回顾云上冷热分离实践
本文根据阿里云技术专家郭泽晖在中国HBase技术社区第3届MeetUp杭州站中分享的《云上HBase冷热分离实践》编辑整理而成。

今天分享的内容分为两个方面,首先会介绍下冷数据的经典场景,以及如果使用开源的HBase应该如何实现,最后介绍下HBase在云端的实现方案。

冷数据定义就是访问比较少,其访问频次可能会随时间流逝而减少。如你在淘宝买的东西产生的很久以前的订单信息你可能不会去看,还有一些监控数据,当业务有问题你肯定是查最近一小时或者半天的数据,但是半年前的数据你根本访问不到。还有车联网数据一般需要保存多久,这些数据如果政府不查基本很难访问。还有一些归档信息,如银行交易记录归档信息。
我们云服务上对冷数据的定义依据成本估算而言,平均每月访问不会超过十万次,我们认为是比较冷的数据,同时对成本敏感的数据也可以做冷热分离。
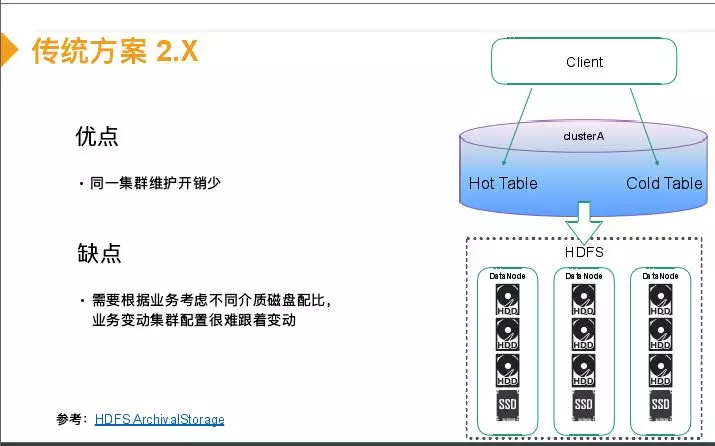
传统方案1.x版本的解决方案是采用两个集群,一个集群可能是SSD的配置,负责在线查询,延迟较低,还有一种是HDD的配置。但是这两张表之间需要进行一个同步,客户端需要感知两个集群的配置。优点是简单不需要改HBase代码,缺点是双集群维护开销大,还有就是冷集群CPU资源可能浪费。2.X版本引入一个配置,就是你可以指定表的hfile存在哪种介质上。主要是利用率HDFS分级处理功能,可以给DataNode配置不同介质的盘,可以指定表写在冷介质还是热介质上,最后在HDFS上可以依据你设置在文件上的属性决定是将数据放在机械盘还是SSD上。这样一个集群可以存在冷表和热表,这样相对于1.X版本更好管理,但是缺点是因为你要依据你的业务在集群硬件配置,这样如果一个集群混合多种业务或者业务发生变化,几群的硬件配置很难调整。
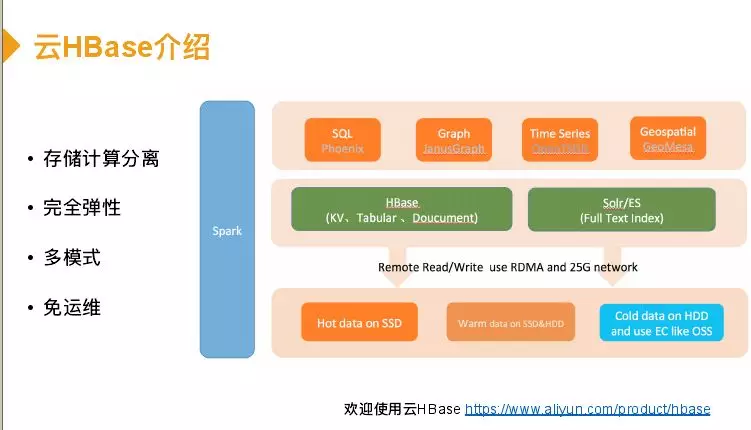
因此在云端解决方案是一个比较弹性的方案,在介绍之前先介绍下我们云端HBase。云HBase是一个存储计算完全分离的架构,底层是存储,今天主要讲冷存储,云端regionserver访问部署的节点,磁盘都是远程读的。因此磁盘大小是可以动态设置的,完全弹性。多模式是HBase云端之上除了HBase本身kv功能,还架设很多开源组件,如phoenix做一些简单的查询分析。Graph主要是应用一些欺诈场景,这个在国外比较成熟,如伪造车祸骗取保险,而图可以分析一个关系网,能够预防这种情况。openTSDB主要是物联网、车联网这些场景使用,geospatial是时空数据库,主要应用在轨迹场景。底下存储层主要是有两块,热数据或一般数据会放在云盘,冷数据是放在OSS。整个模式是一个免运维模式,上来可以直接用。
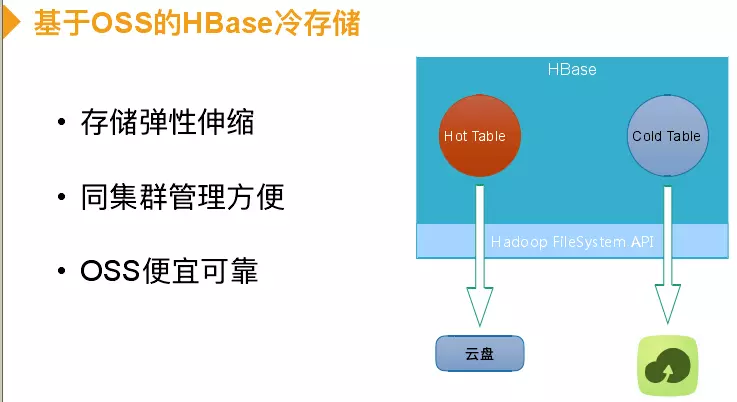
接下来介绍下OSS如何做冷存储,并没有给磁盘配置具体数目,冷表数据是直接放在OSS上,同一个集群也能实现冷表和热表。OSS是阿里的一个对象存储产品,也是一个k-v存储,特点是可以存大对象,可以达到TB级别,同时保证99%的数据可靠性,而且成本非常低。成本和云盘对比,云盘本身也保证数据可靠性,在云上自建HBase、HDFS用两副本就可以,以为你需要一个副本保证数据读取可靠性,否则一台机器宕机所有机器都挂掉。当使用云盘需要0.7,OSS只需要0.2。举例说明如某车企拥有10万辆车,每车每30秒上传7kb的包,数据半年基本不访问,三年基本存储量是2P左右,那么成本开销相差2.5倍。

如果在阿里云上使用OSS作为HBase的底层存储,Hadoop社区 Native Oss File System已经实现,这个类是继承File System,这样你可以直接替换掉,这样你的读写会直接转发到OSS上,也可以享受OSS低成本特性。但是存在几个问题,一个是Native Oss File System针对的是MapReduce离线作业场景实现,在模拟文件系统过程中会有几个问题。因为OSS是k-v存储,没有文件系统结构,“/”字符并不代表目录,只是代表对象名中某一字符。如果要模拟文件系统创建“/root/parent/son/file”,你需要创建图中右边四个对象才能模拟出目录结构,这样就导致你对目录操作不是原子的。比如你要讲“/root/parent”root到其他地方,原本是直接移走,而社区 Native Oss File System实现是一个遍历递归的过程,如果server在mv操作时中途crash只会移走一部分,导致目录文件不一致。
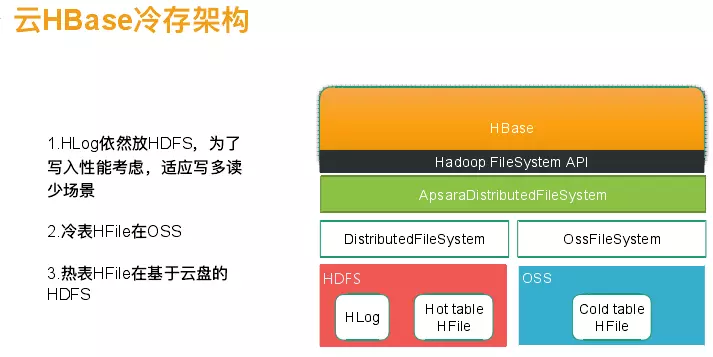
我们自己实现Oss File System方案,这种能避免原子问题。解决方案是将元数据管理还是放在HDFS上,在APP调用Hadoop File System实际是调用Apsara Distributed File System,这个实现会控制你的文件调用Oss File System就将其放到OSS里面,调Distributed File System就将其放到HDFS里面,hlog也是放在HDFS里面,主要考虑的是一个写入性能。
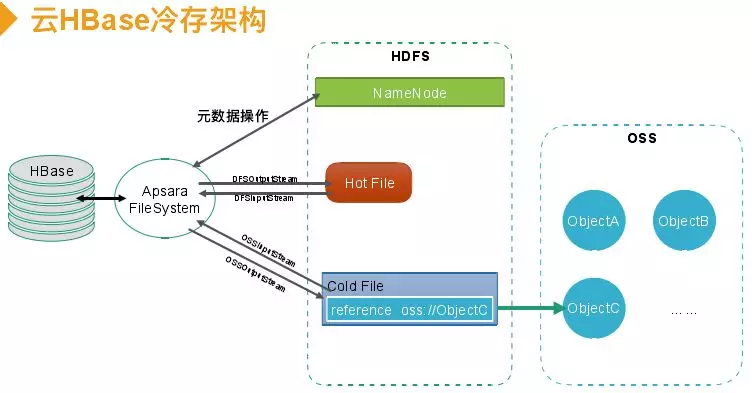
元数据操作通过Apsara FileSystem通过请求操作,如果是热表数据就是直接调Hadoop的FileSystem,直接构造HDFSoutputstream或者HDFSinputStream进行读写。如果是冷数据会在HDFS里创建一个冷文件,利用Hadoop分级存储功能会有一个属性标记,这个文件存储也是保证原子的。读取冷文件时将读的通道转发到OSS上,然后构建一个OSSinputstream和OSSoutputstream。
性能上和社区版比较也做了一些优化,实现上会有一些限制,请求OSS是有费用的,Hadoop File System是提供OutputStream接口输入数据,不断调write接口将数据写进去,OSS的sdk提供的是一个InputStream让数据输入。实现Hadoop filestream接口来嫁接到OSS上必须做一个OutputStream到InputStream的转化,社区版实现是将数据写到native OSS OutputStream里,实际是写到磁盘上,实际有个buffer文件,写满128M将其包装成file InputStream提交给OSS的SDK,会有一个异步线程池来提交buffer文件。这样存在的问题是写入过程需要入磁盘,会损耗性能;第二比较依赖磁盘性能,异步发送buffer会变成一个单线程;crash会残留这些文件,对运维比较麻烦。
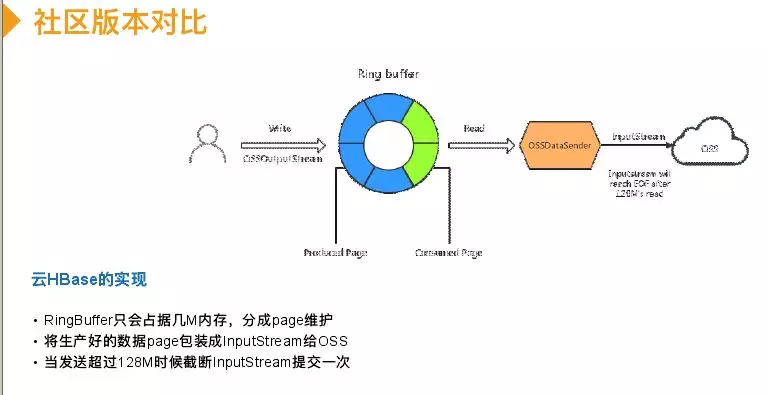
我们实现版本写入是不在磁盘落地,中间会有一个ring buffer(只有几M),用户写入到ring buffer里,里面由固定数量配置组成,有5个配置。蓝色是写入,绿色有一个异步线程将蓝色写好的数据读取出来包装成inputstream,相当于实时源源不断类似于流的形式。每当inputstream被OSS的SDK读完128M,将数据提交,然后再有数据写入再包装成inputstream。成本上都相当于128M提交一次,请求成本很低,但是写入完全不需要落地磁盘,占用内存开销也很少。性能测试写入吞吐差25%,我的valuesize只有100B。

在HBase使用这个特性,建表的时候配一下config,create ’test’, {NAME => ‘info’}, CONFIGURATION => {‘HFILE_STORAGE_POLICY’=>‘COLD’}将表变为冷表,那么所有数据都会存在OSS里面。冷存储使用场景建议是写多读少、顺序读,如果持续读会限制存储读的lops,请求是有成本的,每get一次需要到文件上see
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%9B%9E%E9%A1%BE%E4%BA%91%E4%B8%8A%E5%86%B7%E7%83%AD%E5%88%86%E7%A6%BB%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


