同城多目标排序算法

分享嘉宾:孙启明@58同城
内容来源:58技术
导读: 2020年9月,AI Lab、营销平台部(CRM)、LBG黄页业务方三方联合启动了商机智能分配项目,将CRM商机分配流程抽象为推荐/搜索场景,将传统机器学习以及深度学习算法应用于CRM系统,为每个销售人员分配适合其跟进的商机,优化成单转化,以提高销售团队业绩,进而提升业务线收入。
本文主要分享在上述场景下,精排多目标建模的方法。文章中,首先对读者需要的背景知识进行了适当补充,并阐述了选择多任务深度学习模型进行落地的原因。之后,重点介绍了场景中使用的多目标建模方法,分五个版本将建模过程中使用的多任务学习模型、损失函数、多目标排序方法、模型优化方案等进行了拆解及分享,并展示了每个阶段相比前一阶段取得的线上效果收益。
背景介绍
1、CRM系统相关知识
CRM系统是58同城销售人员进行客户筛选及产品售卖的重要工具,其目的是通过信息化的手段,在整个营销及交易流程上为销售人员进行赋能。
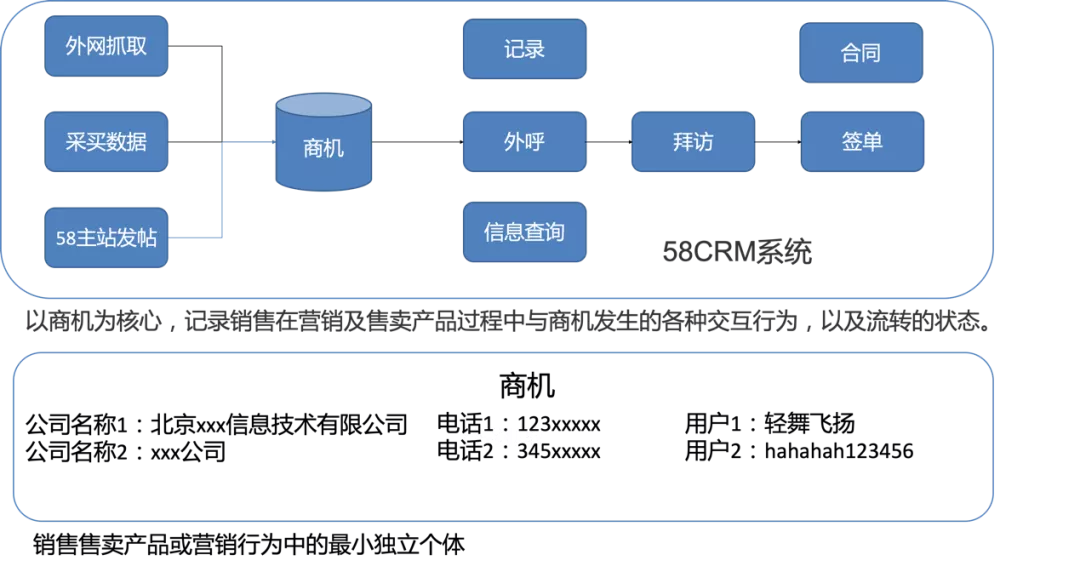
如图1所示,CRM系统作为桥梁,连接了销售与客户交互的各个环节:首先从多种渠道收集潜在客户的信息(线索),并对线索信息进行准确性、合规性、唯一性的识别,去掉不准确、不合规的客户信息,接着对重复客户信息进行合并,生成能代表有购买意向客户的最小实体(被称为商机),销售在CRM系统中的绝大部分操作流程均以商机为载体。在形成商机后,销售会开始对其进行挑选(本文核心赋能点)并进行外呼跟进,对外呼后的客户意图反馈及时更新与记录。当客户表达出较强意向后,销售会对客户发起拜访请求,进一步提升客户购买58会员产品的意向,最终客户确认购买后,会进行下单操作,商机转换为订单,在确认收入到账后,该商机彻底退出CRM系统并转移至客服系统。
销售每日能碰触到的商机包括新增商机和存量商机两大类,新增商机是每日新流入58主站或采集到的商机,销售从未跟进过,这类商机质量更高,但数量稀少。存量商机是沉在CRM系统中,还未能最终成单转化的商机,该类商机数量巨大,质量较低。销售人员日常大部分时间会花在对存量商机的挑选上。基于此,商机智能分配项目希望通过更改销售作业模式并应用人工智能算法,支持销售人员更快速的从海量商机中找到更优质,更符合销售人员兴趣的商机,从而提升转化率。
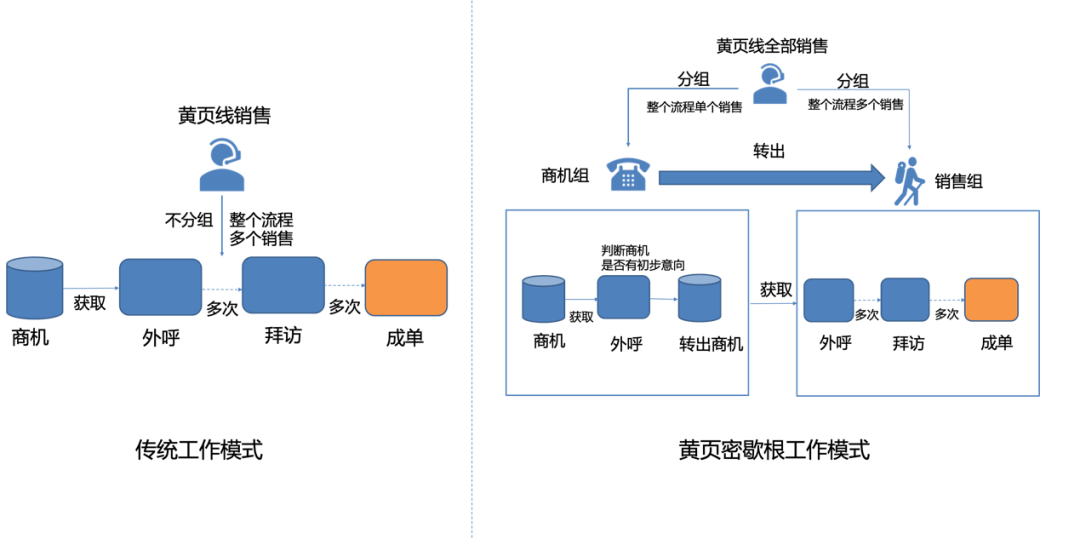
如图2,黄页商机智能分配项目首先对销售工作模式进行了一定的改造(称为密歇根模式),改造后的模式与前面段落概述的传统CRM系统工作模式有一些区别。黄页业务方会将销售团队拆分为两个部分:一部分称为商机组,负责对商机进行初步筛选,以产出有初步沟通、成单意向的商机为目标,并将该类商机以“转出”这一业务动作同步到另一组。另一组被称为销售组,主要负责在获取到商机组“转出”的商机后,继续进行跟进直到成单的环节。当前,针对这两部分销售,我们都进行了人工智能的赋能,本文中,只会对密歇根模式下,为商机组赋能的多目标建模优化进行展开描述,即如何通过引入人工智能方法,提升商机组”转出“的效率,从而提升销售业绩。若读者希望了解更多关于CRM系统逻辑、黄页销售业务背景等内容请参看58技术公众号之前的文章: 《AI + CRM 提高企业的 “绩” 和 “效”》,詹坤林,这里不再赘述。
2、具体业务介绍
如上所述,黄页商机组目的是通过拨打电话,从海量商机中筛选出有一定意向的商机,并进行“转出”操作,所以我们的建模目标就是使用销售及商机的各维度特征,训练模型,从而帮助商机组销售更好的进行商机筛选。当前,商机组获取商机的主要来源如下图所示:
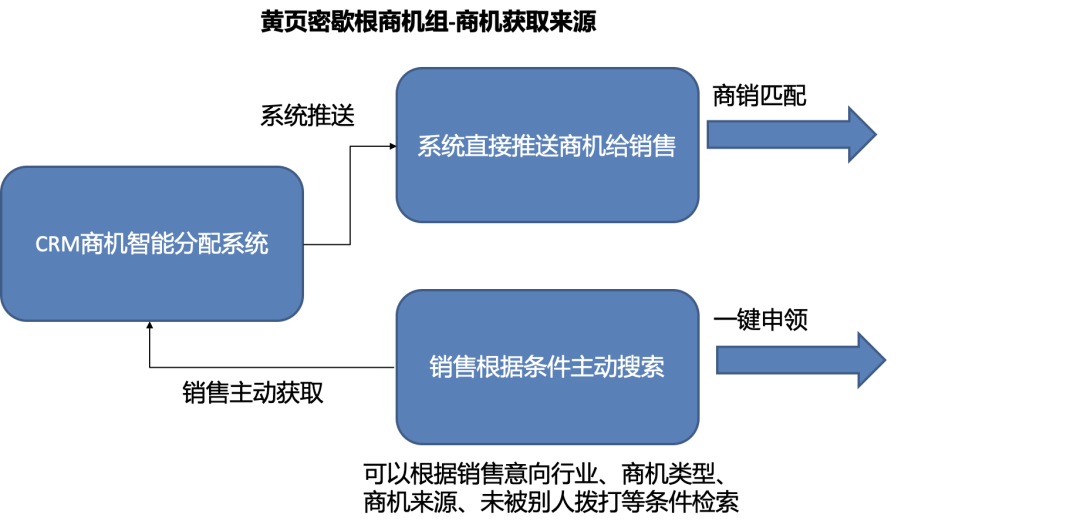
每日一早,CRM商机智能分配系统会按照与各个销售的契合程度挑选合适的商机分配给销售(又称商销匹配过程),在跟进完这部分商机后,销售可以自己配置筛选条件进行条件检索,系统返回商机列表供销售跟进(又称一键申领过程)。每个被商机组认为有继续跟进价值,从而成功转出的商机,在分配后都一定会经历拨打->接通->转出的过程。在实际建模中,我们将商销匹配类比为个性化推荐场景,将一键申领类比为搜索个性化排序场景,因为销售每日通过一键申领方法获取到的商机量远大于商销匹配,本文会以一键申领场景为例,介绍模型优化过程。在正式建模前,我们先进行了如下表所示的目标分析:

将拨打类比为推荐系统中的曝光,接通类比为推荐系统中的点击,转出类比为推荐系统中的转化。
经与业务进行讨论,找到了商机组销售外呼过程中,最关键的两个业务指标,
接通转出率:转出商机数/接通商机数,该指标衡量的是销售在接通一个电话后的转出成本,一线销售对于该指标非常敏感,该值提升会极大增强销售对商机智能分配系统的信心。
拨打转出率:转出商机数/拨打商机数,一直以来业务方对销售的考核中都会包含个人单日拨打商机数的考核,经数据统计,销售单日拨打商机数是一个较为稳定的数值,所以,提升拨打转出率会直观的提升总转出数量,而总转出数量的提升又意味着业绩的提升。
综上,在本场景中,拨打转出率及接通转出率都是非常重要的指标,只有两个指标同时获得提升,才能为黄页业务线带来最大收益。
3、使用多任务深度学习模型的原因
由以上段落可知,本业务场景是个典型的多目标优化场景,最近几年,基于多任务深度学习框架解决多目标优化问题的应用非常多,在我们的场景下,经过讨论及分析,也选用了这一方法,具体优势如下:
- 更贴近业务需求
显而易见,在希望同时提升拨打转出与接通转出的目标下,如果使用传统机器学习模型或者单任务深度学习模型,在训练时无法对两个指标的实时效果进行评估,更不能保证同时优化这两个指标,进而无法很好的达成业务目标。
- 共享信息,考虑任务间的相关性,增强模型表现。
当前在黄页密歇根场景中,对商机组使用的评估指标是拨打转出率及接通转出率,在后面的赋能过程中,也可能会有同时优化其他指标的需求,在这些指标中,部分指标间具有强相关性,部分指标数据分布极其稀疏,传统单任务学习模型对上述情况无法很好处理。而通过使用多任务深度学习模型,既可以利用不同任务样本间的信息,又可以建模任务间的相关关系,从而达到利用其他目标数据提升本目标效果的目的。
- 端到端构建,共享模型,节约内存,加快推理速度
多任务深度学习模型,通过建立一套统一的端到端模型与特征数据框架,即可在推理阶段产出全部任务的推理结果,相比单任务深度学习模型,复杂度大大降低,对线上部署及推理服务都会更加的友好。
- 深度学习模型,自定义方便,快捷
相比传统机器学习模型,深度学习模型可以更方便的自定义网络结构、损失函数等,按照需求更及时更精细的对模型进行调整。
多目标建模迭代过程
AILab自开始以多任务深度学习框架对CRM商机智能分配场景进行赋能以来,在多目标建模这条道路上经历了多次优化及迭代,期间对多种不同的多任务学习框架、多目标合成单目标排序逻辑、损失函数等都进行了探索及实践,以下将按时间先后顺序介绍实践过程中有代表性且效果有显著提升的五个版本,每一个版本都是在上一个版本上的进一步优化。
版本一:基于XGBoost+样本采样的多任务机器学习模型
1.模型介绍
如本文之前段落所述,在本场景下,我们希望能同时提升拨打转出率及接通转出率,并通过一个统一的模型实现这一目的。使用传统机器学习,能否做到这一点呢?在做出回答前,我们先对这两个任务的正负样本按照拨打-接通-转出的漏斗维度进行了拆分,具体结果如下图所示:
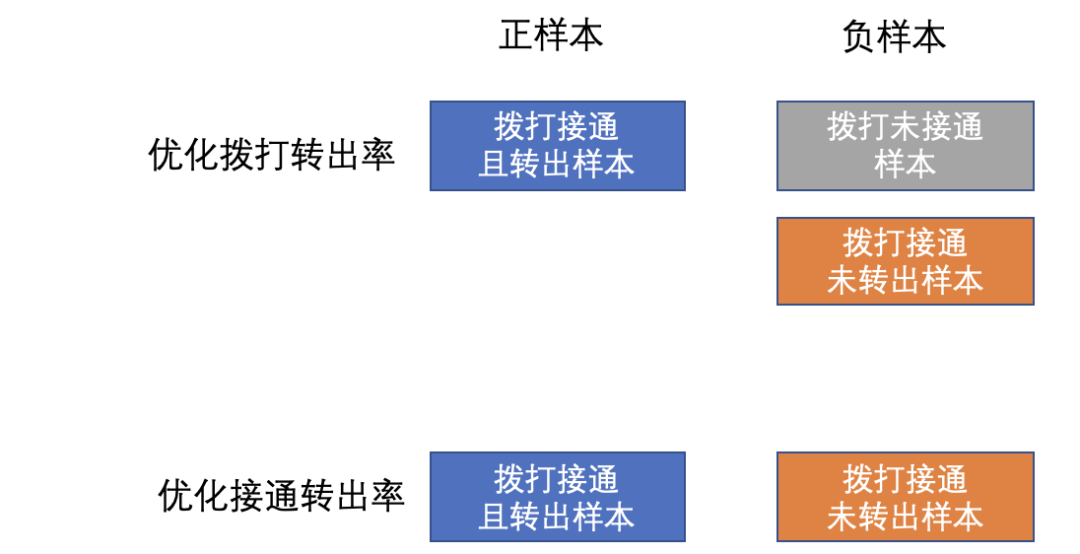
可以看到,无论优化的目标是拨打转出率还是接通转出率,正样本均是满足拨打接通且最终转出的样本,差异点在于负样本的构成,当只取拨打接通未转出的负样本时,模型优化目标就是接通转出率,当同时使用拨打未接通负样本及拨打接通未转出负样本时,优化目标变为拨打转出率。基于此,一个最简单想到的方法就是通过采样的方法,控制拨打接通未转出负样本及拨打未接通负样本的样本比例,等效于对负样本进行加权的过程(经实测在本场景下,使用过/欠采样方法控制样本比例比直接调节样本权重效果更明显、稳定)。
使用该方法后,损失函数等价于

其中y代表了样本的真实标签,i代表了样本编号,tran代表转出标识(转出为1,未转出为0),conn代表接通标识(接通为1,未接通为0),p代表了对应标识的模型预测概率,w表示对应标识的负样本权重,conn代表拨打接通未转出负样本,not conn代表拨打未接通负样本,N代表样本总数。
以上损失函数使得模型在训练时,除了拨打接通的样本外,既考虑了拨打后未接通的样本,又考虑了拨打后接通但是没能转出的样本,且这三者对模型学习的重要性关系可以通过权重参数进行调节(保持正样本权重固定,只需调节两个参数,通过网格搜索即可),通过以上逻辑训练出来的模型,能综合考虑接通、转出等业务环节,从而实现同时优化拨打转出率及接通转出率的目标。在本场景中,机器学习模型选用了XGBoost[1],通过Grid search对两种负样本比例进行搜索,找到使拨打转出及接通转出两个任务平均AUC最高的权重作为模型选择的最终权重。
2.版本效果
在离线实验中,该多任务学习基线模型相比XGB单任务学习模型,拨打转出AUC 相对提升-0.31%,接通转出AUC 相对提升2.72%。
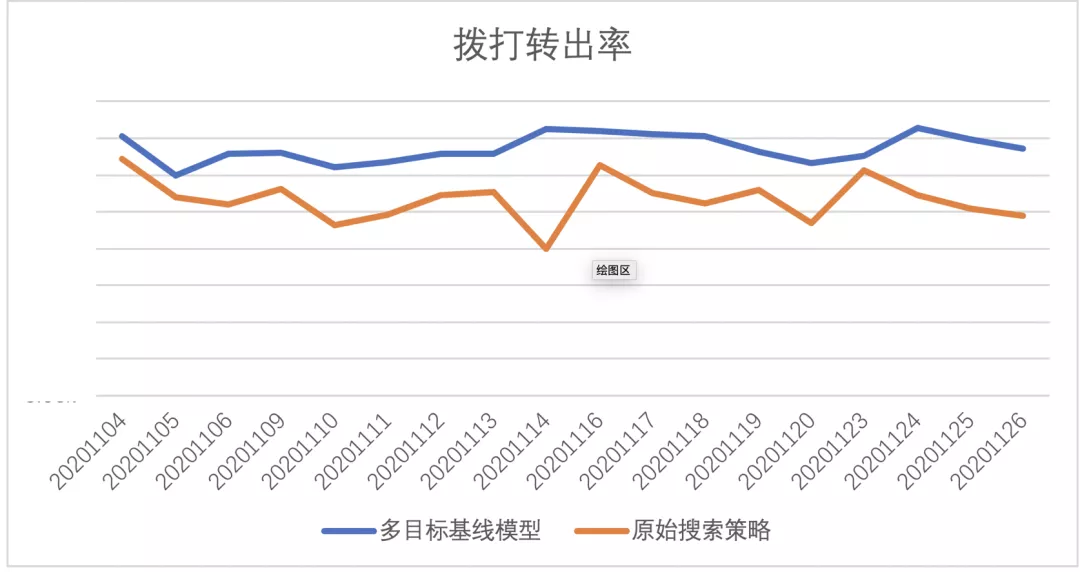
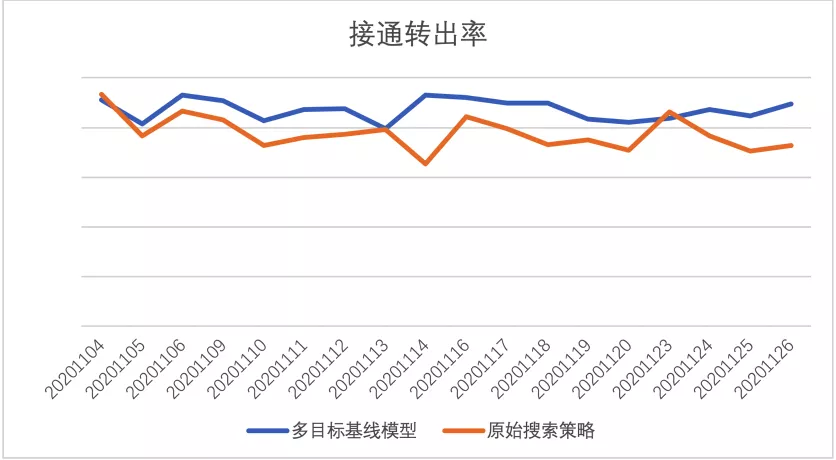
取得离线收益后,对该模型进行了第一次上线,线上CRM使用的原始策略为商机成单质量分评估与销售星级匹配(不同等级的商机按策略分配给不同等级的销售,不赘述),相比CRM商机智能分配系统原始策略,版本一:基于XGBoost+样本采样的多任务机器学习基线模型:
拨打转出率相对提升26.18%,接通转出率相对提升12.17%,分日数据见下图:
3.版本优劣势分析
通过传统机器学习+样本采样加权方法的优点是实现简单,通用性强,且见效快,可以用最快速度拿到收益,这让它成为了一个非常好的基线方法。但是,这种建模方式本质上仍是单目标建模,没有同时使用到多个目标的信息用以相互参考,也没有对多目标之间的相关性进行刻画。在实际上线中发现其效果上限较低,即使增加数据和模型复杂度也难有进一步提升。基于此,我们在下一个版本中选用了多任务深度学习框架替代了传统机器学习,期望利用深度学习模型结构的复杂性、灵活性,以及业界现有的一些成功的落地经验提升模型效果。
版本二:基于MMoE进行优化的多任务深度学习模型
1.模型介绍
在正式引入MMoE框架前,首先要对多任务深度学习的历史做下简要回顾。如下图所示,在多任务学习之初,建模主要通过共享底层(share bottom)的方式,即所有目标共享完全一致的输入,只在最上层塔网络(Tower)处进行区分。
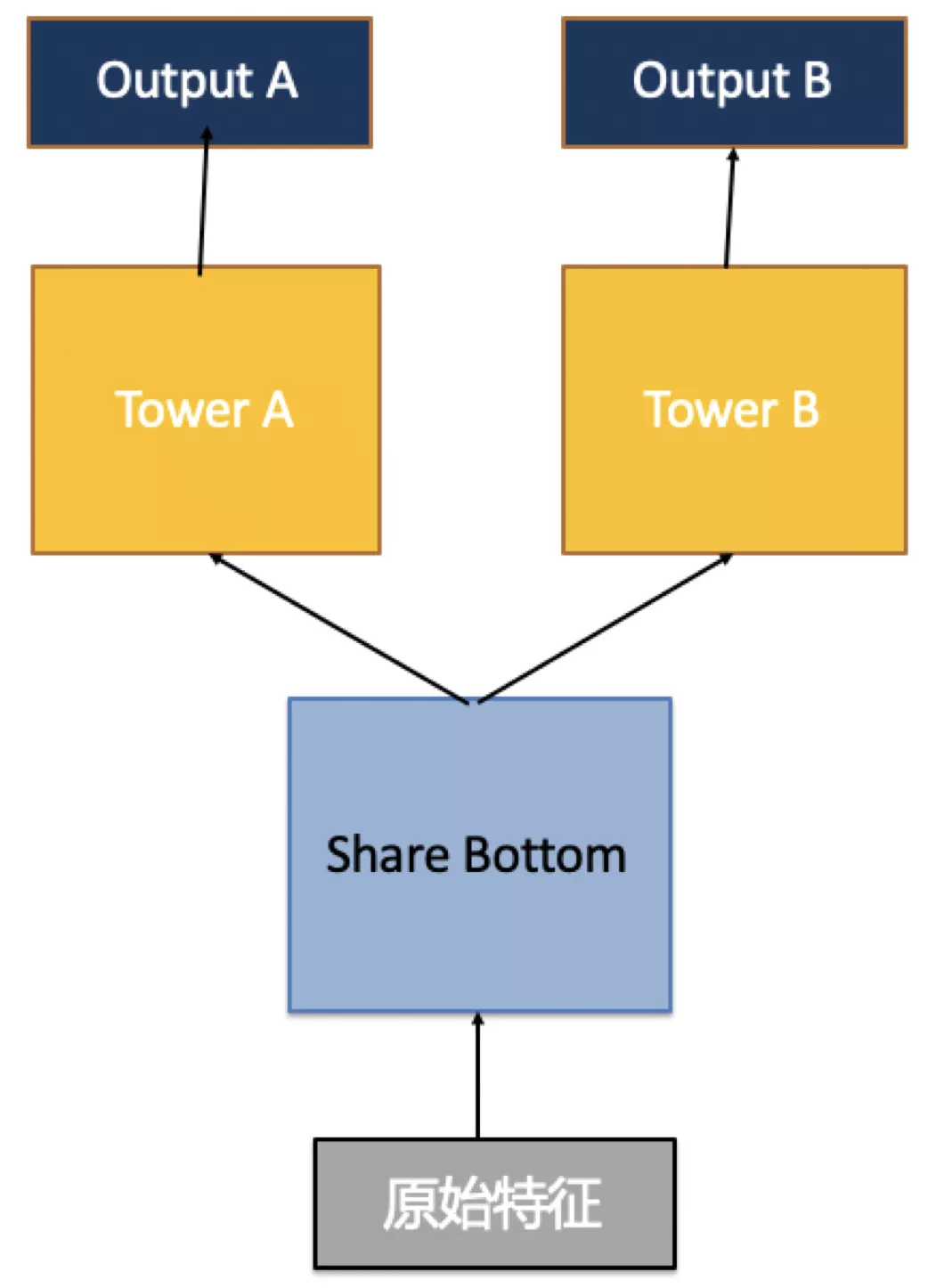
显而易见,该方法通过对所有的任务使用同样的底层参数(参数硬共享),实现了传统单任务模型难以实现的各个任务之间的知识迁移,且训练时因为要同时提升多个目标的效果,Share Bottom层会倾向于提取泛化能力强的特征,大大降低了过拟合的风险。但是,Share Bottom结构必须使用同样的底层特征,在目标相关性不够高时,有较大概率造成两个目标都无法良好学习的严重后果。举个例子,假设某次训练多任务深度学习模型的目标分别是如何定义猫与如何定义狗,Share Bottom层有高概率会抽取一些例如毛发,叫声等特征,在这样的场景下,对每个任务都能获得较好的效果。但是,如果任务变为如何定义猫与如何定义坦克,因为两者相关性不强,很难抽取到同时在两个场景下都有强分类能力的特征组。学习过程中容易出现“跷跷板效应”,即对一个目标效果好的参数或特征,往往会导致另一个目标下降,模型震荡会十分严重。
为了解决这一问题,谷歌在2018年提出了MMoE模型[2],目的是在不显著增加Share Bottom类模型复杂度的情况下,提升刻画与学习各个任务间差异点的能力。MMoE模型可以简单理解为用MoE层替换Share Bottom层的模型。
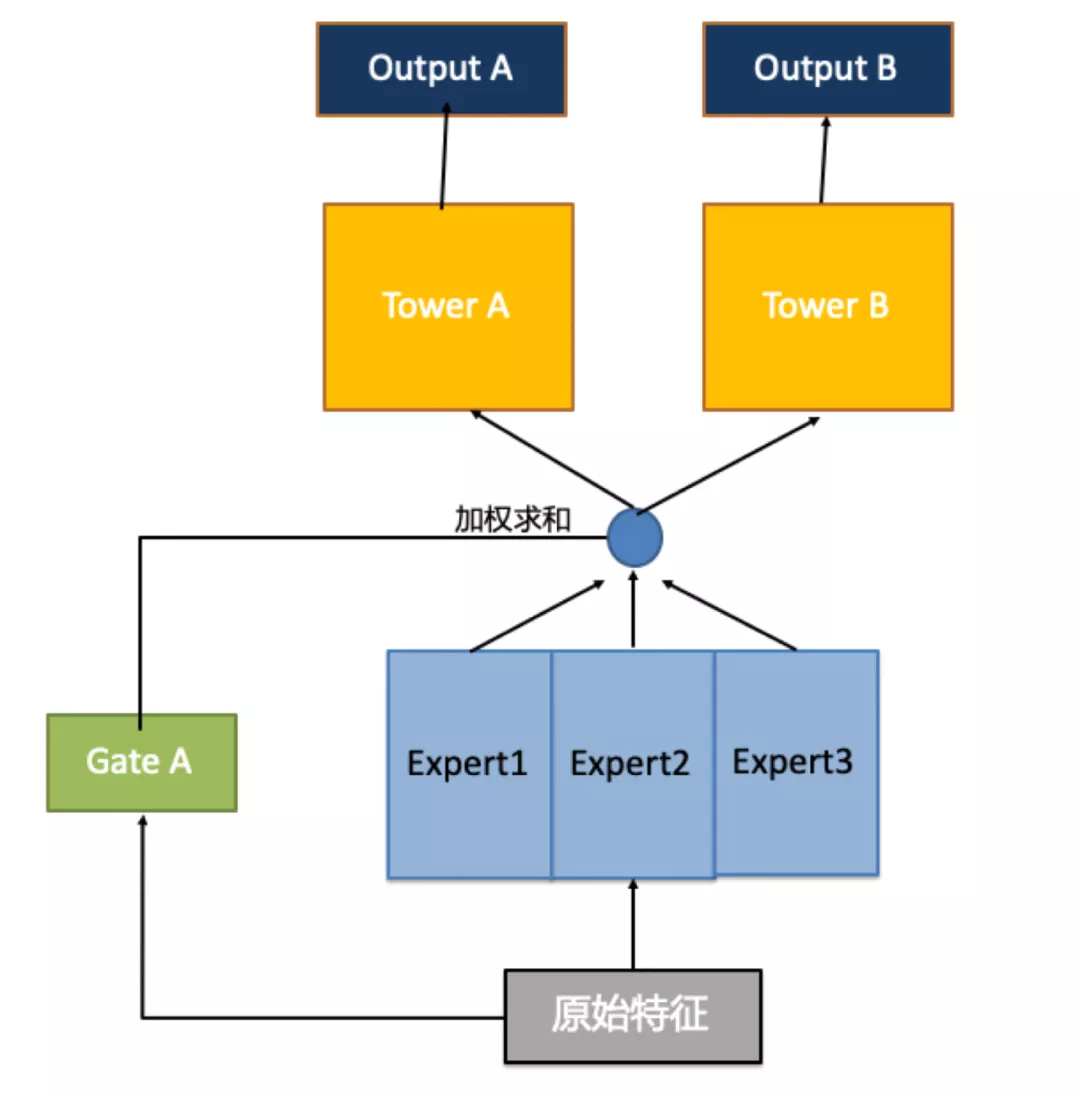
如上图所示,MoE层的应用方法是将共享底层变为多个子网络(称为专家网络,Expert,可用DNN实现),专家网络之间参数不共享。之后,门控网络(Gate,可用Softmax实现)通过原始特征学习各个专家网络的权重,最终,专家网络输出与门控网络输出进行乘积求和后作为最上层塔网络的输入,塔网络输出多任务概率结果。相比原始Share Bottom方法,MoE层与随机森林有些类似,通过基于多个独立模型的集成方法,构建多个子网络,获得更好的表达效果。
将Share Bottom结构与与MoE层相结合,我们就得到了如下图所示的MMoE模型示意图:
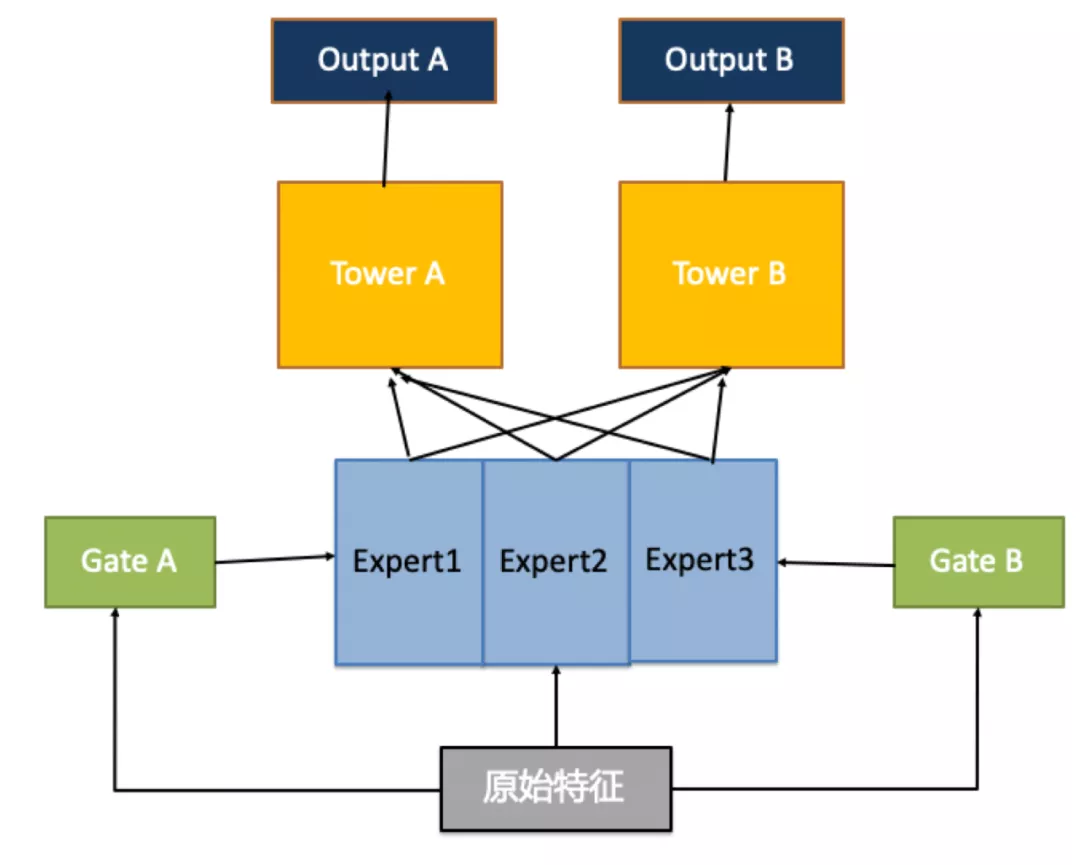
与MoE模型相同,MMoE模型中的多任务仍然共用多专家网络底层,核心区别点在于,每个任务训练独立的门控网络,用于个性化生成对应任务下专家网络的权重。仍然以上文中提到的识别猫与识别坦克为例,如果将MMoE模型应用在该问题中,模型学习出的专家网络1可能是颜色类特征,专家网络2可能是皮毛类特征,专家网络3可能是武器类特征。在这种情况下,识别猫的门控网络会给Expert1、Expert2更高的权重,识别坦克的门控网络会给Expert1、Expert3更高的权重。通过这种方式,即使多个任务间相关性不够强,也能利用其相似的部分进行信息共享,更灵活、准确的拟合各个任务目标。
最终,参考MMoE模型,版本二模型建模结构图如下所示:
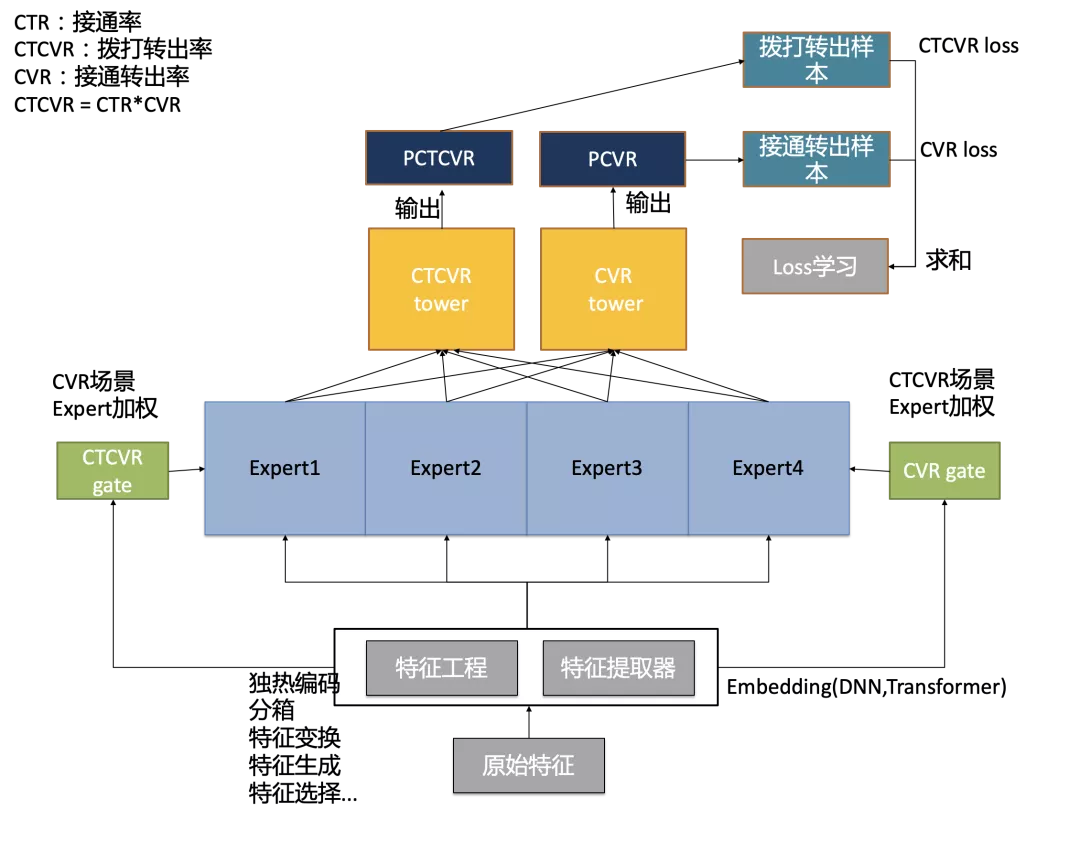
使用MMoE模型范式,将两个目标分别设定为拨打转出与接通转出,在传统MMoE的基础上,额外扩展出特征处理层,包含特征工程及特征提取器两部分,其中特征工程负责对基础特征进行如分箱,归一化等的加工,特征提取主要负责灵活接入机器学习及深度学习生成的多种Embedding方式,并与其他特征拼接后一并送入MMoE模型结构中,在第二版模型中,我们先后尝试过XGBoost叶节点Embedding,transformer Embedding,时间/行为序列Embedding等方法,供读者参考。另外,在本版模型的设计中,Expert网络进行了模块化结构,可以灵活替换多种基础模型(如DNN,DIN等)。从第二版模型开始,模型均沿用特征处理层及专家层灵活可变的设计,用于快速的模型实验及上线。
2.损失函数设计
除了模型结构,多任务学习模型的另一个重要组成部分就是损失函数,注意,损失函数与最终评估时使用的评估指标是有所不同的,一个好的多任务损失函数,不但能用于衡量模型当前训练结果的好坏,也应该能在模型训练的每一步中,及时发现多个任务间训练进度、效果的差异,及时调整,帮助模型快速收敛到一个效果较好的版本。
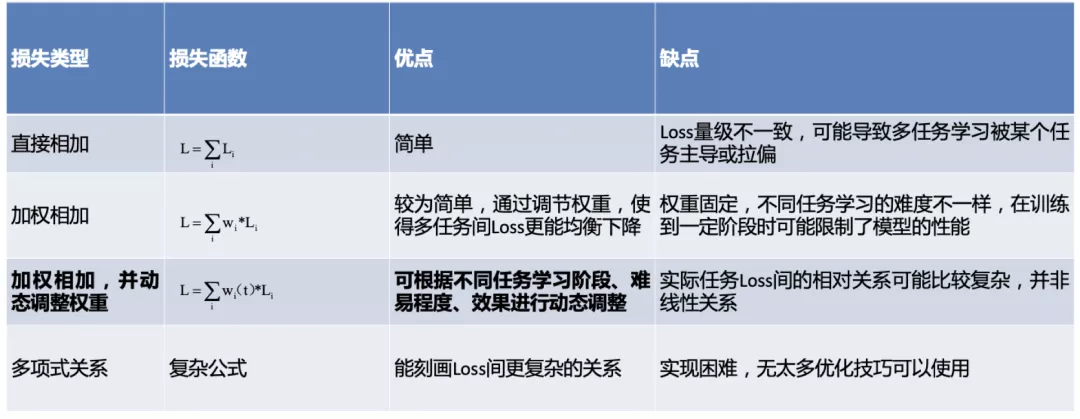
如上表所示,我们对多任务损失函数进行了类型的总结,将其分为直接相加、加权相加、加权相加+动态调整权重、以及多项式关系四个大类。经过实际测试,需要优化的两个目标(拨打转出率、接通转出率)在loss值量级上有一定差异,所以用直接相加的方法会使得量级较小的目标得不到充分优化,该方法排除。另外,预先通过量级对不同目标赋予不同但固定的权重也是不可行的(加权相加),因为实际离线模型训练过程中发现,虽然通过权重调节可以让初始状态时任务间的权重相近,但是因为拨打转出与接通转出任务学习难易度有差异,经过几轮迭代后,损失量级重新变的差距很大,严重影响训练效率。所以,在本例中,选用了加权相加并动态调整权重的方法。
为了实现权重动态调整,试验了如下表所示的几种方法,并将总结的优缺点一并附上。
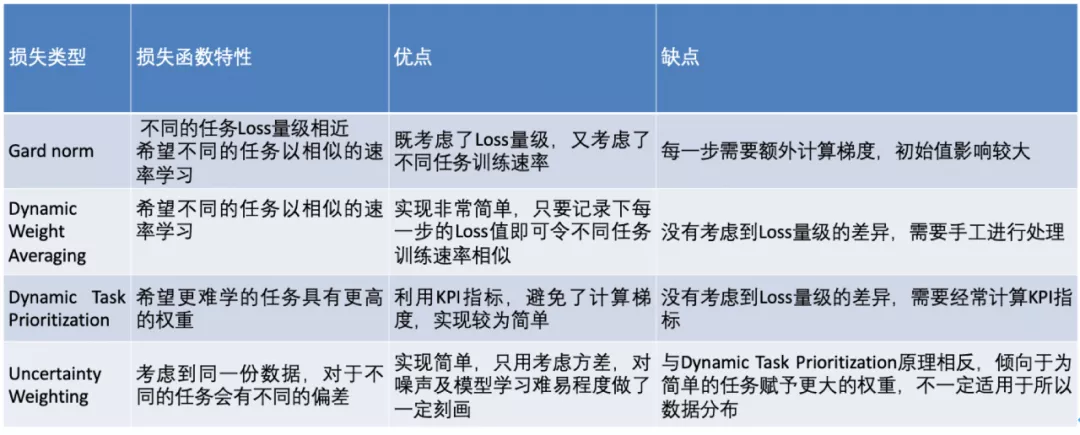
通过对这几种方法进行离线测试及原理分析,选用了不确定性加权[3]的方法。该方法认为可以用不确定性代替权重来辅助模型训练,因为多任务模型中的不确定性表示了对该任务预测的置信程度,而每个任务的最优权重应该与置信程度高度相关。
普遍认为,模型中存在两类不确定性:
认知不确定性:代表了模型中的固有不确定性,一般是由于训练数据量的不足,导致对于模型没见过的数据置信度较低,这种不确定性蕴含在模型参数中,可以通过增加训练数据解决。
偶然不确定性:具体又分为两小类,数据依赖型:即因为数据本身天然误差(因为标注、脏数据等原因)带来的不确定性,这种不确定性显然是异方差的,且会对最终模型输出产生影响。任务依赖型:因为任务本身特性而产生的不确定性,与数据无关,例如,将一个人每日开销作为特征,预测年收入与预测寿命,虽然特征相同,两个任务预测结果的置信度会有天然的差异。这种不确定性是同方差的,且只和任务本身有关,最终加权时选用的就是该类型的不确定性。
基于以上原理,不确定性加权公式如下所示:
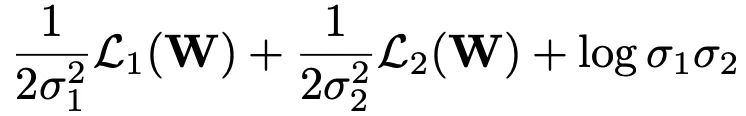
利用损失函数的累积方差,衡量模型学习的难易程度,并进行实时的调整。在训练过程中将损失函数由加权相加替换为不确定加权方法后,拨打转出及接通转出AUC均出现略微上涨,且平均收敛Epoch数从117大幅降低为19。
3.版本效果
在离线实验中,第二版模型相比多任务学习基线模型,拨打转出AUC 相对提升1.95%,接通转出AUC 相对提升0.11%
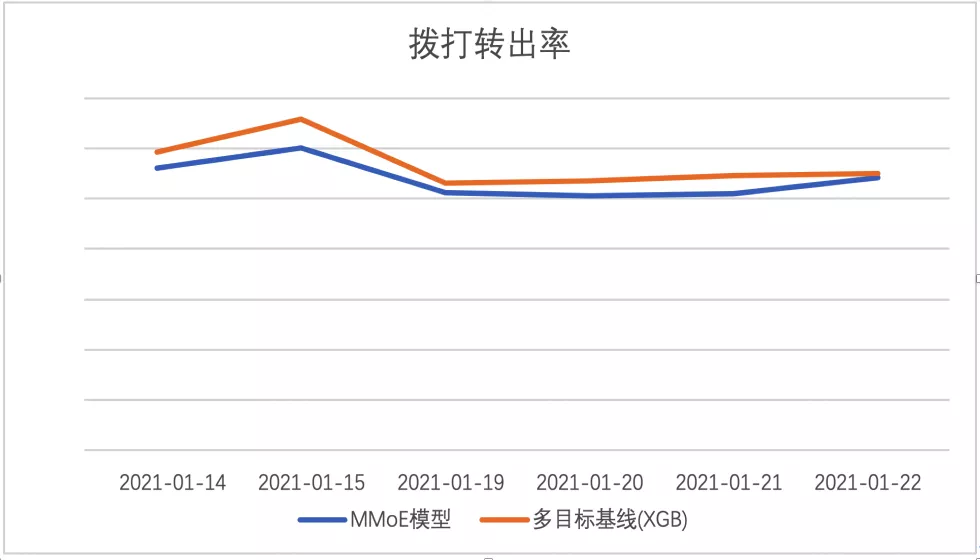
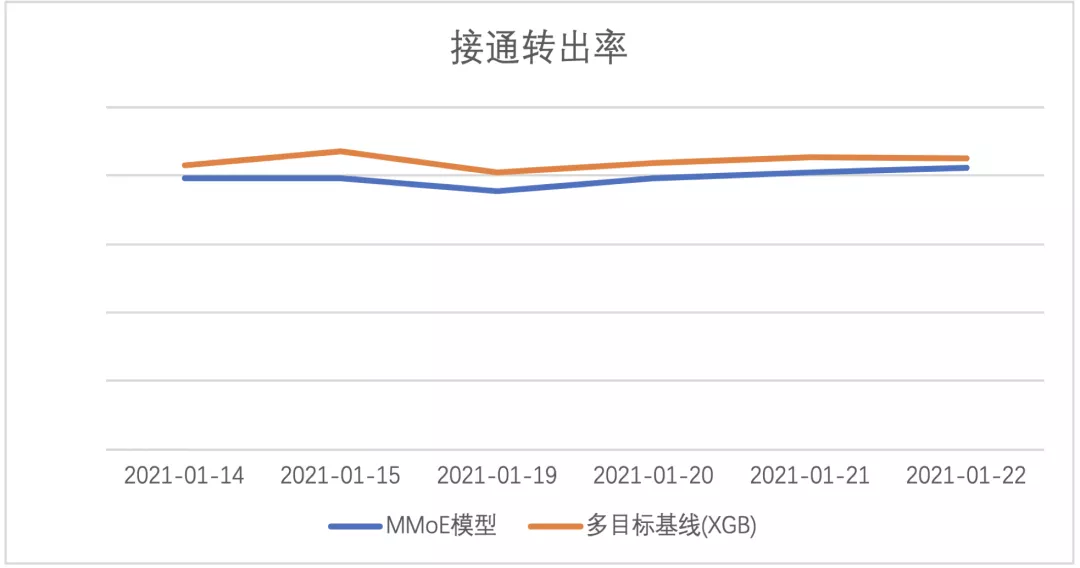
取得离线收益后,对该版模型进行了上线,相比第一版模型,版本二:基于MMoE进行优化的多任务深度学习模型
拨打转出率相对提升7.85%,接通转出率相对提升8.26%,分日数据见下图:
4.版本优劣势分析
版本二同时建模了拨打转出及接通转出两个目标,使得模型在训练阶段做到信息共享,是真正的多任务学习。另外,通过每个目标独享的门控网络,实现了对不同任务选取不同专家网络,并赋予不同的权重,自由度及泛化能力强。在版本二实现中,专家网络与特征处理层都可以通过引入不同模型进行灵活自定义,应用范围相当广泛。但是,模型建模时没考虑到接通转出与拨打转出在数学意义上天然的关系,即两个目标间之间的相关性。为解决这一问题,我们构建了下个版本的模型。
版本三:通过ESMM范式为MMoE模型引入多目标相关关系
1.数据分布问题介绍
在正式进入第三版模型之前,首先分析下使用如版本二所示的建模方式不能解决的数据分布问题。
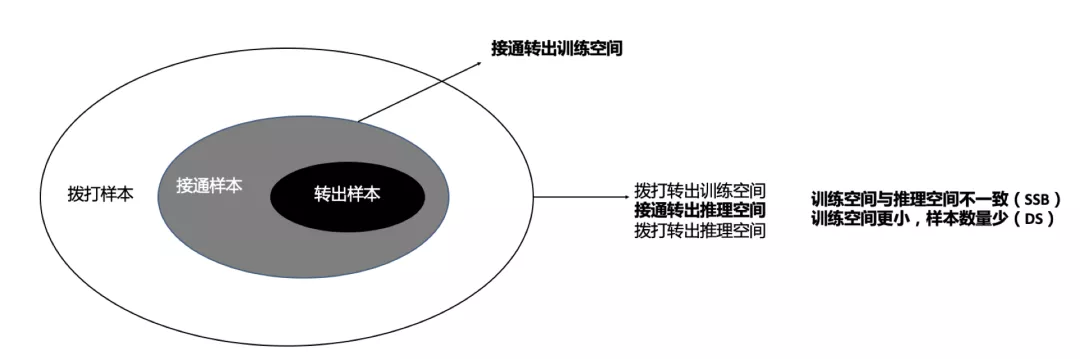
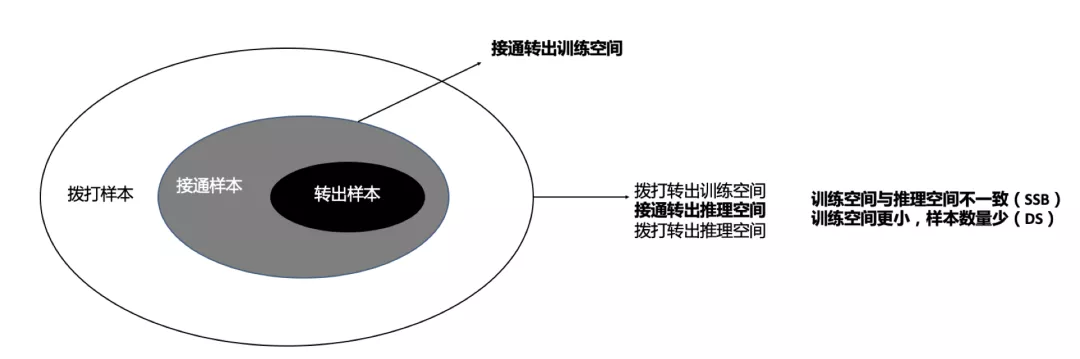
本场景下的拨打转出及接通转出样本分布如上图所示,
拨打转出正样本:拨打->接通->转出样本
接通转出正样本:拨打->接通->转出样本
拨打转出负样本:拨打->无论是否接通->未转出样本
接通转出负样本:拨打->接通->未转出样本
结合样本空间图及样本定义,可以得到这样的结论:对于拨打转出率模型,训练空间及推理空间都是一致的(训练时使用全量拨打数据,推理时同样使用全量拨打数据),但是对于接通转出率模型,训练空间只有全量接通数据,推理空间却仍是全量拨打数据,两者出现了数据分布的不一致(即SSB问题),另外,接通数据量相比拨打数据量是非常稀疏的(即DS问题),容易导致这一目标训练的不够充分。
2.模型介绍
为了解决SSB及DS这两个问题,我们对要优化的两个目标:拨打转出、接通转出进行了转化链路分析。任何一条商机,如果想要成功转出,都要经过拨打->接通->转出这条路径,由拨打转出率与接通转出率的定义,我们不难得到以下公式:
拨打转出率(CTCVR) = 接通率(CTR)X 接通转出率(CVR)
其中拨打转出率与接通率均可使用全空间的数据进行训练,那是否可以考虑通过这两个目标天然的数学关系,以接通率为桥梁,同时优化拨打转出率及接通转出率呢?带着这个问题,通过查阅资料,在版本二的基础上,引入了ESMM范式[4]。
基于ESMM网络的范式会分别预估CTR和CVR,然后使用乘积的方法得到CTCVR的结果。预估的CTR结果会直接和真实标签进行损失计算(可以用全空间数据),预估的CVR结果并不直接用来计算损失,而是作为中间变量,与CTR结果相乘得到CTCVR结果后,再通过CTCVR的标签数据计算损失(同样可以用全空间数据)。这种计算方式,相比之前设想的直接预估CTR及CTCVR,然后通过除法计算CVR的方式会更稳定(除法无法保证CTR>CTCVR,即CVR<1)。
最终,将ESMM机制引入版本二后,模型网络结构图变为如下所示:
在MMoE的基础上,将拨打转出率及接通转出率的数据关系考虑了进去,理论上会进一步提升模型效果。
3.版本效果
相比MMoE模型,MMoE+ESMM模型在离线实验中,拨打转出AUC 相对提升-0.11%,接通转出AUC 相对提升1.74%
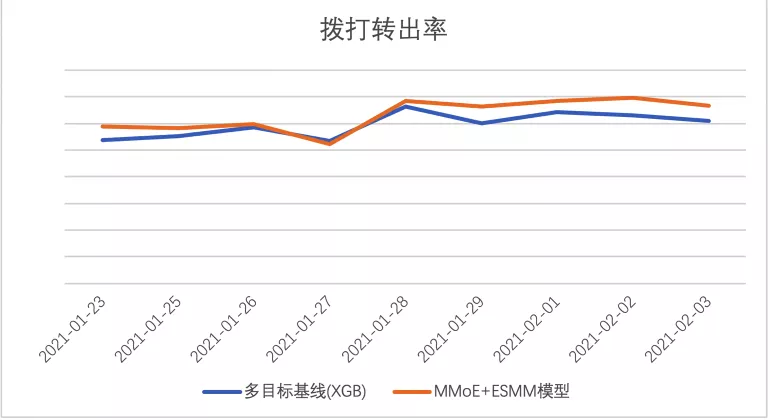
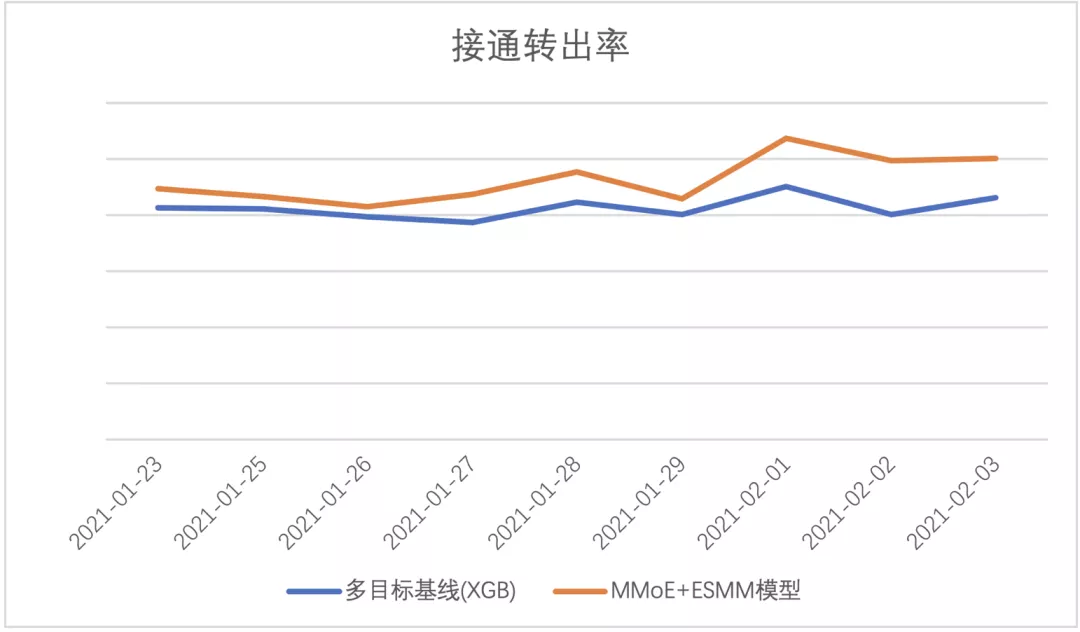
之后,对该版模型进行了上线,相比第一版模型,版本三:通过ESMM范式为MMoE模型引入多目标相关关系的模型
拨打转出率相对提升5.31%,接通转出率相对提升11.03%,分日数据见下图:
4.版本优劣势分析
版本三在版本二的基础上,通过引入多任务之间相关性的方法,解决了DS及SSB问题,另外,通过对线上真实数据进行抽样分析,我们看到在引入ESMM范式后,数据多样性指标有了较大的提升(即重复推送的比例有所降低,之后会在关于提升覆盖率的文章中详细分享)。但是,在尝试进一步迭代时,我们发现,继续对该模型进行调优或添加辅助任务,无法让模型效果获得显著的提升。经分析,我们认为,MMoE模型中的Expert是被所有任务所共享的,所以在任务间相关性复杂或薄弱时,Expert网络无法利用多任务的数据对特征进行很好的学习和捕捉。另外,在MMoE类模型中,Expert之间不存在交互,这导致有一部分信息可能被损失掉。为解决上述问题,我们继续对模型进行了迭代。
版本四:使用PLE模型替换MMoE模型,并添加更多辅助学习任务
1.辅助学习任务
在建模过程中,通过不断与业务方的沟通及交流,并与线上埋点日志进行印证,掌握到一些销售的偏好及行为模式。从中总结了两个与商机组转出行为在业务含义上有依存关系的指标:电话接通时长与成单(本版本模型只使用了电话接通时长)。根据业务定义,只有满足电话接通时间超过30s的商机,才允许销售进行转出。另外,电话接通时长相对于转出来说更为稳定(销售人员转出原则可能在短时间发生变化,但是接通时长由销售人员与客户共同决定,相对不易受到影响)。所以,额外添加电话接通时长作为辅助任务,会令模型泛化能力更强,也相当于一种在模型学习过程添加部分噪声,从而提升模型效果的方法。
本版本模型离线训练时,添加接通后通话达到30s、以及拨打后通话达到30s两个辅助学习任务。在上线预测时,忽略辅助任务,只使用拨打转出与接通转出任务输出的结果。通过该方法,在离线评估时,拨打及接通转出AUC均有一定提升。
2.PLE模型介绍
为了解决版本三中提到的MMoE建模范式存在的问题,我们对业界在MMoE模型基础上进一步优化的方法进行了调研及分析,并最终选择了SNR[5]与PLE[6]两种模型进行复现实验,在我们的场景下,PLE模型表现较好且推理耗时更低,基于此,我们使用PLE模型替代MMoE模型,并结合辅助学习任务,生成了版本4。
PLE模型是腾讯在2020年提出的多任务学习模型,其原理是针对多任务之间的共享机制和单任务的特定网络结构进行了重新的设计,从而解决了MMoE模型在面对复杂多任务目标时可能出现的效果下降。
对于MMoE模型中Expert被所有任务共享,导致在复杂多任务场景下学习效果可能会有下降的问题,PLE通过一种称为CGC的网络结构进行了解决,该网络具体结构如下图所示:
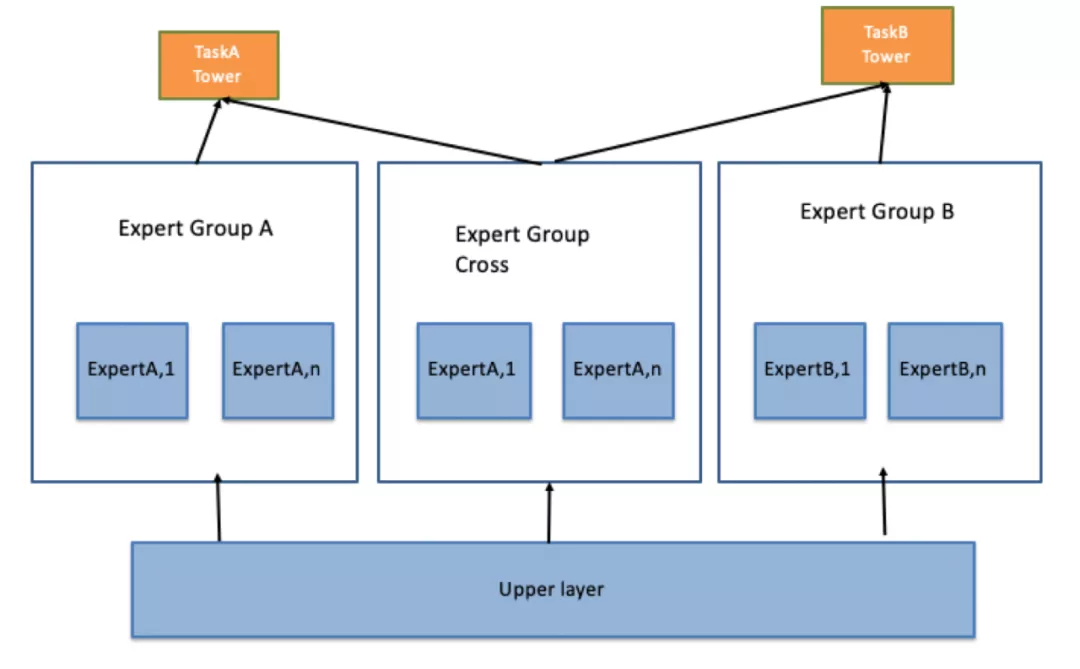
可以看到,Expert网络不再是被多个任务所共享,而是分为不同的Expert Group,对于每个任务而言,有其独有的Expert Group(Task Specific),也有与其他任务共享的Expert Group。
对于MMoE模型中,Expert网络之间没有交互,导致一部分信息没有利用上的问题,PLE模型中通过叠加多层网络进行了解决,底层抽取结构如下图所示:
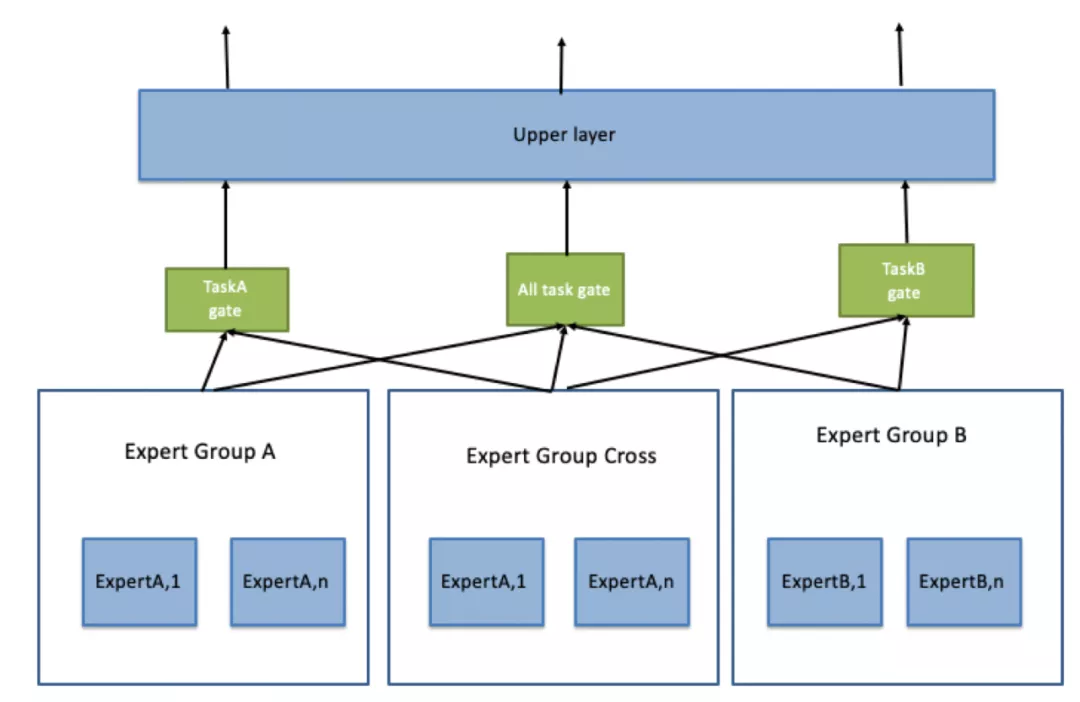
可以看到,在将输出结果送入上层CGC网络之前,底层抽取网络在Expert Group之间通过门控网络进行了交互。叠加多层类似的结构,即可使得各个Expert Group之间的信息进行充分交叉。
3.基于PLE的模型优化
PLE模型实现了Task specific Expert,即不同任务可以使用不同的Expert组。但是,在实际离线实验中我们发现,如果在一个Expert组的内部,对于不同类型的特征使用同样的模型结构,也会导致一部分信息的损失。基于此,在Task specific Expert基础上,我们又使用了Feature specific Expert,即针对不同种类的特征,使用不同种类的基础网络结构(如transformer、DNN等)。
另一个优化点是对Gate网络进行的优化,在原始MMoE模型中,Gate网络主要的用途是对于不同学习任务,通过使用softmax,对各个Expert进行加权。但是,在应用PLE网络结构后,我们发现,随着PLE层数的增多,softmax的能力变得越来越弱,在上层时已经没有明显的权重区分度。其实,Gate网络主要的作用是从Expert中提取到关键的信息,由这一点推论,我们认为使用Attention机制可以提升该加权过程的效果。
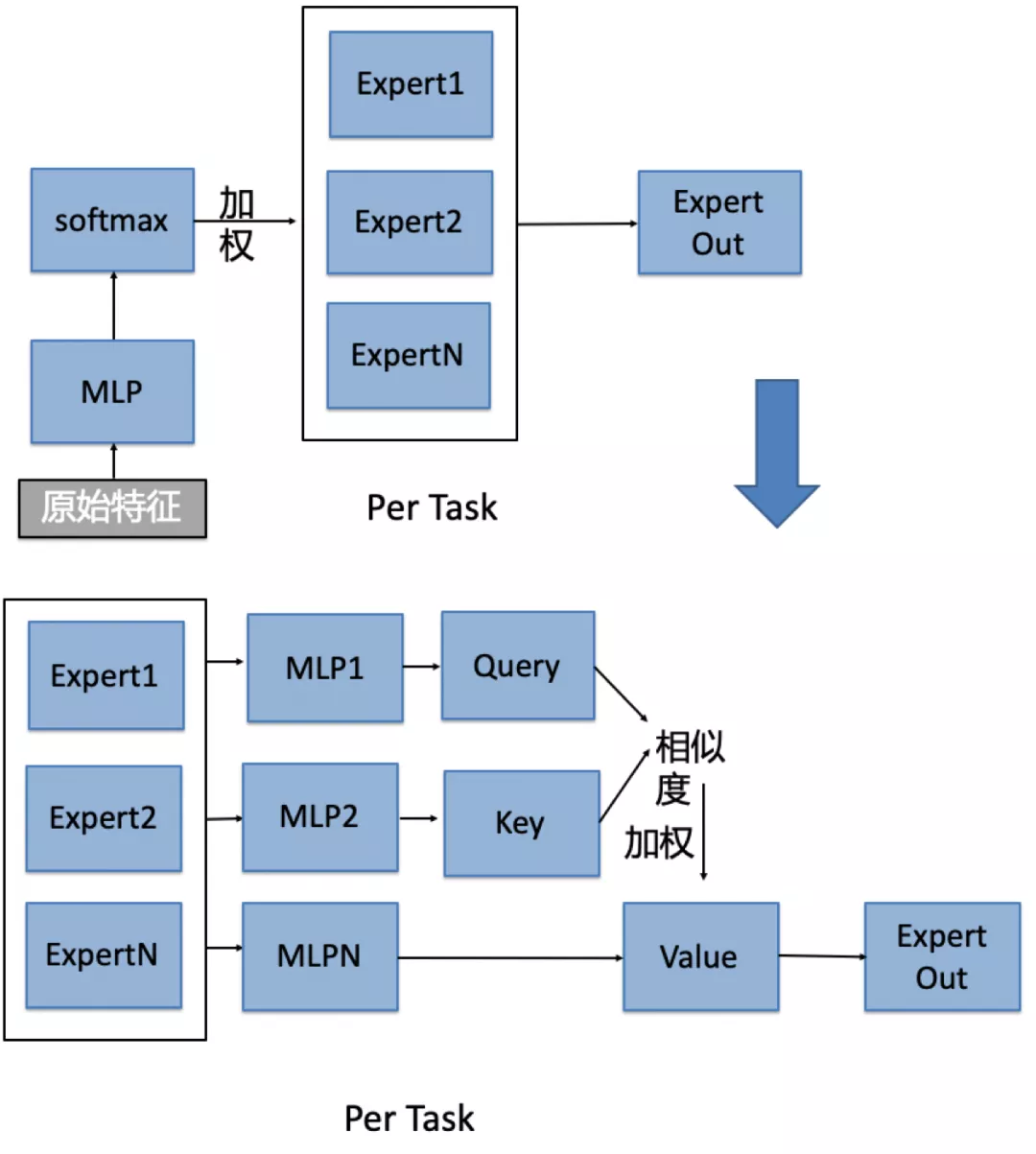
如上图所示,在实际模型落地过程中,我们将部分Gate网络的softmax通过Attention机制进行了替换,希望通过该方法能更好的识别Expert网络中的关键信息。
4.版本效果
相比MMoE+ESMM模型,在离线实验中,PLE+ESMM+Attention模型拨打转出AUC 相对提升1.97%,接通转出AUC 相对提升0.44%
上线之后,相比第三版模型,版本四:使用PLE模型替换MMoE模型,并添加更多辅助学习任务的模型
拨打转出率相对提升6.53%,接通转出率相对提升3.96%,分日数据见下图:
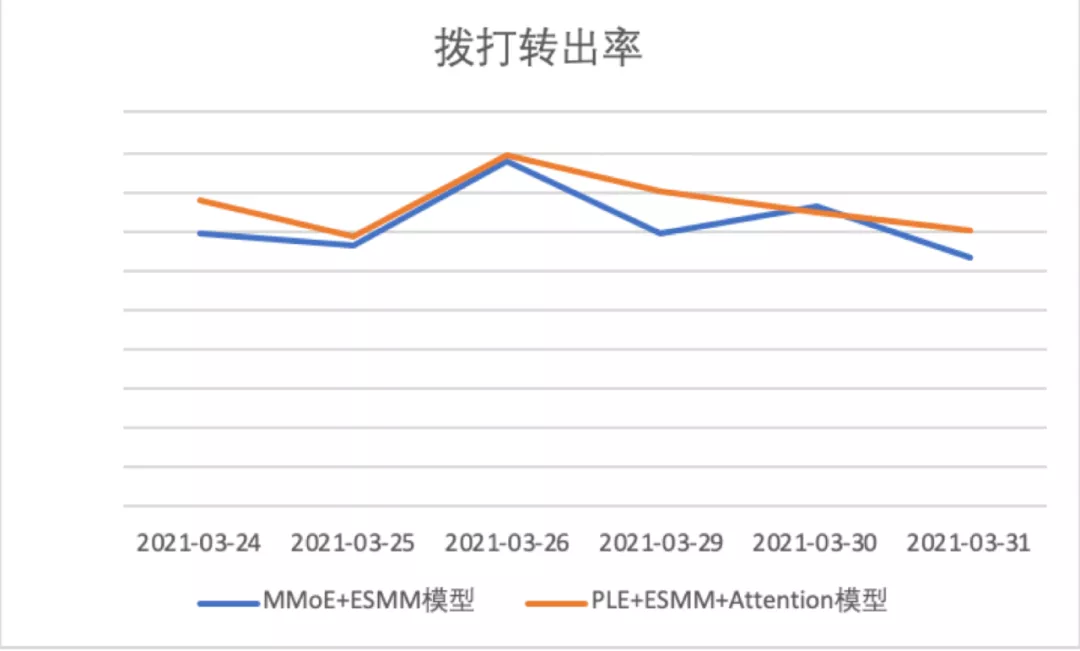
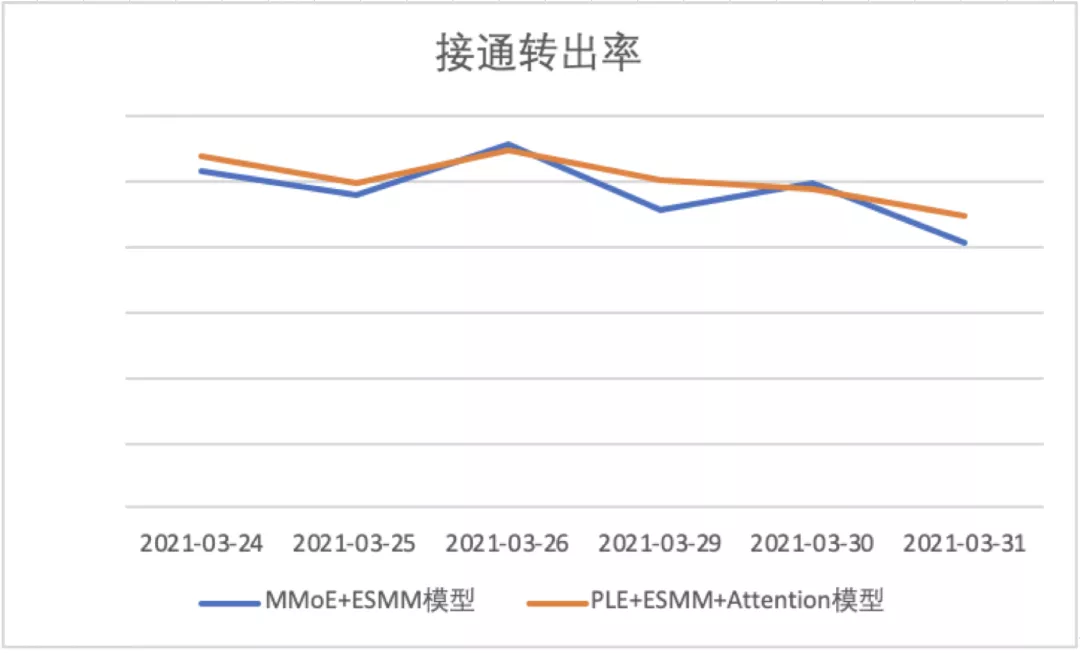
4.版本优劣势分析
相比上一版本模型,通过使用PLE取代MMoE,进一步提升了模型表达能力,且改进了MMoE结构存在的一些问题。另外,通过构建Feature specific Expert,以及使用Attention机制替代Softmax,大大增强了Expert提取关键信息的能力。但是,相比MMoE模型,模型结构的复杂性有了显著提升,对离线训练及线上推理时间会有一定影响。另外,多目标建模过程中,除了多任务模型的迭代,多目标如何合成单目标进行排序也是一个核心优化点,在之前的版本中,基本都是使用对多个目标输出进行加权的方式得到最终输出分数,并进行排序,为解决这一问题,我们又一次开始对模型进行了迭代。
版本五:对精排模型中的偏差进行建模,并优化多目标排序逻辑
1.模型偏倚建模介绍
在本版模型中,希望能通过解决场景中的偏倚(bias)问题提升线上效果。简单来讲,我们认为销售在与客户的沟通环节中,商机最终是否能转出也会受到商机排序,销售申领次数等因素的影响,且通过建模的手段能刻画出这些影响。
具体的,我们将对以下几类偏倚进行建模:
排序偏倚:
申领返回的商机列表的顺序可能对销售有影响,从而影响转出,经离线数据分析,每批返回的前半部分商机,会有更高的转出概率。
申领次数/数量偏倚:
因为一条商机不能分配给多个销售,且销售工作状态不可能在整天都完全一致,有可能在工作的不同作业阶段(例如已经完成当天任务,或仍未完成当天任务)转出的方法有所不同,所以申领累计次数/数量可能对精排结果造成影响。
申领时间偏倚:
销售倾向于在申领后立刻进行作业,但是不同商机对应的用户方便沟通的时间可能是不一致的,所以销售在不同时间申领商机,精排模型的效果会受到影响。
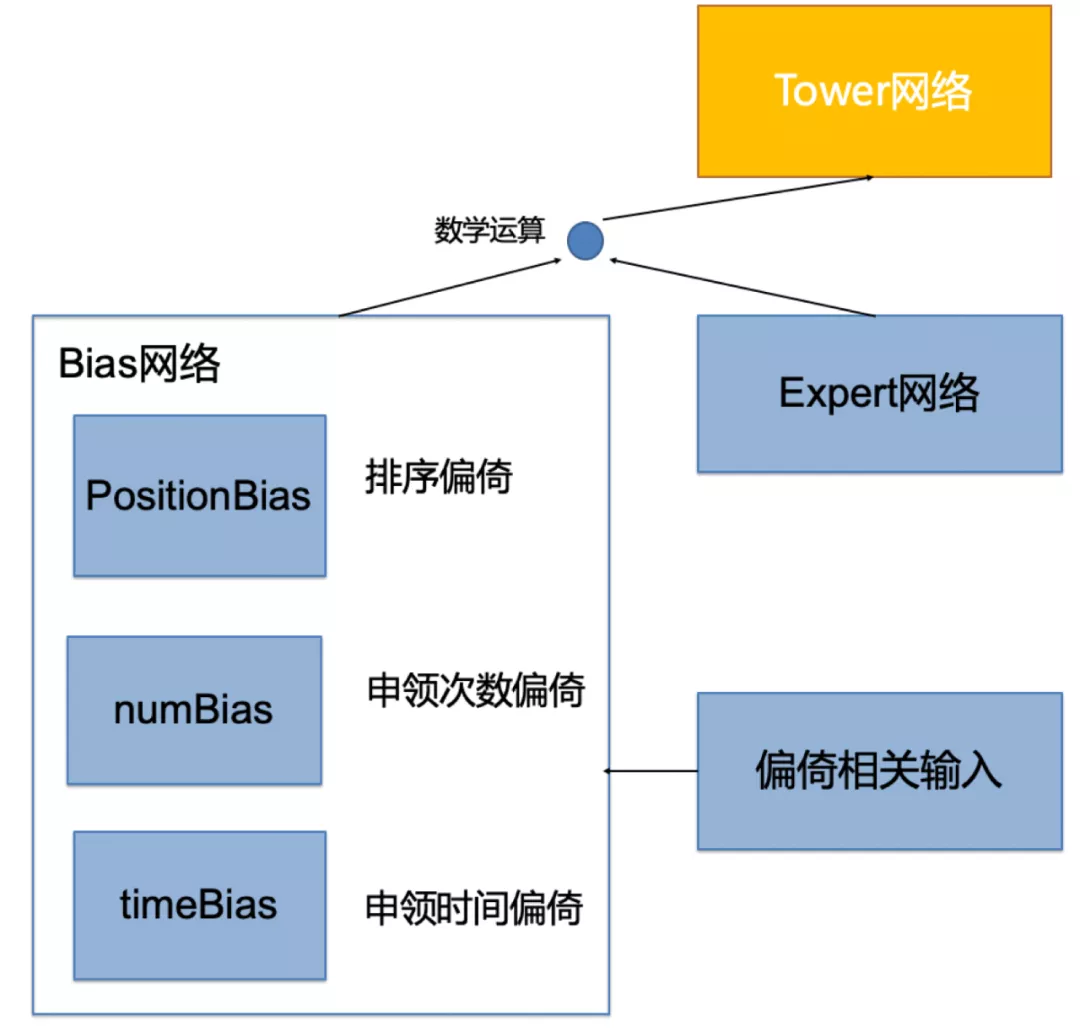
如上图所示,对位置,申领次数/数量,申领时间,均使用将对应偏倚的特征(人工提取,最能表达该类偏倚的属性),在离线训练时输入一个简单网络结构,从而对偏倚刻画的方法进行模型生成。使用该方案,模型会由原来的一个部分变为两个部分,一部分专心学习上文所述的各种偏倚,另一部分就可以学习到更接近无偏的销售及商机匹配度。线上预测阶段,将全部商机的偏倚特征都设置为统一值,从而减少了Bias对模型的影响。
2.多目标排序优化逻辑介绍
可以将多目标建模过程拆解为两阶段任务,多任务学习与多目标排序。
多任务学习:接收输入数据,输出各个任务的个性化预测值
多目标排序:接收各个任务的个性化预测值,输出可供排序的单一数值
无论对多少个任务进行学习,最终在排序阶段只能使用一个数值。
在版本五之前,我们均通过根据规则对输出概率加权融合的方法进行排序指标的生成。具体公式如下:
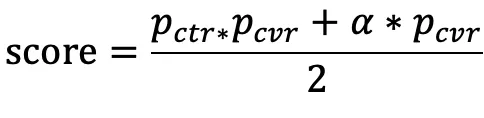
其中a变量为加权变量,控制拨打转出率(ctcvr)与接通转出率(cvr)的加权因子,因为ctcvr概率小于cvr概率,所以a取值范围为[0,1]。确定a最终数值的方法是通过在取值范围内进行网格搜索,找到能使得拨打转出与接通转出平均离线AUC值最大的参数作为a的最终取值。
在版本五中,我们尝试了一种利用模型进行多目标排序的方法。
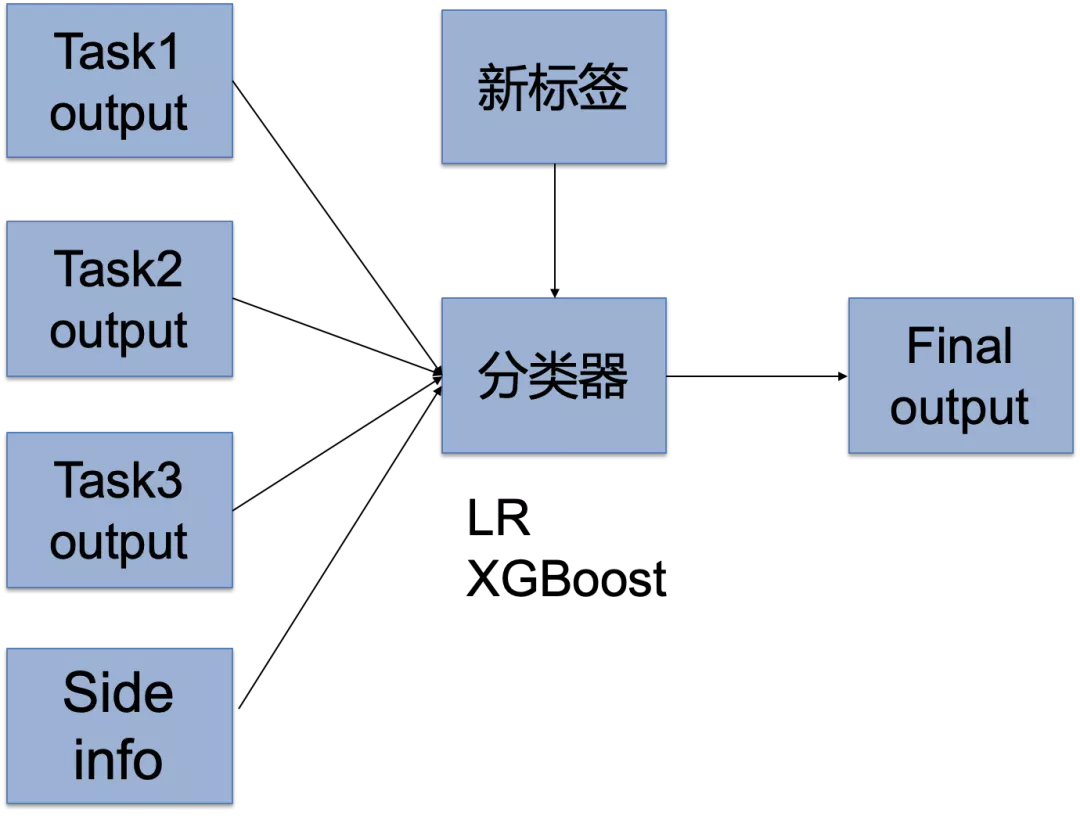
如上图所示,具体实现时,采用了类似模型融合的方法,将多任务的概率输出作为输入送入分类器,进行二阶段模型训练。另外,为了模型效果的稳定,一些对转出有高度相关性的特征会加入Side info中同样作为二阶段模型输入(例如历史接通时长、销售排名等)。二阶段模型训练时使用的标签,是我们对真实标签进行线性组合的方式得到的,公式如下:
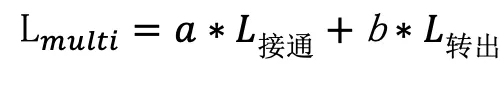
L代表着真实标签,若接通则接通标签为1,若转出则转出标签为1,否则为0。a与b代表着对应标签对实际销售过程的重要性,通过产品及运营讨论得到,在本场景中,我们将接通的权重设为1,转出的权重设为4。
最终,线上预测时,通过将多任务模型输出结果与部分特征送入二阶段模型,就得到了最终唯一的排序分数。
3.版本效果
因为涉及到de bias过程(偏倚去除),该方法不适合进行离线评估,直接给线上效果。
上线之后,相比第四版模型,版本五:对精排模型中的偏差进行建模,并优化多目标排序逻辑模型,拨打转出率相对提升6.78%,接通转出率相对提升11.75%,分日数据见下图:
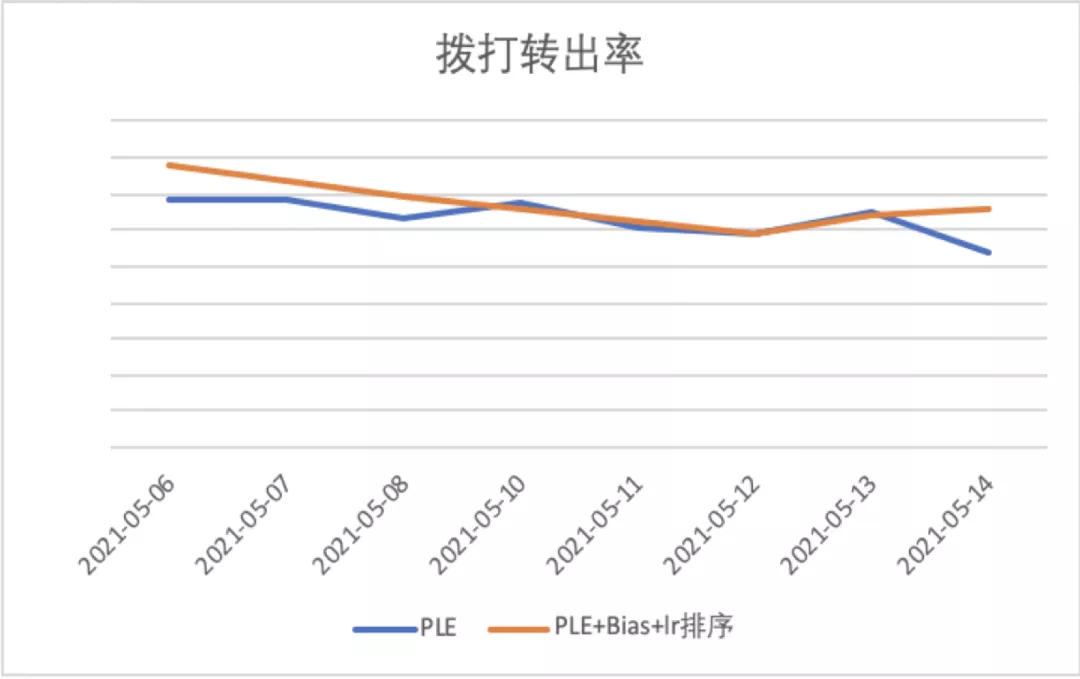
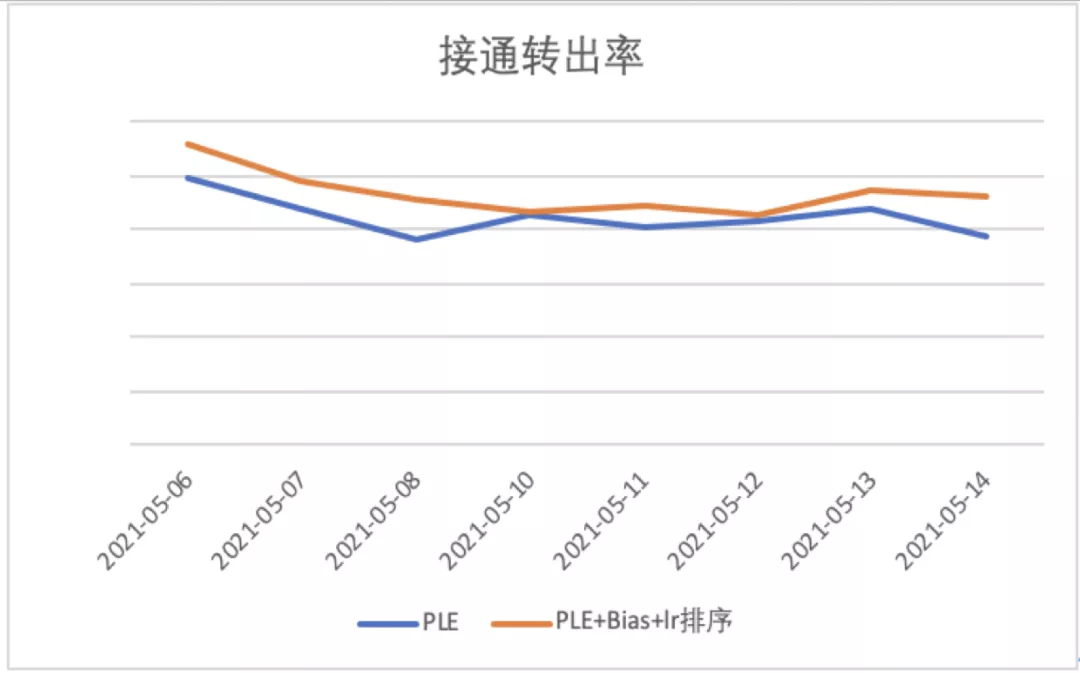
4.版本优劣势分析
相比版本四,版本五在推荐算法的de bias过程与多目标排序优化方面做了一些工作,且在线上取得了一定的收益。这个阶段也是我们当前迭代的最新结果,截止到目前,对模型进行参数与结构的调整已经效果不显著,且模型参数量到达了P40单卡按日训练的瓶颈。希望在后续版本的优化中,在不增加模型复杂度的基础上,提出方案继续迭代。
总结与展望
文章小结
1.在黄页密歇根商机组一键申领场景中,使用多目标建模方法,相比单目标建模,确实能更好的同时提升拨打转出率及接通转出率。
2.通过结合传统机器学习模型与样本采样,提出了一种快速落地的多任务学习基线,该方法在类似场景下,可以最快速度拿到收益。
3.通过引入MMoE范式,构建了真正的多任务学习模型,相比基线模型,无论是拨打转出率还是接通转出率都有了一定提升。
4.在下一阶段,通过借鉴ESMM范式,显式建模了拨打转出率与接通转出率的数学关系,并解决了SSB与DS问题,在接通转出率这一指标获得了较大提升。
5.通过用PLE模型替换MMoE模型,并引入Feature specific Expert和Attention,在付出一定复杂度的代价下增强了模型的表达能力,最终在拨打转出率及接通转出率两个指标上进一步获得了提升。
6.将传统推荐算法中对Selection Bias的处理方法迁移到PLE模型中,并对多任务输出概率最终如何合并为一个指标进行排序做了一些探索,在优化的两个任务上,效果均有所提升。
未来可能优化点展望
未来我们准备从特征、模型、业务这三个角度持续对本场景进行优化。
特征方面,我们经过与公司内部算法及数据团队的多次交流,决定引入更多、更丰富的多模态特征数据(如语音、文本、图片等),这其中尤以销售与客户沟通产生的对话文本价值最高(基于销售与客户沟通的话务数据,AILab内部团队针对营销等数个58内部的个性化场景自主研发了一套高质量的ASR引擎)。结合了销售与客户的历史话务文本类特征后,相信模型效果会有一个大的提升。
模型方面,当前在多任务模型学习的过程中,无法保证一个目标的提升不引起另一个目标的下降(即帕累托有效性),希望在后期的模型迭代中,针对我们的个性化场景,将学术界与工业界中能确保模型在帕累托平面变化的最优化方法落地到模型训练过程。
业务方面,当前建模方法与电商推荐系统相似度很高,但是,销售推荐商机场景与电商等传统推荐场景有很多差异点,希望在之后的迭代过程中,能更吃透业务,并基于业务差异点修改模型,使得该模型在CRM场景上更加适用,从而获得效果提升。
参考文献:
[1]Chen T, Guestrin C. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining 2016 Aug 13 (pp. 785-794).
[2]Ma J, Zhao Z, Yi X, Chen J, Hong L, Chi EH. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining 2018 Jul 19 (pp. 1930-1939).
[3]Kendall A, Gal Y, Cipolla R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InProceedings of the IEEE conference on computer vision and pattern recognition 2018 (pp. 7482-7491).
[4]Ma X, Zhao L, Huang G, Wang Z, Hu Z, Zhu X, Gai K. Entire space multi-task model: An effective approach for estimating post-click conversion rate. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval 2018 Jun 27 (pp. 1137-1140).
[5]Ma J, Zhao Z, Chen J, Li A, Hong L, Chi EH. Snr: Sub-network routing for flexible parameter sharing in multi-task learning. InProceedings of the AAAI Conference on Artificial Intelligence 2019 Jul 17 (Vol. 33, No. 01, pp. 216-223).
[6]Tang H, Liu J, Zhao M, Gong X. Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. InFourteenth ACM Conference on Recommender Systems 2020 Sep 22 (pp. 269-278).
部门简介:
58同城TEG技术工程平台群AI Lab,旨在推动AI技术在58同城的落�
- 原文作者:知识铺
- 原文链接:https://index.zshipu.com/geek/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%90%8C%E5%9F%8E%E5%A4%9A%E7%9B%AE%E6%A0%87%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


