回顾强化学习在自然语言处理中的应用

分享嘉宾: 黄民烈** ** 清华大学计算机系副教授,博士生导师
编辑整理: 邓力
内容来源: 《Reinforcement Learning in Natural Language Processing》
出品社区: DataFun
注:欢迎转载,转载请注明出处。
本文首先介绍了强化学习的概念和相关知识,以及与监督学习的区别,然后就强化学习在自然语言处理应用中的挑战和优势进行了讨论。
1. 强化学习
首先简单介绍一下强化学习的概念。强化学习是一种与监督学习不一样的学习范式,通过一个智能体与环境进行交互从而达到学习目标。其最重要的概念包括状态(state),动作(action),回报(reward)。智能体接收到环境的状态,对该状态做出一个动作,环境根据该动作做出一个回报。
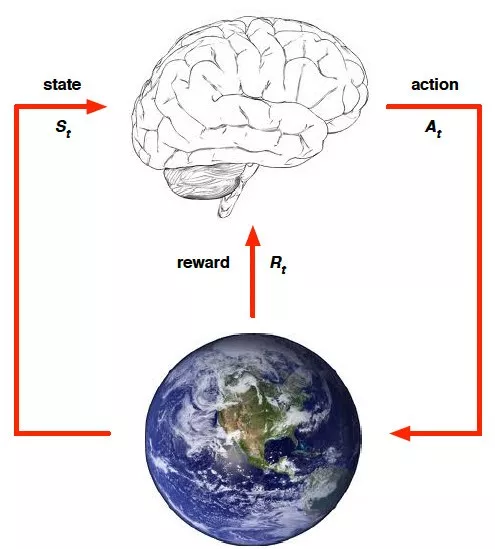
以走迷宫为例,state即为智能体所在的位置,action就是向东西南北移动的动作,当智能体到达目标位置则给100的奖励,当走入死胡同则给-100的惩罚,每走一步给-1的惩罚(希望走的步数越少越好)。在该例子中,我们并没有告诉这个智能体该怎么做,只是当它做对了给它一个大的正分,当它做错了给一个大的负分。

随着深度学习的兴起,我们可以将深度学习与强化学习进行结合从而对问题进行更好的建模。深度学习可以用来刻画强化学习中的状态,动作和策略函数。二者结合的方法在很多领域都有应用,如自动控制,语言交互,系统运维等等方面。
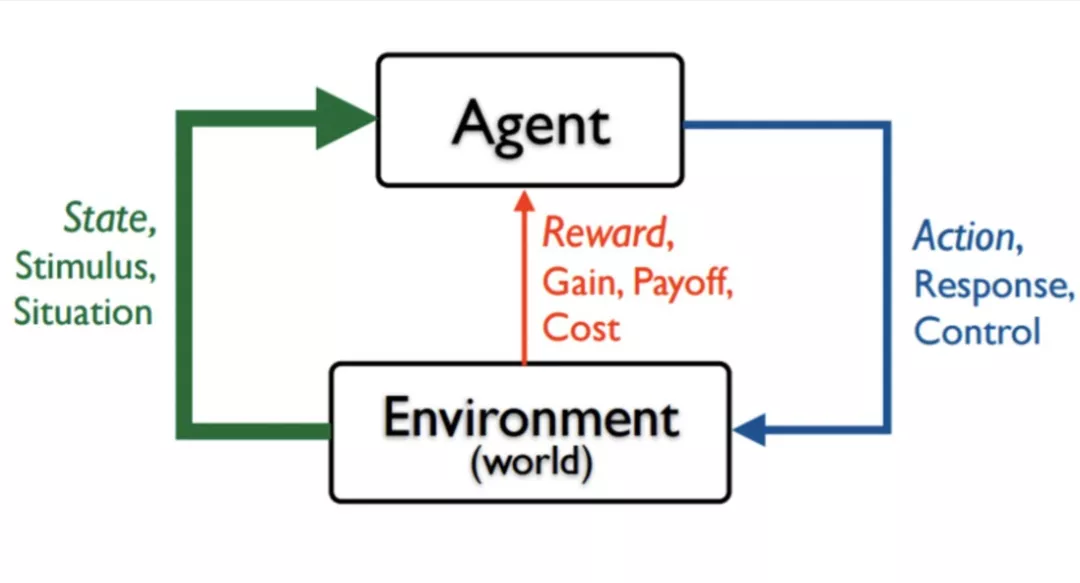
2. 强化学习与监督学习的区别
强化学习的特点:
1、序列决策,即当前决策影响后面的决策;
2、试错,即不告诉智能体怎样决策,让其不断试错;
3、探索和开发,即探索一些低概率事件,开发是利用当前的最佳策略;
4、未来收益,即当前收益可能不是最佳的,对未来来讲当前决策最佳。
监督学习就是给定一个样本集合
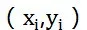 得到一个X到Y的映射。
得到一个X到Y的映射。

以游戏举例,监督学习就会告诉智能体每一步应该怎么做,是向左还是向右,但在强化学习中,并不会告诉智能体应该怎么走,会让智能体自己试错,走得好就给一个大的奖赏,走得不好就给大的惩罚。
3. 强化学习在自然语言处理中的应用
挑战
1、奖励的稀疏性问题;
2、奖励函数的设计;
3、动作空间维度高;
4、训练中的方差较大。
优势
1、适用于弱监督场景,问题中没有显性的标注;
2、不断试错调整,通过试错进行概率的探索;
3、奖励的积累,将专家系统或者先验知识编码进奖励函数。
1)强化学习用于文本分类
(Learning Structured Representation for Text Classification via Reinforcement Learning)
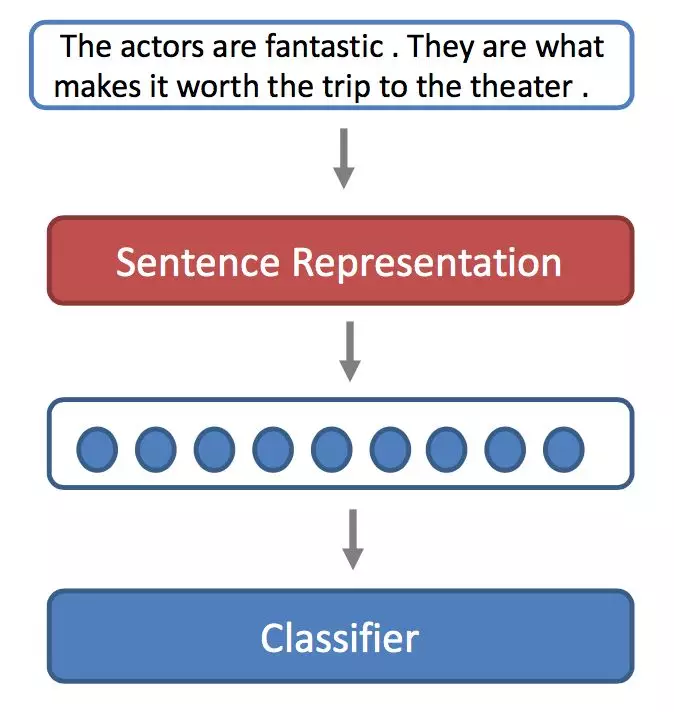
如果做一个句子分类,首先要给句子做一个表示 ,经过sentence representation得到句子表示,把“表示”输入分类器中,最终就会得到这个句子属于哪一类。
传统的sentence representation 有以下几个经典模型:
1、bag-of-words;
2、CNN;
3、RNN;
4、加入注意力机制的方法。
以上几种方法有一个共同的不足之处,完全没有考虑句子的结构信息。所有就有第五种 tree-structured LSTM。
不过这种方法也有一定的不足,虽然用到了结构信息,但是用到的是需要预处理才能得到的语法树结构。并且在不同的任务中可能都是同样的结构,因为语法都是一样的。
所以我们希望能够学到和任务相关的结构,并且基于学到的结构给句子做表示,从而希望能得到更好的分类结构。但面临的挑战是我们并不知道什么样的结构对于这个任务是好的,我们并没有一个结构标注能够指导我们去学这个结构。但我们可以根据新的结构做出的分类结果好不好从而判断这个结构好不好。
可以使用强化学习来对该问题进行建模,使用策略网络来对文本从前往后扫描,得到action(删除,切开)的序列,action的序列即为该文本的表示,利用该表示再输入分类的网络进行分类。在该应用中,强化学习的reward信号来自于文本分类的准确度。
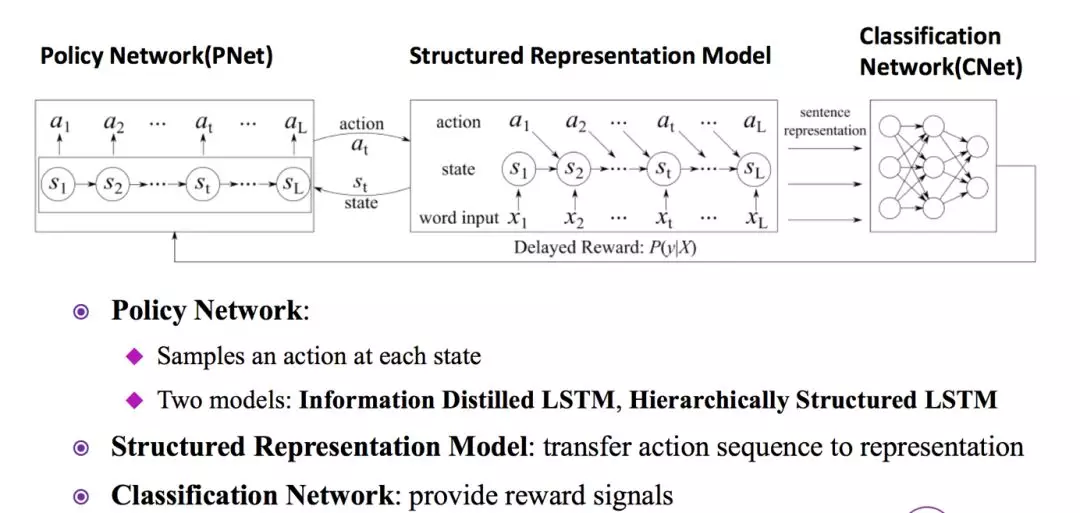
第二种结构是层次的LSTM结构。

先把字符切开连接得到短语,层层往上,所以是一种层次化的结构,其中action是(Inside,End),状态就是当前的词与上一个词的组合,奖励就是当前类别的似然概率和结构化参数。

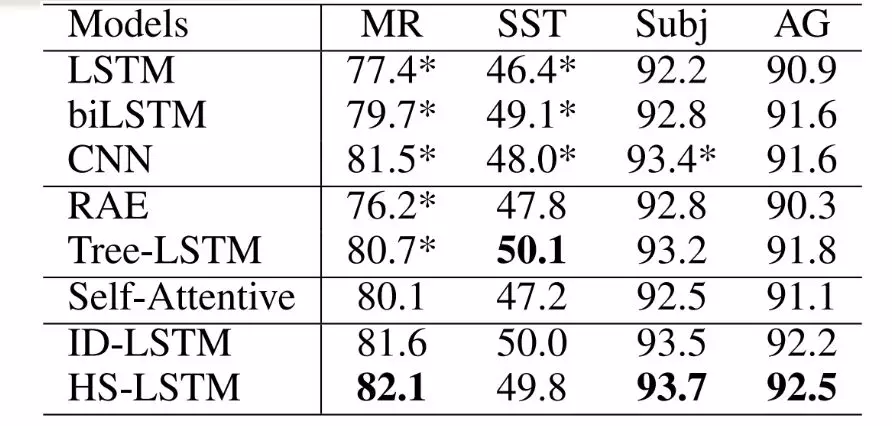
实验数据和结果:

总结
这个工作中学习了跟任务相关的句子结构,基于句子机构得到了不同的句子表示,并且得到个更好的文本分类方法,提出了两种不同的表示方法,ID-LSTM和HS-LSTM。这两个表示也得到了很好的分类结果,得到了非常有意思的和任务相关的表示 。
2)强化学习用于从噪声数据中进行关系抽取
(Reinforcement Learning for Relation Classification from Noisy Data)
任务背景
关系分类任务需要做的是,判断实体之间是什么关系,句子中包含的实体对儿是已知的。关系分类任务是强监督学习,需要人工对每一句话都做标注,因此之前的数据集比较小。

之前也有人提出Distant Supervision 方法,希望能利用已有资源对句子自动打上标签,使得得到更大的数据集。但这种方法是基于已有知识图谱中的实体关系来对一句话的实体关系进行预测,它的标注未必正确。
这篇文章就是用强化学习来解决这个问题。之前也有一些方法是基于multi-instance learning 的方法来做的。

这篇文章就是用强化学习来解决这个问题。之前也有一些方法是基于multi-instance learning的方法来做的。这样做的局现性是不能很好处理句级预测。

基于以上不足,这篇文章中设定了新模型。包括两个部分: Instance Selector和 Relation Calssifier。
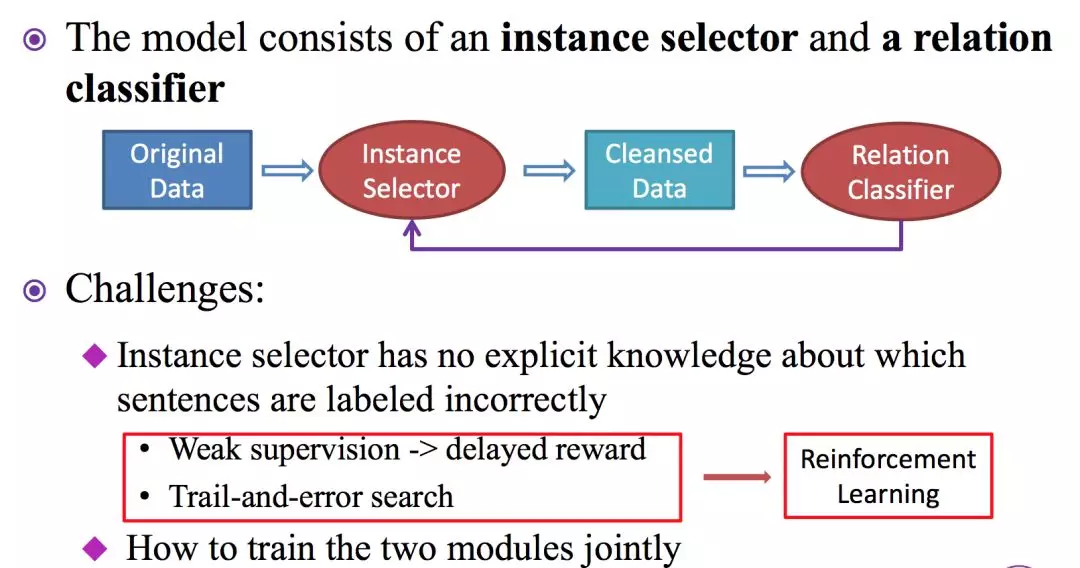
这个模型有两个挑战,第一是不知道每句话的标注是否正确;第二个挑战是怎么将两个部分合到一块,让它们互相影响。
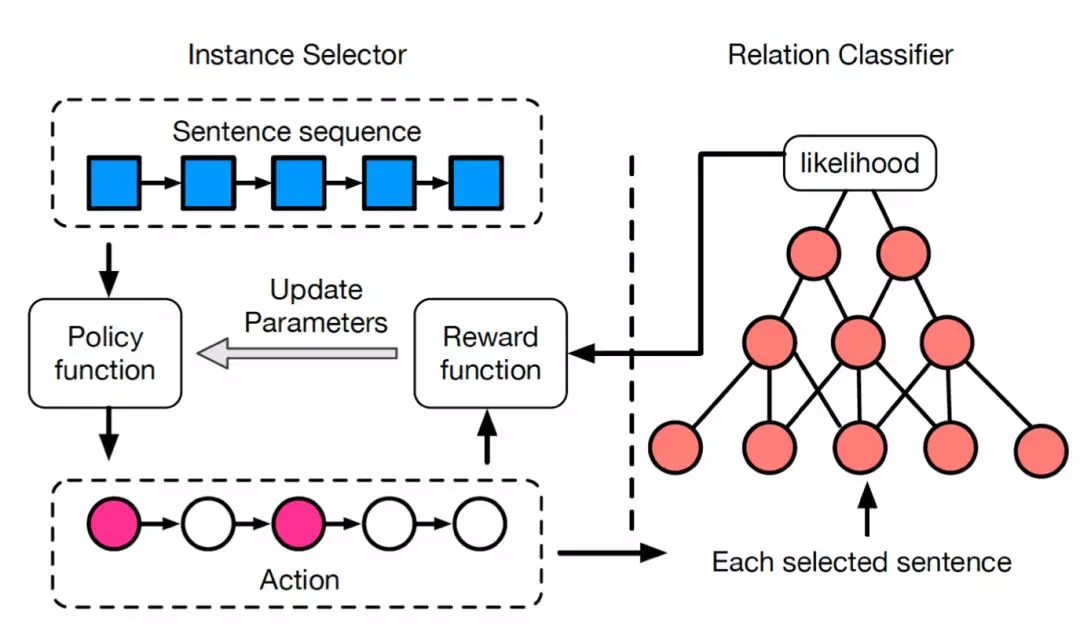
在Instance Selector中的“状态”就表示为,当前的句子是哪一句,之前选了哪些句子,以及当前句子包含的实体对儿。

Relation Classifier 是直接用了一个CNN的结构得到句子的表示。
实验以及baseline:

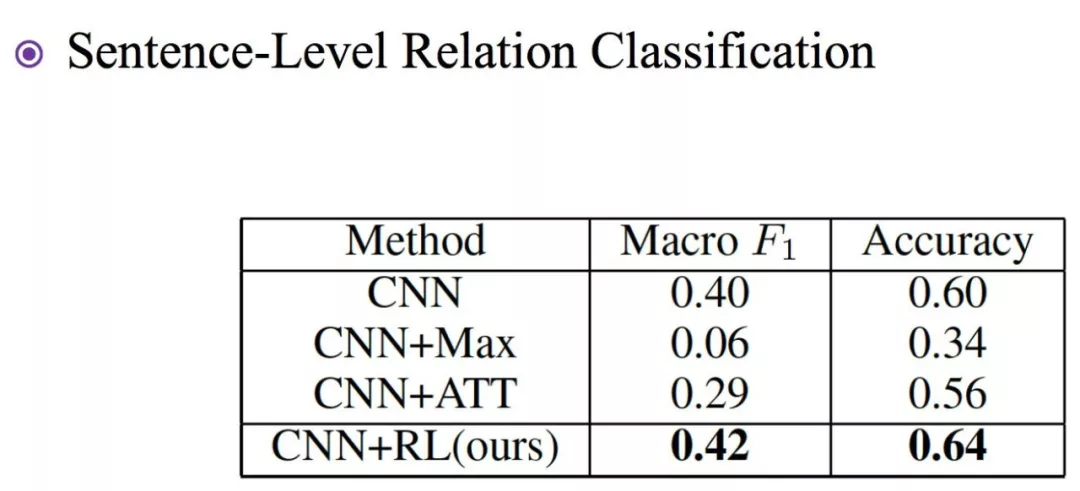
提出一个新的模型,在有噪声的情况下也能句子级别的关系分类,而不仅仅是bags级别的关系预测。
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9B%9E%E9%A1%BE%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%E5%9C%A8%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86%E4%B8%AD%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


