命名实体识别论文综述一
作者: 龚俊民(昵称: 除夕)
学校: 新南威尔士大学
单位:Vivo AI LAB 算法实习生
方向: 自然语言处理和可解释学习
知乎: https://www.zhihu.com/people/gong-jun-min-74
亚里士多德在《形而上学》中认为,对于存在,最重要的问题,就是给世间万物的存在基于语言来分层和分类。从神说要有光起,到基友给你取了个外号叫狗蛋。你会发现,创造与命名,在历史中往往等同。名字是自我概念的一部分。它是搭建视、听、味、嗅、触,五感与想象的桥梁。而花名更是凸显了自我的核心部分,是人们看待事物的侧面。比如奶茶妹妹( 章泽天),哥哥( 张国荣), 教主( 黄晓明 ),范爷( 范冰冰),贾老板( 贾斯汀·汀布莱克),寡姐( 斯嘉丽·约翰逊 ),拔叔( 麦德斯·米科尔森**),**小李子( 莱昂纳多·迪卡普里奥),周董( 周杰伦),罗胖( 罗振宇),雷布斯( 雷军),大表姐( 詹妮弗劳伦斯)等等。这一期,我们来爆肝地聊一聊命名实体识别。
Introduction
文本数据结构化是 NLP 最有价值的任务。一个句子中,命名实体更受到人们的关注。中文分词任务关注句子中的词汇之间的边界,词性标注关注这些被分出边界的词在词法上的类型。而命名实体识别关注的是命名实体的边界。它的粒度通常比中文分词要粗——是多个单词构成的复合词或短语,比如《那些年,我们一起追过的女孩》,《我们仍未知道那天所看见的花的名字》。它的类别通常比词性标注更具混淆性——是基于自然语言体系构建的抽象世界中,某个领域下的概念归属,比如人名,地名,组织机构名、股票、影视,书籍,游戏,艺术、医学术语等等。这些依托人类想象力构筑的事物,会随着时间的向前而不断变迁。它是信息抽取任务的焦点,在实际生产中需求很迫切,但做起来又很难。
难点一:命名『命名实体』
NER 之所以难做,第一点是因为我们对命名实体定义上的模糊。我们要如何命名命名实体呢? Hanlp 作者何晗在《自然语言处理入门》一书中总结了命名实体的以下三个共性:
- 数量无穷。比如宇宙中恒星名称、生物界中的蛋白质名称,即便是人名,也是会随着新生儿的命名不断出现新的组合。人们接触到的命名实体是一个开放的集合。有一些是已经存在,但我们的观测的视野有限,所以还未知晓,直到它在某个突如其来的一天成为了热点。还有一些则是还未存在,但任何人都有可能在某个时刻创造出它们。
- 构词灵活。比如中国工商银行,既可以称为工商银行,也可以简称为工行。一些机构名甚至存在嵌套现象,比如“联合国销毁伊拉克大规模杀伤性武器特别委员会”内部就嵌套了地名和另一个机构名。
- 类别模糊。一些命名实体之间的区别比较模糊,比如地名和机构名。有一些地名本身也是机构,比如“国家博物馆”,从地址角度来看属于地名,但从博物馆工作人员来看则是一个机构。
当我们人都需要费力地去分辨、定义实体时,会带来两个问题。一是工业界对NER 标注数据紧缺。因为数据标注就很困难,需要专家好好定义标准规范。而这个标准是基于人类共有知识的。它还不是一成不变的,你标注完了就能一劳永逸。而是隔几个月热点实体词就要大换一次血。过去标注好了一些实体,因为未来人们谈论它的语境都变了,可能不再适用。二是超越人类专家水平的 NER 系统难以实现。当前的 SOTA 模型大都是建立在有监督模型的基础之上。通常我们会把它看作是一个序列标注问题,可以用 HMM 和 CRF 等机器学习算法,或用 BiLSTM / CNN / BERT + CRF 的深度学习范式来学习解码。这些机器学习算法在封闭式的数据集可以表现得很好,但依然满足不了工业界开放式的业务场景需求。
难点二:实体的无穷
实体命名识别要面对的是排列组合可能无穷的词表。模型对 OOV 的泛化能力远低于我们的预期,所以通常做法是以统计为主,规则词典为辅。Hanlp 作者在书中对适合用规则词典来识别的实体分成了两类:
对于结构性较强的命名实体,比如网址、E-mail、ISBN、商品编号,电话,网址,日期,淘宝或拼多多口令等,都可以用正则表达式来处理。这部分我们会在预处理中,先用规则匹配,而未匹配部分交给统计模型处理。比如数词,标点,字母,数字,量词等混合在一起。对于类如「三六零」这样的中文,我们可以把大写中文汉字不放入核心词典中,这样就可以将其作为未知字符用正则进行匹配。虽然我们需要耗费大量人力去设计规则。但好处是,比起训练玄学的机器学习模型,这里努力性价比更高,都能带来直接有效的回报。
对于较短的命名实体,如人名,完全可以用分词方法去确定边界,用词性标注去确定类别。这样就无需再专门准备命名实体模块及语料库,只需要用分词语料库就可以做到。比如音译人名,我们会先用事先构建好的一个带词性的词典,对句子粗略地分词。再对分词后的句子从左往右扫描遇到人名词典中的词语则合并。这个词典被储存在一个 DoubleArrayTrie 中用作高效匹配。词典中的单字要谨慎选择,因为音译人名常用字通常也是汉语常用字。这套逻辑虽然难以识别未知的人名片段,但可以召回极长的音译人名。
基于词典和规则的方法只在部分类型的实体识别上有用,要获得更好的泛化能力,我们也可以用「张华平」和「刘群」等教授在提出的「角色标注框架」去结合模型和规则预测人名。它的思路是,我们先为构成命名实体的短语打好标签,若标签的序列满足某种模式则识别为某种类别的实体。它是一种层叠的隐马尔可负模型 HMM。第一层是以标签为状态,去发射观测到的构成实体的字词短语,发射的概率和标签与标签之间的转移存在的依赖关系由 HMM 建模。第二层则以实体类型作为状态,去发射观测到的标签。实体内的标签到标签之间的转移存在依赖关系。举个书中的人名识别的例子:
标签 | 意义 | 例子
B | 姓氏 | 「罗」志 祥
C | 双名首字 | 罗「志」 祥
D | 双名末字 | 罗 志 「祥」
E | 单名 | 时(chi)「翔」
F | 前缀 | 「老」王
G | 后缀 | 罗「胖」
K | 人名上文 | 「又看到」卢宇正在吃饭
L | 人名下文 | 又看到卢宇正「在吃饭」
M | 两个人名之间的成分 | 张飞「和」关羽
等等…
首先我们会把语料中的数据标注成如上的标签,再用词典去记录每个标签可能发射的词短语,以及频次。接着,我们根据语料数据去计算每个标签到其它标签的转移概率,即标签 x 到标签 y 的转移次数除以标签 x 到所有标签的转移次数和。这样我们就获得了模型的参数。模型可以是 HMM 或 CRF。它们可以学到很多种规律,比如,标签姓氏 B 后面接 双名、单名或后缀标签的概率远远大于接其它的标签概率。再比如,有双名首字 C 就一定有双名末字 D。又比如,姓氏 B 后面接单名 E 的概率会容易和后面接后缀 G 的概率混淆。通过收集大型的人名库,可以构建出更完善的依赖。
深度学习模型的输入数据要考虑词的粒度问题。即便我们是在一段中文的序列中,也可能掺杂着类如 DOTA2 和 CSOL 这样的英文单词。英文单词与中文的词有显著的不同。由单个字母组成的英文单词显然并没有中文单字那样丰富的语义。所以在英文中很少用 char 作模型的输入。即便是细粒度,也是用类似于前缀后缀这种比字母粗一个粒度,比单词细一个粒度的sub char 语素来作为深度学习模型的输入。在工程上,我们需要注意归一化和分字的问题。
>>> sentence = "褚泽宇是马尼拉特锦赛中的DoTa2选手"
>>> ' '.join(sentence).split() # 未归一化以单字输入
['褚', '泽', '宇', '是', '马', '尼', '拉', '特', '锦', '赛', '中', '的', 'D', 'o', 'T', 'a', '2', '选', '手']
>>> import re
>>> def is_chinese(char):
... return '\u4e00' <= char <= '\u9fff'
...
>>> def segment(sentence):
... i = 0
... tokens = []
... while i < len(sentence):
... tok = sentence[i]
... if is_chinese(tok):
... tokens.append(tok)
... i += 1
... else:
... i += 1
... while i < len(sentence) and not is_chinese(sentence[i]):
... tok += sentence[i]
... i += 1
...
... tokens.append(tok)
... return tokens
>>> segment(sentence.lower()) # 归一化后,中文以单字,英文以单词输入
['褚', '泽', '宇', '是', '马', '尼', '拉', '特', '锦', '赛', '中', '的', 'dota2', '选', '手']
若单独分 char,连续的单词会被分成一个个的字母,这会对模型识别标注带来一定困难。所以我们可以把序列中的连续字母会先通过预处理给过滤掉。比如 「data2」会先用正则获得,然后通过词典匹配到它的类别后,在把原序列的英文单词替换。再用替换过的序列输入给模型。注意,’<游戏>‘是单独的一个 token,会在 word embedding 的词表中额外添加。
|
|
类似的,如果文本序列中有可以用规则确定处理的,我们也会做替换。
|
|
关于规则和词典,这个 Repro 提供了比较充足的语料和规则资源:
[ https://github.com/fighting41love/funNLP/ github.com
]( https://link.zhihu.com/?target=https%3A//github.com/fighting41love/funNLP/tree/master/data)––)-
难点三:歧义的消解
传统的词典规则方法可以很容易召回文本序列中在词表匹配到的词,但它的局限在无法解决歧义问题。一种典型的歧义是多种可能划分问题。比如下面这个例子
输入序列:又看到卢宇正在吃饭
可以分为:又 / 看到 / 卢宇 / 正在 / 吃饭
也能分为:又 / 看到 / 卢宇正 / 在 / 吃饭
通常我们会用二元语法最短路径分词的方法去判断哪种分法路径最短。具体做法是记录所有二元字转移的概率,把文本序列构建成一个词图,然后用最短路径算法找出代价最小的路径。虽然这个例子它能够通过,但这个方案无法考虑复杂的语境。拿我们人的常识来说,识别的人名实体应该为 「卢宇正」,体现在「又」这个字。「又」和「正在」是有一点点冲突的。前者是描述再次看到的状态,而后者体现是当下时刻的进行时。所以第二种分法更符合常识。我们再来看另一个例子:
 a) 马云指着天发誓说,我不喜欢钱。b) 远方有一朵马云仿佛奔腾在宽阔的江面上。并不是所有的马云都是马云。
a) 马云指着天发誓说,我不喜欢钱。b) 远方有一朵马云仿佛奔腾在宽阔的江面上。并不是所有的马云都是马云。
字典匹配会把字典中的词都召回,所以会出现把第二个句子判断成人名的错误。而深度学习模型考虑了上下文语境。人可以“指着”,所以第一句是人名。云才是“一朵”,所以不是人名。当然之前说的基于角色标注的层叠隐马尔科夫模型也可以做到。但复杂一点的语境,深度学习模型能做得更好。在类如搜索推荐的下游任务中我们还需要对实体的指代做进一步的细分。这部分是实体链接任务,日后可以再展开。
难点四:边界的界定
虽然深度学习对歧义的消解有显著优势,但它通常会遇到的问题是对新词的边界把握模糊。而词典中包含了大量词的边界信息。因此如何把词典信息融入到深度学习模型中是近几年研究的主流。一种直观的方法是先执行分词,再对分词序列标注。但这种分割后再做 NER 的流程会遇到误差传播的问题。名词是分割中 OOV 的重要来源,并且分割错误的实体边界会导致 NER 错误。这个问题在开放领域可能会很严重,因为跨领域分词仍然是一个未解决的难题。简单说就是,分词分不好,NER 也难做。而分词确实经常分不好。
这里介绍三种把词表信息融入模型的方法,往后图神经网络 GNN 中加入词表信息的方法会在 图神经网络 GNN 系列中另出一期。
- Chinese NER Using Lattice LSTM
- CNN-Based Chinese NER with Lexicon Rethinking
- Simplify the Usage of Lexicon in Chinese NER
论文1: Chinese NER Using Lattice LSTM
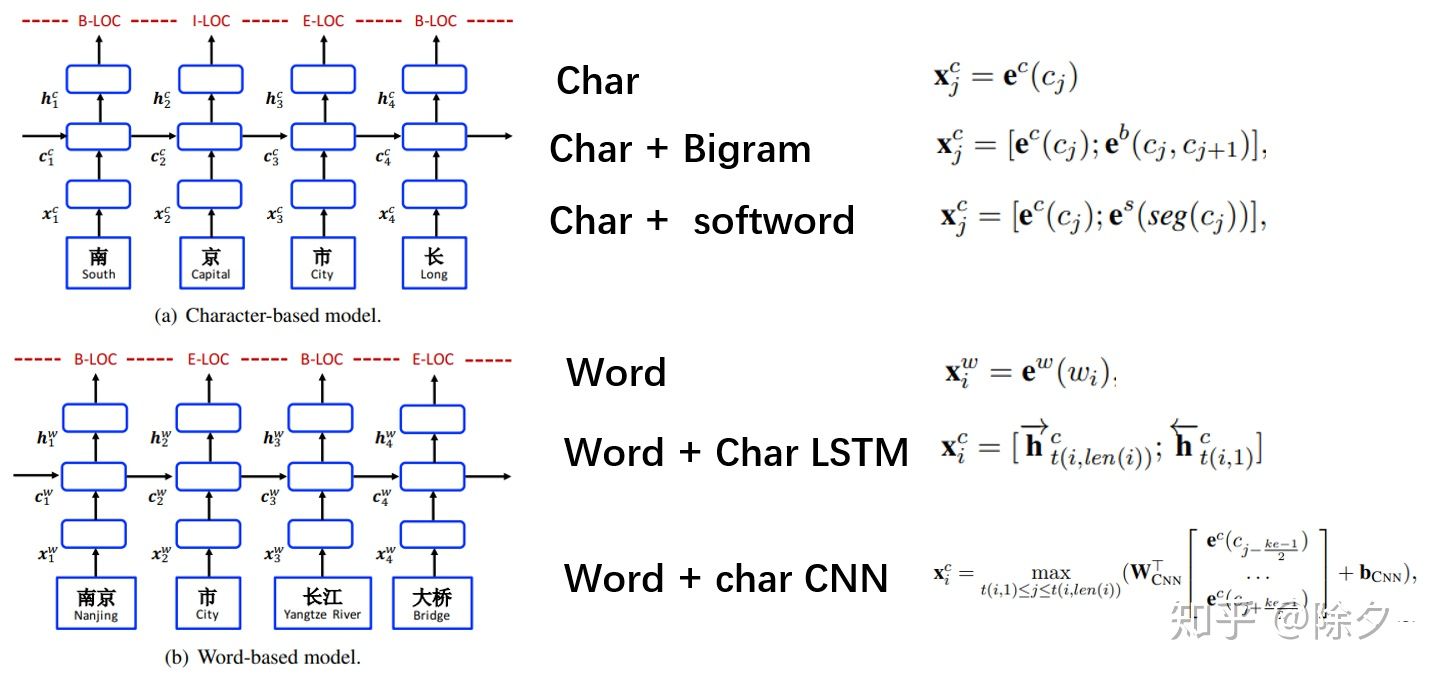 模型的输入有很多种,按字分输入字嵌入,按词分输入词嵌入。灵活一点,可以集二者之长,把前后两个字的 bigram 嵌入,或者是分词后的词嵌入,与字嵌入拼接起来。也可以用 CNN 或 LSTM 这些模型来聚合字嵌入。比如你好这个词,可以这么表示。we 为词嵌入,ce 为字嵌入。
模型的输入有很多种,按字分输入字嵌入,按词分输入词嵌入。灵活一点,可以集二者之长,把前后两个字的 bigram 嵌入,或者是分词后的词嵌入,与字嵌入拼接起来。也可以用 CNN 或 LSTM 这些模型来聚合字嵌入。比如你好这个词,可以这么表示。we 为词嵌入,ce 为字嵌入。
你 好
we(你好) we(你好)
ce(你) ce(好)
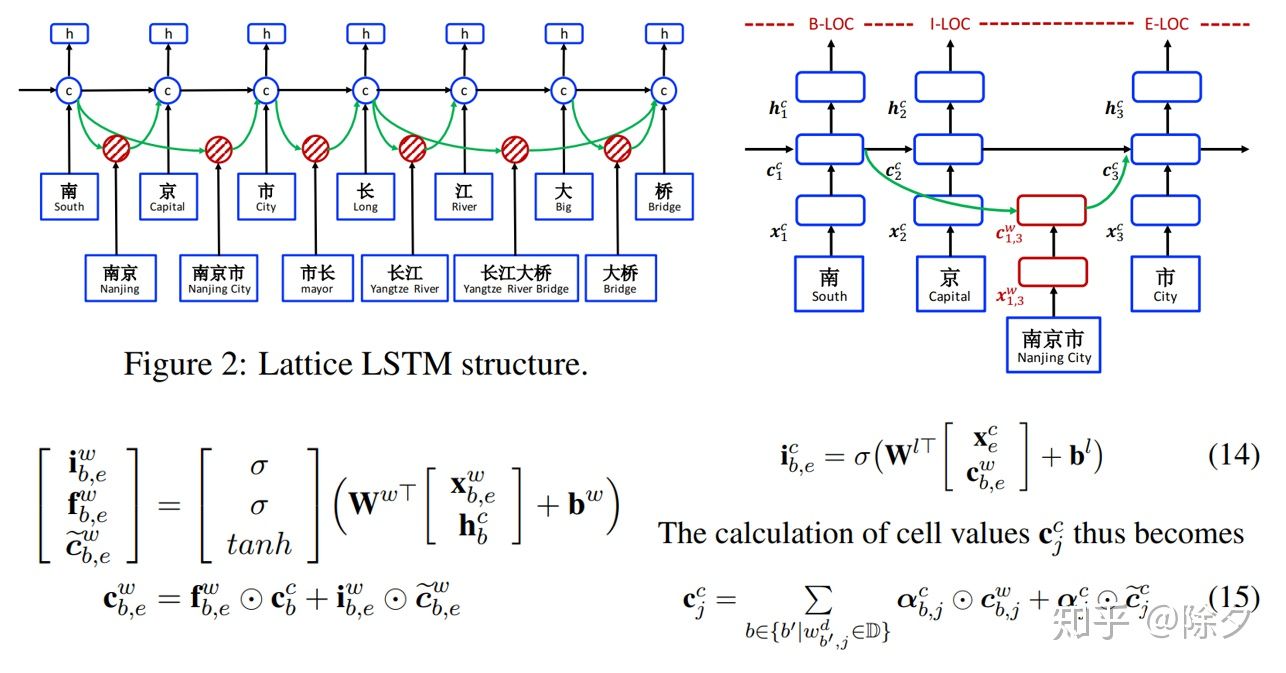 Lattice LSTM 主干部分用的依然是 LSTM,不同在它每个 Cell 处理信息的方式。中间红色的 Cell 储存的是句子中潜在词汇的信息。在 LSTM 中,输入门决定当前输入有多少加入 Cell,遗忘门决定 Cell 要保留多少信息;输出门决定更新后的 Cell 有多少可以输出。“桥"字以它为结尾的词有 “长江大桥”,“大桥”,“桥”。当前字符上的 Cell 除了 “桥” 以外,还需要考虑这些词的信息。图中两个绿色箭头便是这两个词的信息。其中红色的 Cell 互相独立,且没有输出门。原论文引入了一个额外门控来学得 当前字符 Cell 和 当前词汇 Cell 中的信息。该信息通过对 当前字符 Cell 各种输入的归一化权重, 加权求和获得。这类似于 Attention 机制自动给词赋予权重。
Lattice LSTM 主干部分用的依然是 LSTM,不同在它每个 Cell 处理信息的方式。中间红色的 Cell 储存的是句子中潜在词汇的信息。在 LSTM 中,输入门决定当前输入有多少加入 Cell,遗忘门决定 Cell 要保留多少信息;输出门决定更新后的 Cell 有多少可以输出。“桥"字以它为结尾的词有 “长江大桥”,“大桥”,“桥”。当前字符上的 Cell 除了 “桥” 以外,还需要考虑这些词的信息。图中两个绿色箭头便是这两个词的信息。其中红色的 Cell 互相独立,且没有输出门。原论文引入了一个额外门控来学得 当前字符 Cell 和 当前词汇 Cell 中的信息。该信息通过对 当前字符 Cell 各种输入的归一化权重, 加权求和获得。这类似于 Attention 机制自动给词赋予权重。
论文2: CNN-Based Chinese NER with Lexicon Rethinking
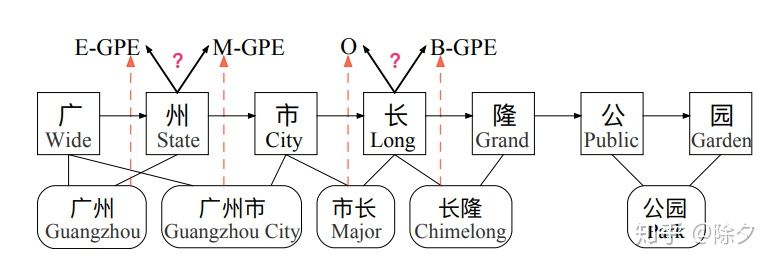 Lattice 成功在两个点,一是为每个字符保存所有可能匹配的单词,自动选择与 NER 任务匹配的词来避免错误传播;二是引入训练好的词嵌入来提升性能。Lattice 缺陷也有两点:一是它的计算效率低下。句子的输入形式从一个链式序列转换为一个图,增大了句子建模的计算成本,还不支持并行化。二是存在字在词表中冲突问题。“长” 可能属于市长一词,也可能属于"长隆"一词,而对"长"所属的词判断不同,会导致字符"长"的预测标签不同。
Lattice 成功在两个点,一是为每个字符保存所有可能匹配的单词,自动选择与 NER 任务匹配的词来避免错误传播;二是引入训练好的词嵌入来提升性能。Lattice 缺陷也有两点:一是它的计算效率低下。句子的输入形式从一个链式序列转换为一个图,增大了句子建模的计算成本,还不支持并行化。二是存在字在词表中冲突问题。“长” 可能属于市长一词,也可能属于"长隆"一词,而对"长"所属的词判断不同,会导致字符"长"的预测标签不同。
为此论文提出一种有 Rethinking 机制的 CNN (LR-CNN),它从两个方面来解决以上问题。
- 用 CNN 对句子与词表中存在的词处理
- 用 Rethinking 机制解决词表冲突问题。
我们如何把词表信息加入到 CNN 中?输入的句子是一串字嵌入 {c1, c2, …, cn},我们找出词表中,所有能在句子中找到的词。
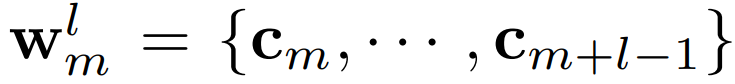 l 表示词的字符长度,m表示在句子字符的下标。比如
l 表示词的字符长度,m表示在句子字符的下标。比如
 = 马桶,
= 马桶,
 =马桶里。
=马桶里。
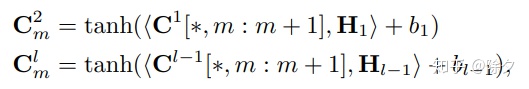 输入序列会被一个窗口为 2 的 CNN 编码 Bigram 特征,层层叠加起来就可以得到 l-gram 的特征。每个字都会对应一个在词表中的集合
输入序列会被一个窗口为 2 的 CNN 编码 Bigram 特征,层层叠加起来就可以得到 l-gram 的特征。每个字都会对应一个在词表中的集合
 ,而层层叠加起来的CNN也可以为每个字编码出一个l-gram的特征嵌入
,而层层叠加起来的CNN也可以为每个字编码出一个l-gram的特征嵌入
 。为了能让词表特征更高效地融入,论文用了一个可并行计算的 Vector-based Attention,计算方式如下。
。为了能让词表特征更高效地融入,论文用了一个可并行计算的 Vector-based Attention,计算方式如下。
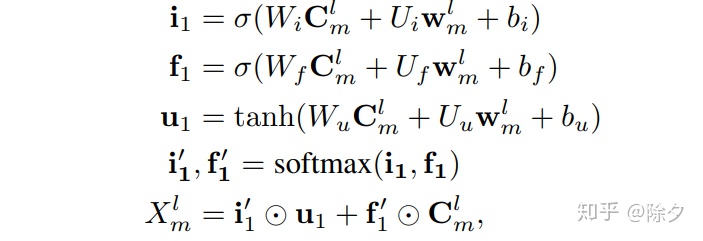
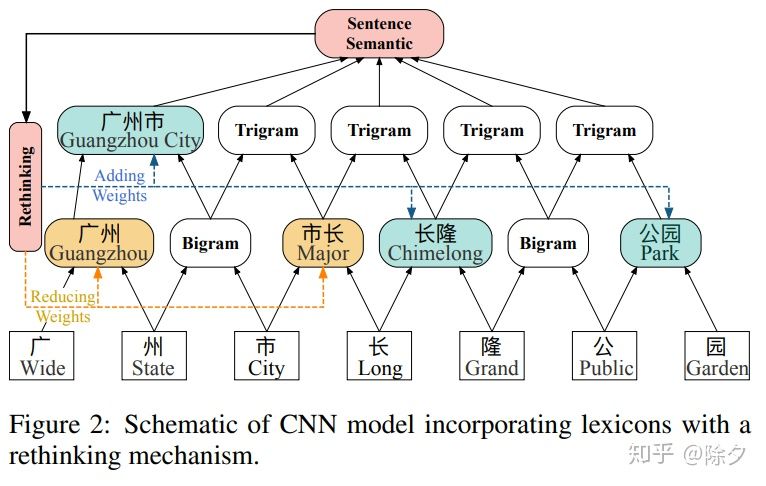 CNN 的分层会让底层的字信息无法影响到高层的词。比如"广州市"和"长隆"中,“市长"一词会误导模型对字符"市"产生错误预测。因此需要高层特征"广州市"来减少"市长"一词在输出特征中的权重。论文在每一层 CNN 上添加了一个 feedback layer 来调整词表的权值,计算方式如下:
CNN 的分层会让底层的字信息无法影响到高层的词。比如"广州市"和"长隆"中,“市长"一词会误导模型对字符"市"产生错误预测。因此需要高层特征"广州市"来减少"市长"一词在输出特征中的权重。论文在每一层 CNN 上添加了一个 feedback layer 来调整词表的权值,计算方式如下:
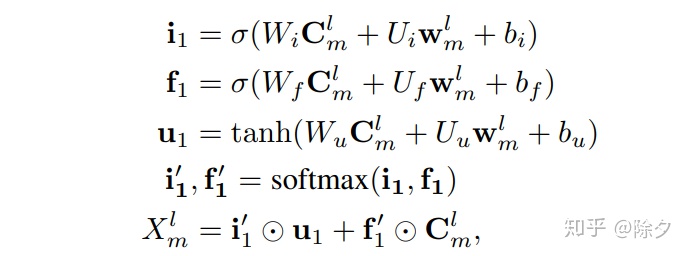 实验结果与 Lattice-LSTM 对比,LR-CNN 在定长句子下都取得了优于 Lattice-LSTM 的效果。但 LR-CNN 会更有处理短句的优势。随着句子长度增加,Lattice-LSTM 会因为要储存的词汇信息过多速度明显变慢,而 LR-CNN 的速度降幅较为稳定。在消融实验中发现,词表信息和Rethinking机制都能显著提升模型表现。即便没有词表信息,Rethinking机制也能提升模型表现。
实验结果与 Lattice-LSTM 对比,LR-CNN 在定长句子下都取得了优于 Lattice-LSTM 的效果。但 LR-CNN 会更有处理短句的优势。随着句子长度增加,Lattice-LSTM 会因为要储存的词汇信息过多速度明显变慢,而 LR-CNN 的速度降幅较为稳定。在消融实验中发现,词表信息和Rethinking机制都能显著提升模型表现。即便没有词表信息,Rethinking机制也能提升模型表现。
论文3: Simplify the Usage of Lexicon in Chinese NER
论文提出了一种更简单的对输入进行编码的方式来实现把词表信息融入模型。首先,我们定义四个集合。
- B(c):所有以字符 c 为起始的词集合
- M(c):所有以字符 c 为中间字的词集合
- E(c):以字符 c 为结束字的词集合
- S(c):字符 c 单独组成一个词的集合
考虑这样一个句子
s = {c1, · · · , c5}
其中与词表匹配的字集合有:
{c1, c2}, {c1, c2, c3}, {c2, c3, c4}, and {c2, c3, c4, c5}
对于 c2 这个字有
B(c2) = {{c2, c3, c4}, {c2, c3, c4, c5}}
M(c2) = {{c1, c2, c3}}
E(c2) = {{c1, c2}}
S(c2) = {NONE}
论文的想法是,把每个字符的四个词集压缩成一个固定维向量。为了尽可能多地保留信息,选择将四个单词集的表示连接成一个整体,并添加到字符表示中。具体的说,我们会做如下计算来构造融合后的嵌入。对每个单词的权重进行平滑处理,以增加非频繁单词的权重。其中 z(W) 为单词的频数。

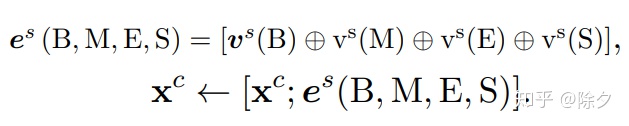 在计算效率上,明显好过其它方法:
在计算效率上,明显好过其它方法:
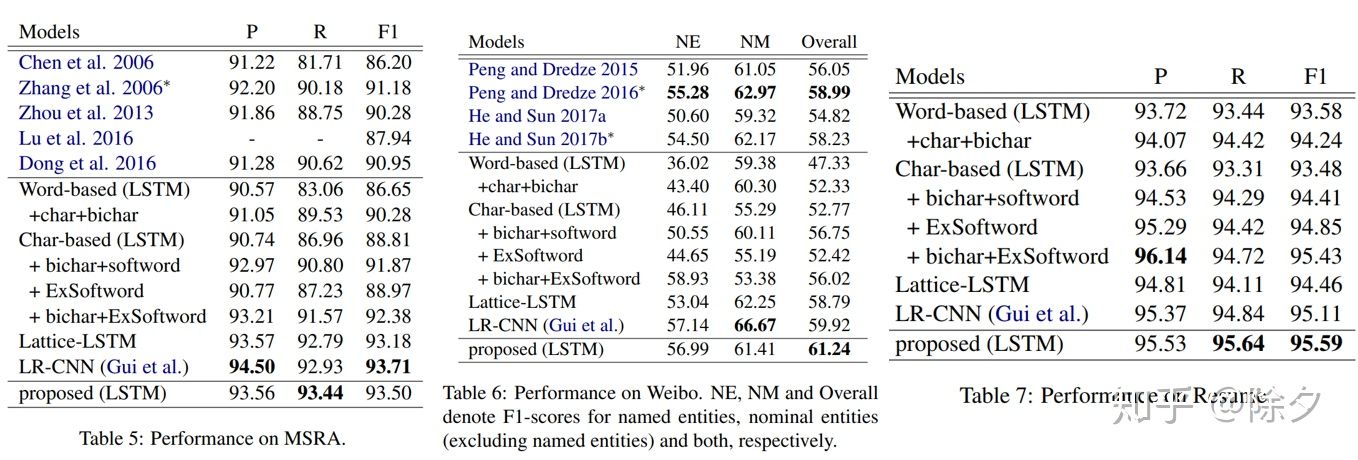
 在MSRA,Weibo,和Resume 数据集的表现上,也是 SOTA。
在MSRA,Weibo,和Resume 数据集的表现上,也是 SOTA。
难点五:标注数据缺失
监督学习固然好,但业务标注数据缺乏情况下,难展现其优势。于是一切又回到了起点。业界常用的做法是用预训练语言模型在业务数据上预训练,再结合少量的人工标注去做微调。在部分类别的实体上效果表现很好,但其他一些实体上却没有改善词典和用人工规则带来的提升那么显著。就简单的名人识别,模型能容易地识别出人名,但进一步明星,歌星和历史人物上细粒度上的区分,就需要词典来做。这是因为细粒度的标注数据有限。
为解决标注数据不足问题,业界紧需好的半监督或无监督算法。通常做法有几个思路。
- 找相似领域的有标记数据做领域迁移。
- 用远程监督的思路,用领域词典生成标记数据
对于第一种思路,我们可以分别对词的边界和词的类别做领域迁移。对于词的类别,比如我们想标注娱乐明星,体育明星和企业名人的数据,可以先用模型识别出人名,再把获得的人名去进一步区分它所归属的领域,可以大大减小标注工作量。对于词的边界,比如武器、战斗机型号。Hanlp 的做法是先用词法分析器对序列做词性标注,再把其中的某几个词合并成目标词。
米格/nr
-/w
17/m
PF/nx
可以变成
[米格/nr -/w 17/m PF/nx]
对于第二种远程监督的思路,我们主要讲一下 AutoNER。
论文: Learning Named Entity Tagger using Domain-Specific Dictionary
我们如何用领域词表来生成标注数据呢?一种方法是直接的词典匹配来标注数据。但这会遇到两个问题:
- 词典无法覆盖所有实体,匹配会有误召回,存在噪音
- 无法解决相同实体对应多个类别的情况,还有未知类型的情况
为此,论文提出了一种 Tie or Break 的标注方案,来让噪音尽可能地少。
- 若当前词与上一个词在同一个实体内 Tie (O)
- 若其中一个词属于一个未知类型的实体短语,则该词的前后都是 Unknown (U)
- 其它情况都默认 Break (I)
- 某个实体类型未知 None (N)
假如我们词典中只有 “银行” 这个词,而要识别的机构实体是 “浙商银行”。如果我们用 IOBES 的方案去做远程监督,效果如下:
输入文本: 浙 商 银 行 企 业 信 贷 部
真实标签:B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG E-ORG
远程监督: O O B-ORG E-ORG O O O O O
这会出现一个问题,即"银行"的边界真实标签会与远程监督得到的标签不一致。这里的银行的两个 “I”,一个标注成了 “B”,一个标注成了 “E”。
输入文本: 浙 商 银 行 企 业 信 贷 部
真实标签: I O O O O O O O O
远程监督: I I I O I I I I I
在以上例子中,Tie or Break 模式能保证 Tie 所在的位置一定是正确的,即在领域核心词典中“银行”的"行"字,一定是和前面的"银"字是合起来的。而剩下未知的 Break,模型会自动学到是否要 Tie。对于 Unknown 的词,它不会作为监督信息计算损失更新模型的权重。模型只会从正确标签中确定的信息计算损失,来从领域词典中学到必要的标注规则。再把这些规则泛化到周边未知边界和类别的词。
在 AutoNER 中,实体边界的远程监督信息和实体类别的远程监督信息是分开来计算的。这是为了能充分利用非领域词典——高质量短语词表中的词的边界信息。
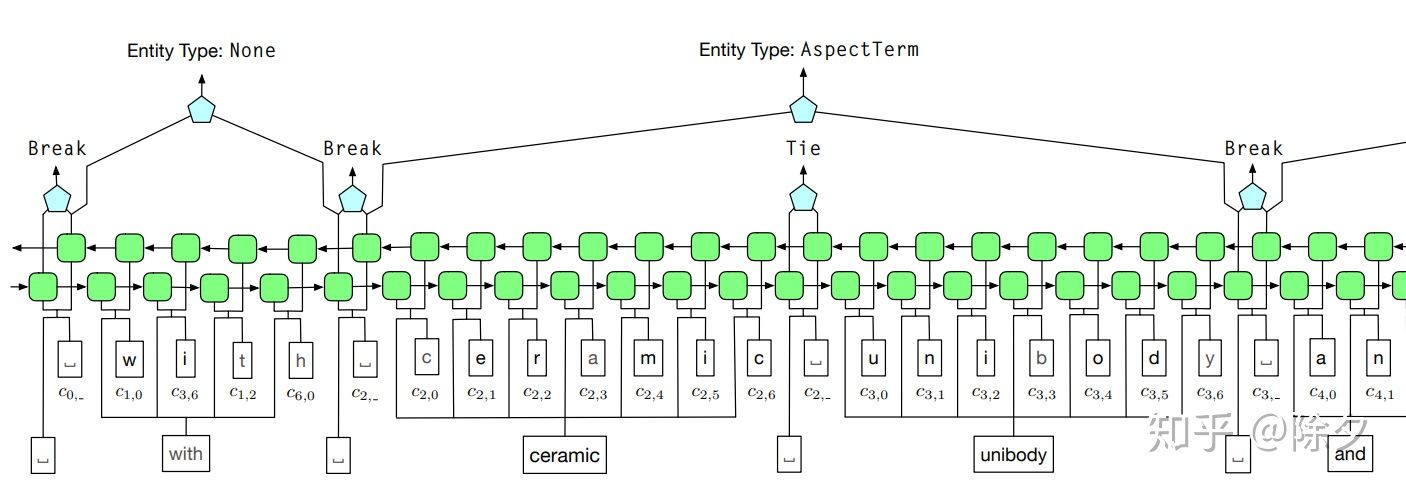 在原论文中,ceramic unibody 是在领域词典中,只有一个类别的词。所以它们组成的实体的类别是可以 100% 确定的。可是实际中领域词典往往不会很全,提供的监督信息是有限的。
在原论文中,ceramic unibody 是在领域词典中,只有一个类别的词。所以它们组成的实体的类别是可以 100% 确定的。可是实际中领域词典往往不会很全,提供的监督信息是有限的。
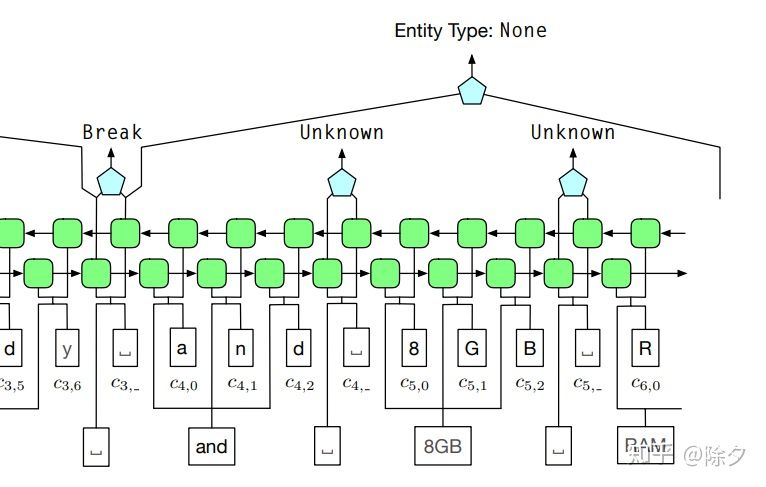 像 8GB RAM 是一个在高质量短语词表中的短语。我们虽然不知道它的类别,但它可以给我们提供词的边界信息。它们边界的标签被标记为 Unknow,且不参与 span prediction 的损失计算。这样做的好处是�
像 8GB RAM 是一个在高质量短语词表中的短语。我们虽然不知道它的类别,但它可以给我们提供词的边界信息。它们边界的标签被标记为 Unknow,且不参与 span prediction 的损失计算。这样做的好处是�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%91%BD%E5%90%8D%E5%AE%9E%E4%BD%93%E8%AF%86%E5%88%AB%E8%AE%BA%E6%96%87%E7%BB%BC%E8%BF%B0%E4%B8%80/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


