果只看左边这就是就是一个LDA主题模型。先对LDA主题模型做个简单介绍,是每篇文档的主题分布的共轭先验分布(dirichlet)超参数,表示文档的主题分布,x就是文档当前词被赋予的主题,是一个隐变量,是每个主题的词分布的先验分布(dirichlet)超参,就是主题的词分布,它与决定词主题的X共同决定产生的当前词W在我们的推荐场景中的概率,我们可以把每个user看作一篇文档document,文档的主题也就是user的喜好,概率图中词w就是具体的item。
接下来我们再来看右边, Z为增加的隐变量,通过映射π,即可在的喜好分布中得到另一个领域的喜好分布, 最后生成在另一领域的喜好物品b。模型的迭代用图中右边的三个公式得到。
具体举个实际的例子,根据新用户的搜索行为(out domain)对超市购物行为(current domain)做推荐,即通过建立从搜索的关键词到超市购买商品的映射关系,对新用户进行商品的推荐。如下图,搜索狗狗,泰迪等的用户,会对其推荐化妆品,女性服装等,比较符合逻辑。

3.2 精准兴趣
在推荐系统中,我们往往使用用户的点击行为来估计用户的喜好类型。然而用户的每次点击未必都是经过其深思熟虑之后的结果,因此行为本身会存在一个置信度的问题。而这个置信度是未知的。那我们如何建立模型表达用户的精准兴趣呢?
我们将用户点击的行为抽象为两种可能,一种是喜欢(深思熟虑置信度较高) , 另一种为随意 (偶然为之,置信度较低,或可理解为系统的bias)。我们建立如下图模型来模拟用户两种行为:
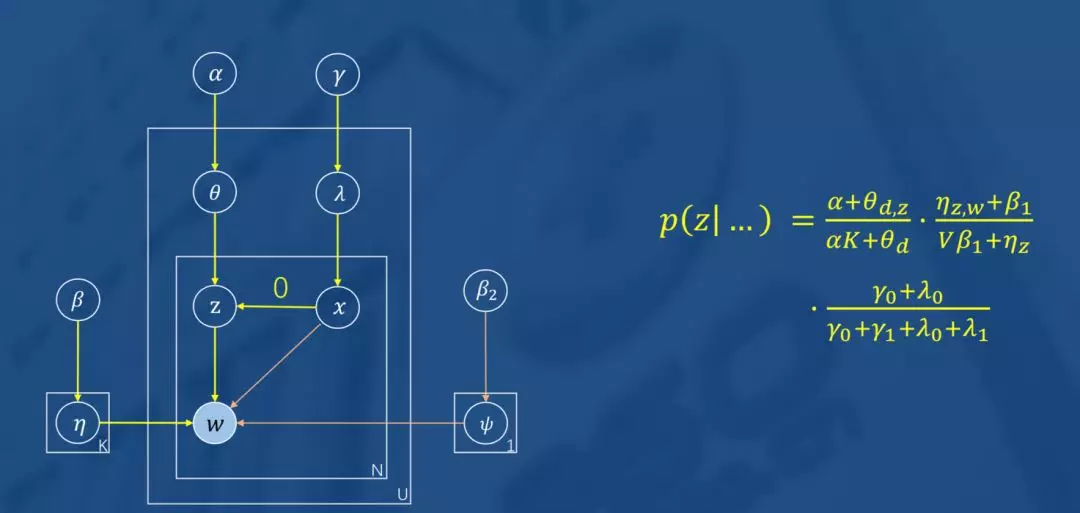
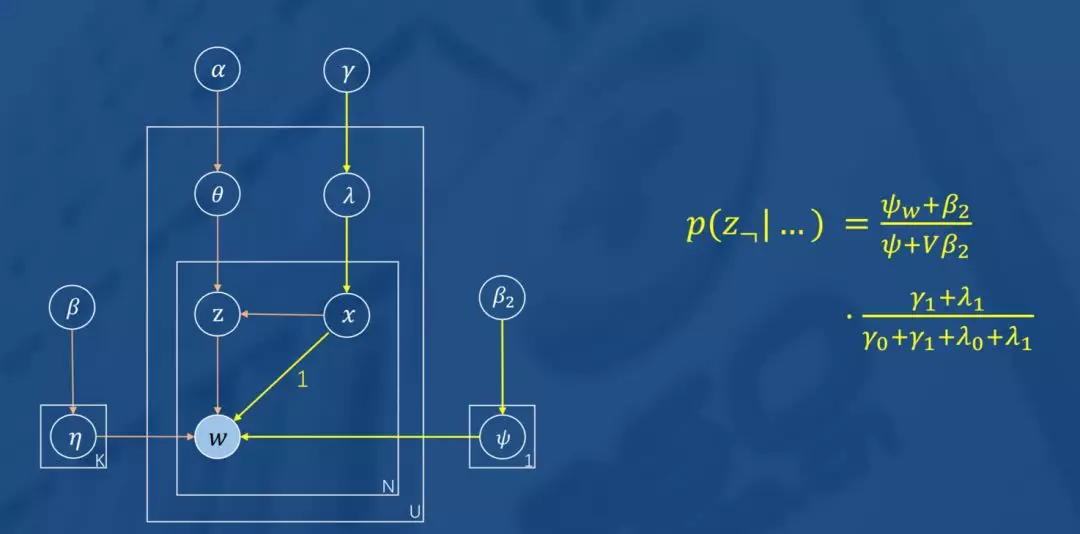
如图所示,图模型左边就是一个 LDA,右边的是一个二项分布,表示用户因为喜欢或者不是因为喜欢而产生点击行为的概率, 是的共轭先验分布(Beta分布)超参。
当分布产生的x为0时,表示用户因喜欢而点击(如上图),这时将完全按照LDA主题模型生成用户U喜欢的物品w;当分布产生的x为1时,表示用户对w的点击不是因为喜欢。迭代公式如图所示,不再赘述。
3.3 协同过滤
讲到推荐系统,一定少不了相似推荐或协同过滤。接下来我们就介绍一种根据用户点击行为序列(把不是用户因为喜欢的点击可以去掉)来构建资源之间的推荐转移关系,进而实现物品协同推荐的方案。如图所示:

我们通过拟合用户相邻点击之间“点了还点”的似然,来为每个Item计算得到一个向量表达。你可以将其理解为最简单版本的序列模型,也可以将其看成一个0,1矩阵的分解,也可以将其看成一个只有一个输入特征、激活函数为y=x,且共享输入层与输出层权值的神经网络。如图中所示,使用二项分布来描述对目标物品的点击概率,对权重,分别求偏导数得到权重更新的梯度,使用梯度迭代即可求解。
如果你觉得这个网络使用同一个W限制模型的表达能力,或者隐层不做nonlinear显得不够专业,则完全可以将模型变为如下形式。
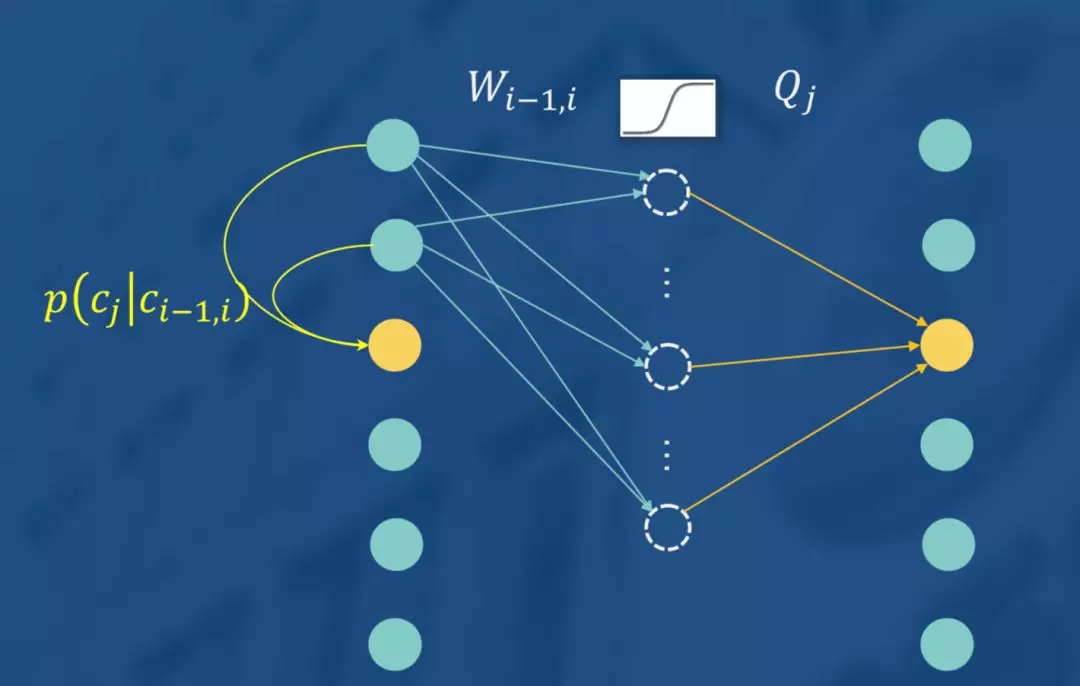
在或者,觉得不够深,则可以将模型变为如下形式:
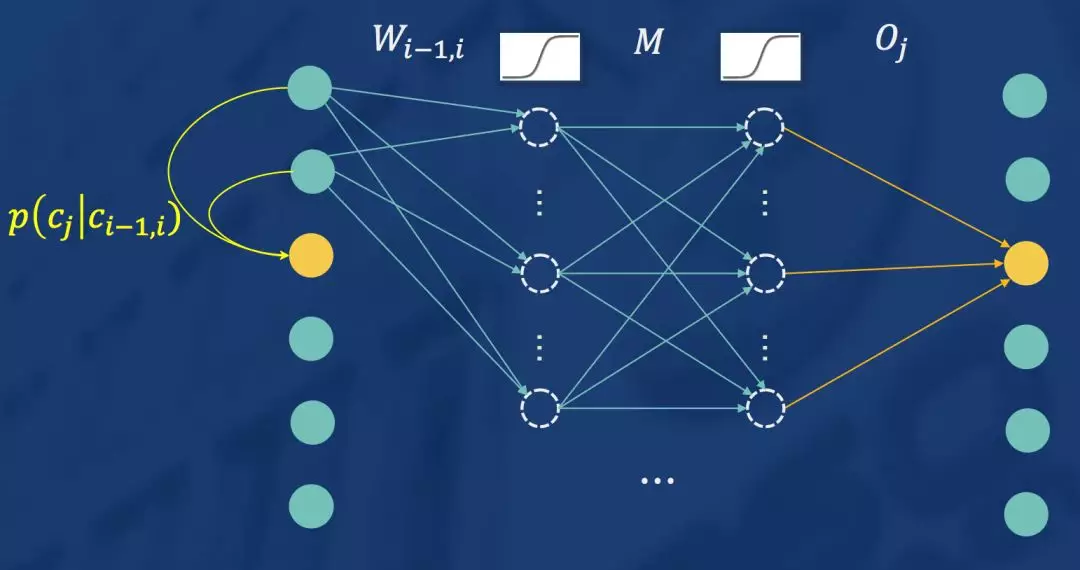
实际中,很多事情并不是“越深越好”,需要根据业务的需要做取舍。
4. 评估
4.1 离线评估
关于离线评估,这里不太想介绍具体指标和方法。更多的是我们在做推荐系统评估过程中的一些问题和思考。以及我们在做评估时需要注意的点:
1. 评估数据的选择?
是不是模型在评估数据上的表现越好,就能够代表,推荐策略或算法的表现越好?评估数据是怎么产生的,是否与系统的未来目标一致?评估数据是否存在bias?
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9B%9E%E9%A1%BE%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E4%B8%8E%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


