同城本地服务虚拟类目标签体系构建
来源: 孙锐 58技术
导读: 本文介绍了58本地服务《虚拟类目-标签》体系构建的相关工作,包括虚拟类目生成、标签筛选及挂载、同义去重等内容,我们将实际业务需求转化成机器学习问题,并调研实践相关算法模型完成构建工作。通过逐步上线《虚拟类目-标签》内容,方便用户找到所需服务以提高转化率,实现业务提效的目标。
背景介绍
58本地服务将现有行业细分为多层次的类目体系结构,为用户提供了汽车、培训、家政等多个类目的商家信息。用户通过搜索或选定类目等方式,跳转到商家帖子列表,查看对应帖子内容。在上述方式外,平台提供虚拟类目作为补充,方便用户筛选特定服务,如图1-1所示,用户选定二级类目“房屋维修”,可通过虚拟类目进一步选取具体维修项目。
在《虚拟类目-标签》体系中,一个虚拟类目对应多个标签,虚拟类目用于前端展示给用户,对应的标签则用于后续商家帖子召回等。
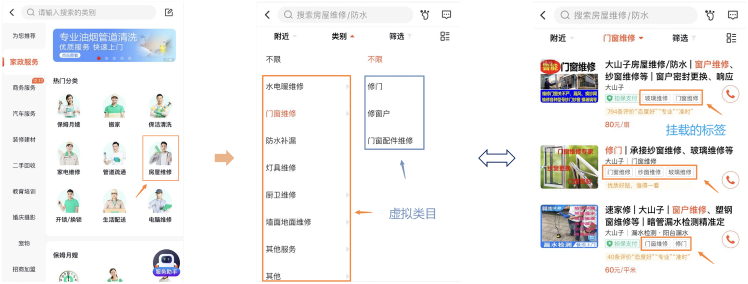
图1-1 虚拟类目-标签示例
当前58黄页仅有少量二级类目,提供相应的《虚拟类目-标签》数据,而人工整理扩充新类目时,所需工作量较大。因此我们希望可将新类目的《虚拟类目-标签》构建流程标准化,生成结果提供给产品运营人员,减少归纳成本,提高构建工作效率。
整体流程
《虚拟类目-标签》构建工作主要分为两个部分,即虚拟类目的生成、将标签挂载到虚拟类目。其中虚拟类目是以三级类目为基础,进行人工筛选后形成的;而将标签挂载到虚拟类目的流程如图2-1所示,包括三个步骤:标签筛选、虚拟类目挂载标签、同义规范化。
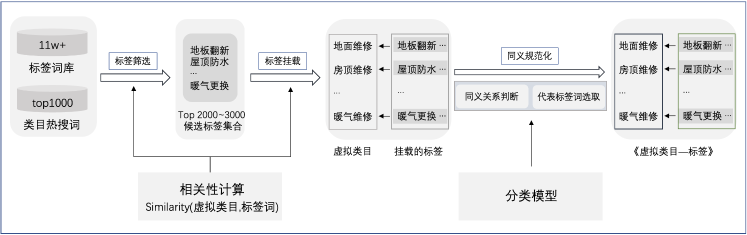
图2-1 标签挂载到虚拟类目流程
在前期数据准备阶段,使用的基础数据包括:黄页标签词库与各级类目数据。标签词库[1]是从现有的商家帖子、类目热搜词中挖掘的,各级类目数据是指58黄页已有的多级层次化的类目体系。
在标签挂载到虚拟类目阶段,给定虚拟类目后,标签挂载的重点在于:
(1) 确保挂载相关的标签
(2)增加挂载标签的多样性
(3)对挂载结果的同义去重
以二级类目房屋维修为例,难点在于如何从11w标签词中,选取不超过100个合适的标签词,并准确挂载到虚拟类目下面。由于标签词库覆盖类目广、语义差异大。标签词一字之差则挂载类目完全不同,如“地板维修”应挂载到“地面维修”类目,而“地暖维修”挂载到“暖气维修”类目。若直接使用模型生成挂载结果,存在样本标注成本高、模型预测结果准确率低且相关标签召回少的问题。
考虑到标签挂载到虚拟类目的工作重点及难点,我们将挂载流程拆分成三个步骤,各步骤分别对应上述的阶段重点,从直接将标签挂载到虚拟类目的方式,转变成先初筛后挂载的多级步骤,最终实现挂载结果的准确可用。
技术实现
本节介绍标签挂载到虚拟类目的三个步骤及对应的技术实现。
1、标签筛选
标签筛选阶段,难点在于如何筛选出相关标签,即筛选的标签,能描述虚拟类目的具体服务内容。如图3-1所示,虚拟类目为“沙发维修”,则标签词需覆盖具体服务项如“沙发清洗翻新”、“修复保养”等。
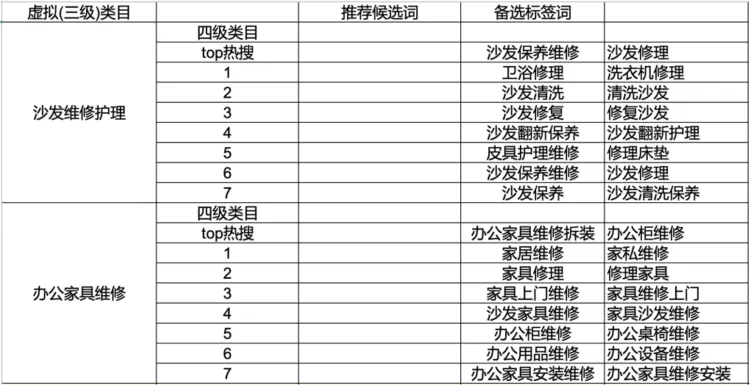
图3-1 虚拟类目挂载标签示例
筛选与虚拟类目相关的标签,需衡量词语间的相关性,我们将其转化成语义相似度的判断问题。即根据虚拟类目与标签词的语义关联程度,筛选得到相关标签。
模型选型时,考虑到虚拟类目词与标签词较短、标注数据少等特点,我们希望模型有效提取词语间的匹配信息,学习输入标签词之间的关联特征。同时期望使用通用领域的先验知识,区分标签词的语义差异。因此对于虚拟类目与标签词语义相似度计算问题,我们选择文本匹配模型CDSSM[2]、MatchPyramid[3],预训练语言模型Bert-Chinese[4]、Roberta-Chinese[5]等进行对比试验。
文本匹配模型属于有监督方式,根据输入样本学习词语的语义表示、区分词语是否相关,按照模型输出的类型,可分成回归模型与分类模型,分类模型CDSSM如图3-3所示,模型使用CNN作为基础模块,对输入的文本对,输出对应概率表示相似程度,回归模型MatchPyramid如图3-4所示,模型计算了输入文本之间的匹配矩阵,对二维矩阵使用CNN提取特征,输出拟合值作为相似度。
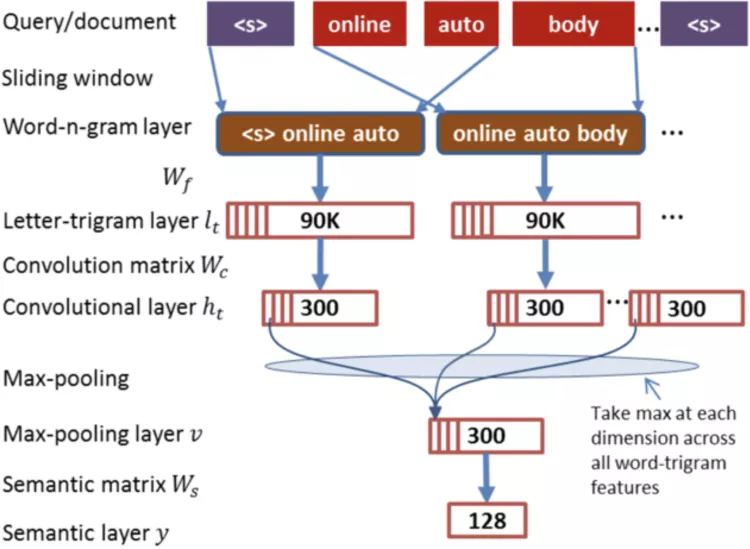
图3-2 CDSSM 模型结构示例

图3-3 MatchPyramid 模型结构示例
Bert模型使用Transformer Encoder[6]作为特征提取模块,如图3-2所示,右侧Encoder模块包括多头自注意力层与全连接层,多头自注意力层将字词间句法特征编码到字向量中。全连接层进行仿射变换,对语义向量进行层归一化,保持梯度平稳、特征有效传递。Bert模型训练包括Masked Language Model(MLM)与Next Sentence Prediction(NSP)两个任务,MLM随机选取输入序列15%的单词进行掩盖,预测掩盖后的单词,用于学习文本序列的字词向量表示。NSP是训练模型理解句子间关系的任务,用于提高模型抽取句子整体语义特征的能力。
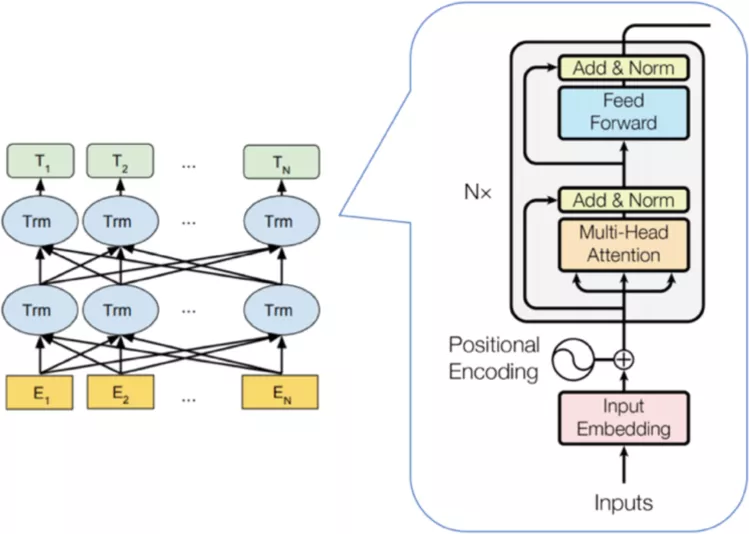
图3-4 Bert与Transformer Encoder模型结构示例
Roberta模型结构与Bert模型结构一致,区别在于Roberta模型在Bert基础上,进行了数据增强与超参优化,具体为:
(1)训练语料更丰富,使用160GB的文本语料,高于Bert的16GB语料
(2)模型训练更充分,迭代次数增加到500k,BatchSize增加到8k
(3)采用动态MASK,多次迭代训练时,同一个输入文本需预测不同位置的单词,有助于模型学习不同位置的特征向量表示
(4)取消NSP任务,由于NSP任务限制单个文本序列的长度,对于MLM任务,引入了其他文本序列的噪声,会降低模型抽取字词特征的能力
在标签筛选对比实验中,给定二级类目“房屋维修”及对应的虚拟类目,标注3000条虚拟类目与标签词样本,训练集、验证集、测试集比例为8:1:1,训练文本匹配模型。预训练语言模型如Bert生成词向量后,取余弦距离作为相似度。各模型分别取top1000标签词,评测筛选的标签词是否相关,评估指标结果如表3-1所示:
从实验结果可知,文本匹配模型存在召回相关标签数量少的问题,从数据层面分析,标签词语长度为2-8个字,较短的词语的信息量更大,语义不确定程度越高,而样本数量较少、词语较短导致了文本匹配模型的泛化性不佳。另一方面文本匹配模型抽取输入文本特征时,较短的词语可参考的上下文信息不足,生成的特征向量区分度不大,因此预测时模型对于相关的标签与不相关的标签,都会给出较高的相似概率。
预训练语言模型筛选相关标签数量相对较多,是由于在训练语言模型阶段,语料中包括了文章百科问答类的数据,基本涵盖了标签词库的标签词及相似语境的上下文,不同标签词向量本身区分度较高,对应的余弦距离差异明显,因此使用Bert系列预训练语言模型,能召回更多相关标签。
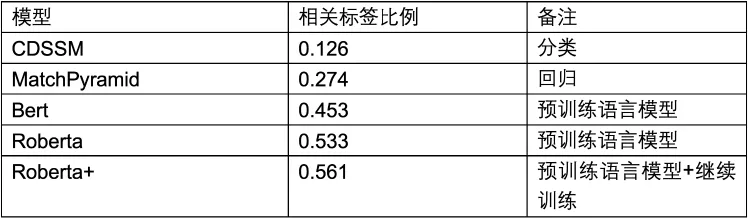
表3-1 标签筛选实验结果
通过标签筛选实验,我们对比了各模型的实际召回效果,最终选择预训练语言模型Roberta作为计算相关度的模型,在此基础上,将清洗过滤后的二级类目帖子微聊数据作为特定领域语料,继续预训练Roberta以提升模型效果。
标签筛选阶段,使用Roberta模型生成词向量,余弦距离作为词语之间的相似度量,对于给定的虚拟类目,输出标签词对应的相似度,降序排序后,选取前2000个标签词作为候选标签集合,用于后续的标签挂载步骤。
2、虚拟类目挂载标签
虚拟类目挂载标签阶段,是将top2000候选标签词,挂载到对应的虚拟类目上,虚拟类目挂载标签时主要考虑挂载结果的相关性及挂载标签的多样性。
虚拟类目挂载标签的难点在于如何将标签词正确挂载到对应的虚拟类目,我们采用的方式是计算标签词与虚拟类目的余弦相似度,同时考虑标签词与虚拟类目对应的三级类目、四级类目的相似度,将标签词划分至相关度最高的虚拟类目下,如下公式所示:

挂载标签时,为提高标签的多样性,在已有标签词库基础上,增加了类目热搜词,作为补充数据。热搜词展现了一段时期内用户偏好,代表了用户侧的热门需求。
3、同义规范化
虚拟类目挂载标签生成结果中,存在较多同义标签词,需进行同义规范化。图3-1展示的挂载结果中,存在“家具修理”、“修理家具”、“家具上门维修”、“家具维修上门”等多个语义相同表述各异的标签词。一方面是由于标签词库存在同义标签,另一方面是增加的类目热搜词在标签词库中有同义词。
同义规范化主要包括两个部分:同义词典生成、挂载结果同义去重。同义词典示例数据如图3-5所示,每一行包括二级类目id、代表标签词、同义标签词集合;挂载结果同义去重则是使用同义词词典,对虚拟类目挂载的标签进行同义词替换,减少语义相同的标签。

图3-5 同义标签词典数据示例
同义词典生成主要包括同义关系判断、代表标签词选取两个步骤。
同义关系判断是给定两个标签词,判断词对是否为同义词。难点在于如何正确区分同义关系,以及如何召回更多的同义词对。
代表标签词选取是对于一个同义词集合,选择其中一个标签词作为代表,进行标签归一。难点在于如何选取长度适中、凝练简洁的标签词。
对于同义关系判断、代表标签词选取,我们将其转化成二分类问题,输入为标签词词对,输出Label分别为:是否是同义词、是否是代表标签词。期望模型通过训练数据,学习正确区分标签的同义关系及选取合适的代表标签词。
在二分类模型选型前期,考虑到标签词较短,缺少上下文,覆盖类目多、语义差异大等特点,因此选择模型时主要关注于:
(1) 能提取文本各层次特征(字词、短语、句法结构)
(2)包括通用领域知识,易于知识迁移
(3)标注样本少的场景下,需扩充样本进行数据增强,提升泛化性能
模型选型时,根据标签词数据特点并参考文本分类领域公开榜单[7], 我们选取了BiLSTM+Attention模型、HAHNN[8]模型、预训练语言模型Roberta、少样本学习方法EDA[9]、UDA[10]进行对比实验。
HAHNN模型使用注意力机制提取句法关联特征、用GRU提取文本整体语义特征;预训练语言模型Roberta,本身具有通用领域知识,模型学习收敛较快;对于标签词标注数据少的问题,少样本学习领域的EDA、UDA等数据增强及模型增强方式,能扩充标签词词对样本,在一定程度上能改善分类模型泛化性能。
HAHNN模型如图3-6所示,整体包括卷积模块、词语编码模块与句子编码模块。卷积模块使用空洞卷积进行特征抽取,词语编码模块与句子编码模块结构相同,由双向GRU与注意力层组成。HAHNN模型使用的空洞卷积相对于原始卷积,在特征抽取时感受野更大,提取局部文本特征时可覆盖更宽范围的词语序列,使用双向GRU保留了每一时间步的状态,学习到句子整体的全局语义,同时注意力层计算词语之间的权重关联矩阵,产生词语间句法结构特征。
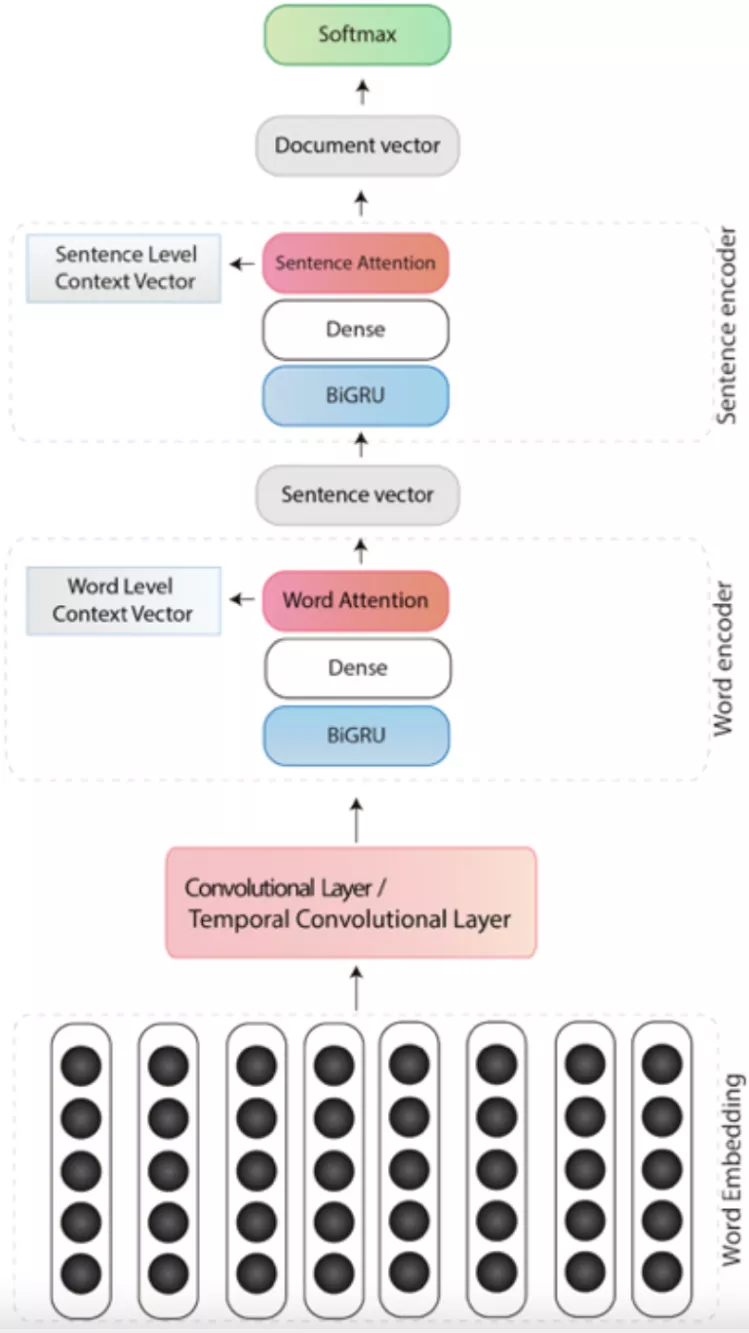
图3-6 HAHNN模型结构示例
EDA作为少样本学习领域的数据增强方式,通过增加输入样本噪声,提高模型提取特征的能力,进而改善模型的泛化性。EDA采用随机交换、随机插入、随机删除、同义词替换等方式,将一个样本扩展成多个同类样本,EDA改变了局部词语顺序,对原始文本语义增加扰动,在模型训练阶段,加大了模型区分输入文本类别的难度。
UDA从模型层面,在训练阶段增加了额外的损失函数,如图3-7所示,图中左侧是传统有监督模型训练方式,即给定标注数据,计算预测Label与实际Label的交叉熵损失,右侧是UDA增加的损失函数,输入文本经过EDA变换后,得到同类别的样本对(x,x’),右侧的损失函数需要模型学习同类别样本的共性特征,增加模型泛化能力,同时左侧的损失函数,需要模型学习不同类别的差异,即正确区分不同类别的样本。
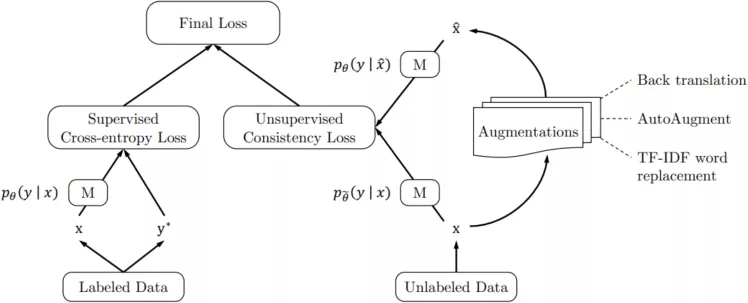
图3-7 UDA模型结构示例
同义关系判断模型对比实验中,数据集为3000条同义标签词样本。训练集、验证集、测试集比例为8:1:1。测试集的评估结果如表3-2所示,实验表明,从头开始训练的模型如CDSSM评估指标不高,原因在于训练数据少、词语字数短、上下文信息不足、样本空间较小,因此模型泛化能力不强,特征提取能力有待提升。
基于Roberta模型进行微调的方式评估指标较高。如Roberta+Linear模型召回率较高,而Roberta+UDA+EDA模型准确率较高。一方面是由于Roberta模型有通用领域的知识,易于进行知识迁移,另一方面是使用UDA、EDA等数据增强方式对样本加噪,要求Roberta模型的特征抽取能力更强,需要模型从样本中学习同类别共性、区分不同类别特性,因此Roberta模型在测试集上表现较好。
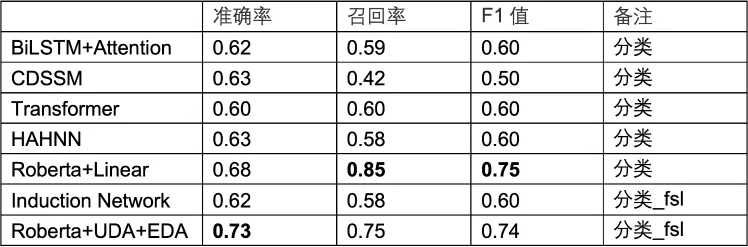
表3-2 同义关系判断实验结果
根据实际业务场景,同义词词典需要覆盖更多的同义标签词,因此主要关注模型的召回率,根据模型对比实验结果,我们选择召回率更高的Roberta+Linear模型用于判断标签词对的同义性,人工审核模型预测结果,得到同义词词典数据。
同义词词典生成后,每个同义词集合,需要选取代表标签词,实现方式是采用Roberta分类模型,对于一个同义词集合,两两组合标签词对,判断首个标签词是否可展示,同时参考EDA方法,使用随机替换词语方式进行数据增强,将一个样本扩展成多个,最终分类模型准确率是0.96, 泛化到其他二级类目的准确率是0.86。
在同义规范化阶段,先使用Roberta+Linear模型生成同义词词典,再根据词典进行同义去重。经过标签筛选、标签挂载、同义规范化等步骤,最终生成的《虚拟类目-标签》结果如图3-8所示:每个虚拟类目对应多个下挂的标签词,同时类目热搜词、四级类目词、标签词分成多行显示,产品运营人员可根据业务实际情况,选定虚拟类目及标签,用于帖子打标及帖子召回等。
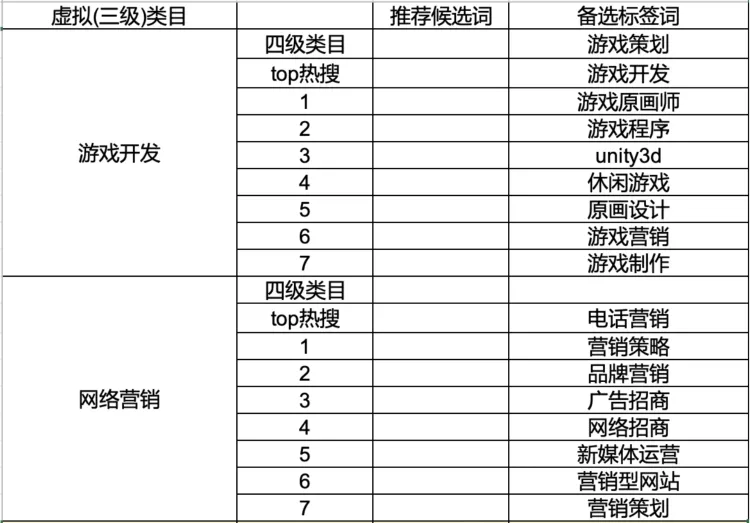
图3-8
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E5%9F%8E%E6%9C%AC%E5%9C%B0%E6%9C%8D%E5%8A%A1%E8%99%9A%E6%8B%9F%E7%B1%BB%E7%9B%AE%E6%A0%87%E7%AD%BE%E4%BD%93%E7%B3%BB%E6%9E%84%E5%BB%BA/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


