和假设检验流量分配
我们观测到的值,并不是我们需要的参数的真实值,而是真实值的估计(举个例子,平均值和期望);这也就意味着,估计可能是不准确的,ABtest的结果可能是错误的。直观上说,样本越多,我们可能犯错的概率越小。我们梳理了这块儿的知识,做一个学习总结。
实际业务中,我们定量下面几个问题:
1)ABtest是否置信
2)一组ABtest只需要多少样本就可以有显著性
3)怎么分配流量来进行多组ABtest计划,保证各组测试都能显著
ABtest和假设检验
1)中心极限定理和正态分布,z检验
中心极限定理说明,在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布(具体推导参考大数定理、中心极限定理)。
在样本数量比较大情况下,可以采用z检验。
ABtest需要采用双样本对照的z检验公式。

2)H0、H1假设和显著性、置信区间、统计功效
现在假设有A、B两个组,我们无法确定A、B两个组的差异究竟是某种误差引起的,还是客观存在的。所以假定:
- H0=A、B没有本质差异
- H1=A、B确实存在差异
显著性 根据z检验算出p值,通常我们会用p值和0.05比较,如果p<0.05,我们就接受H0,认为AB没有显著差异。
置信区间 是用来对一个概率样本的总体参数进行区间估计的样本均值范围,它展现了这个均值范围包含总体参数的概率,这个概率称为置信水平。
双样本的均值差置信区间估算公式如下:

统计功效power 是说拒绝零假设(H0)后接受正确的H1假设概率。直观上说,AB即使有差异,也不一定能被你观测出来,必须保证一定的条件(比如样本要充足)才能使你能观测出统计量之间的差异;否则,结果也是不置信的,具体的,可以参考下面这张图:
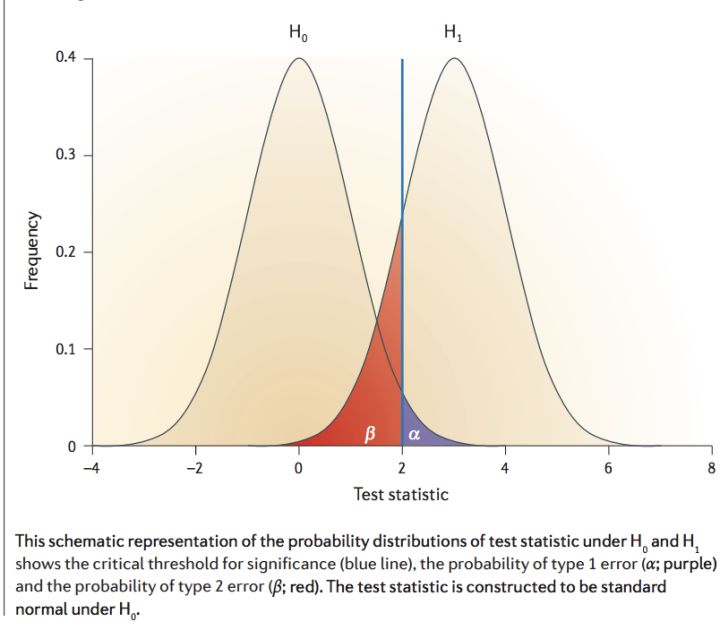
统计功效的计算公式如下:

3)版本替代决策
做完ABtest后,应该用上图中的置信区间,和期望收益比较,做版本替代决策。
比如新版本的期望收益是2%,而检验后置信区间是[16%,20%],那我们有理由替换旧版本。
业务中,我们的ABtest检验工具如下图所示,算法人员选择AB组就可以一次计算完相关检验参数:
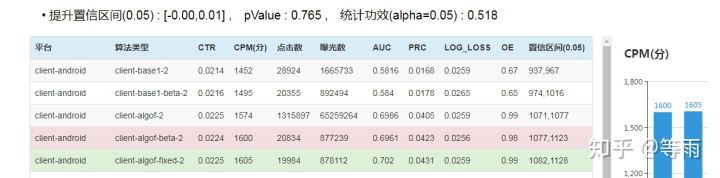
ABtest的流量分配
一个ABtest计划需要多大样本量?
假设双样本都有相同的标准差
 并已有估计值,知道了n1,以及双样本的均值差(
并已有估计值,知道了n1,以及双样本的均值差(
 );再假设power=0.8,a=0.05,那么我们可以根据公式推导出最低样本量n2:
);再假设power=0.8,a=0.05,那么我们可以根据公式推导出最低样本量n2:
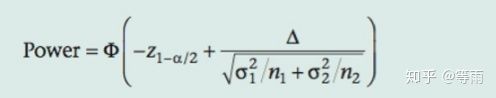
可以使用Python的statsmodels模块的相关方法来预估最低样本数,相关代码如下:
from statsmodels.stats.power import NormalIndPower
def main():
zpower = NormalIndPower()
effect_size = (1145 - 1132) / 20000.0
nobs1 = 1200000
print zpower.solve_power(
effect_size=effect_size,
nobs1=nobs1,
alpha=0.05,
power=0.8,
ratio=None,
alternative='two-sided'
)
main()
这个方法可以在指定其中一些参数的情况下,求解未知的一个参数,具体用法可以参考 [官方文档](https://zshipu.com/t?url=https%3A%2F%2Flink.zhihu.com%2F%3Ftarget%3Dhttp%253A%2F%2Fwww.statsmodels.org%2Fdev%2Fgenerated%
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%92%8C%E5%81%87%E8%AE%BE%E6%A3%80%E9%AA%8C%E6%B5%81%E9%87%8F%E5%88%86%E9%85%8D/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


